How Headless Chrome Works
It’s already clear from the name that a headless browser is something without a head. In the context of a frontend, it is an indispensable tool for a developer, with which you can test the code, check the quality and compliance with layout. Vitaliy Slobodin at Frontend Conf decided that it was necessary to get to know the device of this tool closer.
Under the cut components and features of Headless Chrome, interesting scenarios for using Headless Chrome. The second part about Puppeteer is a convenient Node.js library for managing Headless mode in Google Chrome and Chromium.
About the speaker: Vitaliy Slobodin - a former developer of PhantomJS - the one who closed it and buried it. Sometimes it helps Konstantin Tokarev ( annulen ) in the "resurrected" version of QtWebKit - the very QtWebKit, where there is support for ES6, Flexbox and many other modern standards.
Vitaliy loves exploring browsers, digging into WebKit, Chrome and so on in his free time, and more. We’ll talk about browsers today, namely about headless browsers and their entire ghost family.
What is a headless browser?
Already from the name it is clear that this is something without a head. In a browser context, this means the following.
This is a typical WebKit-based browser. You can not get a grasp of the components - this is just a visual image.

We are only interested in the top component of the Browser UI. This is the same user interface - windows, menus, pop-up notifications and everything else.

This is what the headless browser looks like. Notice the difference? We completely remove the user interface. He is no more. Only the browser remains .
Today we will talk about Headless Chrome (). What is the difference between them? In fact, Chrome is a branded version of Chromium, which has proprietary codecs, the same H.264, integration with Google services and everything else. Chromium is just an open source implementation.

Headless Chrome date of birth: 2016. If you come across it, you can ask me a tricky question: “How so, I remember the news of 2017?” The fact is that a team of engineers from Google contacted the PhantomJS developers back in 2016, when they were just starting to implement Headless -mode in Chrome. We wrote whole Google Docks, how we will implement the interface and so on. Then Google wanted to make an interface fully compatible with PhantomJS. It was only then that the team of engineers came to the decision not to do such compatibility.
We'll talk about the management interface (API), which is the Chrome DevTools protocol, later and see what you can do with it.
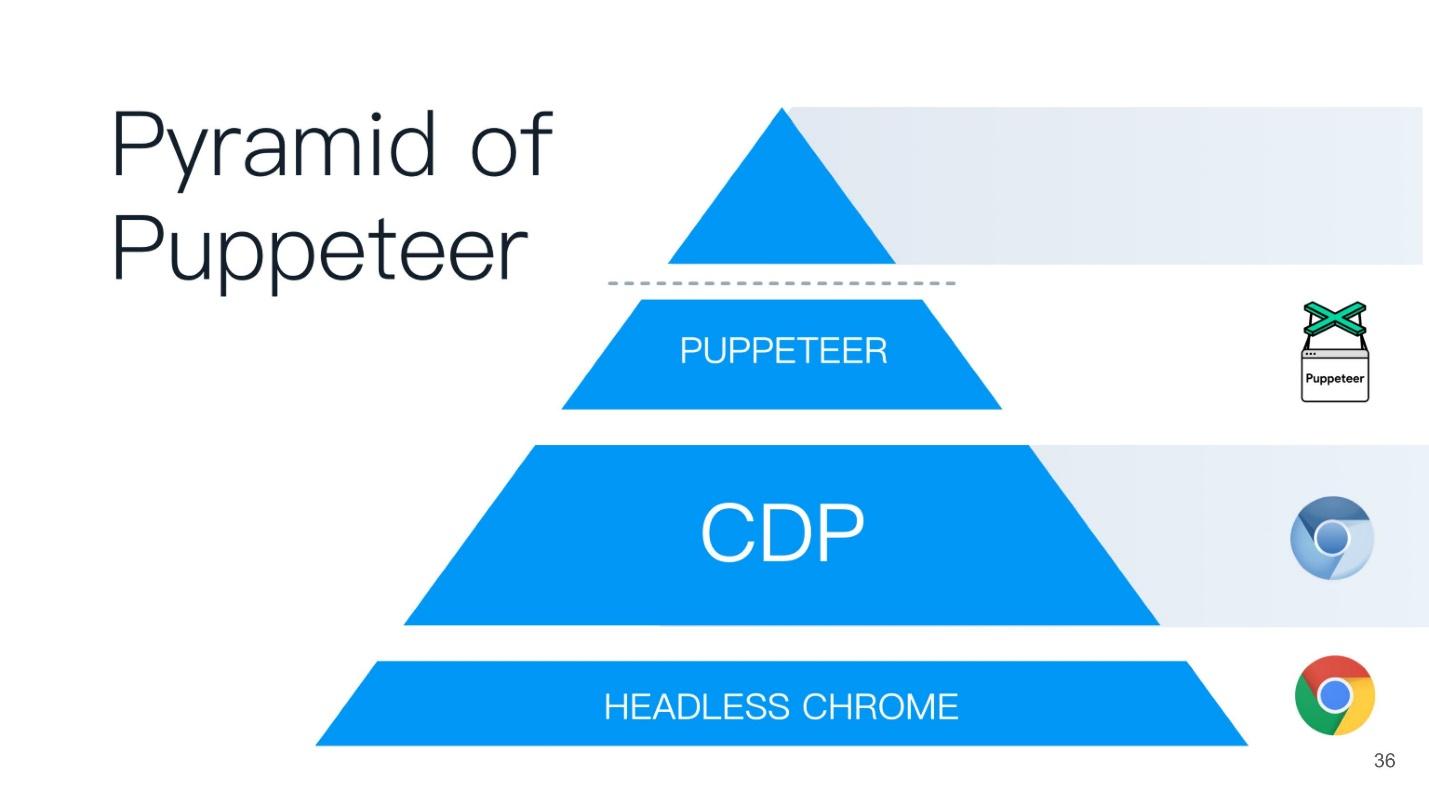
This article will be built on the principle of the Puppeteer pyramid (from the English puppeteer). A good name is chosen - the puppeteer is the one who controls everyone else!
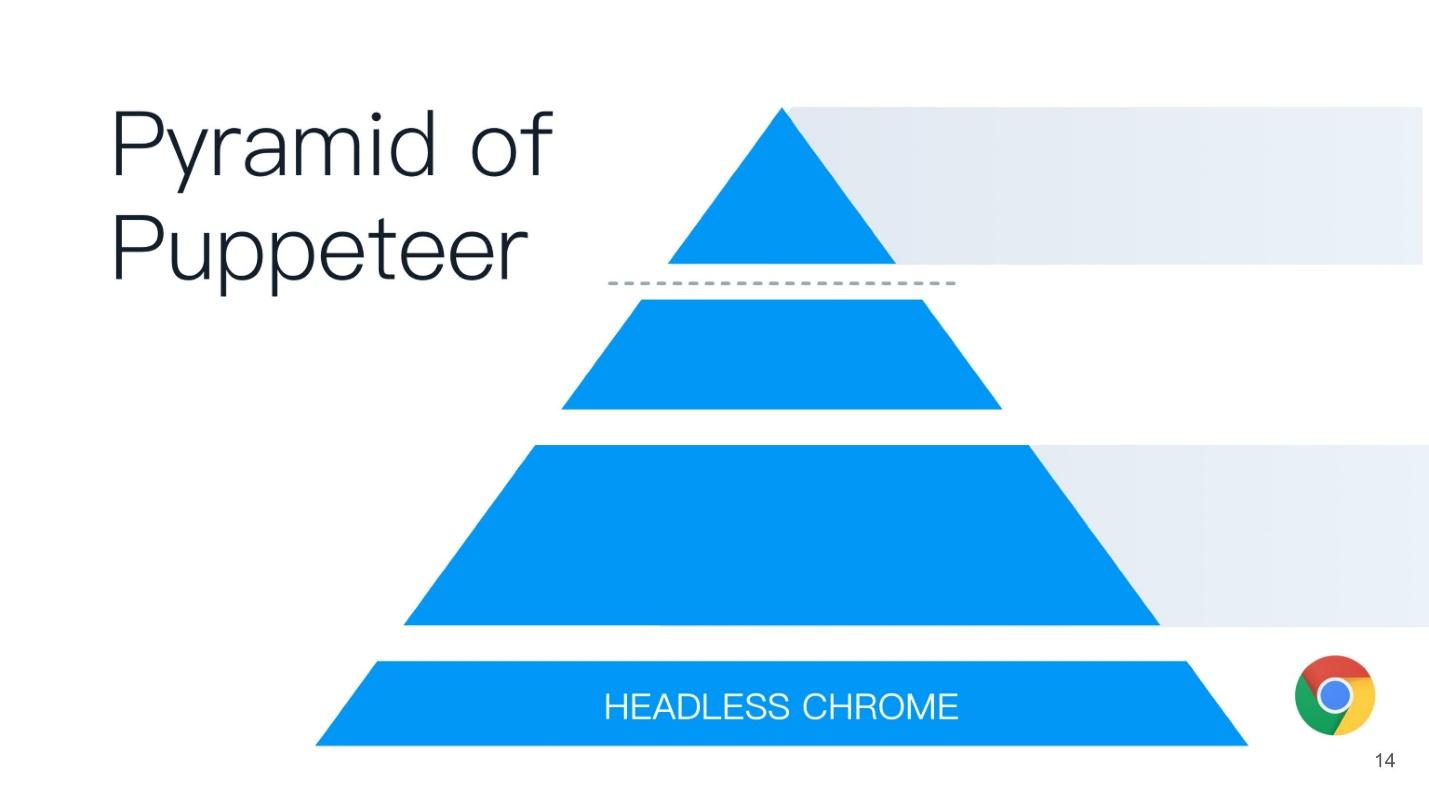
At the base of the pyramid is Headless Chrome - Headless Chrome - what is it?
Headless chrome
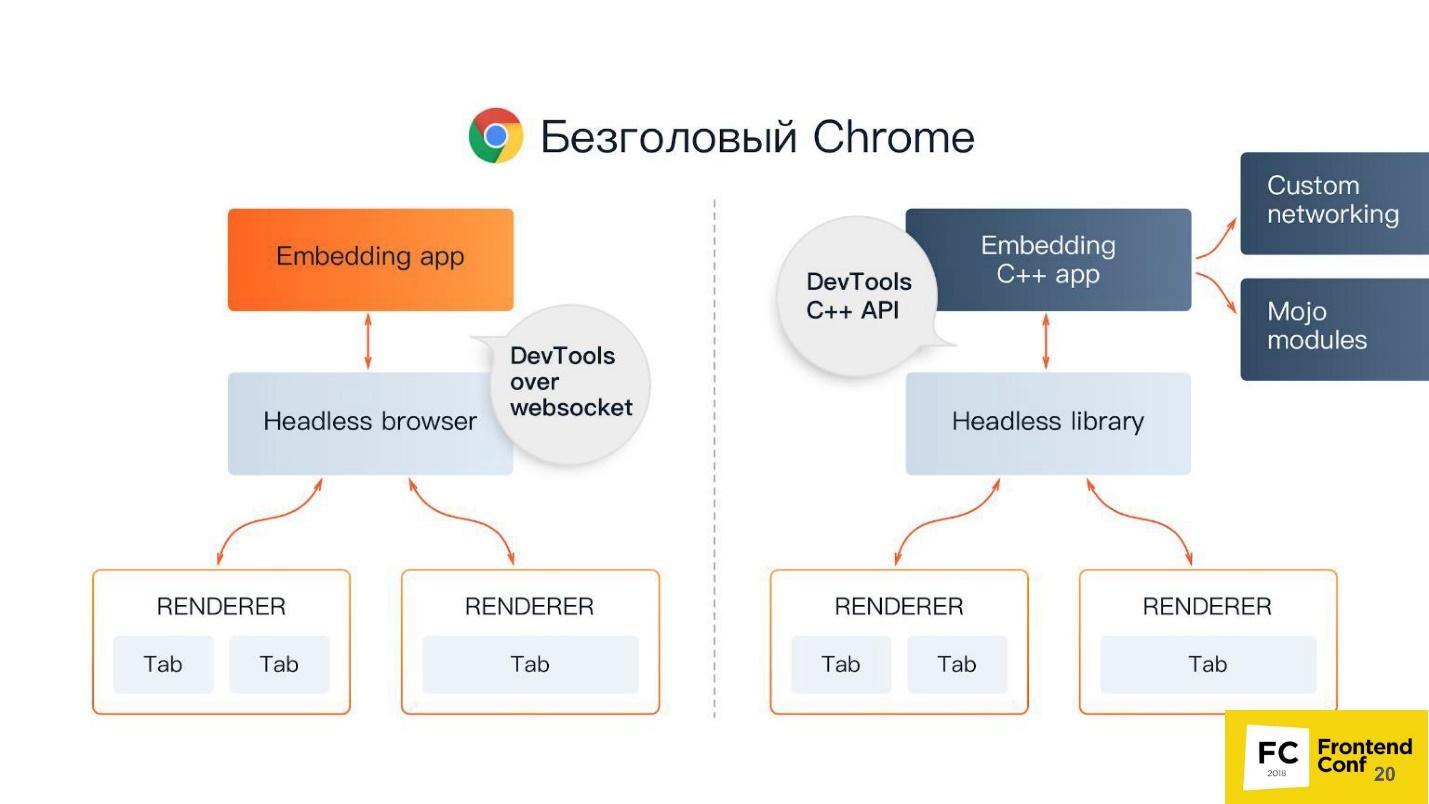
In the center - Headless browser - the same Chromium or Chrome (usually Chromium). It has the so-called renderers (RENDERER) - processes that draw the contents of the page (your window). Moreover, each tab needs its own renderer, so if you open many tabs, then Chrome will start as many processes for rendering.
On top of all this is your application. If we take Chromium or Headless Chrome, then Chrome will be on top of it, or some application in which you can embed it. The closest analogue can be called Steam. Everyone knows that in essence Steam is just a browser to the Steam website. He, of course, is not headless, but similar to this scheme.
There are 2 ways to embed headless Chrome in your application (or use it):
You may ask, why is C ++ on the front end? The answer is the DevTools C ++ API. You can implement and use the features of headless Chrome in different ways. If you use Puppeteer, communication with a headless browser will be done through web sockets. If you embed the Headless library in a desktop application, you will use the native interface, which is written in C ++.
But besides all this, you still have additional things, including:
Chromium Components
Again I hear a tricky question: “Why do I need this terrible scheme? I write under (insert the name of your favorite framework). ”
Because in the case of something, for example, a fatal error or a very serious bug in production, you have to deal with the guts, and you can just get lost there - where, what and how. If you, for example, write tests or use Headless Chrome, you too may encounter some of its strange behavior and bugs. Therefore, I will briefly tell you what Chromium has components. When you see a large stack trace, you will already know which way to dig and how to fix it at all.
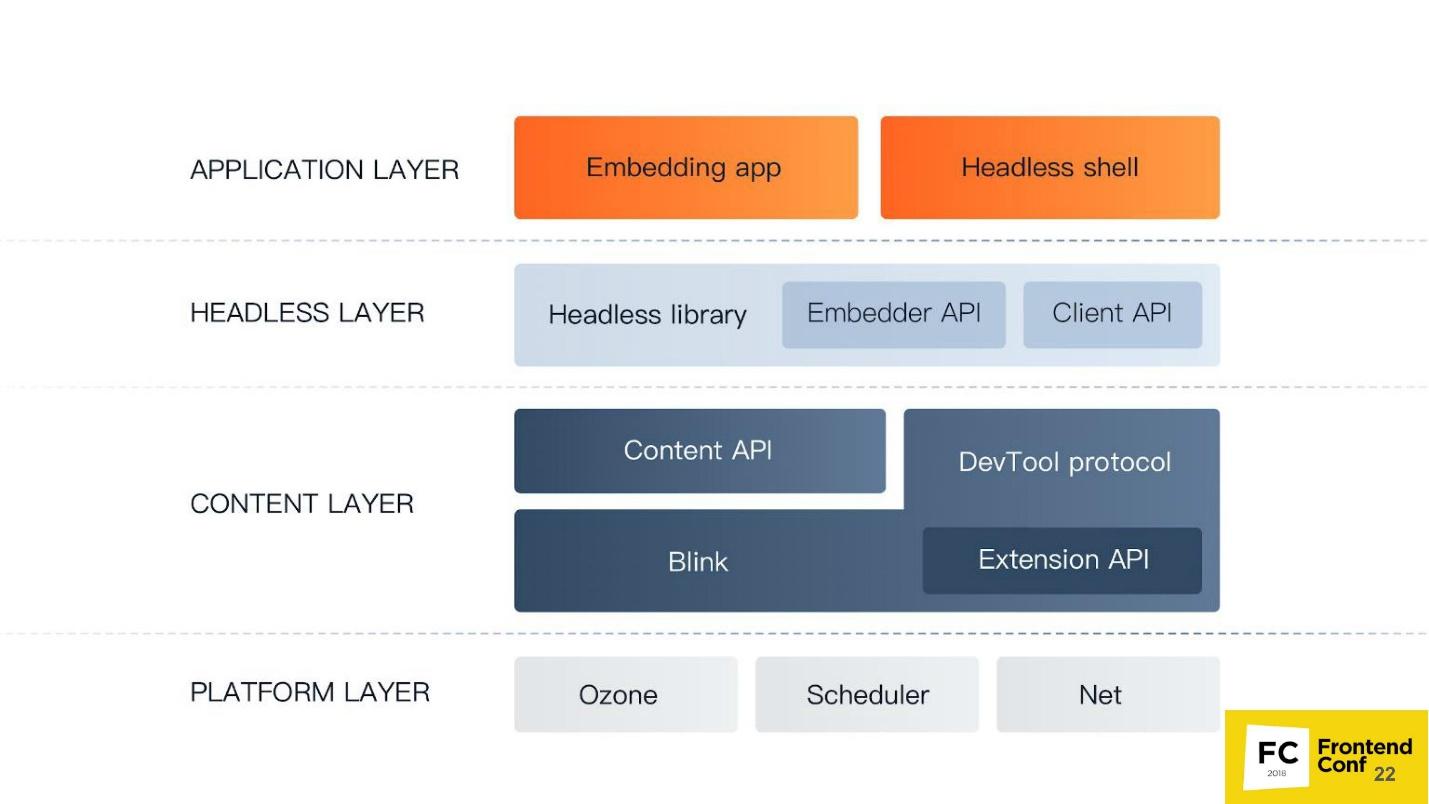
The lowest level of the Platform layer . Its components:
The Content layer is the largest component Chrome has. It includes:
Level Headless of layer - the level of a headless browser:
Application level the Application of layer :
Now let's rise from the depths a little higher, activate - now the frontend will go.
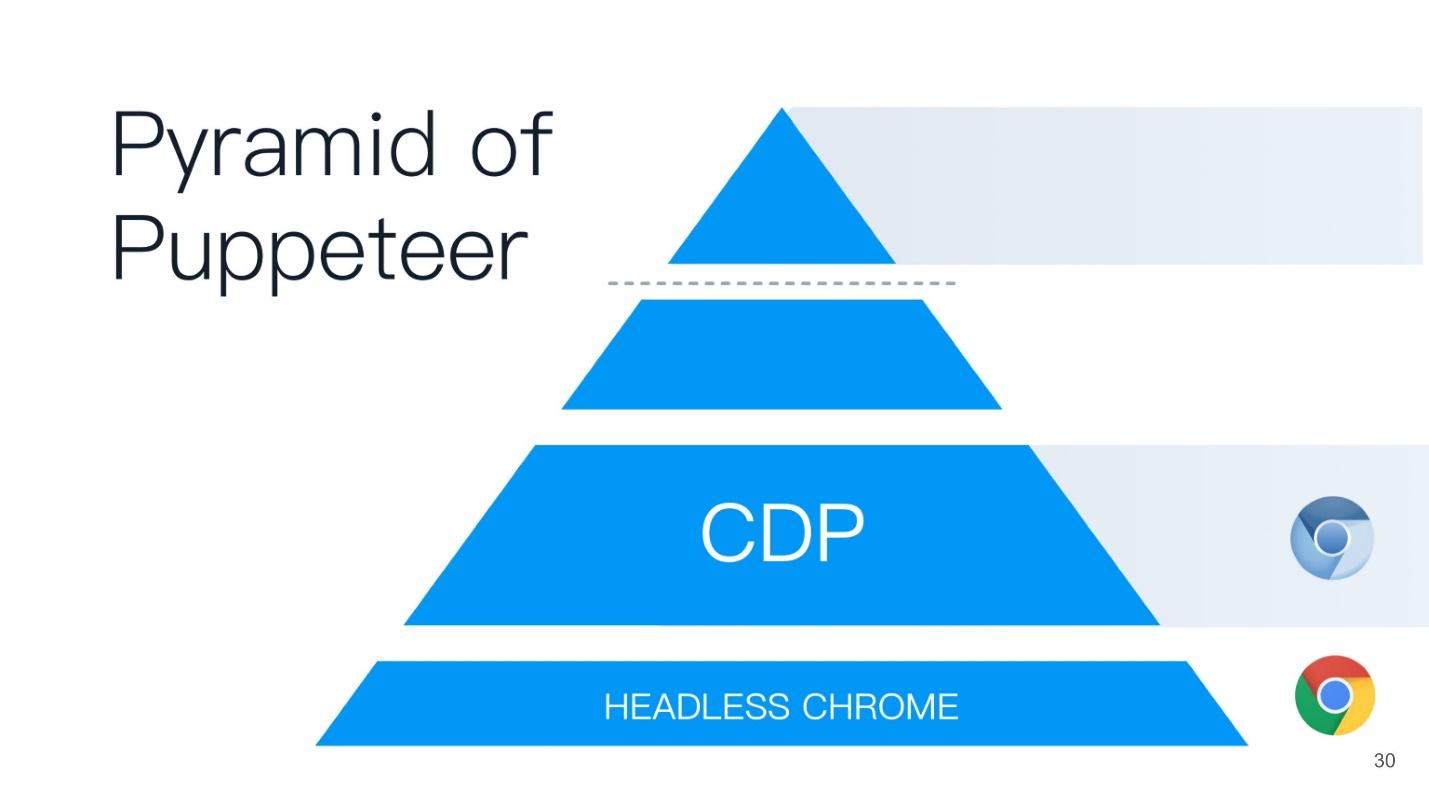
Chrome DevTools protocol
We all came across the Chrome DevTools protocol, because we use the developer panel in Chrome or the remote debugger - the same development tools. If you run the developer tools remotely, communication with the browser occurs using the DevTools protocol. When you install debugger, see code coverage, use geolocation or something else - all this is controlled using DevTools.
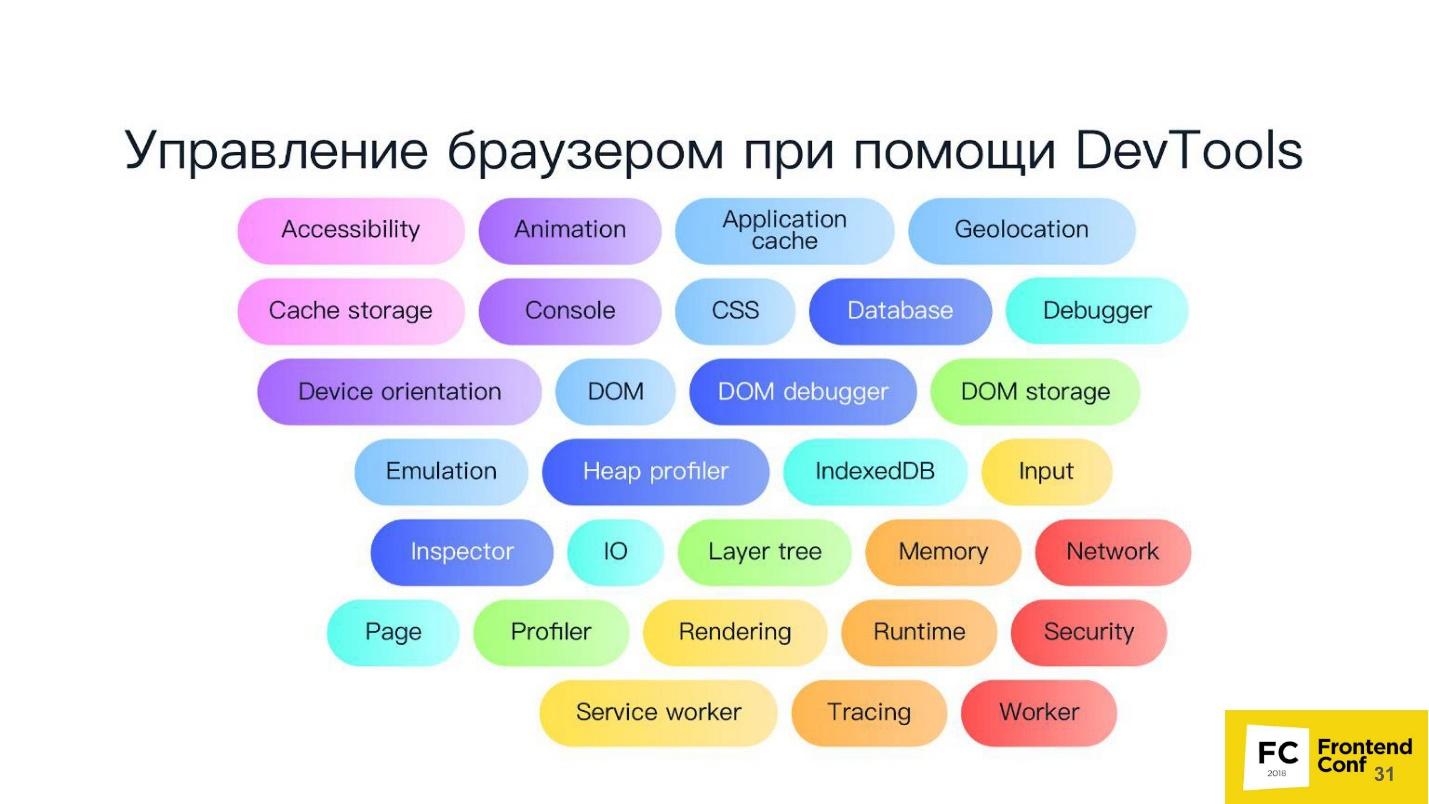
In fact, the DevTools protocol itself has a huge number of methods. Your developer tool does not have access, probably to 80% of them. Really, you can do everything there!
Let's see what this protocol is all about. In fact, it is very simple. It has 2 components:

They communicate using simple JSON:
But among other things, your tab can send events back to you. Suppose when an event on a page occurred, or there was an exception on a page, you will receive a notification through this protocol.

Puppeteer
You can install Puppeteer using your favorite package manager - be it yarn, npm or any other.
Using it is also easy - just request it in your Node.js script, and you can already use it.

Using the link https://try-puppeteer.appspot.com, you can write a script directly on the site, execute it and get the result directly in the browser. All this will be implemented using Headless Chrome.
Consider the simplest script under Node.js:
Here we simply open the page and print it in PDF. Let's see the operation of this script in real time:
Everything will be cool, but it is not clear what is inside. Of course, we have a headless browser, but we don’t see anything. Therefore, Puppeteer has a special flag called headless: false:
It is needed to launch the headless browser in headful mode, when you can see some window and see what happens to your page in real time, that is, how your script interacts with your page.
This will look the same script when we add this flag. A browser window appears on the left - more clearly.
Pros of Puppeteer:
+ This is the Node.js library for Chrome headless.
+ Support for legacy versions of Node.js> = 6.
+ Easy installation.
+ High-level API for managing this entire giant machine.
Headless Chrome installs easily and without system intervention. At the first installation, Puppeteer downloads the version of Chromium and installs it directly in the node_modules folder specifically for your architecture and OS. You do not need to download anything extra, it does this automatically. You can also use your favorite version of Chrome, which is installed on your system. You can do this too - Puppeteer provides you with such an API.
Unfortunately, there are also disadvantages, if we take just the basic installation.
Cons Puppeteer :
- No top-level functions : synchronization of bookmarks and passwords; profile support; hardware acceleration etc.
- Software rendering is the most significant minus. All calculations and rendering take place on your CPU. But here, Google engineers will soon surprise us - work on the implementation of hardware acceleration is already underway. Already now you can try to use it if you are brave and courageous.
- Until recently, there was no support for extensions - now there is! If you are a cunning developer, you can take your favorite AdBlock, specify how Puppeteer will use it, and all ads will be blocked.
- No audio / video support . Because, well, why headless-browser audio and video.
What can Puppeteer:
And a couple of cool things that I will show a little further.
Session Isolation
What is it, what is it eaten with, and will we not choke? - Do not choke!
Session isolation is a separate “repository” for each tab . When you start Puppeteer, you can create a new page, and each new page can have its own repository, including:
All pages will live independently of each other. This is necessary, for example, to maintain the atomicity of the tests.
Session isolation saves resources and time when starting parallel sessions . Suppose you are testing a site that is being built in development mode, that is, bundle are not minimized, and weigh 20 MB. If you just want to cache it, you can tell Puppeteer to use a cache common to all pages that are created, and this bundle will be cached.
You can serialize sessions for later use.. You write a test that checks a certain action on your site. But you have a problem - the site requires authorization. You will not constantly add before in each test for authorization on the site. Puppeteer allows you to log in to the site once, and then reuse this session in the future.
Virtual timers
You may already be using virtual timers. If you moved the slider in a developer tool that speeds up or slows down the animation (and washed your hands after that of course!), Then at that moment you used virtual timers in the browser.
The browser can use virtual timers instead of real ones to “scroll” time forward to speed up page loading or complete animation. Suppose you have the same test, you go to the main page, and there the animation for 30 seconds. It is not beneficial for anyone to have the test wait all this time. Therefore, you can simply speed up the animation so that it is completed instantly when the page loads, and your test continues.
You can stop the time while the network request is running.. For example, you test the reaction of your application to when a request that has gone to the backend takes a very long time to execute, or returns with an error. You can stop time - Puppeteer allows it.
On the slide below, there is another option: stop and continue the renderer. In experimental mode, it was possible to tell the browser not to render, and later, if necessary, request a screenshot. Then headless Chrome would quickly render everything, give a screenshot, and again stop drawing anything. Unfortunately, the developers have already managed to change the working principle of this API and there is no such function anymore.
A schematic view of the virtual timers below.
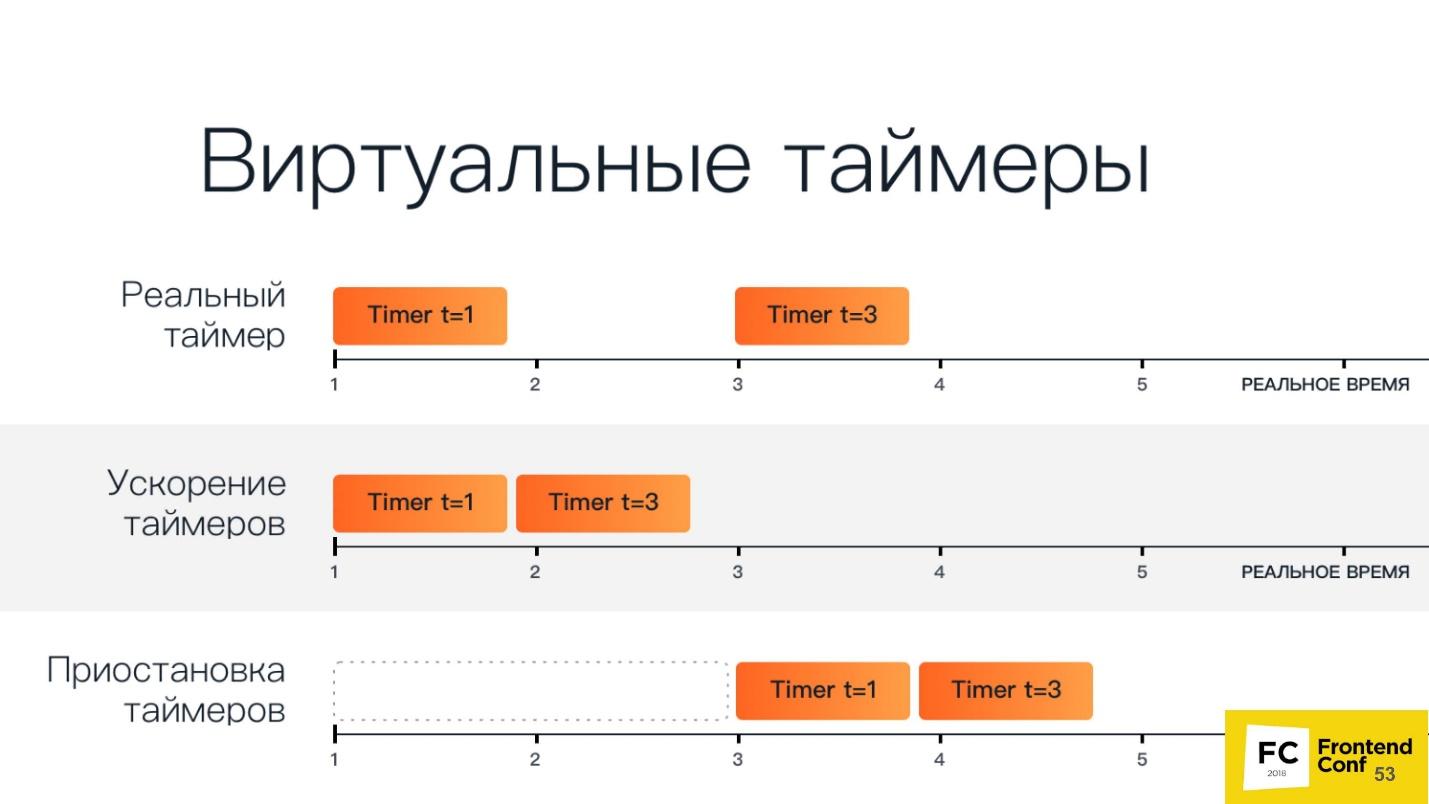
The top line has two regular timers: the first starts in the first unit of time and runs in one unit of time, the second starts in the third unit of time and runs in three units of time.
Speeding up timers - they start one after another. When we pause them, we have a period of time after which all timers start.
Consider this as an example. Below is a cut-off piece of code that essentially just loads the animation page from codepen.io and waits:
This demonstration of implementation during the presentation is just animation.
Now, using the Chrome DevTools protocol, we’ll send a method called Animation.setPlaybackRate, pass it a playbackRate with a value of 12 as parameters:
We load the same link, and the animashka began to work much faster. This is due to the fact that we used a virtual timer and accelerated the playback of animation by 12 times.
Let's do an experiment now - pass playbackRate: 0 - and see what happens. And it is here that : there is no animation at all, it does not play. Zero and negative values simply pause the entire animation completely.
Work with network requests
You can intercept network requests by setting the following flag:
In this mode, an additional event appears that fires when a network request is sent or received.
You can change the request on the fly . This means that you can completely change all its contents (body) and its headers, inspect, even cancel the request.
This is necessary in order to process authorization or authentication , including basic authentication via HTTP.
You can also do code coverage (JS / CSS) . With Puppeteer, you can automate all this. We all know utilities that can load a page, show which classes are used in it, etc. But are we satisfied with them? I think no.
Chrome DevTools protocol comes to the rescue:
In the first two lines, we launch a relatively new feature that allows you to find out the code coverage. Run JS and CSS, go to some page, then say - stop - and we can see the results. And these are not some imaginary results, but those that the browser sees due to the engine.
Among other things, there is already a plugin that for Puppeteer exports it all to Istanbul.
At the top of the Puppeteer pyramid is a script that you wrote on Node.js - it is like the godfather to all the bottom points.
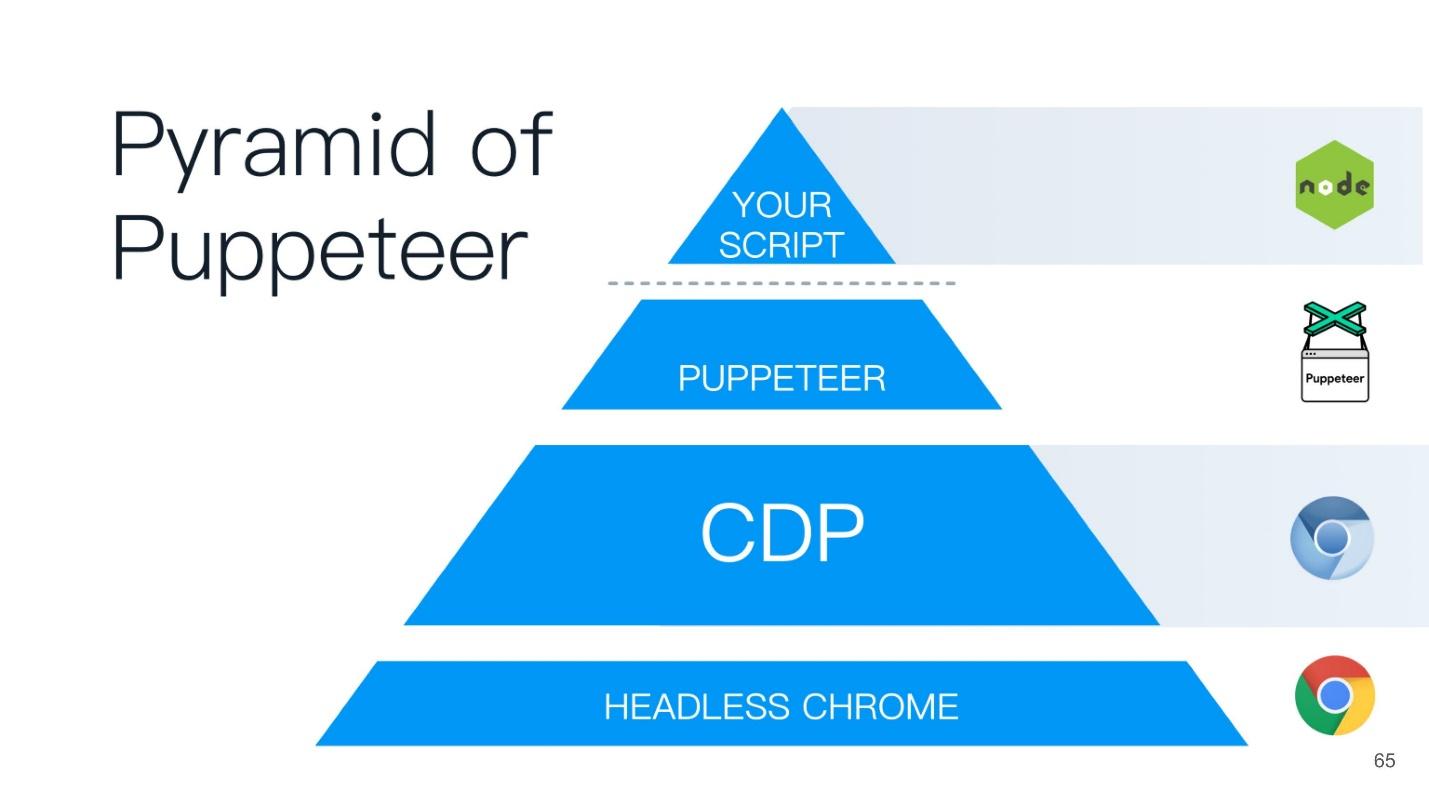
But ... "not everything is calm in the Danish kingdom ..." - as William Shakespeare wrote.
What is wrong with headless browsers?
Headless browsers have problems even though all of their cool features can do so much.
Difference in page rendering on different platforms
I really love this item and constantly talk about it. Let's look at this picture.

Here is a regular page with plain text: on the right - rendering in Chrome on Linux, on the left - under Windows. Those who test with screenshots know that a value is always set, called the “margin of error,” which determines when the screenshot is considered identical and when not.
In fact, the problem is that no matter how you try to set this threshold, the error will always go beyond this line, and you will still receive false positive results. This is due to the fact that all pages, and even web fonts, are rendered differently on all three platforms - on Windows according to one algorithm, on MacOS differently, on Linux in general a zoo. You cannot just take and test with screenshots .
You will say: “I just need a reference machine where I will run all these tests and compare screenshots.” But in fact, this is wildly inconvenient, because you have to wait for CI, and you want to check here locally on your machine whether you’ve broken something. If you have reference screenshots taken on a Linux machine, and you have a Mac, then there will be false results.
By the way, if you still want to test with screenshots, there is a wonderful article by Roman Dvornov, “ Unit-testing with screenshots: breaking the sound barrier ”. This is straight detective fiction.
Locks
Many large content providers do not like when you do scraping or get their content in an illegal way. Imagine that I am a major content provider and want to play the same game with you. There are two GET requests in two different browsers.
Can you guess where Chrome is here? The "both" option is not accepted - Chrome is only one. Most likely, you will not be able to answer this question, and I, as a major content provider, can: on the right - PhantomJS, and on the left - Chrome.

I can reach the point where I will detect your browsers (what exactly is Chrome or FireFox) by matching the order of the HTTP headers in your requests. If the host goes first - I clearly know - this is Chrome. Then I can not compare. Yes, of course, there are more complex algorithms - we check not only the order, but also the values, etc. etc. But it’s important that I can cast your headings, check who you are, and then just block you or not block you.
Unable to implement some features (Flash)
Have you ever studied in depth, directly hardcore, Flash in browsers? Somehow I looked in - then I didn’t sleep for six months.
We all remember how we used to watch YouTube when there was still Flash: the video is spinning, everything is fine. But at the moment when an embedded object is created on a page such as Flash, it always requests a real window from your OS. That is, in addition to your browser window, there was another window of your OS inside the Flash YouTube window. Flash cannot work unless you give it a real window — not just a real window, but a window that is visible on your screen. Therefore, some functions cannot be implemented in headless browsers, including Flash.
Full automation and bots
As I said earlier, large content providers are very afraid when you write spiders or grabbings that simply steal information that is provided for a fee.
Various tricks are used. There are articles on how to still detect headless browsers. I can say that you will not be able to detect headless browsers . All methods described there are bypassed. For example, there were detection methods using Canvas. I remember there was even one script that watched the mouse move around the screen and filled the Canvas. We are people and we move the mouse rather slowly, and Headless Chrome is much faster. The script understood that Canvas fills up too quickly - which means it is most likely headless Chrome. We also circumvented this, just slowing down the browser is not a problem.
There is no standard (single) API
If you watched headless implementations in other browsers - be it Safari or FireFox - there it is all implemented using the webdriver API. Chrome has the Chrome DevTools protocol. In Edge, nothing is clear at all - what is there, what is not.
WebGL?
People also ask for WebGL in headless mode. This link allows you to access the Google Chrome bug tracker. There, developers are actively voting for the implementation of headless-mode for WebGL, and already he can draw something. They are now simply restrained by hardware rendering. As soon as the implementation of hardware rendering is completed, then WebGL will automatically be available, that is, something can be done in the background.
But it is not all that bad!
We have a second player on the market - on May 11, 2018 there was newsthat Microsoft in its Edge browser has decided to implement almost the same protocol that is used in Google Chrome. They specially created a consortium where they are discussing a protocol that they want to bring to an industry standard so that you can take your script and run it under Edge, Chrome, and FireFox.
But there is one “but” - Microsoft Edge does not have a headless mode, unfortunately. They have a voting ballot where people write: “Give us a headless mode!” - but they are silent. Probably sawing something in secret.
TODO (conclusion)
I told all this so that you can come to your manager, or, if you are a manager, to the developer, and say: “That's it! We do not want Selenium anymore - give us Puppeteer! We will test in it. " If this happens, I will be glad.
But if you can learn, like me, browsers using Puppeteer, actively post bugs, or send a pull request, then I will be glad even more. This tool in OpenSource lies on GitHub, is written in Node.js - you can just borrow and contribute to it.
The case with Puppeteer is unique in that there are two teams working in Google: one deals specifically with Puppeteer, the other with headless mode. If a user finds a bug and writes about it on GitHub, then if this bug is not in Puppeteer, but in Headless Chrome, the bug goes to the Headless Chrome command. If they fix it there, then Puppeteer is updated very quickly. This results in a single ecosystem when the community helps improve the browser.
Therefore, I urge you to help improve the tool, which is used not only by you, but also by other developers and testers.
Contacts:
Under the cut components and features of Headless Chrome, interesting scenarios for using Headless Chrome. The second part about Puppeteer is a convenient Node.js library for managing Headless mode in Google Chrome and Chromium.
About the speaker: Vitaliy Slobodin - a former developer of PhantomJS - the one who closed it and buried it. Sometimes it helps Konstantin Tokarev ( annulen ) in the "resurrected" version of QtWebKit - the very QtWebKit, where there is support for ES6, Flexbox and many other modern standards.
Vitaliy loves exploring browsers, digging into WebKit, Chrome and so on in his free time, and more. We’ll talk about browsers today, namely about headless browsers and their entire ghost family.
What is a headless browser?
Already from the name it is clear that this is something without a head. In a browser context, this means the following.
- It does not have a real rendering of the content , that is, it draws everything in memory.
- Due to this, it consumes less memory , because there is no need to draw pictures or gigabyte PNGs that people try to put in the backend using a bomb.
- It works faster because it does not need to render anything on the real screen.
- Has a programming interface for management . You ask - he does not have an interface, buttons, windows? How to manage it? Therefore, of course, it has an interface for management.
- An important property is the ability to install on a bare Linux server . This is necessary so that if you have a freshly installed Ubuntu or Red Hat, you can just drop the binary or put the package in there, and the browser will work out of the box. No shamanism or voodoo magic is needed.
This is a typical WebKit-based browser. You can not get a grasp of the components - this is just a visual image.
We are only interested in the top component of the Browser UI. This is the same user interface - windows, menus, pop-up notifications and everything else.
This is what the headless browser looks like. Notice the difference? We completely remove the user interface. He is no more. Only the browser remains .
Today we will talk about Headless Chrome (). What is the difference between them? In fact, Chrome is a branded version of Chromium, which has proprietary codecs, the same H.264, integration with Google services and everything else. Chromium is just an open source implementation.
Headless Chrome date of birth: 2016. If you come across it, you can ask me a tricky question: “How so, I remember the news of 2017?” The fact is that a team of engineers from Google contacted the PhantomJS developers back in 2016, when they were just starting to implement Headless -mode in Chrome. We wrote whole Google Docks, how we will implement the interface and so on. Then Google wanted to make an interface fully compatible with PhantomJS. It was only then that the team of engineers came to the decision not to do such compatibility.
We'll talk about the management interface (API), which is the Chrome DevTools protocol, later and see what you can do with it.
This article will be built on the principle of the Puppeteer pyramid (from the English puppeteer). A good name is chosen - the puppeteer is the one who controls everyone else!
At the base of the pyramid is Headless Chrome - Headless Chrome - what is it?
Headless chrome
In the center - Headless browser - the same Chromium or Chrome (usually Chromium). It has the so-called renderers (RENDERER) - processes that draw the contents of the page (your window). Moreover, each tab needs its own renderer, so if you open many tabs, then Chrome will start as many processes for rendering.
On top of all this is your application. If we take Chromium or Headless Chrome, then Chrome will be on top of it, or some application in which you can embed it. The closest analogue can be called Steam. Everyone knows that in essence Steam is just a browser to the Steam website. He, of course, is not headless, but similar to this scheme.
There are 2 ways to embed headless Chrome in your application (or use it):
- Standard when you take Puppeteer and use Headless Chrome.
- When you take the Headless library component , that is, a library that implements headless mode, and embeds it into your application, for example, in C ++.
You may ask, why is C ++ on the front end? The answer is the DevTools C ++ API. You can implement and use the features of headless Chrome in different ways. If you use Puppeteer, communication with a headless browser will be done through web sockets. If you embed the Headless library in a desktop application, you will use the native interface, which is written in C ++.
But besides all this, you still have additional things, including:
- Custom networking - custom implementation of interaction with the network. Suppose you work in a bank or in a government agency that consists of three letters and starts with "F" and uses a very tricky authentication or authorization protocol that is not supported by browsers. Therefore, you may need a custom handler for your network. You can simply take your already implemented library and use it in Chrome.
- Mojo modules . The closest analogue of Mojo are the native binders in Node.js to your native libraries written in C ++. Mojo does the same - you take your native library, write a Mojo interface for it, and then you can call the methods of your native library in your browser.
Chromium Components
Again I hear a tricky question: “Why do I need this terrible scheme? I write under (insert the name of your favorite framework). ”
I believe that a developer should know how his tool works. If you write under React, you should know how React works. If you write under Angular, you should know what Angular has under the hood.
Because in the case of something, for example, a fatal error or a very serious bug in production, you have to deal with the guts, and you can just get lost there - where, what and how. If you, for example, write tests or use Headless Chrome, you too may encounter some of its strange behavior and bugs. Therefore, I will briefly tell you what Chromium has components. When you see a large stack trace, you will already know which way to dig and how to fix it at all.
The lowest level of the Platform layer . Its components:
- Ozone , the abstract window manager in Chrome, is what the window manager of the operating system interacts with. On Linux, it is either an X-server or Wayland. On Windows, it is a Windows window manager.
- Scheduler is the same scheduler without which we are nowhere, because we all know that Chrome is a multi-process application, and we need to somehow resolve all threads, processes and everything else.
- Net - the browser should always have a component for working with the network, for example, parsing HTTP, creating headers, editing, etc.
The Content layer is the largest component Chrome has. It includes:
- Blink is a WebCore-based web engine from WebKit. It can take HTML as a string, parse, execute JavaScript - and that’s it. He no longer knows how to do anything: neither work with the network, nor draw - all this happens on top of Blink.
Blink includes: a highly modified version of WebCore - a web engine for working with HTML and CSS; V8 (JavaScript engine); as well as an API for all extensions we use in Chrome, such as an ad blocker. It also includes the DevTools protocol. - The Content API is an interface with which you can very easily use all the features of the web engine. Since there are so many things inside Blink (probably more than a million interfaces), in order not to get lost in all these methods and functions, you need a Content API. You enter HTML, the engine will automatically process it, parse the DOM, build CSS OM, execute JavaScript, run timers, handlers, and everything else.
Level Headless of layer - the level of a headless browser:
- Headless library .
- Embedder API interface for embedding Headless library in the application.
- Client API is an interface that Puppeteer uses.
Application level the Application of layer :
- Your application ( Embedding app );
- Gadgets, for example, Headless shell .
Now let's rise from the depths a little higher, activate - now the frontend will go.
Chrome DevTools protocol
We all came across the Chrome DevTools protocol, because we use the developer panel in Chrome or the remote debugger - the same development tools. If you run the developer tools remotely, communication with the browser occurs using the DevTools protocol. When you install debugger, see code coverage, use geolocation or something else - all this is controlled using DevTools.
In fact, the DevTools protocol itself has a huge number of methods. Your developer tool does not have access, probably to 80% of them. Really, you can do everything there!
Let's see what this protocol is all about. In fact, it is very simple. It has 2 components:
- DevTools target — the tab you are inspecting;
- DevTools client - let's say this is a developer panel that is launched remotely.
They communicate using simple JSON:
- There is an identifier for the command, the name of the method to be executed, and some parameters.
- We send a request and get an answer that also looks very simple: an identifier that is needed because all the commands that are executed using the protocol are asynchronous. In order for us to always be able to compare which response to which team we received, we need an identifier.
- Is there a result. In our case, it is a result object with the following attributes: type: "number", value: 2, description: "2" , no exception was thrown: wasThrown: false.
But among other things, your tab can send events back to you. Suppose when an event on a page occurred, or there was an exception on a page, you will receive a notification through this protocol.
Puppeteer
You can install Puppeteer using your favorite package manager - be it yarn, npm or any other.
Using it is also easy - just request it in your Node.js script, and you can already use it.
Using the link https://try-puppeteer.appspot.com, you can write a script directly on the site, execute it and get the result directly in the browser. All this will be implemented using Headless Chrome.
Consider the simplest script under Node.js:
const puppeteer = require('puppeteer');
(async() => {
const browser = await puppeteer.launch() ;
const page = await browser.newPage();
await page.goto('http://devconf.ru/') ;
await page.emulateMedia('screen') ;
await page.pdf({
path: './devconf.pdf,
printBackground: true
});
await browser.close() ;
})();
Here we simply open the page and print it in PDF. Let's see the operation of this script in real time:
Everything will be cool, but it is not clear what is inside. Of course, we have a headless browser, but we don’t see anything. Therefore, Puppeteer has a special flag called headless: false:
const browser = await puppeteer.launch({
headless: false
});
It is needed to launch the headless browser in headful mode, when you can see some window and see what happens to your page in real time, that is, how your script interacts with your page.
This will look the same script when we add this flag. A browser window appears on the left - more clearly.
Pros of Puppeteer:
+ This is the Node.js library for Chrome headless.
+ Support for legacy versions of Node.js> = 6.
+ Easy installation.
+ High-level API for managing this entire giant machine.
Headless Chrome installs easily and without system intervention. At the first installation, Puppeteer downloads the version of Chromium and installs it directly in the node_modules folder specifically for your architecture and OS. You do not need to download anything extra, it does this automatically. You can also use your favorite version of Chrome, which is installed on your system. You can do this too - Puppeteer provides you with such an API.
Unfortunately, there are also disadvantages, if we take just the basic installation.
Cons Puppeteer :
- No top-level functions : synchronization of bookmarks and passwords; profile support; hardware acceleration etc.
- Software rendering is the most significant minus. All calculations and rendering take place on your CPU. But here, Google engineers will soon surprise us - work on the implementation of hardware acceleration is already underway. Already now you can try to use it if you are brave and courageous.
- Until recently, there was no support for extensions - now there is! If you are a cunning developer, you can take your favorite AdBlock, specify how Puppeteer will use it, and all ads will be blocked.
- No audio / video support . Because, well, why headless-browser audio and video.
What can Puppeteer:
- Isolation Sessions.
- Virtual timers.
- Interception of network requests.
And a couple of cool things that I will show a little further.
Session Isolation
What is it, what is it eaten with, and will we not choke? - Do not choke!
Session isolation is a separate “repository” for each tab . When you start Puppeteer, you can create a new page, and each new page can have its own repository, including:
- cookes
- local storage;
- cache.
All pages will live independently of each other. This is necessary, for example, to maintain the atomicity of the tests.
Session isolation saves resources and time when starting parallel sessions . Suppose you are testing a site that is being built in development mode, that is, bundle are not minimized, and weigh 20 MB. If you just want to cache it, you can tell Puppeteer to use a cache common to all pages that are created, and this bundle will be cached.
You can serialize sessions for later use.. You write a test that checks a certain action on your site. But you have a problem - the site requires authorization. You will not constantly add before in each test for authorization on the site. Puppeteer allows you to log in to the site once, and then reuse this session in the future.
Virtual timers
You may already be using virtual timers. If you moved the slider in a developer tool that speeds up or slows down the animation (and washed your hands after that of course!), Then at that moment you used virtual timers in the browser.
The browser can use virtual timers instead of real ones to “scroll” time forward to speed up page loading or complete animation. Suppose you have the same test, you go to the main page, and there the animation for 30 seconds. It is not beneficial for anyone to have the test wait all this time. Therefore, you can simply speed up the animation so that it is completed instantly when the page loads, and your test continues.
You can stop the time while the network request is running.. For example, you test the reaction of your application to when a request that has gone to the backend takes a very long time to execute, or returns with an error. You can stop time - Puppeteer allows it.
On the slide below, there is another option: stop and continue the renderer. In experimental mode, it was possible to tell the browser not to render, and later, if necessary, request a screenshot. Then headless Chrome would quickly render everything, give a screenshot, and again stop drawing anything. Unfortunately, the developers have already managed to change the working principle of this API and there is no such function anymore.
A schematic view of the virtual timers below.
The top line has two regular timers: the first starts in the first unit of time and runs in one unit of time, the second starts in the third unit of time and runs in three units of time.
Speeding up timers - they start one after another. When we pause them, we have a period of time after which all timers start.
Consider this as an example. Below is a cut-off piece of code that essentially just loads the animation page from codepen.io and waits:
(async() => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
const url = ‘https ://codepen.o/ajerez/full/EaEEOW/'; // # 1
await page.goto(url, { waitUnitl: 'load' }); // # 2
})();
This demonstration of implementation during the presentation is just animation.
Now, using the Chrome DevTools protocol, we’ll send a method called Animation.setPlaybackRate, pass it a playbackRate with a value of 12 as parameters:
const url = 'https://codepen.o/ajerez/full/EaEEOW/'; // # 1
await page._client.send('Animation.setPlaybackRate', { playbackRate: 12 }); // # 3
await page.goto(url, { waitUntil: 'load' }); // # 2
We load the same link, and the animashka began to work much faster. This is due to the fact that we used a virtual timer and accelerated the playback of animation by 12 times.
Let's do an experiment now - pass playbackRate: 0 - and see what happens. And it is here that : there is no animation at all, it does not play. Zero and negative values simply pause the entire animation completely.
Work with network requests
You can intercept network requests by setting the following flag:
await page.setRequestlnterception(true);In this mode, an additional event appears that fires when a network request is sent or received.
You can change the request on the fly . This means that you can completely change all its contents (body) and its headers, inspect, even cancel the request.
This is necessary in order to process authorization or authentication , including basic authentication via HTTP.
You can also do code coverage (JS / CSS) . With Puppeteer, you can automate all this. We all know utilities that can load a page, show which classes are used in it, etc. But are we satisfied with them? I think no.
The browser knows better which selectors and classes are used - it's a browser! He always knows which JavaScript executed, which not, which CSS is used, which not.
Chrome DevTools protocol comes to the rescue:
await Promise.all ( [
page.coverage.startJSCoverage(),
page.coverage.startCSSCoverage()
]);
await page.goto(’https://example.com’);
const [jsCoverage, cssCoverage] = await Promise,all([
page.coverage.stopJSCoverage(), page.coverage.stopCSSCoverage()
]):
In the first two lines, we launch a relatively new feature that allows you to find out the code coverage. Run JS and CSS, go to some page, then say - stop - and we can see the results. And these are not some imaginary results, but those that the browser sees due to the engine.
Among other things, there is already a plugin that for Puppeteer exports it all to Istanbul.
At the top of the Puppeteer pyramid is a script that you wrote on Node.js - it is like the godfather to all the bottom points.
But ... "not everything is calm in the Danish kingdom ..." - as William Shakespeare wrote.
What is wrong with headless browsers?
Headless browsers have problems even though all of their cool features can do so much.
Difference in page rendering on different platforms
I really love this item and constantly talk about it. Let's look at this picture.
Here is a regular page with plain text: on the right - rendering in Chrome on Linux, on the left - under Windows. Those who test with screenshots know that a value is always set, called the “margin of error,” which determines when the screenshot is considered identical and when not.
In fact, the problem is that no matter how you try to set this threshold, the error will always go beyond this line, and you will still receive false positive results. This is due to the fact that all pages, and even web fonts, are rendered differently on all three platforms - on Windows according to one algorithm, on MacOS differently, on Linux in general a zoo. You cannot just take and test with screenshots .
You will say: “I just need a reference machine where I will run all these tests and compare screenshots.” But in fact, this is wildly inconvenient, because you have to wait for CI, and you want to check here locally on your machine whether you’ve broken something. If you have reference screenshots taken on a Linux machine, and you have a Mac, then there will be false results.
Therefore, I say that do not test with screenshots at all - forget it.
By the way, if you still want to test with screenshots, there is a wonderful article by Roman Dvornov, “ Unit-testing with screenshots: breaking the sound barrier ”. This is straight detective fiction.
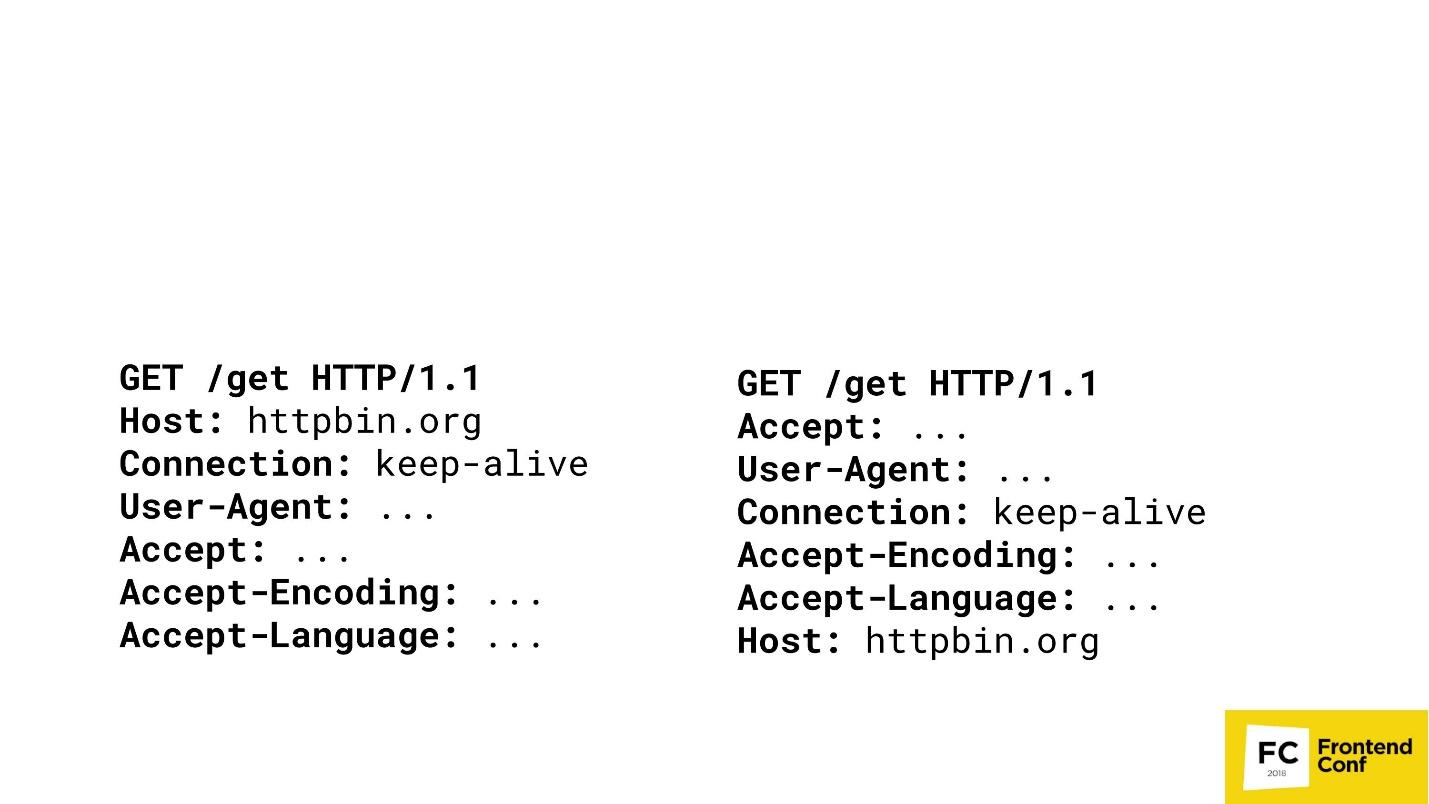
Locks
Many large content providers do not like when you do scraping or get their content in an illegal way. Imagine that I am a major content provider and want to play the same game with you. There are two GET requests in two different browsers.
Can you guess where Chrome is here? The "both" option is not accepted - Chrome is only one. Most likely, you will not be able to answer this question, and I, as a major content provider, can: on the right - PhantomJS, and on the left - Chrome.
I can reach the point where I will detect your browsers (what exactly is Chrome or FireFox) by matching the order of the HTTP headers in your requests. If the host goes first - I clearly know - this is Chrome. Then I can not compare. Yes, of course, there are more complex algorithms - we check not only the order, but also the values, etc. etc. But it’s important that I can cast your headings, check who you are, and then just block you or not block you.
Unable to implement some features (Flash)
Have you ever studied in depth, directly hardcore, Flash in browsers? Somehow I looked in - then I didn’t sleep for six months.
We all remember how we used to watch YouTube when there was still Flash: the video is spinning, everything is fine. But at the moment when an embedded object is created on a page such as Flash, it always requests a real window from your OS. That is, in addition to your browser window, there was another window of your OS inside the Flash YouTube window. Flash cannot work unless you give it a real window — not just a real window, but a window that is visible on your screen. Therefore, some functions cannot be implemented in headless browsers, including Flash.
Full automation and bots
As I said earlier, large content providers are very afraid when you write spiders or grabbings that simply steal information that is provided for a fee.
Various tricks are used. There are articles on how to still detect headless browsers. I can say that you will not be able to detect headless browsers . All methods described there are bypassed. For example, there were detection methods using Canvas. I remember there was even one script that watched the mouse move around the screen and filled the Canvas. We are people and we move the mouse rather slowly, and Headless Chrome is much faster. The script understood that Canvas fills up too quickly - which means it is most likely headless Chrome. We also circumvented this, just slowing down the browser is not a problem.
There is no standard (single) API
If you watched headless implementations in other browsers - be it Safari or FireFox - there it is all implemented using the webdriver API. Chrome has the Chrome DevTools protocol. In Edge, nothing is clear at all - what is there, what is not.
WebGL?
People also ask for WebGL in headless mode. This link allows you to access the Google Chrome bug tracker. There, developers are actively voting for the implementation of headless-mode for WebGL, and already he can draw something. They are now simply restrained by hardware rendering. As soon as the implementation of hardware rendering is completed, then WebGL will automatically be available, that is, something can be done in the background.
But it is not all that bad!
We have a second player on the market - on May 11, 2018 there was newsthat Microsoft in its Edge browser has decided to implement almost the same protocol that is used in Google Chrome. They specially created a consortium where they are discussing a protocol that they want to bring to an industry standard so that you can take your script and run it under Edge, Chrome, and FireFox.
But there is one “but” - Microsoft Edge does not have a headless mode, unfortunately. They have a voting ballot where people write: “Give us a headless mode!” - but they are silent. Probably sawing something in secret.
TODO (conclusion)
I told all this so that you can come to your manager, or, if you are a manager, to the developer, and say: “That's it! We do not want Selenium anymore - give us Puppeteer! We will test in it. " If this happens, I will be glad.
But if you can learn, like me, browsers using Puppeteer, actively post bugs, or send a pull request, then I will be glad even more. This tool in OpenSource lies on GitHub, is written in Node.js - you can just borrow and contribute to it.
The case with Puppeteer is unique in that there are two teams working in Google: one deals specifically with Puppeteer, the other with headless mode. If a user finds a bug and writes about it on GitHub, then if this bug is not in Puppeteer, but in Headless Chrome, the bug goes to the Headless Chrome command. If they fix it there, then Puppeteer is updated very quickly. This results in a single ecosystem when the community helps improve the browser.
Therefore, I urge you to help improve the tool, which is used not only by you, but also by other developers and testers.
Contacts:
- github.com/vitallium
- vk.com/vitallium
- twitter.com/vitalliumm
Frontend Conf Moscow - a specialized conference of front-end developers will be held on October 4 and 5 in Moscow , in Infospace. A list of accepted reports has already been published on the conference website.
In our newsletter we regularly do thematic reviews of speeches, talk about the transcripts that have been released and future events - sign up to receive the news first.
And this is a link to our Youtube channel on the front end, it contains all the speeches related to the development of the client part of the projects.