Downloading SNMP Monitoring Data to Oracle
- Tutorial
Some time ago, I wrote an article on optimizing data loading in an Oracle database. Judging by the abundance of comments that followed, the article aroused great interest, but judging by the same comments (as well as the subsequent article about loading data into PostgreSQL), many people understood it differently from what I had expected. For the most part, I myself am to blame for this, because, in the process of simplifying the presentation of the material, I divorced myself from life so much that the task ceased to be understood by others (this, in turn, negatively affected the understanding of the reasons for choosing the methods used to solve it).
Today, I want to correct the mistakes made. I will talk about the real task of processing SNMP monitoring data, paying maximum attention to technical details. I will try to justify the choice of approaches for its solution and compare their performance. Also, I will pay attention to those technical points that can cause difficulties for beginners. Before moving on, I want to express my gratitude to DenKrep , xlix123 , zhekappp and all the other comrades who gave an incredible amount of useful advice in the discussion of the previous article.
I want to say right away that I am not at all interested in such questions as:
For the most part, these questions, and the like, do not make sense (at least in isolation from the details of the hardware configuration). I deliberately do not say a word about which hardware my Oracle server is running on. In my opinion, this is not important. But what is important then?
It is important that there is a real task, for example, collecting SNMP monitoring data, during the execution of which a large amount of data is constantly generated that needs to be processed. In this case, the following points are significant:
I consider various options for solving this problem and compare their performance. Of course, the goal is to find the most productive solution.
To begin with, remember what kind of data we get using SNMP? In fact, we can get the values of some predefined variables by querying the OID of interest to us using a GET request. For example, by requesting OID = 1.3.6.1.2.1.1.3.0, we can get a value as important for monitoring as sysUpTime . The values of variables accessed through SNMP are not necessarily numeric. It can be strings.
But SNMP is not limited to accessing a set of scalar variables. Values of variables can be grouped into tables. In each row of the table are grouped the values of the variables associated with a particular resource. To access each value, it is necessary to supplement the OID assigned to the column of the table with some identifier that defines the resource description line. We will call this row identifier the resource index.
In the case of polling the list of interfaces (1.3.6.1.2.1.2), the integer acts as the resource identifier, but, for other tables, it can be an IP address or something else determined by the specification . The difficulty lies in the fact that we do not know the index of the resource being polled in advance and we cannot get the value of the variable we are interested in using the GET request.
To read the values in tables, you need to use GETNEXT queries that return the OID and value of the variable that follows the lexicographic order of the OID specified in the query. So passing the OID column, which is the prefix of the OID of the variable we are interested in, we get the corresponding value from the first row of the table. To get the value of the next row, we pass in the OID received as part of the response to the first query, and so on, until the table is fully scanned.
In order to optimize performance (by reducing the number of requests sent), we can transfer the OIDs of several columns with one request. In addition, the ability to generate BULK requests was added in version 2 of SNMP. One BULK request replaces several GETNEXT requests executed one after another, which allows you to read the entire table in one request (with a sufficient BULK value). I already talked about all this before .
I repeat all this in order to make it clear - the tables are not constant! The description (for example, somewhere in the database) of the interface table manually, with the assignment of OIDs to them, is completely meaningless. Rows of tables can be added and deleted during reconfiguration of equipment. Moreover, the index of some existing interface may change! In fact, one of the tasks of the SNMP monitoring system is to automate the tracking of all changes to the viewed tables.
How will it look in the database? Pretty simple:
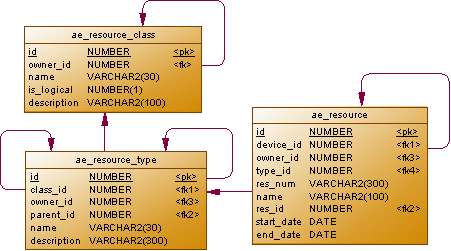
The data obtained during the monitoring process, we will bind to the resources (ae_resource). Resources, in turn, will be linked into a two-level hierarchy. At the top level, the device resource will be presented. According to owner_id, child resources, such as interfaces, will be associated with it (the fact that these are interfaces, and not something else, will be determined by the type_id value from the ae_resource_type directory). The device_id values of the parent and all child resources will match and point to the hardware description.
You may notice that the ae_resource table has start_date and end_date fields. Keeping them up to date is our task. We must create new resources, as necessary, putting them the start date of the action in start_date and end the action of obsolete resources by setting end_date. To identify resources, the name field will be used (in the case of interfaces, the value of the ifDescr attribute is 1.3.6.1.2.1.2.2.1.2). We will save the resource index in the res_num field (if it changes, the resource with the old index value must be closed, after which a new resource must be created).
The need to keep the list of interfaces up to date is the main reason that the data will have to be processed (although it would take much less time to normally insert the received data into the table). But if we process the data anyway, why not get the most out of it? In the process of monitoring, we get a lot of data, some of which do not change or change slightly. We can reduce the amount of data stored in the database (which will have a beneficial effect on both its volume and performance) if it saves only significant changes. But how to determine which changes are significant? The politicians will help us with this:
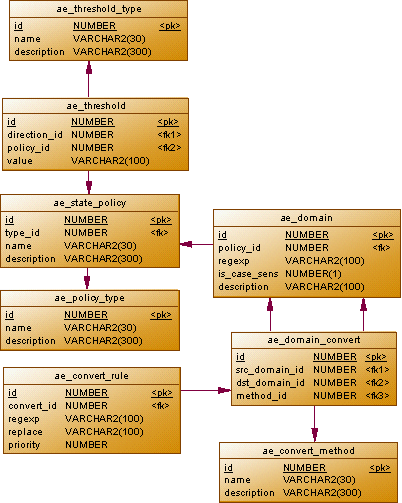
The value of each parameter we receive will be associated with a certain domain (ae_domain). A regular expression (regexp) will help validate the value. Before saving to the database, the value can be converted to some other domain (for example, we get the strings in hexadecimal notation, which would be nice to convert to a more familiar form). Conversion rules will be determined by the ae_domain_convert table.
What changes will be considered significant? It depends on the domain. By default, any change in the value will be considered significant (that is, if the value has not changed, writing to the database will not be performed). For some parameters it makes sense to set special rules. For example, sysUpTime (after the appropriate conversion) is a monotonically increasing numerical value. Decreasing this value means that the host has rebooted. Setting a special policy for this domain will allow us to record in the database only events of decreasing value (meaning reboots), while the previous value (that is, the maximum achieved uptime) will be written to the database, not the received one.
In ae_threshold we will set the thresholds, the intersection of which (in a given direction) will be considered as a significant change. In addition, we introduce a special type of threshold (delta), which determines the absolute value of the difference between the previous and received values. Setting such a threshold can be convenient, for example, for traffic counters, such as ifInOctets (1.3.6.1.2.1.2.2.1.10).
As a whole, the data schema will look like this:
Now it remains to fill the directories with data:
And prepare a draft test code:
For a detailed performance analysis, we will use the event 10046 trace on the server, with subsequent processing of traces by the tkprof utility .
We start testing with the most obvious single-record processing. In addition to actually evaluating performance, writing this code will help us better understand how the data will be processed.
Obviously, for this code to correctly support the list of interfaces, it is necessary that the name of the interface be transferred to the database before the other attributes of the resource.
Testing results are quite predictable:
We perform a very large number of requests and spend a lot of time on network interaction.
The most radical way to deal with overhead is the transition to mass processing. We can pre-save the data set for processing in some table, and then process the data not by one record, but all at once. Of course, for intermediate data storage, you can use regular tables, but using GTT for these purposes is more profitable, due to reduced overhead for logging.
To insert data into a temporary table, we will use DML, rather than calls to stored procedures, which will allow us to use JDBC batch to reduce network overhead.
When using this approach, it is not required that the interface name be processed before the rest of its parameters. It is enough that the names of all the processed interfaces are present in the processed data set.
Run this code to execute and get:
If you think about it, the reason for this error becomes clear. If the set of processed data contains conflicting data for some variable (we managed to read it several times), a problem arises. With the normal functioning of SNMP monitoring, this situation should not occur, but we must provide for something to prevent the application from crashing if it does occur.
The first thing that comes to mind is storing aggregated data for each variable. We will add a new record if it is not already or update an existing one, write a new value in it:
Now we are dealing with the same problem, but at the stage of the batch request:
I have to abandon batch:
Results have improved markedly:
We can simplify our lives at the data insertion stage (at the same time getting rid of the ORA-600 feature) by adding grouping at the mass processing stage. In this case, we can not be shy with BULK_SIZE, setting it to the maximum.
Run and see the results:
As expected, the cost of inserting data has decreased, but subsequent processing has become more complicated.
As DenKrep rightly remarked , even with the lowest possible cost of inserting data, the GTT approach is very similar to the process of pouring from empty to empty. How else can we reduce the cost of networking? We cannot use JDBC batch to call PL / SQL code (or rather we can, but it will not bring any benefit), but we can pass arrays!
The process of passing arrays from Java code itself is well described in this guide. To transfer data, we need to determine the following types:
Since I have Oracle Client 11g installed, I had to replace [ORACLE_HOME] /jdbc/lib/classes12.zip with [ORACLE_HOME] /jdbc/lib/ojdbc5.jar. Also, I want to emphasize that [ORACLE_HOME] /jdbc/lib/nls_charset12.zip should be available when the application starts, otherwise it will be impossible to transmit string values (there will be no errors, but NULL will be transmitted).
How will we process the array on the server? To get started, just try calling the addValue previously written in a loop:
Java code is noticeably more complicated:
Various funny operators appear in the trace related to the transfer of arrays from the client:
The result is logical:
The indicators related to data transfer from the client have improved, but the data processing has become somewhat more complicated compared to the plsql option.
Obviously, we are not fully utilizing the potential of arrays transmitted from the client. It would be nice to pass the array directly to SQL queries to enable bulk processing, but how to do it? We cannot use BULK COLLECT , because our queries are too complex for this. Fortunately, we can wrap the collection in TABLE :
The result speaks for itself:
As the test results show, direct transfer of arrays to Oracle from the client code (bulk) allows you to achieve the best performance. Variants using GTT (temporary, distinct) are not much inferior to it in terms of performance, but much simpler from the point of view of Java code. The temporary option, in addition, makes it possible to observe the ORA-600 when using batch and the poor arrangement of stars.
Which approach to use for data processing is up to you. Test results are available on GitHub .
Today, I want to correct the mistakes made. I will talk about the real task of processing SNMP monitoring data, paying maximum attention to technical details. I will try to justify the choice of approaches for its solution and compare their performance. Also, I will pay attention to those technical points that can cause difficulties for beginners. Before moving on, I want to express my gratitude to DenKrep , xlix123 , zhekappp and all the other comrades who gave an incredible amount of useful advice in the discussion of the previous article.
What is all this for?
I want to say right away that I am not at all interested in such questions as:
- At what maximum speed can I upload data to Oracle?
- What is faster than Oracle or PostgreSQL?
- How fast can I insert into a database table?
For the most part, these questions, and the like, do not make sense (at least in isolation from the details of the hardware configuration). I deliberately do not say a word about which hardware my Oracle server is running on. In my opinion, this is not important. But what is important then?
It is important that there is a real task, for example, collecting SNMP monitoring data, during the execution of which a large amount of data is constantly generated that needs to be processed. In this case, the following points are significant:
- It is not enough just to insert the data into the table (how exactly the data should be processed and why, I will describe in the next section)
- Data is not generated on the database server (most likely, there will be several data collection servers that transfer data to a single database)
- Data is received continuously and must also be constantly processed, it is desirable to minimize the processing time of data (in order to ensure a minimum response time to the occurrence of an emergency)
- Loss of part of the data is allowed (if an accident occurs, we will find it in the next polling cycle, even if part of the current data is lost)
- The history of changes in key parameters should be maintained for a long time
I consider various options for solving this problem and compare their performance. Of course, the goal is to find the most productive solution.
Formulation of the problem
To begin with, remember what kind of data we get using SNMP? In fact, we can get the values of some predefined variables by querying the OID of interest to us using a GET request. For example, by requesting OID = 1.3.6.1.2.1.1.3.0, we can get a value as important for monitoring as sysUpTime . The values of variables accessed through SNMP are not necessarily numeric. It can be strings.
But SNMP is not limited to accessing a set of scalar variables. Values of variables can be grouped into tables. In each row of the table are grouped the values of the variables associated with a particular resource. To access each value, it is necessary to supplement the OID assigned to the column of the table with some identifier that defines the resource description line. We will call this row identifier the resource index.
In the case of polling the list of interfaces (1.3.6.1.2.1.2), the integer acts as the resource identifier, but, for other tables, it can be an IP address or something else determined by the specification . The difficulty lies in the fact that we do not know the index of the resource being polled in advance and we cannot get the value of the variable we are interested in using the GET request.
To read the values in tables, you need to use GETNEXT queries that return the OID and value of the variable that follows the lexicographic order of the OID specified in the query. So passing the OID column, which is the prefix of the OID of the variable we are interested in, we get the corresponding value from the first row of the table. To get the value of the next row, we pass in the OID received as part of the response to the first query, and so on, until the table is fully scanned.
In order to optimize performance (by reducing the number of requests sent), we can transfer the OIDs of several columns with one request. In addition, the ability to generate BULK requests was added in version 2 of SNMP. One BULK request replaces several GETNEXT requests executed one after another, which allows you to read the entire table in one request (with a sufficient BULK value). I already talked about all this before .
I repeat all this in order to make it clear - the tables are not constant! The description (for example, somewhere in the database) of the interface table manually, with the assignment of OIDs to them, is completely meaningless. Rows of tables can be added and deleted during reconfiguration of equipment. Moreover, the index of some existing interface may change! In fact, one of the tasks of the SNMP monitoring system is to automate the tracking of all changes to the viewed tables.
How will it look in the database? Pretty simple:
The data obtained during the monitoring process, we will bind to the resources (ae_resource). Resources, in turn, will be linked into a two-level hierarchy. At the top level, the device resource will be presented. According to owner_id, child resources, such as interfaces, will be associated with it (the fact that these are interfaces, and not something else, will be determined by the type_id value from the ae_resource_type directory). The device_id values of the parent and all child resources will match and point to the hardware description.
You may notice that the ae_resource table has start_date and end_date fields. Keeping them up to date is our task. We must create new resources, as necessary, putting them the start date of the action in start_date and end the action of obsolete resources by setting end_date. To identify resources, the name field will be used (in the case of interfaces, the value of the ifDescr attribute is 1.3.6.1.2.1.2.2.1.2). We will save the resource index in the res_num field (if it changes, the resource with the old index value must be closed, after which a new resource must be created).
The need to keep the list of interfaces up to date is the main reason that the data will have to be processed (although it would take much less time to normally insert the received data into the table). But if we process the data anyway, why not get the most out of it? In the process of monitoring, we get a lot of data, some of which do not change or change slightly. We can reduce the amount of data stored in the database (which will have a beneficial effect on both its volume and performance) if it saves only significant changes. But how to determine which changes are significant? The politicians will help us with this:
The value of each parameter we receive will be associated with a certain domain (ae_domain). A regular expression (regexp) will help validate the value. Before saving to the database, the value can be converted to some other domain (for example, we get the strings in hexadecimal notation, which would be nice to convert to a more familiar form). Conversion rules will be determined by the ae_domain_convert table.
What changes will be considered significant? It depends on the domain. By default, any change in the value will be considered significant (that is, if the value has not changed, writing to the database will not be performed). For some parameters it makes sense to set special rules. For example, sysUpTime (after the appropriate conversion) is a monotonically increasing numerical value. Decreasing this value means that the host has rebooted. Setting a special policy for this domain will allow us to record in the database only events of decreasing value (meaning reboots), while the previous value (that is, the maximum achieved uptime) will be written to the database, not the received one.
In ae_threshold we will set the thresholds, the intersection of which (in a given direction) will be considered as a significant change. In addition, we introduce a special type of threshold (delta), which determines the absolute value of the difference between the previous and received values. Setting such a threshold can be convenient, for example, for traffic counters, such as ifInOctets (1.3.6.1.2.1.2.2.1.10).
As a whole, the data schema will look like this:
Data schema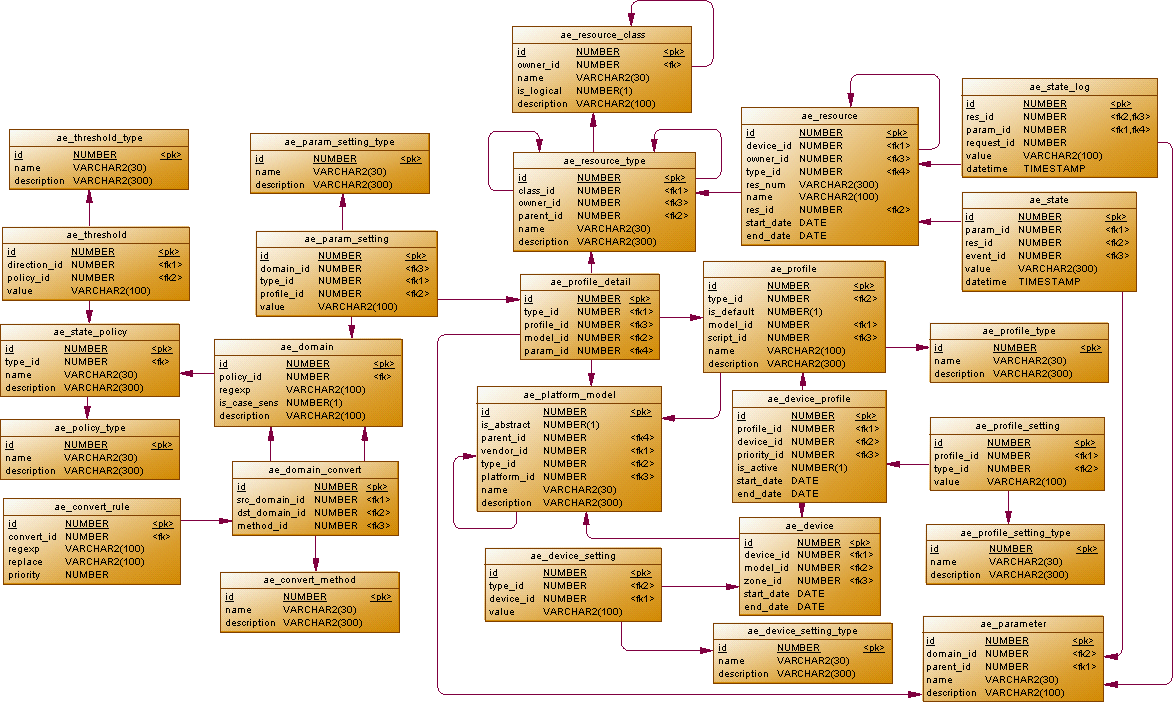
Script
create sequence ae_platform_model_seq start with 100;
create table ae_platform_model (
id number not null,
name varchar2(30) not null,
description varchar2(300)
);
comment on table ae_platform_model is 'Модель оборудования';
create unique index ae_platform_model_pk on ae_platform_model(id);
alter table ae_platform_model add
constraint pk_ae_platform_model primary key(id);
create sequence ae_device_seq cache 100;
create table ae_device (
id number not null,
model_id number not null,
start_date date default sysdate not null,
end_date date default null
);
comment on table ae_device is 'Оборудование';
create unique index ae_device_pk on ae_device(id);
create index ae_device_fk on ae_device(device_id);
create index ae_device_model_fk on ae_device(model_id);
create index ae_device_zone_fk on ae_device(zone_id);
alter table ae_device add
constraint pk_ae_device primary key(id);
alter table ae_device add
constraint fk_ae_device_model foreign key (model_id)
references ae_platform_model(id);
create sequence ae_resource_class_seq start with 100;
create table ae_resource_class (
id number not null,
owner_id number,
is_logical number(1) not null,
name varchar2(30) not null,
description varchar2(300)
);
comment on table ae_resource_class is 'Класс ресурса';
comment on column ae_resource_class.is_logical is 'Признак логического ресурса';
create unique index ae_resource_class_pk on ae_resource_class(id);
create index ae_resource_class_fk on ae_resource_class(owner_id);
alter table ae_resource_class
add constraint ae_resource_class_ck check (is_logical in (0, 1));
alter table ae_resource_class add
constraint pk_ae_resource_class primary key(id);
create sequence ae_resource_type_seq start with 100;
create table ae_resource_type (
id number not null,
owner_id number,
parent_id number,
class_id number not null,
name varchar2(30) not null,
description varchar2(300)
);
comment on table ae_resource_type is 'Тип ресурса';
create unique index ae_resource_type_pk on ae_resource_type(id);
create index ae_resource_type_owner_fk on ae_resource_type(owner_id);
create index ae_resource_type_parent_fk on ae_resource_type(parent_id);
alter table ae_resource_type add
constraint pk_ae_resource_type primary key(id);
alter table ae_resource_type add
constraint fk_ae_resource_type foreign key (class_id)
references ae_resource_class(id);
alter table ae_resource_type add
constraint fk_ae_resource_type_owner foreign key (owner_id)
references ae_resource_type(id);
alter table ae_resource_type add
constraint fk_ae_resource_type_parent foreign key (parent_id)
references ae_resource_type(id);
create sequence ae_resource_seq cache 100;
create table ae_resource (
id number not null,
device_id number not null,
owner_id number default null,
type_id number not null,
name varchar2(1000) not null,
res_num varchar2(300) not null,
res_id number,
tmp_id number,
start_date date default sysdate not null,
end_date date default null
);
create unique index ae_resource_pk on ae_resource(id);
create index ae_res_dev_fk on ae_resource(device_id);
create index ae_res_dev_type_fk on ae_resource(type_id);
create index ae_res_dev_res_fk on ae_resource(res_id);
create index ae_res_dev_res_tmp_fk on ae_resource(tmp_id);
alter table ae_resource add
constraint pk_ae_resource primary key(id);
alter table ae_resource add
constraint fk_ae_res_device foreign key (device_id)
references ae_device(id);
alter table ae_resource add
constraint fk_ae_res_dev_parent foreign key (owner_id)
references ae_resource(id);
alter table ae_resource add
constraint fk_ae_res_dev_type foreign key (type_id)
references ae_resource_type(id);
create table ae_policy_type (
id number not null,
name varchar2(30) not null,
description varchar2(100)
);
comment on table ae_policy_type is 'Список поддерживаемых платформ';
create unique index ae_policy_type_pk on ae_policy_type(id);
create unique index ae_policy_type_uk on ae_policy_type(name);
alter table ae_policy_type add
constraint pk_ae_policy_type primary key(id);
create table ae_state_policy (
id number not null,
type_id number not null,
name varchar2(30) not null,
description varchar2(100)
);
comment on table ae_state_policy is 'Список поддерживаемых платформ';
create unique index ae_state_policy_pk on ae_state_policy(id);
create index ae_state_policy_fk on ae_state_policy(type_id);
alter table ae_state_policy add
constraint pk_ae_state_policy primary key(id);
alter table ae_state_policy add
constraint fk_ae_state_policy foreign key (type_id)
references ae_policy_type(id);
create table ae_threshold_type (
id number not null,
name varchar2(30) not null,
description varchar2(300)
);
create unique index ae_threshold_type_pk on ae_threshold_type(id);
alter table ae_threshold_type add
constraint pk_ae_threshold_type primary key(id);
create sequence ae_threshold_seq start with 100;
create table ae_threshold (
id number not null,
type_id number not null,
policy_id number not null,
value varchar2(100) not null
);
create unique index ae_threshold_pk on ae_threshold(id);
create index ae_threshold_direction_fk on ae_threshold(type_id);
create index ae_threshold_profile_fk on ae_threshold(policy_id);
alter table ae_threshold add
constraint pk_ae_threshold primary key(id);
alter table ae_threshold add
constraint fk_ae_threshold_type foreign key (type_id)
references ae_threshold_type(id);
alter table ae_threshold add
constraint fk_ae_threshold_policy foreign key (policy_id)
references ae_state_policy(id);
create sequence ae_domain_convert_seq start with 100;
create table ae_domain (
id number not null,
policy_id number default null,
regexp varchar2(100),
is_case_sens number(1) default 0 not null,
description varchar2(100)
);
create unique index ae_domain_pk on ae_domain(id);
create index ae_domain_fk on ae_domain(policy_id);
alter table ae_domain
add constraint ae_domain_ck check (is_case_sens in (0, 1));
alter table ae_domain add
constraint pk_ae_domain primary key(id);
alter table ae_domain add
constraint fk_ae_domain foreign key (policy_id)
references ae_state_policy(id);
create sequence ae_parameter_seq start with 1000;
create table ae_parameter (
id number not null,
domain_id number not null,
parent_id number,
name varchar2(30) not null,
description varchar2(100)
);
create unique index ae_parameter_pk on ae_parameter(id);
create unique index ae_parameter_uk on ae_parameter(name);
create index ae_parameter_domain_fk on ae_parameter(domain_id);
create index ae_parameter_parent_fk on ae_parameter(parent_id);
alter table ae_parameter add
constraint pk_ae_parameter primary key(id);
alter table ae_parameter add
constraint fk_ae_parameter_domain foreign key (domain_id)
references ae_domain(id);
alter table ae_parameter add
constraint fk_ae_parameter foreign key (parent_id)
references ae_parameter(id);
create sequence ae_state_seq cache 100;
create table ae_state (
id number not null,
res_id number not null,
param_id number not null,
value varchar2(300),
datetime timestamp default current_timestamp not null
);
comment on table ae_state is 'Состояние параметра';
comment on column ae_state.datetime is 'Дата и время последнего изменения';
create unique index ae_state_pk on ae_state(id);
create index ae_state_res_fk on ae_state(res_id);
create index ae_state_param_fk on ae_state(param_id);
alter table ae_state add
constraint pk_ae_state primary key(id);
alter table ae_state add
constraint fk_ae_state_res foreign key (res_id)
references ae_resource(id);
alter table ae_state add
constraint fk_ae_state_param foreign key (param_id)
references ae_parameter(id);
create sequence ae_state_log_seq cache 100;
create table ae_state_log (
id number not null,
res_id number not null,
param_id number not null,
value varchar2(300),
datetime timestamp default current_timestamp not null
) pctfree 0
partition by range (datetime)
( partition ae_state_log_p1 values less than (maxvalue)
);
comment on table ae_state_log is 'Хронология изменения состояния параметра';
create unique index ae_state_log_pk on ae_state_log(datetime, id) local;
alter table ae_state_log add
constraint pk_ae_state_log primary key(datetime, id);
create sequence ae_profile_type_seq;
create table ae_profile_type (
id number not null,
name varchar2(30) not null,
description varchar2(100)
);
create unique index ae_profile_type_pk on ae_profile_type(id);
create unique index ae_profile_type_uk on ae_profile_type(name);
alter table ae_profile_type add
constraint pk_ae_profile_type primary key(id);
create sequence ae_profile_seq;
create table ae_profile (
id number not null,
type_id number not null,
is_default number(1) default 0 not null,
model_id number not null,
script_id number default null,
name varchar2(30) not null,
description varchar2(100)
);
create unique index ae_profile_pk on ae_profile(id);
create index ae_profile_type_fk on ae_profile(type_id);
create index ae_profile_model_fk on ae_profile(model_id);
create index ae_profile_script_fk on ae_profile(script_id);
alter table ae_profile
add constraint ae_profile_ck check (is_default in (0, 1));
alter table ae_profile add
constraint pk_ae_profile primary key(id);
alter table ae_profile add
constraint fk_ae_profile_type foreign key (type_id)
references ae_profile_type(id);
create sequence ae_profile_detail_seq;
create table ae_profile_detail (
id number not null,
type_id number not null,
profile_id number not null,
model_id number not null,
param_id number not null
);
create unique index ae_profile_detail_pk on ae_profile_detail(id);
create index ae_profile_detail_fk on ae_profile_detail(profile_id);
create index ae_profile_detail_type_fk on ae_profile_detail(type_id);
create index ae_profile_detail_model_fk on ae_profile_detail(model_id);
create index ae_profile_detail_param_fk on ae_profile_detail(param_id);
alter table ae_profile_detail add
constraint pk_ae_profile_detail primary key(id);
alter table ae_profile_detail add
constraint fk_ae_profile_detail foreign key (profile_id)
references ae_profile(id);
alter table ae_profile_detail add
constraint fk_ae_profile_detail_type foreign key (type_id)
references ae_resource_type(id);
alter table ae_profile_detail add
constraint fk_ae_profile_detail_model foreign key (model_id)
references ae_platform_model(id);
create global temporary table ae_state_tmp (
id number not null,
device_id number not null,
profile_id number not null,
param_id number not null,
num varchar2(300),
value varchar2(300),
datetime timestamp default current_timestamp not null
) on commit delete rows;
create index ae_state_tmp_ix on ae_state_tmp(device_id, profile_id, param_id, num);
Now it remains to fill the directories with data:
Test data
Insert into AE_POLICY_TYPE
(ID, NAME, DESCRIPTION)
Values
(1, 'default', NULL);
Insert into AE_POLICY_TYPE
(ID, NAME, DESCRIPTION)
Values
(2, 'uptime', NULL);
Insert into AE_POLICY_TYPE
(ID, NAME, DESCRIPTION)
Values
(3, 'threshold', NULL);
COMMIT;
Insert into AE_STATE_POLICY
(ID, NAME, DESCRIPTION, TYPE_ID)
Values
(1, 'default', NULL, 1);
Insert into AE_STATE_POLICY
(ID, NAME, DESCRIPTION, TYPE_ID)
Values
(2, 'uptime', NULL, 2);
COMMIT;
Insert into AE_DOMAIN
(ID, REGEXP, IS_CASE_SENS, DESCRIPTION, POLICY_ID)
Values
(10, '((\d+)\D*,\s*)?(\d+):(\d+):(\d+)(\.\d+)?', 0, 'SNMP uptime', 1);
Insert into AE_DOMAIN
(ID, REGEXP, IS_CASE_SENS, DESCRIPTION, POLICY_ID)
Values
(11, '\d+', 0, 'SNMP число', 1);
Insert into AE_DOMAIN
(ID, REGEXP, IS_CASE_SENS, DESCRIPTION, POLICY_ID)
Values
(12, '([a-fA-F\d])+', 0, 'SNMP строка', 1);
Insert into AE_DOMAIN
(ID, REGEXP, IS_CASE_SENS, DESCRIPTION, POLICY_ID)
Values
(13, '.*', 0, 'SNMP Произвольная строка', 1);
Insert into AE_DOMAIN
(ID, REGEXP, IS_CASE_SENS, DESCRIPTION, POLICY_ID)
Values
(14, '\d+', 0, 'SNMP uptime (числовая форма)', 2);
COMMIT;
Insert into AE_PARAMETER
(ID, DOMAIN_ID, PARENT_ID, NAME, DESCRIPTION)
Values
(101, 14, NULL, 'uptime', 'SNMP Uptime');
Insert into AE_PARAMETER
(ID, DOMAIN_ID, PARENT_ID, NAME, DESCRIPTION)
Values
(102, 11, NULL, 'ifIndex', 'Индекс интерфейса');
Insert into AE_PARAMETER
(ID, DOMAIN_ID, PARENT_ID, NAME, DESCRIPTION)
Values
(103, 13, NULL, 'ifName', 'Имя интерфейса');
Insert into AE_PARAMETER
(ID, DOMAIN_ID, PARENT_ID, NAME, DESCRIPTION)
Values
(104, 11, NULL, 'ifInOctets', 'Входящий трафик');
Insert into AE_PARAMETER
(ID, DOMAIN_ID, PARENT_ID, NAME, DESCRIPTION)
Values
(105, 11, NULL, 'ifOutOctets', 'Исходящий трафик');
COMMIT;
Insert into AE_PLATFORM_MODEL
(ID, NAME, DESCRIPTION)
Values
(1, 'test', NULL);
COMMIT;
Insert into AE_PROFILE_TYPE
(ID, NAME, DESCRIPTION)
Values
(1, 'mon', 'Мониторинг');
COMMIT;
Insert into AE_PROFILE
(ID, TYPE_ID, IS_DEFAULT, MODEL_ID, SCRIPT_ID,
NAME, DESCRIPTION)
Values
(1, 1, 1, 1, NULL,
'test', NULL);
COMMIT;
Insert into AE_RESOURCE_CLASS
(ID, IS_LOGICAL, NAME, DESCRIPTION, OWNER_ID)
Values
(1, 0, 'Устройство', NULL, NULL);
Insert into AE_RESOURCE_CLASS
(ID, IS_LOGICAL, NAME, DESCRIPTION, OWNER_ID)
Values
(2, 0, 'Интерфейс', NULL, 1);
COMMIT;
Insert into AE_RESOURCE_TYPE
(ID, CLASS_ID, NAME, DESCRIPTION, OWNER_ID,
PARENT_ID)
Values
(1, 1, 'Host', NULL, NULL,
NULL);
Insert into AE_RESOURCE_TYPE
(ID, CLASS_ID, NAME, DESCRIPTION, OWNER_ID,
PARENT_ID)
Values
(2, 2, 'Interface', NULL, 1,
NULL);
COMMIT;
Insert into AE_PROFILE_DETAIL
(ID, TYPE_ID, PROFILE_ID, MODEL_ID, PARAM_ID)
Values
(4, 2, 1, 1, 104);
Insert into AE_PROFILE_DETAIL
(ID, TYPE_ID, PROFILE_ID, MODEL_ID, PARAM_ID)
Values
(5, 2, 1, 1, 105);
Insert into AE_PROFILE_DETAIL
(ID, TYPE_ID, PROFILE_ID, MODEL_ID, PARAM_ID)
Values
(6, 1, 1, 1, 1);
Insert into AE_PROFILE_DETAIL
(ID, TYPE_ID, PROFILE_ID, MODEL_ID, PARAM_ID)
Values
(1, 1, 1, 1, 101);
Insert into AE_PROFILE_DETAIL
(ID, TYPE_ID, PROFILE_ID, MODEL_ID, PARAM_ID)
Values
(2, 2, 1, 1, 102);
Insert into AE_PROFILE_DETAIL
(ID, TYPE_ID, PROFILE_ID, MODEL_ID, PARAM_ID)
Values
(3, 2, 1, 1, 103);
COMMIT;
Insert into AE_DEVICE
(ID, MODEL_ID, START_DATE, END_DATE)
Values
(0, 1, TO_DATE('10/30/2013 15:37:16', 'MM/DD/YYYY HH24:MI:SS'), NULL);
COMMIT;
Insert into AE_RESOURCE
(ID, DEVICE_ID, OWNER_ID, TYPE_ID, NAME,
RES_NUM, RES_ID, START_DATE, END_DATE, TMP_ID)
Values
(1, 0, NULL, 1, '127.0.0.1',
'0', NULL, TO_DATE('10/30/2013 15:24:44', 'MM/DD/YYYY HH24:MI:SS'), NULL, NULL);
COMMIT;
Insert into AE_THRESHOLD_TYPE
(ID, NAME, DESCRIPTION)
Values
(1, 'increase', 'Увеличение');
Insert into AE_THRESHOLD_TYPE
(ID, NAME, DESCRIPTION)
Values
(2, 'decrease', 'Уменьшение');
Insert into AE_THRESHOLD_TYPE
(ID, NAME, DESCRIPTION)
Values
(3, 'delta', 'Приращение');
COMMIT;
Insert into AE_THRESHOLD
(ID, TYPE_ID, POLICY_ID, VALUE)
Values
(1, 3, 1, '100');
COMMIT;
And prepare a draft test code:
Test code
package com.acme.ae.tests.jdbc;
import oracle.jdbc.driver.OracleCallableStatement;
import oracle.sql.*;
import java.sql.CallableStatement;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
public class Test {
private final static String CLASS_NAME = "oracle.jdbc.driver.OracleDriver";
private final static String USER_CONN = "jdbc:oracle:thin:@192.168.124.5:1523:new11";
private final static String USER_NAME = "ais";
private final static String USER_PASS = "ais";
private final static boolean AUTO_COMMIT_MODE = false;
private final static int BULK_SIZE = 100;
private final static int ALL_SIZE = 1000;
private final static String TRACE_ON_SQL =
"ALTER SESSION SET EVENTS '10046 trace name context forever, level 12'";
private final static Long DEVICE_ID = 0L;
private final static Long PROFILE_ID = 1L;
private final static Long UPTIME_PARAM_ID = 101L;
private final static Long IFNAME_PARAM_ID = 103L;
private final static Long INOCT_PARAM_ID = 104L;
private final static String FAKE_NUM_VALUE = "0";
private Connection c = null;
private void start() throws ClassNotFoundException, SQLException {
Class.forName(CLASS_NAME);
c = DriverManager.getConnection(USER_CONN, USER_NAME, USER_PASS);
c.setAutoCommit(AUTO_COMMIT_MODE);
CallableStatement st = c.prepareCall(TRACE_ON_SQL);
try {
st.execute();
} finally {
st.close();
}
}
private void stop() throws SQLException {
if (c != null) {
c.close();
}
}
public static void main(String[] args) {
Test t = new Test();
try {
try {
t.start();
t.test_plsql();
// Здесь будем вызывать тестовый код
} finally {
t.stop();
}
} catch (Exception e) {
System.out.println(e.toString());
}
}
}
For a detailed performance analysis, we will use the event 10046 trace on the server, with subsequent processing of traces by the tkprof utility .
The slowest way (plsql)
We start testing with the most obvious single-record processing. In addition to actually evaluating performance, writing this code will help us better understand how the data will be processed.
PL / SQL code
CREATE OR REPLACE package AIS.ae_monitoring as
procedure addValue( p_device in number
, p_profile in number
, p_param in number
, p_num in varchar2
, p_val in varchar2 );
end ae_monitoring;
/
CREATE OR REPLACE package body AIS.ae_monitoring as
g_ifName_parameter constant number default 103;
g_default_policy constant number default 1;
g_uptime_policy constant number default 2;
g_threshold_policy constant number default 3;
g_increase_type constant number default 1;
g_decrease_type constant number default 2;
g_delta_type constant number default 3;
procedure addValue( p_device in number
, p_profile in number
, p_param in number
, p_num in varchar2
, p_val in varchar2 ) as
cursor c_res(p_type number) is
select r.id, r.name
from ae_resource r
where r.device_id = p_device
and r.res_num = p_num
and r.type_id = p_type
and r.start_date <= sysdate and sysdate <= nvl(r.end_date, sysdate + 1);
cursor c_state(p_resid number) is
select s.value
from ae_state s
where s.res_id = p_resid
and s.param_id = p_param;
l_resid ae_resource.id%type default null;
l_resname ae_resource.name%type default null;
l_oldval ae_state.value%type default null;
l_restype ae_profile_detail.type_id%type default null;
l_owntype ae_resource_type.owner_id%type default null;
l_owner ae_resource.id%type default null;
l_policy ae_state_policy.type_id%type default null;
l_polid ae_state_policy.id%type default null;
l_count number default 0;
begin
-- Получить тип ресурса
select d.type_id, r.owner_id
into l_restype, l_owntype
from ae_profile_detail d
inner join ae_resource_type r on (r.id = d.type_id)
where d.profile_id = p_profile
and d.param_id = p_param;
-- Получить ID владельца
if not l_owntype is null then
select r.id into l_owner
from ae_resource r
where r.device_id = p_device
and r.type_id = l_owntype;
end if;
-- Обработать имя интерфейса
if p_param = g_ifName_parameter then
open c_res(l_restype);
fetch c_res into l_resid, l_resname;
if c_res%notfound or l_resname <> p_val then
-- Закрыть старый ресурс интерфейса
update ae_resource set end_date = sysdate
where id = l_resid;
-- Создать новый ресурс интерфейса
insert into ae_resource(id, device_id, owner_id, type_id, res_num, name)
values (ae_resource_seq.nextval, p_device, l_owner, l_restype, p_num, p_val);
end if;
close c_res;
return;
end if;
-- Получить ID ресурса
open c_res(l_restype);
fetch c_res into l_resid, l_resname;
if c_res%notfound then
-- Если ресурс не найден, создать новый ресурс интерфейса
insert into ae_resource(id, device_id, owner_id, type_id, res_num, name)
values (ae_resource_seq.nextval, p_device, l_owner, l_restype, p_num, p_val)
returning id into l_resid;
end if;
-- Получить старое значение параметра
open c_state(l_resid);
fetch c_state into l_oldval;
if c_state%notfound then
l_oldval := null;
end if;
close c_state;
-- Получить политику сохранения значений
select l.type_id, l.id
into l_policy, l_polid
from ae_parameter p
inner join ae_domain d on (d.id = p.domain_id)
inner join ae_state_policy l on (l.id = d.policy_id)
where p.id = p_param;
-- Получить количество пересеченных порогов
select count(*)
into l_count
from ae_threshold t
where t.policy_id = l_polid
and (( t.type_id = g_increase_type and l_oldval <= t.value and p_val >= t.value ) or
( t.type_id = g_decrease_type and l_oldval >= t.value and p_val <= t.value ) or
( t.type_id = g_delta_type and abs(p_val - l_oldval) >= t.value ));
-- Сохранить запись в ae_state_log в соответствии с политикой
if l_oldval is null or l_count > 0 or
( l_policy = g_uptime_policy and p_val < l_oldval) or
( l_policy = g_default_policy and p_val <> l_oldval) then
insert into ae_state_log(id, res_id, param_id, value)
values (ae_state_log_seq.nextval, l_resid, p_param, decode(l_policy, g_uptime_policy, nvl(l_oldval, p_val), p_val));
end if;
-- Обновить ae_state
update ae_state set value = p_val
, datetime = current_timestamp
where res_id = l_resid and param_id = p_param;
if sql%rowcount = 0 then
insert into ae_state(id, param_id, res_id, value)
values (ae_state_seq.nextval, p_param, l_resid, p_val);
end if;
close c_res;
exception
when others then
if c_res%isopen then close c_res; end if;
if c_state%isopen then close c_state; end if;
raise;
end;
end ae_monitoring;
/
Java code
private final static String ADD_VAL_SQL =
"begin ae_monitoring.addValue(?,?,?,?,?); end;";
private void test_plsql() throws SQLException {
System.out.println("test_plsql:");
CallableStatement st = c.prepareCall(ADD_VAL_SQL);
Long timestamp = System.currentTimeMillis();
Long uptime = 0L;
Long inoct = 0L;
try {
for (int i = 1; i <= ALL_SIZE; i++) {
// Передать uptime
st.setLong(1, DEVICE_ID);
st.setLong(2, PROFILE_ID);
st.setLong(3, UPTIME_PARAM_ID);
st.setString(4, FAKE_NUM_VALUE);
st.setString(5, uptime.toString());
st.execute();
// Передать имя интерфейса
st.setLong(1, DEVICE_ID);
st.setLong(2, PROFILE_ID);
st.setLong(3, IFNAME_PARAM_ID);
st.setString(4, Integer.toString((i % 100) + 1));
st.setString(5, Integer.toString((i % 100) + 1));
st.execute();
// Передать счетчик трафика
st.setLong(1, DEVICE_ID);
st.setLong(2, PROFILE_ID);
st.setLong(3, INOCT_PARAM_ID);
st.setString(4, Integer.toString((i % 100) + 1));
st.setString(5, inoct.toString());
st.execute();
// Увеличить счетчики
uptime += 100L;
if (uptime >= 1000) {
uptime = 0L;
}
inoct += 10L;
}
} finally {
st.close();
}
Long delta_1 = System.currentTimeMillis() - timestamp;
System.out.println((ALL_SIZE * 1000L) / delta_1);
timestamp = System.currentTimeMillis();
c.commit();
Long delta_2 = System.currentTimeMillis() - timestamp;
System.out.println(delta_2);
System.out.println((ALL_SIZE * 1000L) / (delta_1 - delta_2));
}
Obviously, for this code to correctly support the list of interfaces, it is necessary that the name of the interface be transferred to the database before the other attributes of the resource.
Testing results are quite predictable:
results
OVERALL TOTALS FOR ALL NON-RECURSIVE STATEMENTS
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.00 0.00 0 0 0 0
Execute 3000 4.23 4.13 7 102942 6615 3000
Fetch 0 0.00 0.00 0 0 0 0
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 3001 4.23 4.13 7 102942 6615 3000
Misses in library cache during parse: 1
Misses in library cache during execute: 1
Elapsed times include waiting on following events:
Event waited on Times Max. Wait Total Waited
---------------------------------------- Waited ---------- ------------
SQL*Net message to client 3002 0.00 0.00
SQL*Net message from client 3002 5.92 7.12
latch: library cache 4 0.00 0.00
log file sync 1 0.00 0.00
OVERALL TOTALS FOR ALL RECURSIVE STATEMENTS
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 69 0.00 0.00 0 0 0 0
Execute 17261 2.42 2.36 7 9042 6615 3160
Fetch 14000 0.38 0.37 0 93900 0 13899
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 31330 2.81 2.74 7 102942 6615 17059
Misses in library cache during parse: 10
Misses in library cache during execute: 10
Elapsed times include waiting on following events:
Event waited on Times Max. Wait Total Waited
---------------------------------------- Waited ---------- ------------
db file sequential read 7 0.00 0.00
We perform a very large number of requests and spend a lot of time on network interaction.
We use mass processing (temporary)
The most radical way to deal with overhead is the transition to mass processing. We can pre-save the data set for processing in some table, and then process the data not by one record, but all at once. Of course, for intermediate data storage, you can use regular tables, but using GTT for these purposes is more profitable, due to reduced overhead for logging.
To insert data into a temporary table, we will use DML, rather than calls to stored procedures, which will allow us to use JDBC batch to reduce network overhead.
When using this approach, it is not required that the interface name be processed before the rest of its parameters. It is enough that the names of all the processed interfaces are present in the processed data set.
PL / SQL code
CREATE OR REPLACE package AIS.ae_monitoring as
procedure saveValues;
end ae_monitoring;
/
CREATE OR REPLACE package body AIS.ae_monitoring as
g_ifName_parameter constant number default 103;
g_default_policy constant number default 1;
g_uptime_policy constant number default 2;
g_threshold_policy constant number default 3;
g_increase_type constant number default 1;
g_decrease_type constant number default 2;
g_delta_type constant number default 3;
procedure saveValues as
begin
-- Создать ресурс, если он отсутствует
merge into ae_resource d
using ( select t.id, t.device_id, t.num, t.value name, p.type_id, o.id owner_id
from ae_state_tmp t
inner join ae_profile_detail p on (p.profile_id = t.profile_id and p.param_id = t.param_id)
inner join ae_resource_type r on (r.id = p.type_id)
left join ae_resource o on (o.device_id = t.device_id and o.type_id = r.owner_id)
where t.param_id = g_ifName_parameter
) s
on ( d.device_id = s.device_id and d.res_num = s.num and d.type_id = s.type_id and
d.start_date <= sysdate and sysdate <= nvl(d.end_date, sysdate + 1) )
when matched then
update set d.tmp_id = s.id
where d.name <> s.name
when not matched then
insert (id, device_id, owner_id, type_id, res_num, name)
values (ae_resource_seq.nextval, s.device_id, s.owner_id, s.type_id, s.num, s.name);
-- Добавить недостающие ae_resource
insert into ae_resource(id, device_id, owner_id, type_id, res_num, name)
select ae_resource_seq.nextval, t.device_id, o.id, p.type_id, t.num, t.value
from ae_state_tmp t
inner join ae_resource c on (c.tmp_id = t.id)
inner join ae_profile_detail p on (p.profile_id = t.profile_id and p.param_id = t.param_id)
inner join ae_resource_type r on (r.id = p.type_id)
left join ae_resource o on (o.device_id = t.device_id and o.type_id = r.owner_id);
-- Закрыть устаревшие интерфейсы
update ae_resource set end_date = sysdate
, tmp_id = null
where tmp_id > 0;
-- Сохранить записи в ae_state_log
insert into ae_state_log(id, res_id, param_id, value)
select ae_state_log_seq.nextval, id, param_id, value
from ( select distinct r.id, t.param_id,
decode(l.type_id, g_uptime_policy, nvl(s.value, t.value), t.value) value
from ae_state_tmp t
inner join ae_profile_detail p on (p.profile_id = t.profile_id and p.param_id = t.param_id)
inner join ae_resource r on ( r.device_id = t.device_id and r.res_num = t.num and r.type_id = p.type_id and
r.start_date <= sysdate and sysdate <= nvl(r.end_date, sysdate + 1))
left join ae_state s on (s.res_id = r.id and s.param_id = t.param_id)
inner join ae_parameter a on (a.id = p.param_id)
inner join ae_domain d on (d.id = a.domain_id)
inner join ae_state_policy l on (l.id = d.policy_id)
left join ae_threshold h on (
h.policy_id = l.id and
(( h.type_id = g_increase_type and s.value <= h.value and t.value >= h.value ) or
( h.type_id = g_decrease_type and s.value >= h.value and t.value <= h.value ) or
( h.type_id = g_delta_type and abs(t.value - s.value) >= h.value )))
where ( s.id is null or not h.id is null
or ( l.type_id = g_uptime_policy and t.value < s.value )
or ( l.type_id = g_default_policy and t.value <> s.value ) )
and t.param_id <> g_ifName_parameter );
-- Обновить ae_state
merge into ae_state d
using ( select t.param_id, t.value, r.id res_id
from ae_state_tmp t
inner join ae_profile_detail p on (p.profile_id = t.profile_id and p.param_id = t.param_id)
inner join ae_resource r on ( r.device_id = t.device_id and r.res_num = t.num and r.type_id = p.type_id and
r.start_date <= sysdate and sysdate <= nvl(r.end_date, sysdate + 1))
where t.param_id <> g_ifName_parameter
) s
on (d.res_id = s.res_id and d.param_id = s.param_id)
when matched then
update set d.value = s.value
, d.datetime = current_timestamp
when not matched then
insert (id, param_id, res_id, value)
values (ae_state_seq.nextval, s.param_id, s.res_id, s.value);
-- Сохранить изменения
commit write nowait;
end;
end ae_monitoring;
/
Java code
private final static int BULK_SIZE = 200;
private final static String INS_VAL_SQL =
"insert into ae_state_tmp(id, device_id, profile_id, param_id, num, value) values (?,?,?,?,?,?)";
private final static String SAVE_VALUES_SQL =
"begin ae_monitoring.saveValues; end;";
private void test_temporary() throws SQLException {
System.out.println("test_temporary:");
CallableStatement st = c.prepareCall(INS_VAL_SQL);
Long timestamp = System.currentTimeMillis();
Long uptime = 0L;
Long inoct = 0L;
Long ix = 1L;
int bulk = BULK_SIZE;
try {
for (int i = 1; i <= ALL_SIZE; i++) {
// Передать uptime
st.setLong(1, ix++);
st.setLong(2, DEVICE_ID);
st.setLong(3, PROFILE_ID);
st.setLong(4, UPTIME_PARAM_ID);
st.setString(5, FAKE_NUM_VALUE);
st.setString(6, uptime.toString());
st.addBatch();
// Передать имя интерфейса
st.setLong(1, ix++);
st.setLong(2, DEVICE_ID);
st.setLong(3, PROFILE_ID);
st.setLong(4, IFNAME_PARAM_ID);
st.setString(5, Integer.toString((i % 100) + 1));
st.setString(6, Integer.toString((i % 100) + 1));
st.addBatch();
// Передать счетчик трафика
st.setLong(1, ix++);
st.setLong(2, DEVICE_ID);
st.setLong(3, PROFILE_ID);
st.setLong(4, INOCT_PARAM_ID);
st.setString(5, Integer.toString((i % 100) + 1));
st.setString(6, inoct.toString());
st.addBatch();
if (--bulk <= 0) {
st.executeBatch();
bulk = BULK_SIZE;
}
// Увеличить счетчики
uptime += 100L;
if (uptime >= 1000) {
uptime = 0L;
}
inoct += 10L;
}
if (bulk < BULK_SIZE) {
st.executeBatch();
}
} finally {
st.close();
}
Long delta_1 = System.currentTimeMillis() - timestamp;
System.out.println((ALL_SIZE * 1000L) / delta_1);
timestamp = System.currentTimeMillis();
st = c.prepareCall(SAVE_VALUES_SQL);
timestamp = System.currentTimeMillis();
try {
st.execute();
} finally {
st.close();
}
Long delta_2 = System.currentTimeMillis() - timestamp;
System.out.println(delta_2);
System.out.println((ALL_SIZE * 1000L) / (delta_1 - delta_2));
}
Run this code to execute and get:
java.sql.SQLException: ORA-30926: невозможно получить устойчивый набор строк в исходных таблицах
ORA-06512: на "AIS.AE_MONITORING", line 205
ORA-06512: на line 1
If you think about it, the reason for this error becomes clear. If the set of processed data contains conflicting data for some variable (we managed to read it several times), a problem arises. With the normal functioning of SNMP monitoring, this situation should not occur, but we must provide for something to prevent the application from crashing if it does occur.
The first thing that comes to mind is storing aggregated data for each variable. We will add a new record if it is not already or update an existing one, write a new value in it:
Java code
private final static int BULK_SIZE = 200;
private final static String MERGE_VAL_SQL =
"merge into ae_state_tmp d " +
"using ( select ? id,? device_id,? profile_id,? param_id,? num,? value " +
" from dual" +
" ) s " +
"on ( d.device_id = s.device_id and d.profile_id = s.profile_id and " +
" d.param_id = s.param_id and d.num = s.num ) " +
"when matched then " +
" update set d.value = s.value " +
"when not matched then " +
" insert (id, device_id, profile_id, param_id, num, value) " +
" values (s.id, s.device_id, s.profile_id, s.param_id, s.num, s.value)";
private final static String SAVE_VALUES_SQL =
"begin ae_monitoring.saveValues; end;";
private void test_temporary() throws SQLException {
System.out.println("test_temporary:");
CallableStatement st = c.prepareCall(MERGE_VAL_SQL);
...
Now we are dealing with the same problem, but at the stage of the batch request:
java.sql.BatchUpdateException: ORA-00600: код внутренней ошибки, аргументы: [6704], [2], [0], [6301696], [], [], [], [], [], [], [], []
I have to abandon batch:
private final static int BULK_SIZE = 1;
Results have improved markedly:
results
OVERALL TOTALS FOR ALL NON-RECURSIVE STATEMENTS
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 2 0.00 0.00 0 0 0 0
Execute 1001 1.02 1.01 0 9002 3503 3001
Fetch 0 0.00 0.00 0 0 0 0
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 1003 1.02 1.01 0 9002 3503 3001
Misses in library cache during parse: 1
Misses in library cache during execute: 1
Elapsed times include waiting on following events:
Event waited on Times Max. Wait Total Waited
---------------------------------------- Waited ---------- ------------
SQL*Net message to client 1002 0.00 0.00
SQL*Net message from client 1002 0.00 0.41
log file sync 1 0.00 0.00
OVERALL TOTALS FOR ALL RECURSIVE STATEMENTS
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 23 0.01 0.01 0 1 0 0
Execute 23 0.21 0.21 43 29392 348 111
Fetch 11 0.00 0.00 0 27 0 10
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 57 0.22 0.23 43 29420 348 121
Misses in library cache during parse: 8
Misses in library cache during execute: 6
Elapsed times include waiting on following events:
Event waited on Times Max. Wait Total Waited
---------------------------------------- Waited ---------- ------------
db file sequential read 41 0.01 0.01
db file scattered read 1 0.00 0.00
Alternative approach (distinct)
We can simplify our lives at the data insertion stage (at the same time getting rid of the ORA-600 feature) by adding grouping at the mass processing stage. In this case, we can not be shy with BULK_SIZE, setting it to the maximum.
PL / SQL code
CREATE OR REPLACE package AIS.ae_monitoring as
procedure saveValuesDistinct;
end ae_monitoring;
/
CREATE OR REPLACE package body AIS.ae_monitoring as
g_ifName_parameter constant number default 103;
g_default_policy constant number default 1;
g_uptime_policy constant number default 2;
g_threshold_policy constant number default 3;
g_increase_type constant number default 1;
g_decrease_type constant number default 2;
g_delta_type constant number default 3;
procedure saveValuesDistinct as
begin
-- Создать ресурс, если он отсутствует
merge into ae_resource d
using ( select t.id, t.device_id, t.num, t.value name, p.type_id, o.id owner_id
from ( select device_id, profile_id, param_id, num
, max(id) keep (dense_rank last order by datetime) id
, max(value) keep (dense_rank last order by datetime) value
, max(datetime) datetime
from ae_state_tmp
group by device_id, profile_id, param_id, num
) t
inner join ae_profile_detail p on (p.profile_id = t.profile_id and p.param_id = t.param_id)
inner join ae_resource_type r on (r.id = p.type_id)
left join ae_resource o on (o.device_id = t.device_id and o.type_id = r.owner_id)
where t.param_id = g_ifName_parameter
) s
on ( d.device_id = s.device_id and d.res_num = s.num and d.type_id = s.type_id and
d.start_date <= sysdate and sysdate <= nvl(d.end_date, sysdate + 1) )
when matched then
update set d.tmp_id = s.id
where d.name <> s.name
when not matched then
insert (id, device_id, owner_id, type_id, res_num, name)
values (ae_resource_seq.nextval, s.device_id, s.owner_id, s.type_id, s.num, s.name);
-- Добавить недостающие ae_resource
insert into ae_resource(id, device_id, owner_id, type_id, res_num, name)
select ae_resource_seq.nextval, t.device_id, o.id, p.type_id, t.num, t.value
from ( select device_id, profile_id, param_id, num
, max(id) keep (dense_rank last order by datetime) id
, max(value) keep (dense_rank last order by datetime) value
, max(datetime) datetime
from ae_state_tmp
group by device_id, profile_id, param_id, num
) t
inner join ae_resource c on (c.tmp_id = t.id)
inner join ae_profile_detail p on (p.profile_id = t.profile_id and p.param_id = t.param_id)
inner join ae_resource_type r on (r.id = p.type_id)
left join ae_resource o on (o.device_id = t.device_id and o.type_id = r.owner_id);
-- Закрыть устаревшие интерфейсы
update ae_resource set end_date = sysdate
, tmp_id = null
where tmp_id > 0;
-- Сохранить записи в ae_state_log
insert into ae_state_log(id, res_id, param_id, value)
select ae_state_log_seq.nextval, id, param_id, value
from ( select distinct r.id, t.param_id,
decode(l.type_id, g_uptime_policy, nvl(s.value, t.value), t.value) value
from ( select device_id, profile_id, param_id, num
, max(id) keep (dense_rank last order by datetime) id
, max(value) keep (dense_rank last order by datetime) value
, max(datetime) datetime
from ae_state_tmp
group by device_id, profile_id, param_id, num
) t
inner join ae_profile_detail p on (p.profile_id = t.profile_id and p.param_id = t.param_id)
inner join ae_resource r on ( r.device_id = t.device_id and r.res_num = t.num and r.type_id = p.type_id and
r.start_date <= sysdate and sysdate <= nvl(r.end_date, sysdate + 1))
left join ae_state s on (s.res_id = r.id and s.param_id = t.param_id)
inner join ae_parameter a on (a.id = p.param_id)
inner join ae_domain d on (d.id = a.domain_id)
inner join ae_state_policy l on (l.id = d.policy_id)
left join ae_threshold h on (
h.policy_id = l.id and
(( h.type_id = g_increase_type and s.value <= h.value and t.value >= h.value ) or
( h.type_id = g_decrease_type and s.value >= h.value and t.value <= h.value ) or
( h.type_id = g_delta_type and abs(t.value - s.value) >= h.value )))
where ( s.id is null or not h.id is null
or ( l.type_id = g_uptime_policy and t.value < s.value )
or ( l.type_id = g_default_policy and t.value <> s.value ) )
and t.param_id <> g_ifName_parameter );
-- Обновить ae_state
merge into ae_state d
using ( select t.param_id, t.value, r.id res_id
from ( select device_id, profile_id, param_id, num
, max(id) keep (dense_rank last order by datetime) id
, max(value) keep (dense_rank last order by datetime) value
, max(datetime) datetime
from ae_state_tmp
group by device_id, profile_id, param_id, num
) t
inner join ae_profile_detail p on (p.profile_id = t.profile_id and p.param_id = t.param_id)
inner join ae_resource r on ( r.device_id = t.device_id and r.res_num = t.num and r.type_id = p.type_id and
r.start_date <= sysdate and sysdate <= nvl(r.end_date, sysdate + 1))
where t.param_id <> g_ifName_parameter
) s
on (d.res_id = s.res_id and d.param_id = s.param_id)
when matched then
update set d.value = s.value
, d.datetime = current_timestamp
when not matched then
insert (id, param_id, res_id, value)
values (ae_state_seq.nextval, s.param_id, s.res_id, s.value);
-- Сохранить изменения
commit write nowait;
end;
end ae_monitoring;
/
Java code
private final static int BULK_SIZE = 200;
private final static String INS_VAL_SQL =
"insert into ae_state_tmp(id, device_id, profile_id, param_id, num, value) values (?,?,?,?,?,?)";
private final static String SAVE_VALUES_DISTINCT_SQL =
"begin ae_monitoring.saveValuesDistinct; end;";
private void test_temporary_distinct() throws SQLException {
System.out.println("test_temporary:");
CallableStatement st = c.prepareCall(INS_VAL_SQL);
Long timestamp = System.currentTimeMillis();
Long uptime = 0L;
Long inoct = 0L;
Long ix = 1L;
int bulk = BULK_SIZE;
try {
for (int i = 1; i <= ALL_SIZE; i++) {
// Передать uptime
st.setLong(1, ix++);
st.setLong(2, DEVICE_ID);
st.setLong(3, PROFILE_ID);
st.setLong(4, UPTIME_PARAM_ID);
st.setString(5, FAKE_NUM_VALUE);
st.setString(6, uptime.toString());
st.addBatch();
// Передать имя интерфейса
st.setLong(1, ix++);
st.setLong(2, DEVICE_ID);
st.setLong(3, PROFILE_ID);
st.setLong(4, IFNAME_PARAM_ID);
st.setString(5, Integer.toString((i % 100) + 1));
st.setString(6, Integer.toString((i % 100) + 1));
st.addBatch();
// Передать счетчик трафика
st.setLong(1, ix++);
st.setLong(2, DEVICE_ID);
st.setLong(3, PROFILE_ID);
st.setLong(4, INOCT_PARAM_ID);
st.setString(5, Integer.toString((i % 100) + 1));
st.setString(6, inoct.toString());
st.addBatch();
if (--bulk <= 0) {
st.executeBatch();
bulk = BULK_SIZE;
}
// Увеличить счетчики
uptime += 100L;
if (uptime >= 1000) {
uptime = 0L;
}
inoct += 10L;
}
if (bulk < BULK_SIZE) {
st.executeBatch();
}
} finally {
st.close();
}
Long delta_1 = System.currentTimeMillis() - timestamp;
System.out.println((ALL_SIZE * 1000L) / delta_1);
timestamp = System.currentTimeMillis();
st = c.prepareCall(SAVE_VALUES_DISTINCT_SQL);
timestamp = System.currentTimeMillis();
try {
st.execute();
} finally {
st.close();
}
Long delta_2 = System.currentTimeMillis() - timestamp;
System.out.println(delta_2);
System.out.println((ALL_SIZE * 1000L) / (delta_1 - delta_2));
}
Run and see the results:
results
OVERALL TOTALS FOR ALL NON-RECURSIVE STATEMENTS
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 2 0.00 0.00 0 0 0 0
Execute 1001 0.36 0.33 0 96 6616 3001
Fetch 0 0.00 0.00 0 0 0 0
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 1003 0.36 0.33 0 96 6616 3001
Misses in library cache during parse: 2
Misses in library cache during execute: 1
Elapsed times include waiting on following events:
Event waited on Times Max. Wait Total Waited
---------------------------------------- Waited ---------- ------------
SQL*Net message to client 1002 0.00 0.00
SQL*Net message from client 1002 0.00 0.41
log file sync 1 0.00 0.00
OVERALL TOTALS FOR ALL RECURSIVE STATEMENTS
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 30 0.01 0.01 0 3 0 0
Execute 30 0.41 0.40 3 48932 1104 218
Fetch 8 0.00 0.00 0 176 0 8
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 68 0.44 0.43 3 49111 1104 226
Misses in library cache during parse: 8
Misses in library cache during execute: 7
Elapsed times include waiting on following events:
Event waited on Times Max. Wait Total Waited
---------------------------------------- Waited ---------- ------------
db file sequential read 3 0.00 0.00
As expected, the cost of inserting data has decreased, but subsequent processing has become more complicated.
We use collections (collection)
As DenKrep rightly remarked , even with the lowest possible cost of inserting data, the GTT approach is very similar to the process of pouring from empty to empty. How else can we reduce the cost of networking? We cannot use JDBC batch to call PL / SQL code (or rather we can, but it will not bring any benefit), but we can pass arrays!
The process of passing arrays from Java code itself is well described in this guide. To transfer data, we need to determine the following types:
create or replace type ae_state_rec as object (
device_id number,
profile_id number,
param_id number,
num varchar2(300),
value varchar2(300)
)
/
create or replace type ae_state_tab as table of ae_state_rec;
/
Since I have Oracle Client 11g installed, I had to replace [ORACLE_HOME] /jdbc/lib/classes12.zip with [ORACLE_HOME] /jdbc/lib/ojdbc5.jar. Also, I want to emphasize that [ORACLE_HOME] /jdbc/lib/nls_charset12.zip should be available when the application starts, otherwise it will be impossible to transmit string values (there will be no errors, but NULL will be transmitted).
How will we process the array on the server? To get started, just try calling the addValue previously written in a loop:
...
procedure addValues( p_tab in ae_state_tab ) as
begin
for i in 1 .. p_tab.count loop
addValue( p_device => p_tab(i).device_id
, p_profile => p_tab(i).profile_id
, p_param => p_tab(i).param_id
, p_num => p_tab(i).num
, p_val => p_tab(i).value );
end loop;
commit write nowait;
end;
...
Java code is noticeably more complicated:
Java code
private final static String ADD_VALUES_SQL =
"begin ae_monitoring.addValues(?); end;";
private void test_collection() throws SQLException {
System.out.println("test_collection:");
OracleCallableStatement st = (OracleCallableStatement)c.prepareCall(ADD_VALUES_SQL);
int oracleId = CharacterSet.CL8MSWIN1251_CHARSET;
CharacterSet charSet = CharacterSet.make(oracleId);
Long timestamp = System.currentTimeMillis();
Long uptime = 0L;
Long inoct = 0L;
RecType r[] = new RecType[ALL_SIZE * 3];
int ix = 0;
for (int i = 1; i <= ALL_SIZE; i++) {
// Передать uptime
r[ix++] = new RecType(
new NUMBER(DEVICE_ID),
new NUMBER(PROFILE_ID),
new NUMBER(UPTIME_PARAM_ID),
new CHAR(FAKE_NUM_VALUE, charSet),
new CHAR(uptime.toString(), charSet));
// Передать имя интерфейса
r[ix++] = new RecType(
new NUMBER(DEVICE_ID),
new NUMBER(PROFILE_ID),
new NUMBER(IFNAME_PARAM_ID),
new CHAR(Integer.toString((i % 100) + 1), charSet),
new CHAR(Integer.toString((i % 100) + 1), charSet));
// Передать счетчик трафика
r[ix++] = new RecType(
new NUMBER(DEVICE_ID),
new NUMBER(PROFILE_ID),
new NUMBER(INOCT_PARAM_ID),
new CHAR(Integer.toString((i % 100) + 1), charSet),
new CHAR(inoct.toString(), charSet));
// Увеличить счетчики
uptime += 100L;
if (uptime >= 1000) {
uptime = 0L;
}
inoct += 10L;
}
RecTab t = new RecTab(r);
try {
st.setORAData(1, t);
st.execute();
} finally {
st.close();
}
System.out.println((ALL_SIZE * 1000L) / (System.currentTimeMillis() - timestamp));
}
Various funny operators appear in the trace related to the transfer of arrays from the client:
SELECT INSTANTIABLE, supertype_owner, supertype_name, LOCAL_ATTRIBUTES
FROM
all_types WHERE type_name = :1 AND owner = :2
The result is logical:
results
OVERALL TOTALS FOR ALL NON-RECURSIVE STATEMENTS
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 4 0.00 0.00 0 0 0 0
Execute 4 4.35 4.31 5 136053 6610 3
Fetch 1 0.00 0.00 0 9 0 1
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 9 4.35 4.31 5 136062 6610 4
Misses in library cache during parse: 2
Misses in library cache during execute: 2
Elapsed times include waiting on following events:
Event waited on Times Max. Wait Total Waited
---------------------------------------- Waited ---------- ------------
SQL*Net message to client 6 0.00 0.00
SQL*Net message from client 6 0.23 0.34
SQL*Net more data from client 41 0.00 0.00
OVERALL TOTALS FOR ALL RECURSIVE STATEMENTS
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 77 0.00 0.00 0 0 0 0
Execute 17270 2.97 2.92 5 6046 6610 3160
Fetch 14013 0.49 0.49 1 129930 0 13909
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 31360 3.48 3.43 6 135976 6610 17069
Misses in library cache during parse: 8
Misses in library cache during execute: 11
Elapsed times include waiting on following events:
Event waited on Times Max. Wait Total Waited
---------------------------------------- Waited ---------- ------------
db file sequential read 6 0.00 0.00
The indicators related to data transfer from the client have improved, but the data processing has become somewhat more complicated compared to the plsql option.
We use collections on clever (bulk)
Obviously, we are not fully utilizing the potential of arrays transmitted from the client. It would be nice to pass the array directly to SQL queries to enable bulk processing, but how to do it? We cannot use BULK COLLECT , because our queries are too complex for this. Fortunately, we can wrap the collection in TABLE :
PL / SQL code
CREATE OR REPLACE package AIS.ae_monitoring as
procedure saveValues( p_tab in ae_state_tab );
end ae_monitoring;
/
CREATE OR REPLACE package body AIS.ae_monitoring as
g_ifName_parameter constant number default 103;
g_default_policy constant number default 1;
g_uptime_policy constant number default 2;
g_threshold_policy constant number default 3;
g_increase_type constant number default 1;
g_decrease_type constant number default 2;
g_delta_type constant number default 3;
procedure saveValues( p_tab in ae_state_tab ) as
begin
-- Создать ресурс, если он отсутствует
merge into ae_resource d
using ( select t.device_id, t.num, t.value name, p.type_id, o.id owner_id
from ( select device_id, profile_id, param_id, num
, max(value) value
from table( p_tab )
group by device_id, profile_id, param_id, num
) t
inner join ae_profile_detail p on (p.profile_id = t.profile_id and p.param_id = t.param_id)
inner join ae_resource_type r on (r.id = p.type_id)
left join ae_resource o on (o.device_id = t.device_id and o.type_id = r.owner_id)
where t.param_id = g_ifName_parameter
) s
on ( d.device_id = s.device_id and d.res_num = s.num and d.type_id = s.type_id and
d.start_date <= sysdate and sysdate <= nvl(d.end_date, sysdate + 1) )
when not matched then
insert (id, device_id, owner_id, type_id, res_num, name)
values (ae_resource_seq.nextval, s.device_id, s.owner_id, s.type_id, s.num, s.name);
-- Сохранить записи в ae_state_log
insert into ae_state_log(id, res_id, param_id, value)
select ae_state_log_seq.nextval, id, param_id, value
from ( select distinct r.id, t.param_id,
decode(l.type_id, g_uptime_policy, nvl(s.value, t.value), t.value) value
from ( select device_id, profile_id, param_id, num
, max(value) value
from table( p_tab )
group by device_id, profile_id, param_id, num
) t
inner join ae_profile_detail p on (p.profile_id = t.profile_id and p.param_id = t.param_id)
inner join ae_resource r on ( r.device_id = t.device_id and r.res_num = t.num and r.type_id = p.type_id and
r.start_date <= sysdate and sysdate <= nvl(r.end_date, sysdate + 1))
left join ae_state s on (s.res_id = r.id and s.param_id = t.param_id)
inner join ae_parameter a on (a.id = p.param_id)
inner join ae_domain d on (d.id = a.domain_id)
inner join ae_state_policy l on (l.id = d.policy_id)
left join ae_threshold h on (
h.policy_id = l.id and
(( h.type_id = g_increase_type and s.value <= h.value and t.value >= h.value ) or
( h.type_id = g_decrease_type and s.value >= h.value and t.value <= h.value ) or
( h.type_id = g_delta_type and abs(t.value - s.value) >= h.value )))
where ( s.id is null or not h.id is null
or ( l.type_id = g_uptime_policy and t.value < s.value )
or ( l.type_id = g_default_policy and t.value <> s.value ) )
and t.param_id <> g_ifName_parameter );
-- Обновить ae_state
merge into ae_state d
using ( select t.param_id, t.value, r.id res_id
from ( select device_id, profile_id, param_id, num
, max(value) value
from table( p_tab )
group by device_id, profile_id, param_id, num
) t
inner join ae_profile_detail p on (p.profile_id = t.profile_id and p.param_id = t.param_id)
inner join ae_resource r on ( r.device_id = t.device_id and r.res_num = t.num and r.type_id = p.type_id and
r.start_date <= sysdate and sysdate <= nvl(r.end_date, sysdate + 1))
where t.param_id <> g_ifName_parameter
) s
on (d.res_id = s.res_id and d.param_id = s.param_id)
when matched then
update set d.value = s.value
, d.datetime = current_timestamp
when not matched then
insert (id, param_id, res_id, value)
values (ae_state_seq.nextval, s.param_id, s.res_id, s.value);
-- Сохранить изменения
commit write nowait;
end;
end ae_monitoring;
/
Java code
private final static String BULK_VALUES_SQL =
"begin ae_monitoring.saveValues(?); end;";
private void test_bulk() throws SQLException {
System.out.println("test_bulk:");
OracleCallableStatement st = (OracleCallableStatement)c.prepareCall(BULK_VALUES_SQL);
int oracleId = CharacterSet.CL8MSWIN1251_CHARSET;
CharacterSet charSet = CharacterSet.make(oracleId);
Long timestamp = System.currentTimeMillis();
Long uptime = 0L;
Long inoct = 0L;
RecType r[] = new RecType[ALL_SIZE * 3];
int ix = 0;
for (int i = 1; i <= ALL_SIZE; i++) {
// Передать uptime
r[ix++] = new RecType(
new NUMBER(DEVICE_ID),
new NUMBER(PROFILE_ID),
new NUMBER(UPTIME_PARAM_ID),
new CHAR(FAKE_NUM_VALUE, charSet),
new CHAR(uptime.toString(), charSet));
// Передать имя интерфейса
r[ix++] = new RecType(
new NUMBER(DEVICE_ID),
new NUMBER(PROFILE_ID),
new NUMBER(IFNAME_PARAM_ID),
new CHAR(Integer.toString((i % 100) + 1), charSet),
new CHAR(Integer.toString((i % 100) + 1), charSet));
// Передать счетчик трафика
r[ix++] = new RecType(
new NUMBER(DEVICE_ID),
new NUMBER(PROFILE_ID),
new NUMBER(INOCT_PARAM_ID),
new CHAR(Integer.toString((i % 100) + 1), charSet),
new CHAR(inoct.toString(), charSet));
// Увеличить счетчики
uptime += 100L;
if (uptime >= 1000) {
uptime = 0L;
}
inoct += 10L;
}
RecTab t = new RecTab(r);
try {
st.setORAData(1, t);
st.execute();
} finally {
st.close();
}
System.out.println((ALL_SIZE * 1000L) / (System.currentTimeMillis() - timestamp));
}
The result speaks for itself:
results
OVERALL TOTALS FOR ALL NON-RECURSIVE STATEMENTS
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 4 0.00 0.00 0 0 0 0
Execute 4 0.20 0.20 4 696 1095 3
Fetch 1 0.00 0.00 0 9 0 1
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 9 0.20 0.20 4 705 1095 4
Misses in library cache during parse: 0
Elapsed times include waiting on following events:
Event waited on Times Max. Wait Total Waited
---------------------------------------- Waited ---------- ------------
SQL*Net message to client 6 0.00 0.00
SQL*Net message from client 6 0.10 0.19
SQL*Net more data from client 41 0.00 0.00
OVERALL TOTALS FOR ALL RECURSIVE STATEMENTS
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 30 0.00 0.00 0 0 0 0
Execute 38 0.18 0.17 4 591 1095 217
Fetch 46 0.00 0.00 0 96 0 30
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 114 0.18 0.18 4 687 1095 247
Misses in library cache during parse: 7
Misses in library cache during execute: 7
Elapsed times include waiting on following events:
Event waited on Times Max. Wait Total Waited
---------------------------------------- Waited ---------- ------------
db file sequential read 4 0.00 0.00
conclusions
As the test results show, direct transfer of arrays to Oracle from the client code (bulk) allows you to achieve the best performance. Variants using GTT (temporary, distinct) are not much inferior to it in terms of performance, but much simpler from the point of view of Java code. The temporary option, in addition, makes it possible to observe the ORA-600 when using batch and the poor arrangement of stars.
Which approach to use for data processing is up to you. Test results are available on GitHub .