Nine-year-old router optimization
I want to tell the life story of the server on the campus network of Novosibirsk University, which began back in 2004, as well as the stages of its optimization and downgrading .
Many things in the article will seem well-known, if only for the reason that we will talk about events of almost a decade ago, although at that time they were advanced technologies. For the same reason, something has generally lost relevance, but not all, since the server still lives and maintains a grid of 1000 machines.
The network itself has existed since 1997 - this is the date when all the hostels were integrated into a single network and gained access to the Internet. Until 2004, the campus network was built entirely on copper, between dormitories the links were forwarded with a P270 cable (well, the distance between the dormitories did not exceed 350m, and the link, when using 3c905 cards, rose “on a hundred”). Each building had its own server, in which there were 3 network cards. Two of them “looked” at the neighboring servers, the “lokalka” of the hostel connected to the third. In total, all six (and there were so many hostels at our university) were closed in a ring, and the routes between them were built using the OSPF protocol, which made it possible to start traffic bypassing the dropped link when the line was broken. And clippings happened often: then a thunderstorm will break out and the link will break down, then electricians will cheat. And servicing the servers themselves was not very convenient,
The disadvantages of such an organization (in addition to the link that is very unreliable by today's standards) are obvious: it’s very inconvenient to manage the user base. The addresses are white, their number is limited. The contract was tied to IP “for life”, that is, for the entire duration of the student’s studies. The network is cut into segments, the sizes of which were originally made taking into account the number of students in each dormitory. But then students move from dorms to dorms, then the Faculty of Automation needed significantly more addresses than philologists - in general, horror.
Access restrictions were on a pair of MAC-IP, because at the time of the "conception" of the network, changing the MAC address of the network card without a programmer (or even a soldering iron) was very problematic, if not impossible. Therefore, it was enough to keep the / etc / ethers file up to date and save from 99% of freebie lovers. Managed switches in those days were only dreamed of, and it was impossible to afford to install them as subscriber equipment (since the network was developing 100% with the money of the students themselves, and students, as you know, are not rich)
In 2004, a good opportunity turned up: one of the city providers offered in exchange for peering between its network and the campus network to connect all the buildings optically for free. Well, how to connect - an initiative group of students was directly involved in the installation of optics, and the techies of the provider only boiled it. As a result, using this optics, it was possible to build not a ring, but a star!
And then the idea was born - to put one good server, with several gigabit network cards, connect all the links into one bridge and make one flat network, which would get rid of the headache with the address space cut into subnets, and also allow you to control access from one places.
Since the PCI bus could not pump such traffic, and the required 6-8 gigabit ports could not be obtained due to the lack of so many PCI connectors on the motherboards, it was decided to take 2x Intel Quad Port Server Adapter on the PCI-X 133Mhz bus. I had to take the Supermicro X6DHE-XG2 motherboard to these networks because of the presence of as many as three PCI-X 133, well, the processors on it, Xeon 3Ghz 2 pcs (these are those that can be found on ark.intel.com in the Legacy Xeon section)
and it started: RHELAS 2.1 is installed on the server, the bridge is started, the network is glued together into one large / 22. And then it turns out that if you restrict access to a couple of hundreds of addresses using rules like:
then loading on the server bounces to indecent values. Server does not cope?
A search on the Internet suggests only a project that then appeared - ipset . Yes, it turned out that this is exactly what you need. In addition to the fact that it was possible to get rid of a large number of similar entries in iptables, it became possible to bind IP-MAC using macipmap.
One of the features of the bridge was that a packet passing through the bridge in some cases fell into the FORWARD chain, but in some cases did not. It turned out that “routed” packets between interfaces get into FORWARD, and “bridged” packets (that is, those entering br0 immediately exiting br0) do not.
The solution was to use the mangle table instead of filter.
It also happened to bind a specific address not only to the MAC, but also to the hostel in which the network user lived. It was done using the iptables physdev module and looked something like this:
Since the optical “star” was built using optoconverters, its own network card “looked” at each building. And it was necessary to add only MAC-IP pairs of users of the first hostel to the IPMAC_H1 set, to the second hostel to the IPMAC_H2 set, and so on.
I tried to make the order of the rules themselves inside iptables so that those rules describing hostels where users are more active were higher, which allowed packets to go through chains faster.
Since, as a result, all intercommunity and external traffic eventually began to go through the server, the idea came up if the subscriber is disconnected, or if the IP-MAC pair doesn’t match, display a user with a page with information explaining why, in fact, the network does not work. It seemed that it is not difficult. Instead of DROP packets going to port 80, you had to make a MARK packet, and then redirect the marked packets using DNAT to the local web server.
The first problem turned out to be that if you simply redirect packages to a web server, the web server in 99% of cases responds that the page was not found. Because if the user was going to ark.intel.com/products/27100, and you wrapped it on your web server, it is unlikely that there will be a products / 27100 page, and at best you will get a 404 error. Therefore, a simple daemon was written in C, which issued any request. Later
this crutch was replaced with more beautiful solution with mod_rewrite.
The second, and most significant, problem was that as soon as the nat module was loaded into the kernel, the load jumped again. Of course, the conntrack table is to blame, and with so many connections and pps, the existing iron did not take out during peak hours.
Server does not cope?
Start to think. The goal is quite interesting, but does not work on existing hardware. Using
it simply changed the gateway address and sent the packet further, bypassing the rest of the chains.
In general, it was very convenient to send "objectionable" packets in this way for processing to a third-party server, without worrying about passing through the remaining chains of the filter type, but with a change in the kernel architecture, this patch from patch-o-matic became unsupported.
Solution: mark the necessary packets with 0x1, then, using ip rule fw, send the packet to the “other” routing table, where the only route is our server with NAT
As a result, “good” traffic was skipped, and “bad” users were shown a page with information about blocking. And also, in case of IP-MAC mismatch, the user could enter the login / password to re-bind to his current MAC.
The action takes place during megabyte traffic, in a hostel. That is, in a non-cash, online-active and IT-advanced user environment. This means that a simple IP-MAC binding is no longer enough, and cases of theft of Internet traffic are becoming widespread.
The only sane option is vpn. But, given that by that time the campus network had free peering with half a dozen city operators, it would not work to drive peer-to-peer traffic through a vpn server, it simply could not be taken out. Of course, a method that became widespread was possible: on the Internet - via vpn, to peering and LAN - a batch file with routes. But the batch file seemed to me a very ugly decision. We considered the option with RIPv2, which at that time was “built-in” in most operating systems, but there remained an open question with the authenticity of the announcements. Without additional configuration, anyone could send routes, and in the then-popular WindowXP and its "RIP Listener" there was no configuration at all.
Then the "asymmetric VPN" was "invented." To access the Internet, the client establishes a normal vpn-pptp connection to the server with a username / password, while unchecking "Use a gateway on a remote network" in the settings. The address 192.0.2.2 was issued to the client end of the tunnel, and all clients had the same address, and as will be shown later, it had no significance at all.
On the VPN server side, the / etc / ppp / ip-up script was modified, which is executed after authentication and raising the interface
That is, the IP address that the user with PEERNAME (the login with which he connected) is pulled from the database into the PEERIP variable from the database, and if this address matches the IP from which the connection (LOGDEVICE) to the VPN server was established, then all traffic to this IP is routed to the IFNAME interface through table 101. Also, in the table 101, the default gateway is set to 127.0.0.1
All routed traffic is wrapped in table 101 as a rule.
As a result, we get that the traffic that came to the vpn server and the next one to NOT vpn server (that will go to the local table, which will st by default) goes to table 101. And there it will “spread out” over ppp tunnels. And if he does not find the right one, then he will simply drop.
An example of what results in the plate 101 (ip r sh ta 101)
Now all that remains is to wrap up all the traffic from the "Internet" interface to the vpn gateway on the central router, and users will not have Internet access without connecting to a VPN. Moreover, the rest of the traffic (peer-to-peer) will run IPoE (that is, the “usual" way), and will not load the VPN server. When additional peer-to-peer networks appear, the user does not have to edit any bat-files. Again, access to some internal resources, at least IP, at least ports, can be done via VPN, just wrap the packet on the VPN server.
Using this technique, an attacker can certainly send traffic to the Internet by substituting IP-MAC, but can’t get anything back, since the vpn tunnel has not been raised. What almost completely kills the meaning of the substitution - now you can’t “sit on the Internet” from someone else’s IP.
In order for client computers to be able to receive packets through the vpn tunnel, it was necessary to set the IPEnableRouter = 1 key in the registry in Windows, and rp_filter = 0 in linux. Otherwise, the OS did not accept responses not from the interfaces where the requests were sent.
The implementation costs are almost zero, for ~ 700 simultaneous connections to vpn havatlo server level celeron 2Ghz, since the Internet traffic inside ppp at the time of megabyte tariffs was not very large. At the same time, peer-to-peer traffic ran at speeds up to 6 Gbit / s in total (via Xeon on S604)
This miracle worked for about 8 years. In 2006, RHELAS 2.1 was replaced by the freshly released CentOS 4. The central switches in the buildings were changed to DES-3028, the DES-1024 remained subscriber. Access control on the DES-3028 did not work out properly. In order to bind ip-mac to the port using the ACL, 256 entries were missing, because in some hostels there were more than 300 computers. Changing equipment became a problem, since the university “legalized” the network, and now it was necessary to pay for it at the university’s cash desk, no money was allocated for equipment back, and if it was allocated, it was very sparing, a year later and through a competition (when they don’t buy what you need, and what’s cheaper, or where the rollback is more).
And then the server broke down. Rather, the motherboard burned out (according to the conclusion from the workshop - the north bridge died). Need to collect something to replace, no money. That is, it would be nice for free. And so that you can insert the PCI-X network. Fortunately, my friend was returning a server written off from the bank, it just had a couple of PCI-X 133 slots. But the motherboard is single-processor, and it does not have Xeon, but Socket 478 Pentium 4 3Ghz
Throw screws, network cards. We start - it seems to work.
But softirq “eats” 90% of the total of two pseudo-nuclei (there is one core in the processor, and hypertreading is enabled), ping jumps to 3000, even the console “dies” to impossibility.
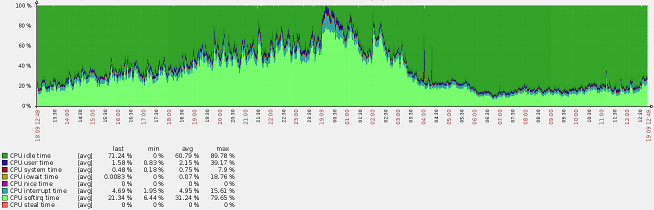
It would seem here it is, the server is out of date, it's time to rest.
Armed with oprofile, I begin to "cough up the excess." In general, oprofile in the process of "communication" with this server was used quite often, and more than once it helped out. For example, even using ipset I try to use ipmap, not iphash (if possible), since with oprofile you can really see how much the difference in performance is. According to my data, it turned out two orders of magnitude, that is, it sailed from 200 to 400 times. Also, when calculating traffic at different times, I switched from ipcad-ulog to ipcad-pcap, and then to nflow, focusing on profiling. I didn’t use ipt_NETFLOW anymore, so we entered the age of “unlimited Internet”, and our netflow top-level provider for SORM writes there or not - its problems. Actually, using oprofile, it was revealed that ip_conntrack was the main resource eater when nat was turned on.
In general, oprofile this time tells me that 60% of the processor cycles are occupied by the e1000 kernel module (network card). Well what to do with it? Recommended in e1000.txt
entered in 2005.
A quick look at git.kernel.org/cgit/linux/kernel/git/stable/linux-stable.git for any significant changes in e1000 did not produce results (that is, of course there are changes, but either bug fixes or spaces in code). Just in case, the kernel still updated, but it did not produce results.
The core also stands
Oprofile also states that the bridge module takes up a fairly large proportion of the cycles. And, it would seem, nowhere without it, since the IP addresses are spread in a mess over several buildings, and it is no longer possible to split them into segments (the option to combine everything into one segment without a server is not considered, since control is lost)
I think Break the bridge, and use proxy_arp. Moreover, I wanted to do this for a long time, after detecting bugs in DES-3028 with flood_fdb. In principle, it is possible to load all addresses into the routing table in the form:
because it is known which subscriber should be where (stored in the database)
But I also wanted to implement IP-MAC binding not only to the building, but also to the port of the host switch on the building (I repeat, there are uncontrolled DES-1024 type subscribers)
And here hands get to deal with dhcp-relay and dhcp-snooping.
On switches included:
On the server, I removed the interfaces from the bridge, removed the IP addresses on them (interfaces without IP), enabled arp_proxy
Configuring isc-dhcp
In the dhcp-event file, the agent.circuit-id, agent.remote-id, IP and MAC are checked for validity, and if everything is ok, then the route is added to this address through the desired interface.
Primitive dhcp-event example:
only $ ARGV [3] is checked here (that is, agent.remote-id, or the MAC of the switch through which the DHCP request was received), but you can also check all the other fields by receiving their valid values, for example, from the database
As a result, we get :
1) the client that did not request the address via DHCP - does not go beyond its unmanaged switch, IP-MAC-PORT-BINDING does not let it through;
2) a client whose MAC is known (is in the database), but the request does not match the port or switch - will receive an IP bound to this MAC, but the route to it will not be added, accordingly proxy_arp will “answer” that the address is already taken, and the address will be immediately released;
3) a client whose MAC is not known will receive an address from the temporary pool. From these addresses there is a redirection to a page with information, here you can also re-register your MAC using login / password;
4) and finally, the client whose MAC is known and matches the connection to the switch and port will receive its address. Dhcp-snooping will add dynamic binding to the impb table on the switch, the server will add a route to this address through the desired interface of the former bridge.
At the end of the lease or release of the address, the script / etc / dhcp / dhcp-release is called, the contents of which are very primitive:
There is a small security flaw, specifically in paragraph 2. If you use a non-standard dhcp-client, which does not check if the address provided by the dhcp server is busy, then the address will not be released. Of course, the user will not have access to an external network beyond the router, since the server will not add a route to this address through the desired interface, but the switch will unlock this MAC-IP pair on its port.
You can get around this flaw using the classes in dhcpd.conf, but this significantly complicates the configuration file, and, accordingly, increases the load on our old server. Because for each subscriber you will have to create your own class, with a rather difficult condition for getting into it, and then your own pool. Although there are plans to try in practice how much this will increase the load.
Thus, it turned out that the correspondence of the IP-MAC pair is now “monitored” by DHCP when issuing the address, access from the “invalid” MAC-IP is limited by the switch. Now it was possible to remove not only bridge but also macipmap from the server, replacing 6 sets (from "Optimization 1") with one ipmap, which contains all public IP addresses. And also by removing -m physdev.
Server interfaces also switched from promisc mode to normal, which also slightly reduced the load.
Namely, this whole procedure with disassembling the bridge reduced the overall load on the server by almost 2 times ! Softirq is now not 50-100%, but 25-50%. At the same time, access control to the network only got better.
After the last optimization, although the load dropped noticeably, a strange thing was noticed: iowait increased. Not that much, from 0-0.3% to 5-7%. This is taking into account the fact that there are practically no any disk operations on this server - it just throws packets.
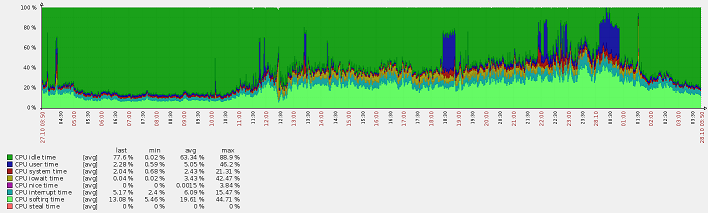
(blue user time - kernel compilation)
iostat showed that there is a constant load on the disk in 800-820 Blk_wrtn / s
Started searching for processes that could write. Performance
gave a strange result: the culprits were
Ext3 is in mode
I started to scroll through the steps in my head, what I was doing and what could affect iowait. As a result, I stopped syslog - and iowait dropped sharply to ~ 0%.
To prevent dhcp from cluttering messages with my messages, I sent them to log-facility local6, and wrote in syslog.conf:
it turned out that when writing via syslog, sync is done for each line. There are quite a lot of requests to the dhcp server, a lot of events are generated that get to the log, and a lot of sync is called.
Fix on
iowait reduced in my case 10-100 times, instead of 5-7% it became 0-0.3%
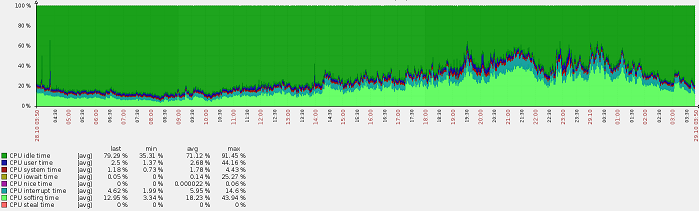
Optimization result:
Why this article.
Firstly, maybe someone will draw from it useful solutions for themselves. I didn’t discover America here, although most of the events described here were in the pre-Guban era, and “googling recipes” didn’t help much, I got it all with my own head.
Secondly, we constantly have to deal with the fact that instead of optimizing the code, developers are engaged in increasing computing power, and this article can be an example of the fact that, if you wish, you can find errors in your seemingly many times tested code and manage them . 90% of site developers check the work of the site on their machine, put it into production. Then the whole thing slows down under load. Teasing admin server. By optimizing the server in this case, little can be achieved if the code is originally written not optimally. And a new server is bought, or another server and balancer. Then the balancer of the balancer and so on. And the code inside was not optimal, and remains forever. Of course, I understand that in the current realities, code optimization is more expensive than extensive capacity building,
From the nostalgic: I have on the shelf an old laptop, P3-866 2001 (Panasonic CF-T1 if someone says something to this), but now it’s impossible to even look at sites on it, although there has been no more sense on these sites over 10 years. With love, I recall interesting toys on the ZX-Spectrum in terms of gameplay not inferior to today's monsters requiring 4 cores / 4 gig
Many things in the article will seem well-known, if only for the reason that we will talk about events of almost a decade ago, although at that time they were advanced technologies. For the same reason, something has generally lost relevance, but not all, since the server still lives and maintains a grid of 1000 machines.
Network
The network itself has existed since 1997 - this is the date when all the hostels were integrated into a single network and gained access to the Internet. Until 2004, the campus network was built entirely on copper, between dormitories the links were forwarded with a P270 cable (well, the distance between the dormitories did not exceed 350m, and the link, when using 3c905 cards, rose “on a hundred”). Each building had its own server, in which there were 3 network cards. Two of them “looked” at the neighboring servers, the “lokalka” of the hostel connected to the third. In total, all six (and there were so many hostels at our university) were closed in a ring, and the routes between them were built using the OSPF protocol, which made it possible to start traffic bypassing the dropped link when the line was broken. And clippings happened often: then a thunderstorm will break out and the link will break down, then electricians will cheat. And servicing the servers themselves was not very convenient,
The disadvantages of such an organization (in addition to the link that is very unreliable by today's standards) are obvious: it’s very inconvenient to manage the user base. The addresses are white, their number is limited. The contract was tied to IP “for life”, that is, for the entire duration of the student’s studies. The network is cut into segments, the sizes of which were originally made taking into account the number of students in each dormitory. But then students move from dorms to dorms, then the Faculty of Automation needed significantly more addresses than philologists - in general, horror.
Access restrictions were on a pair of MAC-IP, because at the time of the "conception" of the network, changing the MAC address of the network card without a programmer (or even a soldering iron) was very problematic, if not impossible. Therefore, it was enough to keep the / etc / ethers file up to date and save from 99% of freebie lovers. Managed switches in those days were only dreamed of, and it was impossible to afford to install them as subscriber equipment (since the network was developing 100% with the money of the students themselves, and students, as you know, are not rich)
Star
In 2004, a good opportunity turned up: one of the city providers offered in exchange for peering between its network and the campus network to connect all the buildings optically for free. Well, how to connect - an initiative group of students was directly involved in the installation of optics, and the techies of the provider only boiled it. As a result, using this optics, it was possible to build not a ring, but a star!
And then the idea was born - to put one good server, with several gigabit network cards, connect all the links into one bridge and make one flat network, which would get rid of the headache with the address space cut into subnets, and also allow you to control access from one places.
Since the PCI bus could not pump such traffic, and the required 6-8 gigabit ports could not be obtained due to the lack of so many PCI connectors on the motherboards, it was decided to take 2x Intel Quad Port Server Adapter on the PCI-X 133Mhz bus. I had to take the Supermicro X6DHE-XG2 motherboard to these networks because of the presence of as many as three PCI-X 133, well, the processors on it, Xeon 3Ghz 2 pcs (these are those that can be found on ark.intel.com in the Legacy Xeon section)
and it started: RHELAS 2.1 is installed on the server, the bridge is started, the network is glued together into one large / 22. And then it turns out that if you restrict access to a couple of hundreds of addresses using rules like:
iptables -A FORWARD -s a.b.c.d -j REJECTthen loading on the server bounces to indecent values. Server does not cope?
Optimization 1
A search on the Internet suggests only a project that then appeared - ipset . Yes, it turned out that this is exactly what you need. In addition to the fact that it was possible to get rid of a large number of similar entries in iptables, it became possible to bind IP-MAC using macipmap.
One of the features of the bridge was that a packet passing through the bridge in some cases fell into the FORWARD chain, but in some cases did not. It turned out that “routed” packets between interfaces get into FORWARD, and “bridged” packets (that is, those entering br0 immediately exiting br0) do not.
The solution was to use the mangle table instead of filter.
It also happened to bind a specific address not only to the MAC, but also to the hostel in which the network user lived. It was done using the iptables physdev module and looked something like this:
iptables -t mangle -A PREROUTING -m physdev --physdev-in eth1 -m set --set IPMAC_H1 src -j ACCEPT
iptables -t mangle -A PREROUTING -m physdev --physdev-in eth2 -m set --set IPMAC_H2 src -j ACCEPT
...
iptables -t mangle -A PREROUTING -i br0 -j DROP
Since the optical “star” was built using optoconverters, its own network card “looked” at each building. And it was necessary to add only MAC-IP pairs of users of the first hostel to the IPMAC_H1 set, to the second hostel to the IPMAC_H2 set, and so on.
I tried to make the order of the rules themselves inside iptables so that those rules describing hostels where users are more active were higher, which allowed packets to go through chains faster.
Optimization 2
Since, as a result, all intercommunity and external traffic eventually began to go through the server, the idea came up if the subscriber is disconnected, or if the IP-MAC pair doesn’t match, display a user with a page with information explaining why, in fact, the network does not work. It seemed that it is not difficult. Instead of DROP packets going to port 80, you had to make a MARK packet, and then redirect the marked packets using DNAT to the local web server.
The first problem turned out to be that if you simply redirect packages to a web server, the web server in 99% of cases responds that the page was not found. Because if the user was going to ark.intel.com/products/27100, and you wrapped it on your web server, it is unlikely that there will be a products / 27100 page, and at best you will get a 404 error. Therefore, a simple daemon was written in C, which issued any request. Later
Location: myserverruthis crutch was replaced with more beautiful solution with mod_rewrite.
The second, and most significant, problem was that as soon as the nat module was loaded into the kernel, the load jumped again. Of course, the conntrack table is to blame, and with so many connections and pps, the existing iron did not take out during peak hours.
Server does not cope?
Start to think. The goal is quite interesting, but does not work on existing hardware. Using
-t raw -j NOTRACKhelped, but not much. The solution was this: NAT packets not on the central router, but on one of the old machines that still remained and were used for various services such as a p2p server, game server, jabber server, or even simply idle ones. In the event of a surge in load on this server, in the worst case, the subscriber would not receive a message in the browser window that he was disconnected (or that his IP does not match the registered MAC), and this would not affect the work of other network users. And in order to deliver user traffic to this server with NAT, the following command was used: iptables -t mangle -A POSTROUTING -p tcp --dport 80 -j ROUTE --gw a.b.c.dit simply changed the gateway address and sent the packet further, bypassing the rest of the chains.
In general, it was very convenient to send "objectionable" packets in this way for processing to a third-party server, without worrying about passing through the remaining chains of the filter type, but with a change in the kernel architecture, this patch from patch-o-matic became unsupported.
Solution: mark the necessary packets with 0x1, then, using ip rule fw, send the packet to the “other” routing table, where the only route is our server with NAT
iptables -t mangle -A PREROUTING -p tcp --dport 80 -j MARK --set-mark 0x1
ip route flush table 100
ip route add via a.b.c.d table 100
ip rule add fwmark 0x1 lookup 100
As a result, “good” traffic was skipped, and “bad” users were shown a page with information about blocking. And also, in case of IP-MAC mismatch, the user could enter the login / password to re-bind to his current MAC.
Optimization 3
The action takes place during megabyte traffic, in a hostel. That is, in a non-cash, online-active and IT-advanced user environment. This means that a simple IP-MAC binding is no longer enough, and cases of theft of Internet traffic are becoming widespread.
The only sane option is vpn. But, given that by that time the campus network had free peering with half a dozen city operators, it would not work to drive peer-to-peer traffic through a vpn server, it simply could not be taken out. Of course, a method that became widespread was possible: on the Internet - via vpn, to peering and LAN - a batch file with routes. But the batch file seemed to me a very ugly decision. We considered the option with RIPv2, which at that time was “built-in” in most operating systems, but there remained an open question with the authenticity of the announcements. Without additional configuration, anyone could send routes, and in the then-popular WindowXP and its "RIP Listener" there was no configuration at all.
Then the "asymmetric VPN" was "invented." To access the Internet, the client establishes a normal vpn-pptp connection to the server with a username / password, while unchecking "Use a gateway on a remote network" in the settings. The address 192.0.2.2 was issued to the client end of the tunnel, and all clients had the same address, and as will be shown later, it had no significance at all.
On the VPN server side, the / etc / ppp / ip-up script was modified, which is executed after authentication and raising the interface
PATH=/sbin:/usr/sbin:/bin:/usr/bin
export PATH
LOGDEVICE=$6
REALDEVICE=$1
[ -f /etc/sysconfig/network-scripts/ifcfg-${LOGDEVICE} ] && /etc/sysconfig/network-scripts/ifup-post ifcfg-${LOGDEVICE}
[ -x /etc/ppp/ip-up.local ] && /etc/ppp/ip-up.local "$@"
PEERIP=`/usr/local/bin/getip.pl $PEERNAME`
if [ $LOGDEVICE == $PEERIP ] ; then
ip ro del $PEERIP table vpn > /dev/null 2>/dev/null&
ip ro add $PEERIP dev $IFNAME table 101
else
ifconfig $IFNAME down
kill $PPPD_PID
fi
exit 0
That is, the IP address that the user with PEERNAME (the login with which he connected) is pulled from the database into the PEERIP variable from the database, and if this address matches the IP from which the connection (LOGDEVICE) to the VPN server was established, then all traffic to this IP is routed to the IFNAME interface through table 101. Also, in the table 101, the default gateway is set to 127.0.0.1
All routed traffic is wrapped in table 101 as a rule.
ip ru add iif eth0 lookup 101As a result, we get that the traffic that came to the vpn server and the next one to NOT vpn server (that will go to the local table, which will st by default) goes to table 101. And there it will “spread out” over ppp tunnels. And if he does not find the right one, then he will simply drop.
An example of what results in the plate 101 (ip r sh ta 101)
[root@vpn ~]# ip route show table 101
a.b.c.d dev ppp2 scope link
a.b.c.e dev ppp6 scope link
a.b.c.f dev ppp1 scope link
default via 127.0.0.1 dev lo
Now all that remains is to wrap up all the traffic from the "Internet" interface to the vpn gateway on the central router, and users will not have Internet access without connecting to a VPN. Moreover, the rest of the traffic (peer-to-peer) will run IPoE (that is, the “usual" way), and will not load the VPN server. When additional peer-to-peer networks appear, the user does not have to edit any bat-files. Again, access to some internal resources, at least IP, at least ports, can be done via VPN, just wrap the packet on the VPN server.
Using this technique, an attacker can certainly send traffic to the Internet by substituting IP-MAC, but can’t get anything back, since the vpn tunnel has not been raised. What almost completely kills the meaning of the substitution - now you can’t “sit on the Internet” from someone else’s IP.
In order for client computers to be able to receive packets through the vpn tunnel, it was necessary to set the IPEnableRouter = 1 key in the registry in Windows, and rp_filter = 0 in linux. Otherwise, the OS did not accept responses not from the interfaces where the requests were sent.
The implementation costs are almost zero, for ~ 700 simultaneous connections to vpn havatlo server level celeron 2Ghz, since the Internet traffic inside ppp at the time of megabyte tariffs was not very large. At the same time, peer-to-peer traffic ran at speeds up to 6 Gbit / s in total (via Xeon on S604)
Works
This miracle worked for about 8 years. In 2006, RHELAS 2.1 was replaced by the freshly released CentOS 4. The central switches in the buildings were changed to DES-3028, the DES-1024 remained subscriber. Access control on the DES-3028 did not work out properly. In order to bind ip-mac to the port using the ACL, 256 entries were missing, because in some hostels there were more than 300 computers. Changing equipment became a problem, since the university “legalized” the network, and now it was necessary to pay for it at the university’s cash desk, no money was allocated for equipment back, and if it was allocated, it was very sparing, a year later and through a competition (when they don’t buy what you need, and what’s cheaper, or where the rollback is more).
The server is broken
And then the server broke down. Rather, the motherboard burned out (according to the conclusion from the workshop - the north bridge died). Need to collect something to replace, no money. That is, it would be nice for free. And so that you can insert the PCI-X network. Fortunately, my friend was returning a server written off from the bank, it just had a couple of PCI-X 133 slots. But the motherboard is single-processor, and it does not have Xeon, but Socket 478 Pentium 4 3Ghz
Throw screws, network cards. We start - it seems to work.
But softirq “eats” 90% of the total of two pseudo-nuclei (there is one core in the processor, and hypertreading is enabled), ping jumps to 3000, even the console “dies” to impossibility.
It would seem here it is, the server is out of date, it's time to rest.
Optimization 4
Armed with oprofile, I begin to "cough up the excess." In general, oprofile in the process of "communication" with this server was used quite often, and more than once it helped out. For example, even using ipset I try to use ipmap, not iphash (if possible), since with oprofile you can really see how much the difference in performance is. According to my data, it turned out two orders of magnitude, that is, it sailed from 200 to 400 times. Also, when calculating traffic at different times, I switched from ipcad-ulog to ipcad-pcap, and then to nflow, focusing on profiling. I didn’t use ipt_NETFLOW anymore, so we entered the age of “unlimited Internet”, and our netflow top-level provider for SORM writes there or not - its problems. Actually, using oprofile, it was revealed that ip_conntrack was the main resource eater when nat was turned on.
In general, oprofile this time tells me that 60% of the processor cycles are occupied by the e1000 kernel module (network card). Well what to do with it? Recommended in e1000.txt
options e1000 RxDescriptors=4096,4096,4096,4096,4096,4096,4096,4096,4096,4096 TxDescriptors=4096,4096,4096,4096,4096,4096,4096,4096,4096,4096 InterruptThrottleRate=3000,3000,3000,3000,3000,3000,3000,3000,3000,3000entered in 2005.
A quick look at git.kernel.org/cgit/linux/kernel/git/stable/linux-stable.git for any significant changes in e1000 did not produce results (that is, of course there are changes, but either bug fixes or spaces in code). Just in case, the kernel still updated, but it did not produce results.
The core also stands
CONFIG_HZ_100=y, with a larger value, the results are even worse.Oprofile also states that the bridge module takes up a fairly large proportion of the cycles. And, it would seem, nowhere without it, since the IP addresses are spread in a mess over several buildings, and it is no longer possible to split them into segments (the option to combine everything into one segment without a server is not considered, since control is lost)
I think Break the bridge, and use proxy_arp. Moreover, I wanted to do this for a long time, after detecting bugs in DES-3028 with flood_fdb. In principle, it is possible to load all addresses into the routing table in the form:
ip route add a.b.c1.d1 dev eth1 src 1.2.3.4
ip route add a.b.c1.d2 dev eth1 src 1.2.3.4
...
ip route add a.b.c2.d1 dev eth2 src 1.2.3.4
ip route add a.b.c2.d2 dev eth2 src 1.2.3.4
...
because it is known which subscriber should be where (stored in the database)
But I also wanted to implement IP-MAC binding not only to the building, but also to the port of the host switch on the building (I repeat, there are uncontrolled DES-1024 type subscribers)
And here hands get to deal with dhcp-relay and dhcp-snooping.
On switches included:
enable dhcp_relay
config dhcp_relay option_82 state enable
config dhcp_relay option_82 check enable
config dhcp_relay option_82 policy replace
config dhcp_relay option_82 remote_id default
config dhcp_relay add ipif System 10.160.8.1
enable address_binding dhcp_snoop
enable address_binding trap_log
config address_binding ip_mac ports 1-28 mode acl stop_learning_threshold 500
config address_binding ip_mac ports 1-24 state enable strict allow_zeroip enable forward_dhcppkt enable
config address_binding dhcp_snoop max_entry ports 1-24 limit no_limit
config filter dhcp_server ports 1-24 state enable
config filter dhcp_server ports 25-28 state disable
config filter dhcp_server trap_log enable
config filter dhcp_server illegal_server_log_suppress_duration 1min
On the server, I removed the interfaces from the bridge, removed the IP addresses on them (interfaces without IP), enabled arp_proxy
Configuring isc-dhcp
log-facility local6;
ddns-update-style none;
authoritative;
use-host-decl-names on;
default-lease-time 300;
max-lease-time 600;
get-lease-hostnames on;
option domain-name "myserver.ru";
option ntp-servers myntp.ru;
option domain-name-servers mydnsp-ip;
local-address 10.160.8.1;
include "/etc/dhcp-hosts"; #здесь лежат привязки MAC-IP в виде "host hostname {hardware ethernet AA:BB:CC:55:92:A4; fixed-address w.x.y.z;}"
on release {
set ClientIP = binary-to-ascii(10, 8, ".", leased-address);
log(info, concat("***** release IP " , ClientIP));
execute("/etc/dhcp/dhcp-release", ClientIP);
}
on expiry {
set ClientIP = binary-to-ascii(10, 8, ".", leased-address);
log(info, concat("***** expiry IP " , ClientIP));
execute("/etc/dhcp/dhcp-release", ClientIP);
}
on commit {
if exists agent.remote-id {
set ClientIP = binary-to-ascii(10, 8, ".", leased-address);
set ClientMac = binary-to-ascii(16, 8, ":", substring(hardware, 1, 6));
set ClientPort = binary-to-ascii(10,8,"",suffix(option agent.circuit-id,1));
set ClientSwitch = binary-to-ascii(16,8,":",substring(option agent.remote-id,2,6));
log(info, concat("***** IP: " , ClientIP, " Mac: ", ClientMac, " Port: ",ClientPort, " Switch: ",ClientSwitch));
execute("/etc/dhcp/dhcp-event", ClientIP, ClientMac, ClientPort, ClientSwitch);
}
}
option space microsoft; #не нужена нам микрософ-сеть
option microsoft.disable-netbios-over-tcpip code 1 = unsigned integer 32;
if substring(option vendor-class-identifier, 0, 4) = "MSFT" {
vendor-option-space microsoft;
}
shared-network HOSTEL {
subnet 10.160.0.0 netmask 255.255.248.0 {
range 10.160.0.1 10.160.0.100; #пул для неизвестных хостов
option routers 10.160.1.1;
option microsoft.disable-netbios-over-tcpip 2;
}
subnet a.b.c.0 netmask 255.255.252.0 {
option routers a.b.c.d;
option microsoft.disable-netbios-over-tcpip 2;
}
subnet 10.160.8.0 netmask 255.255.255.0 { #из этой подсети запросы dhcp-relay со свичей
}
}
In the dhcp-event file, the agent.circuit-id, agent.remote-id, IP and MAC are checked for validity, and if everything is ok, then the route is added to this address through the desired interface.
Primitive dhcp-event example:
#hostel 1
if ($ARGV[3] eq '0:21:91:92:d7:55') {
system "/sbin/ip ro add $ARGV[0] dev eth1 src a.b.c.d";
}
#hostel 2
if ($ARGV[3] eq '0:21:91:92:d4:92') {
system "/sbin/ip ro add $ARGV[0] dev eth2 src a.b.c.d";
}
only $ ARGV [3] is checked here (that is, agent.remote-id, or the MAC of the switch through which the DHCP request was received), but you can also check all the other fields by receiving their valid values, for example, from the database
As a result, we get :
1) the client that did not request the address via DHCP - does not go beyond its unmanaged switch, IP-MAC-PORT-BINDING does not let it through;
2) a client whose MAC is known (is in the database), but the request does not match the port or switch - will receive an IP bound to this MAC, but the route to it will not be added, accordingly proxy_arp will “answer” that the address is already taken, and the address will be immediately released;
3) a client whose MAC is not known will receive an address from the temporary pool. From these addresses there is a redirection to a page with information, here you can also re-register your MAC using login / password;
4) and finally, the client whose MAC is known and matches the connection to the switch and port will receive its address. Dhcp-snooping will add dynamic binding to the impb table on the switch, the server will add a route to this address through the desired interface of the former bridge.
At the end of the lease or release of the address, the script / etc / dhcp / dhcp-release is called, the contents of which are very primitive:
system "/sbin/ip ro del $ARGV[0]";
There is a small security flaw, specifically in paragraph 2. If you use a non-standard dhcp-client, which does not check if the address provided by the dhcp server is busy, then the address will not be released. Of course, the user will not have access to an external network beyond the router, since the server will not add a route to this address through the desired interface, but the switch will unlock this MAC-IP pair on its port.
You can get around this flaw using the classes in dhcpd.conf, but this significantly complicates the configuration file, and, accordingly, increases the load on our old server. Because for each subscriber you will have to create your own class, with a rather difficult condition for getting into it, and then your own pool. Although there are plans to try in practice how much this will increase the load.
Thus, it turned out that the correspondence of the IP-MAC pair is now “monitored” by DHCP when issuing the address, access from the “invalid” MAC-IP is limited by the switch. Now it was possible to remove not only bridge but also macipmap from the server, replacing 6 sets (from "Optimization 1") with one ipmap, which contains all public IP addresses. And also by removing -m physdev.
Server interfaces also switched from promisc mode to normal, which also slightly reduced the load.
Namely, this whole procedure with disassembling the bridge reduced the overall load on the server by almost 2 times ! Softirq is now not 50-100%, but 25-50%. At the same time, access control to the network only got better.
Optimization 5
After the last optimization, although the load dropped noticeably, a strange thing was noticed: iowait increased. Not that much, from 0-0.3% to 5-7%. This is taking into account the fact that there are practically no any disk operations on this server - it just throws packets.
(blue user time - kernel compilation)
iostat showed that there is a constant load on the disk in 800-820 Blk_wrtn / s
Started searching for processes that could write. Performance
echo 1 > /proc/sys/vm/block_dump
gave a strange result: the culprits were
kjournald(483): WRITE block 76480 on md0
и
md0_raid1(481): WRITE block 154207744 on sdb2
md0_raid1(481): WRITE block 154207744 on sda3
Ext3 is in mode
data=writeback, noatime, and nothing is written to the disk, except for logs. But the logs that were written yesterday are written today, their volume has not increased, that is, iowait also did not have to increase. I started to scroll through the steps in my head, what I was doing and what could affect iowait. As a result, I stopped syslog - and iowait dropped sharply to ~ 0%.
To prevent dhcp from cluttering messages with my messages, I sent them to log-facility local6, and wrote in syslog.conf:
*.info;mail.none;authpriv.none;cron.none;local6.none /var/log/messages
local6.info /var/log/dhcpd.log
it turned out that when writing via syslog, sync is done for each line. There are quite a lot of requests to the dhcp server, a lot of events are generated that get to the log, and a lot of sync is called.
Fix on
local6.info -/var/log/dhcpd.log
iowait reduced in my case 10-100 times, instead of 5-7% it became 0-0.3%
Optimization result:
Why this article.
Firstly, maybe someone will draw from it useful solutions for themselves. I didn’t discover America here, although most of the events described here were in the pre-Guban era, and “googling recipes” didn’t help much, I got it all with my own head.
Secondly, we constantly have to deal with the fact that instead of optimizing the code, developers are engaged in increasing computing power, and this article can be an example of the fact that, if you wish, you can find errors in your seemingly many times tested code and manage them . 90% of site developers check the work of the site on their machine, put it into production. Then the whole thing slows down under load. Teasing admin server. By optimizing the server in this case, little can be achieved if the code is originally written not optimally. And a new server is bought, or another server and balancer. Then the balancer of the balancer and so on. And the code inside was not optimal, and remains forever. Of course, I understand that in the current realities, code optimization is more expensive than extensive capacity building,
From the nostalgic: I have on the shelf an old laptop, P3-866 2001 (Panasonic CF-T1 if someone says something to this), but now it’s impossible to even look at sites on it, although there has been no more sense on these sites over 10 years. With love, I recall interesting toys on the ZX-Spectrum in terms of gameplay not inferior to today's monsters requiring 4 cores / 4 gig