DGFS - Fast DIY File System
Sometimes the file system means you have to store a lot of information, most of which is static. When there are few files and they are large, this is bearable. But if the data is in a huge number of small files, access to which is pseudo-random, the situation is approaching disaster.

There is an opinion that a specialized read-only file system, ceteris paribus, has advantages over the general purpose one because:
In this article, we will understand how to organize a file system with the objective function maximum performance at minimum cost.
First of all, the disc: all experiments are conducted on a dedicated 1 Tb Seagate Barracuda ST31000340NS.
The operating system is Windows XP.
Processor: AMD Athlon II X3 445 3 GHz.
Memory: 4 GB.
Before starting the substantive work, I want to understand what can be expected from the disk. Therefore, a series of measurements were taken of random positioning and readings from the disk.
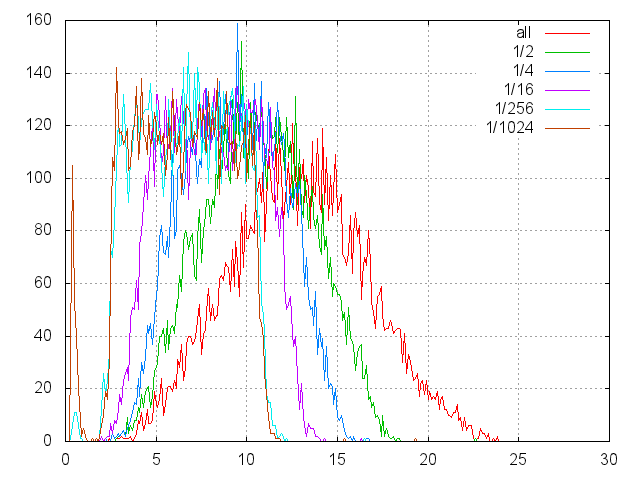
The graph below shows histograms of read times from disk in arbitrary positions. The abscissa shows the duration of positioning and reading. On the y-axis - the number of hits in a basket 0.1 msec wide.
Disk accesses were made in the regular way:
Several series of measurements were made, 10,000 in each series. Each series is marked with its own color:
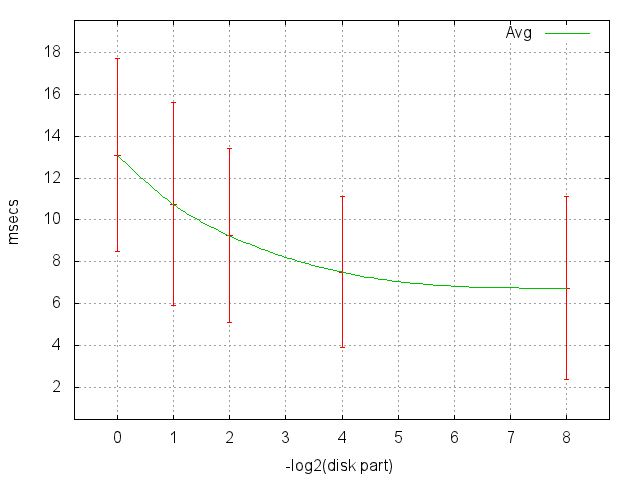
And here are shown mat. expectations and errors from the previous graph, the abscissa axis in the logarithmic scale, for example, 1/16 corresponds to 4 (1/2 1/2).
What conclusions can be drawn?
Let's try to create a file the size of a disk and get the time characteristics of working with it. To do this, create a file commensurate with the file system size and read it in random places with regular _fseeki64 / fread .
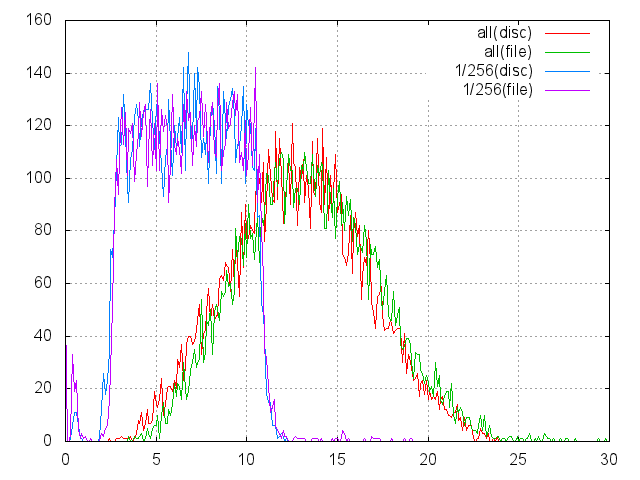
The graph is similar to previously presented histograms. And two of them, marked as (disc), are taken from the previous chart. Paired histograms marked as (file) were obtained on the basis of measurements of file readings. What can be noted:
That is, it is necessary to additionally spend a byte for each kilobyte of data, a gigabyte comes out per terabyte, and caching a gigabyte is not so simple. However, in ext4 there seems to be no such problem, or it is masked with extents.
Let us recall our test problem and try to solve it head on - using the file system. It immediately turns out that:
First, consider the histogram in milliseconds:
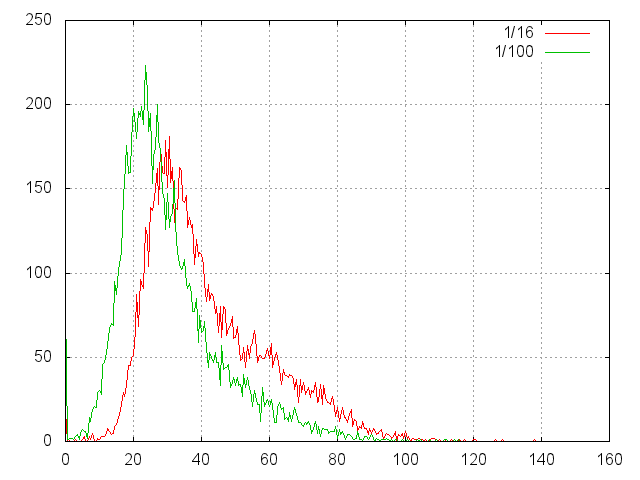
So, here is a histogram of the read times of random files.
Now let's look at the same in units of conditional seeks:
Let's build a prototype of our read-only file system:
The following are histograms of the times obtained on this data:
Here is the time to ask - well, well, we made out a very special case of a regularly arranged file system (three levels with fixed names). But what about the usual data, the usual paths and names?
The answer is that fundamentally nothing will change. There will still be one main index. But it will be arranged a little differently.
Above, the file identifier (index key) was the encoded path to it. So it will be, the key is the string full path to the file. Everything else in the meaning - size, position, owner, group, rights ...
Perhaps there will not be many combinations (owner, group, rights), and it will be profitable to store them with Huffman codes pointing to the global combination table. But these are the details. Fundamentally, the situation does not differ from that which we have already tested.
To find a file, you need to specify its full path. To view the contents of a directory, you need to specify the directory path and select everything that matches the prefix. To move up the hierarchy, bite off a piece of the path and again search by prefix.
But do file paths take up a lot of space? Yes, but files in the same directory have a common prefix that can only be stored once. A common suffix is also common. To understand the amount of data that needs to be stored, a series of experiments were performed with the file system paths, which showed that they are compressed with an average of 10 times using bzip2 (BWT + suffix sort + huffman). This leaves 5-6 bytes per file.
In total, you can count on 10-16 bytes per file, or ~ 2 bytes per kilobyte of data (if the average file is 8K). A terabyte file requires 2 gigabytes of index, a regular 64-gigabyte SSD-drive, therefore, is capable of serving 32 terabytes of data.
Full counterparts and hard to present.
For example, SquashFS , with zero compression, can be used in a similar way. But this system repeats the traditional structure, simply compresses files, inodes and directories. Therefore, it is inherent in all those bottlenecks that we diligently tried to avoid.
An approximate analogue can be considered the use of a DBMS for data storage. In fact: we store the contents of the files as BLOBs, and the metadata as table attributes. Simple and elegant. The DBMS itself takes care of how to more efficiently arrange files in the available disk space. It creates and maintains all the necessary indexes itself. Plus a nice bonus - we can change our data without restrictions.
However:
Obviously, nobody needs a one-time file system. Filling a file system a few terabytes in size can take tens of hours. During this time, new changes may accumulate, therefore, there must be a method for changing data that is different from a full update. It is advisable not to stop the work. Well, this topic is worthy of a separate story and over time we are going to talk about it.
So, the prototype read-only file system is presented , which is simple, flexible, solves the test problem and at the same time:
There is an opinion that a specialized read-only file system, ceteris paribus, has advantages over the general purpose one because:
- It’s not necessary to manage free space;
- no need to spend money on journaling;
- You can not worry about fragmentation and store files continuously;
- it is possible to collect all meta information in one place and cache it effectively;
- It’s a sin not to compress meta-information, since it was in one heap.
In this article, we will understand how to organize a file system with the objective function maximum performance at minimum cost.
Task
- 100 million small files (~ 8K each).
- Three-level hierarchy - 100 top-level directories, each of which has 100 middle-level directories, each of which has 100 lower-level directories, each of which has 100 files.
- We optimize the build time and average reading time of a random file.
Iron
First of all, the disc: all experiments are conducted on a dedicated 1 Tb Seagate Barracuda ST31000340NS.
The operating system is Windows XP.
Processor: AMD Athlon II X3 445 3 GHz.
Memory: 4 GB.
Disk specifications
Before starting the substantive work, I want to understand what can be expected from the disk. Therefore, a series of measurements were taken of random positioning and readings from the disk.
The graph below shows histograms of read times from disk in arbitrary positions. The abscissa shows the duration of positioning and reading. On the y-axis - the number of hits in a basket 0.1 msec wide.
Disk accesses were made in the regular way:
- opening through CreateFile ("\\\\. \\ PhysicalDrive1" ...);
- positioning through SetFilePointer;
- and reading through ReadFile.
Several series of measurements were made, 10,000 in each series. Each series is marked with its own color:
- all - positioning goes all over the disk;
- ½ - only in its younger half, etc.
And here are shown mat. expectations and errors from the previous graph, the abscissa axis in the logarithmic scale, for example, 1/16 corresponds to 4 (1/2 1/2).
What conclusions can be drawn?
- In the worst case (random search), the expectation of one reading is 13 msec. That is, more than 80 random reads per second from this disk can not be done.
- At 1/256, we first see hits in the cache.
- At 1/1024, a tangible number of reads ~ 1% begins to get into the cache.
- More than 1/256 does not differ from 1/1024, the run of the heads is already too small, we only see their acceleration and (mostly) calming.
- We have the ability to scale, that is, it is permissible to conduct experiments on a partially filled disk and rather confidently extrapolate the results.
NTFS
Let's try to create a file the size of a disk and get the time characteristics of working with it. To do this, create a file commensurate with the file system size and read it in random places with regular _fseeki64 / fread .
The graph is similar to previously presented histograms. And two of them, marked as (disc), are taken from the previous chart. Paired histograms marked as (file) were obtained on the basis of measurements of file readings. What can be noted:
- Times are near.
- Although the file is 90% of the file system (9xE11 bytes), reading from it in full size is on average almost a millisecond slower.
- Disk cache for a file works better than for disk.
- Tails appeared in ~ 6 msec, if the worst time for full reading was about 24 msec, now it stretches to almost 30. Similarly, for 1/256. Apparently, metadata fell out of the cache and you have to read it additionally.
- But in general, reading from a large file works very similar to working with a bare disk and in some cases can replace or emulate it. This is an honor to NTFS. for example, the ext2 / ext3 structure requires a minimum of 4 bytes for each 4-Kb data block for a file:
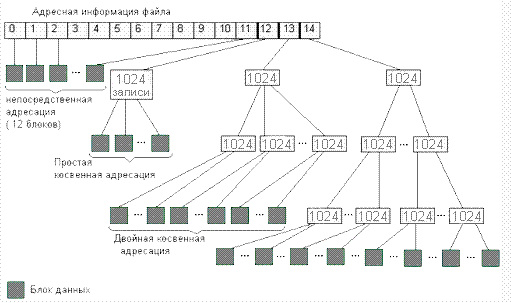
That is, it is necessary to additionally spend a byte for each kilobyte of data, a gigabyte comes out per terabyte, and caching a gigabyte is not so simple. However, in ext4 there seems to be no such problem, or it is masked with extents.
NTFS with hierarchy
Let us recall our test problem and try to solve it head on - using the file system. It immediately turns out that:
- This takes quite a lot of time, it takes about half an hour to create one branch out of a million files, with a tendency to gradually slow down as the disk becomes full in accordance with our first schedule.
- Creating all 100 million files would therefore take 50+ hours.
- Therefore, we will take measurements on 7 million files (~ 1/16) and scale to the full task.
- An attempt to take measurements in conditions more close to combat led to the fact that NTFS crashed in about 12 million files with approximately the same diagnostics as the main character in the movie “Death to her face”: - “Actually, fragmented the cervical vertebra is a very, VERY bad sign! ”
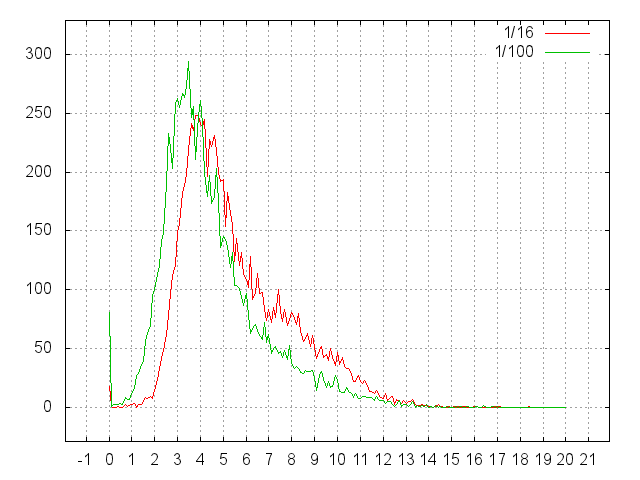
First, consider the histogram in milliseconds:
So, here is a histogram of the read times of random files.
- Two series - 7 million as 1/16 of the task and 1 million for calibration.
- In a series of 10000 measurements, in the basket 0.5 msec.
- The total time of the 1/16 test is 7'13 '', i.e. the expectation is 43 msec.
- The total time of the 1/100 test is 5'20 '', i.e. the expectation is 32 msec.
Now let's look at the same in units of conditional seeks:
- That 1/16, that 1/100, are too large to be cached anyhow. And our files are too small for fragmentation.
- Therefore, 1 seek, we must pay for reading the actual data. Everything else is the internal affairs of the file system.
- Maximums are at 3.5 (for 1/100) and 4 (for 1/16) seek'a.
- And expectation is generally 4 ... 5.
- That is, to get to the information about where the file is stored, the file system (NTFS) has to do 3-4 readings. And sometimes more than 10.
- In the case of a complete task, presumably, the situation will not improve.
Prototype
Let's build a prototype of our read-only file system:
- It consists of two files - data and metadata.
- Data file - just all files written in a row.
- Metadata file - In-tree with key - file identifier. Value is the address in the data file and its size.
- A file identifier is an encoded path to it. Recall that our data is located in a three-level directory system, where each level is encoded with a number from 0 to 100, the file itself is similar. This whole structure is packed into an integer.
- The tree is written in the form of 4K pages, primitive compression is applied.
- In order to avoid fragmentation, these files have to be created on different file systems.
- Just appending data to the end of the file (data) is inefficient. The larger the file, the more expensive the file system (NTFS, WinXP) is its extension. To avoid this non-linearity, you must first create a file of the desired size (900 GB).
- This preliminary creation takes more than 2 hours, all this time it takes to fill this file with zeros, apparently, for security reasons.
- Filling this file with data takes the same amount of time.
- Building an index takes about 2 minutes.
- Recall a total of 100 million files, each about 8K in size.
- The index file occupies 521 MB. Or ~ 5 bytes per file. Or ~ 5 bits per kilobyte of data.
- A variant of the index with more complex compression (Huffman codes) was also tested. This index occupies 325 MB. Or 3 bits per kilobyte of data.
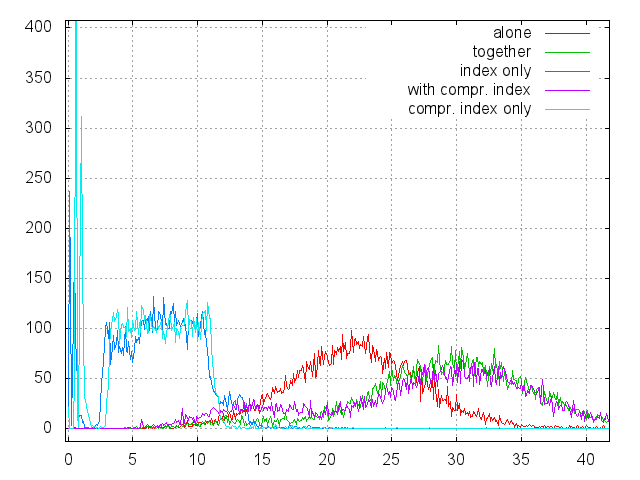
The following are histograms of the times obtained on this data:
- “Alone” - under this label is a data file located separately from the index file on another physical disk;
- “Ogether” - both the data file and the index are located within the same file system on the same physical disk;
- “Index only” - only information about the file in the index is searched without reading the actual data;
- “With compr. index "- the same as" together ", but with a compressed index;
- “Compr. index only "- the same as" index only ", but with a compressed index;
- a total of 10,000 reads, a histogram step of 0.1 msec.
Conclusions:
- The compression quality of the index almost does not affect the speed of work. It takes CPU time to compress pages, but the page cache works better.
- Reading the index looks like one reading from a file of the appropriate size (see the first graph). Since 512 MB is 1/2000 of the disk, the average seek time should be about 6.5 msec, plus the premium for what we read from the file, and not directly from the disk. Apparently, this is it. The index tree is three-tier, the top two levels are very quickly cached, and it is pointless to cache the lower level of pages. As a result, any search in the tree degenerates into a single reading of a leaf page.
- If the data file and the index file are located on the same physical disk, the total search time is equal to two random seeks for the full distance. One to read data and one to go to the index file, which is located either at the very beginning or at the very end of the disk.
- If the files are spread across different devices, we have one full seek for reading data and one short seek for searching in the index. Considering that the index file is relatively small, the natural solution suggests itself - if we need a storage of several (tens) terabytes, we need to prepare a dedicated drive for the index (SSD) and several drives for data. It can be styled as a JBOD and looks like a regular file system.
- This scheme has an important feature - guaranteed response time, which is difficult to achieve in conventional file systems, for example, for use in real-time systems.
Here is the time to ask - well, well, we made out a very special case of a regularly arranged file system (three levels with fixed names). But what about the usual data, the usual paths and names?
The answer is that fundamentally nothing will change. There will still be one main index. But it will be arranged a little differently.
Above, the file identifier (index key) was the encoded path to it. So it will be, the key is the string full path to the file. Everything else in the meaning - size, position, owner, group, rights ...
Perhaps there will not be many combinations (owner, group, rights), and it will be profitable to store them with Huffman codes pointing to the global combination table. But these are the details. Fundamentally, the situation does not differ from that which we have already tested.
To find a file, you need to specify its full path. To view the contents of a directory, you need to specify the directory path and select everything that matches the prefix. To move up the hierarchy, bite off a piece of the path and again search by prefix.
But do file paths take up a lot of space? Yes, but files in the same directory have a common prefix that can only be stored once. A common suffix is also common. To understand the amount of data that needs to be stored, a series of experiments were performed with the file system paths, which showed that they are compressed with an average of 10 times using bzip2 (BWT + suffix sort + huffman). This leaves 5-6 bytes per file.
In total, you can count on 10-16 bytes per file, or ~ 2 bytes per kilobyte of data (if the average file is 8K). A terabyte file requires 2 gigabytes of index, a regular 64-gigabyte SSD-drive, therefore, is capable of serving 32 terabytes of data.
Analogs
Full counterparts and hard to present.
For example, SquashFS , with zero compression, can be used in a similar way. But this system repeats the traditional structure, simply compresses files, inodes and directories. Therefore, it is inherent in all those bottlenecks that we diligently tried to avoid.
An approximate analogue can be considered the use of a DBMS for data storage. In fact: we store the contents of the files as BLOBs, and the metadata as table attributes. Simple and elegant. The DBMS itself takes care of how to more efficiently arrange files in the available disk space. It creates and maintains all the necessary indexes itself. Plus a nice bonus - we can change our data without restrictions.
However:
- Ultimately, the DBMS still accesses the disk, either directly or through the file system. And this is fraught with danger, it is worth overlooking and - bam! operating time slowed down significantly. But let's say we have an ideal DBMS with which this will not happen.
- DBMS will not be able to compress prefixes just as efficiently simply because it is not designed for read-only mode.
- The same can be said about metadata - they will occupy much more space in the DBMS.
- More space — more disk reads — slower work.
- Using hash codes from the file path does not solve the problem since matching the path with the hash code still needs to be stored somewhere just to ensure that the contents of the directory can be viewed. Everything will result in the fact that you have to reproduce the structure of the file system using the DBMS.
- Files larger than a page will be forced to split the DBMS into parts, and random access to them will be carried out in the best case for a logarithmic time from the file size.
- If we can just put all the metadata on a dedicated SSD, in the case of a DBMS it will be much more difficult.
- You can forget about the guaranteed response time.
Transactional
Obviously, nobody needs a one-time file system. Filling a file system a few terabytes in size can take tens of hours. During this time, new changes may accumulate, therefore, there must be a method for changing data that is different from a full update. It is advisable not to stop the work. Well, this topic is worthy of a separate story and over time we are going to talk about it.
Total
So, the prototype read-only file system is presented , which is simple, flexible, solves the test problem and at the same time:
- demonstrates the maximum possible performance on the hardware allocated to it;
- its architecture does not impose objective restrictions on the amount of data;
- makes it clear what to do in order to get a general-purpose file system, and not a hobby made for a specific task
- makes it clear which way it is worth moving in order to make our file system incrementally mutable.