The Japanese presented a prototype processor for an ex-flop supercomputer: how does a chip work?
Earlier we talked about the most powerful Japanese supercomputer for research in the field of nuclear physics. Now Japan is creating an Post-K ex-flop supercomputer - the Japanese will be among the first to launch a machine with such computing power.
Commissioning is scheduled for 2021.
Last week, Fujitsu told about the technical characteristics of the A64FX chip, which will form the basis of the new “machine”. Tell us more about the chip and its capabilities.

/ photo Toshihiro Matsui CC / Japanese K computer supercomputer
It is expected that the computing capabilities of Post-K will be almost ten times higher than the performance of the most powerful of the existing IBM Summit supercomputers ( according to data for June 2018 ).
Such performance supercomputer required chip A64FX on the architecture of Arm. This chip consists of 48 cores for performing computational operations and four cores for controlling them. All of them are evenly divided into four groups - Core Memory Groups (CMG).
Each group has 8 MB of L2 cache. It is connected to the memory controller and the NoC interface (" network on chip"). NoC connects various CMGs with PCIe and Tofu controllers. The latter is responsible for the connection of the processor with the rest of the system. The Tofu controller has ten ports with a throughput of 12.5 GB / s.
The chip layout is as follows:
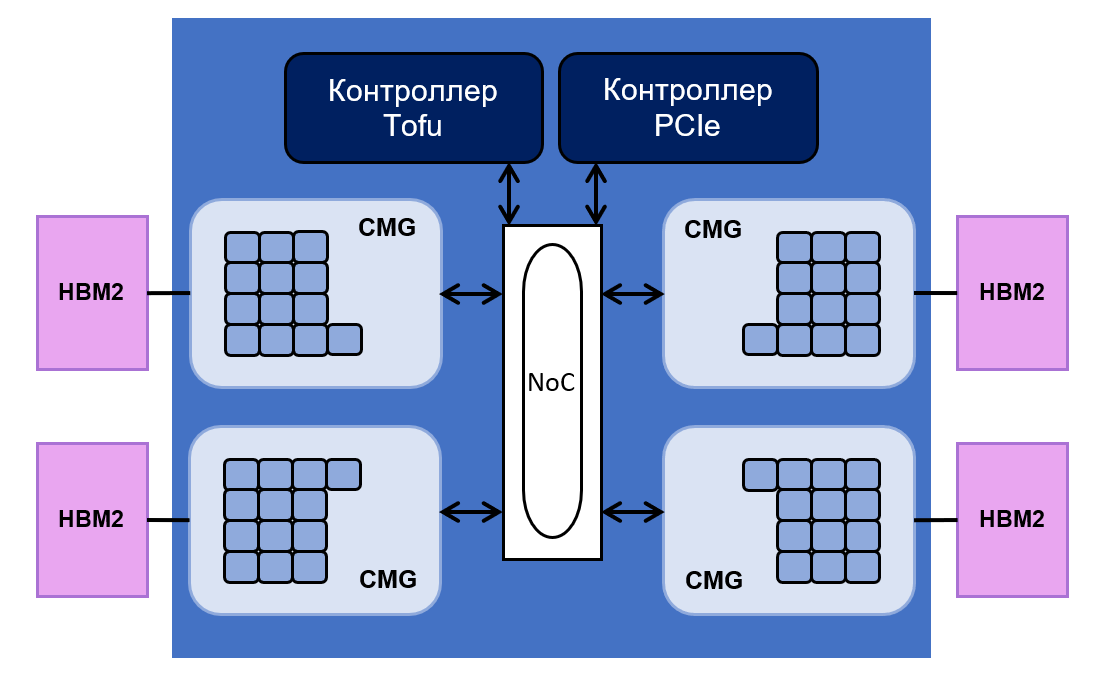
The total HBM2 memory capacity of the processor is 32 gigabytes, and its bandwidth is 1024 GB / s. Fujitsu says that processor performance on floating point operations reaches 2.7 teraflops for 64-bit operations, 5.4 teraflops for 32-bit operations and 10.8 teraflops for 16-bit operations.
The creation of Post-K is monitored by Top500 resource editors, who compile a list of the most powerful computing systems. According to their estimates, over 370 thousand A64FX processors are used in a supercomputer to achieve performance in one exaflops.
The device will first use the technology of vector expansion called Scalable Vector Extension (SVE). It differs from other SIMD architectures in that it does not limit the length of vector registers, but gives them a valid range. SVE supports vectors from 128 to 2048 bits in length. So any program can be run on other processors that support SVE, without the need for recompilation.
With the help of SVE (since this is a SIMD function), the processor can simultaneously perform calculations with several arrays of data. Here is an example of one such instruction for the NEON function, which was used for vector computing in other Arm processor architectures:
It adds four 32-bit integers from the 128-bit q2 register with the corresponding numbers in the 128-bit q3 register and writes the resulting array to q1. The equivalent of this C operation looks like this:
Additionally, SVE supports the auto-vectoring feature. The automatic vectorizer analyzes loops in code and, if possible, uses vector registers itself to execute them. This improves code performance.
For example, a function on C:
It will be compiled as follows (for a 32-bit Arm processor):
If you use auto-vectoring, it will look like this:
Here the SIMD registers q8 and q9 are loaded with data from the arrays pointed to by r5 and r4. Then the vadd instruction adds four 32-bit integer values at a time. This increases the amount of code, but much more data is processed this way for each iteration of the loop.
Creating exaflops supercomputers are engaged not only in Japan. For example, work is also being done in China and the United States.
In China, create Tianhe-3 (Tianhe-3). Its prototype is already being tested at the National Supercomputer Center in Tianjin. The final version of the computer is scheduled for completion in 2020.

/ photo O01326 CC / Supercomputer Tianhe-2 - the predecessor of Tianhe-3
At the heart of the Tianhe-3 are Chinese Phytium processors. The device contains 64 cores, has a performance of 512 gigaflops and a memory bandwidth of 204.8 GB / s.
A working prototype was created for the car from the Sunway series.. It is being tested at the National Supercomputer Center in Jinan. According to the developers, about 35 applications are currently operating on the computer - these are biomedical simulators, applications for processing big data, and programs for studying climate change. It is expected that work on the computer will be completed in the first half of 2021.
As for the United States, the Americans are planning to create their exaflops computer by 2021. The project is called Aurora A21, and the Argonne National Laboratory of the US Department of Energy , as well as Intel and Cray, are working on it .
This year, researchers have already selectedten projects for the Aurora Early Science Program, whose participants will be the first to use the new high-performance system. Among them were programs for creating a map of neurons in the brain, studying dark matter and developing a particle accelerator simulator.
Exaflops computers will make it possible to build complex models for research, so many research projects await the creation of such machines. One of the most ambitious is the Human Brain Project (HBP), whose goal is to create a complete model of the human brain and study neuromorphic calculations. As the HBP scientists say , the use of new exaflops systems will be found from the very first days of their existence.
What do we do in IT-GRAD: • IaaS • PCI DSS hosting • Cloud FZ-152
Materials from our blog on corporate IaaS:
Commissioning is scheduled for 2021.
Last week, Fujitsu told about the technical characteristics of the A64FX chip, which will form the basis of the new “machine”. Tell us more about the chip and its capabilities.
/ photo Toshihiro Matsui CC / Japanese K computer supercomputer
Specifications A64FX
It is expected that the computing capabilities of Post-K will be almost ten times higher than the performance of the most powerful of the existing IBM Summit supercomputers ( according to data for June 2018 ).
Such performance supercomputer required chip A64FX on the architecture of Arm. This chip consists of 48 cores for performing computational operations and four cores for controlling them. All of them are evenly divided into four groups - Core Memory Groups (CMG).
Each group has 8 MB of L2 cache. It is connected to the memory controller and the NoC interface (" network on chip"). NoC connects various CMGs with PCIe and Tofu controllers. The latter is responsible for the connection of the processor with the rest of the system. The Tofu controller has ten ports with a throughput of 12.5 GB / s.
The chip layout is as follows:
The total HBM2 memory capacity of the processor is 32 gigabytes, and its bandwidth is 1024 GB / s. Fujitsu says that processor performance on floating point operations reaches 2.7 teraflops for 64-bit operations, 5.4 teraflops for 32-bit operations and 10.8 teraflops for 16-bit operations.
The creation of Post-K is monitored by Top500 resource editors, who compile a list of the most powerful computing systems. According to their estimates, over 370 thousand A64FX processors are used in a supercomputer to achieve performance in one exaflops.
The device will first use the technology of vector expansion called Scalable Vector Extension (SVE). It differs from other SIMD architectures in that it does not limit the length of vector registers, but gives them a valid range. SVE supports vectors from 128 to 2048 bits in length. So any program can be run on other processors that support SVE, without the need for recompilation.
With the help of SVE (since this is a SIMD function), the processor can simultaneously perform calculations with several arrays of data. Here is an example of one such instruction for the NEON function, which was used for vector computing in other Arm processor architectures:
vadd.i32 q1, q2, q3It adds four 32-bit integers from the 128-bit q2 register with the corresponding numbers in the 128-bit q3 register and writes the resulting array to q1. The equivalent of this C operation looks like this:
for(i = 0; i < 4; i++) a[i] = b[i] + c[i];Additionally, SVE supports the auto-vectoring feature. The automatic vectorizer analyzes loops in code and, if possible, uses vector registers itself to execute them. This improves code performance.
For example, a function on C:
voidvectorize_this(unsignedint *a, unsignedint *b, unsignedint *c){
unsignedint i;
for(i = 0; i < SIZE; i++)
{
a[i] = b[i] + c[i];
}
}
It will be compiled as follows (for a 32-bit Arm processor):
104cc: ldr.w r3, [r4, #4]!
104d0: ldr.w r1, [r2, #4]!
104d4: cmp r4, r5
104d6: add r3, r1
104d8: str.w r3, [r0, #4]!
104dc: bne.n 104cc <vectorize_this+0xc>
If you use auto-vectoring, it will look like this:
10780: vld1.64 {d18-d19}, [r5 :64]
10784: adds r6, #110786: cmp r6, r7
10788: add.w r5, r5, #161078c: vld1.32 {d16-d17}, [r4]
10790: vadd.i32 q8, q8, q9
10794: add.w r4, r4, #1610798: vst1.32 {d16-d17}, [r3]
1079c: add.w r3, r3, #16107a0: bcc.n 10780 <vectorize_this+0x70>
Here the SIMD registers q8 and q9 are loaded with data from the arrays pointed to by r5 and r4. Then the vadd instruction adds four 32-bit integer values at a time. This increases the amount of code, but much more data is processed this way for each iteration of the loop.
Who else creates exaflops supercomputers
Creating exaflops supercomputers are engaged not only in Japan. For example, work is also being done in China and the United States.
In China, create Tianhe-3 (Tianhe-3). Its prototype is already being tested at the National Supercomputer Center in Tianjin. The final version of the computer is scheduled for completion in 2020.
/ photo O01326 CC / Supercomputer Tianhe-2 - the predecessor of Tianhe-3
{kind=link}
At the heart of the Tianhe-3 are Chinese Phytium processors. The device contains 64 cores, has a performance of 512 gigaflops and a memory bandwidth of 204.8 GB / s.
A working prototype was created for the car from the Sunway series.. It is being tested at the National Supercomputer Center in Jinan. According to the developers, about 35 applications are currently operating on the computer - these are biomedical simulators, applications for processing big data, and programs for studying climate change. It is expected that work on the computer will be completed in the first half of 2021.
As for the United States, the Americans are planning to create their exaflops computer by 2021. The project is called Aurora A21, and the Argonne National Laboratory of the US Department of Energy , as well as Intel and Cray, are working on it .
This year, researchers have already selectedten projects for the Aurora Early Science Program, whose participants will be the first to use the new high-performance system. Among them were programs for creating a map of neurons in the brain, studying dark matter and developing a particle accelerator simulator.
Exaflops computers will make it possible to build complex models for research, so many research projects await the creation of such machines. One of the most ambitious is the Human Brain Project (HBP), whose goal is to create a complete model of the human brain and study neuromorphic calculations. As the HBP scientists say , the use of new exaflops systems will be found from the very first days of their existence.
What do we do in IT-GRAD: • IaaS • PCI DSS hosting • Cloud FZ-152
Materials from our blog on corporate IaaS:
- Serverless computing in the cloud - a trend of modernity or necessity?
- How to place 100% of the infrastructure in the cloud IaaS-provider and not regret it
- Cloud technologies in the financial sector: the experience of Russian companies