KDD 2018, the fifth and final day

That ended the fifth, the last day of KDD. It was possible to hear some interesting reports from Facebook and Google AI, to remember football tactics and to generate some chemicals. This and not only - under the cut. See you next year in Anchorage, the capital of Alaska!
On Big Data Learning for Small Data Problems
The morning report from the Chinese professor was hard. The speaker was clearly a freebie in preparation, often lost, began to skip slides, and instead of talking for life he tried to load sleepy brain with mathematics.
The general outline of the story revolved around the idea that there is not always a lot of data. There are, for example, a long tail with many different examples. There are datasets with a large number of classes, which, although large, are in themselves, but there are only a few entries for each class. As an example of such a dataset, Omniglot cited- handwritten characters from 50 alphabets, 1623 classes and 20 pictures per class on average. But in fact, in this perspective, datasets of recommendation tasks can also be considered, when we have a lot of users and not so many ratings for each of them individually.
What can be done to make life easier for ML in this situation? Firstly. try to bring into it the knowledge of the subject area. This can be done in different forms: this is engineering of features, and specific regularizations, and refinement of the network architecture. Another common solution is transfer learning, I think almost everyone who worked with pictures started with additional training of some ImageNet on their data. In the case of Omniglot, the natural donor for the transfer will be MNIST .
One of the forms of transfer can be multi-task learning , about which we have already spoken several times on KDD. The development of MTL can be considered the meta learning approach - by teaching the algorithm to sample from a multitude of tasks, we can LEARN not only parameters, but also hyper parameters (of course, only if our procedure is differentiable).
Continuing the topic of multi-task, you can come to the concept of lifelong continuous learning, which can be most clearly shown on the example of robotics. The robot must be able to solve different tasks, and use the previous experience when learning a new task. But you can consider this approach on the example of Omniglot: having learned one of the symbols, you can proceed to learning the next one, using the experience gained. However, on this road we are waiting for a dangerous problem.catastrophic forgetting when the algorithm begins to forget what he learned before (advises EWC regularization to combat this ).
In addition, the speaker spoke about several of his works in this direction.
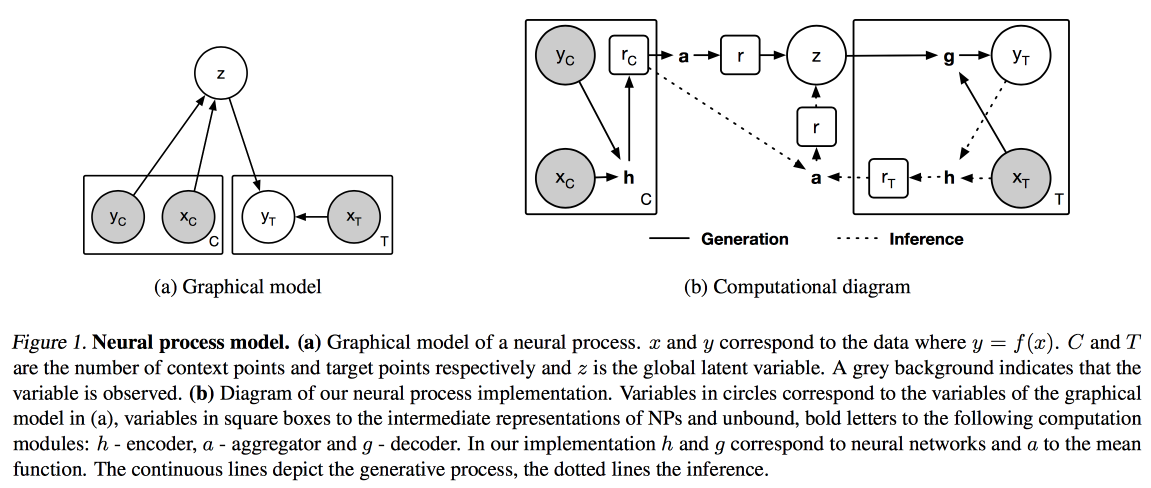
Neural Processes (Gaussian process analogy for neural networks) and Distil and Transfer Learning (transfer learning optimization for the case when we do not take a previously trained model as a basis, but teach our own in multi-task mode).
Images And Texts
Today I decided to walk on the application reports, in the morning about working with texts, images and video.
Corpus Conversion Service
The frequency of publications is growing very quickly, it is difficult to work with this, especially considering that almost the entire search is conducted according to the text. IBM offers its services for the marking of buildings Scientific knowledge 3.0. The main workflow looks like this:
- Parsim PDF, recognize the text in the pictures.
- We check if there is a model for the given form of the text, if there is - we make a semantic extract with its help.
- If there is no model, we send for annotation and train.
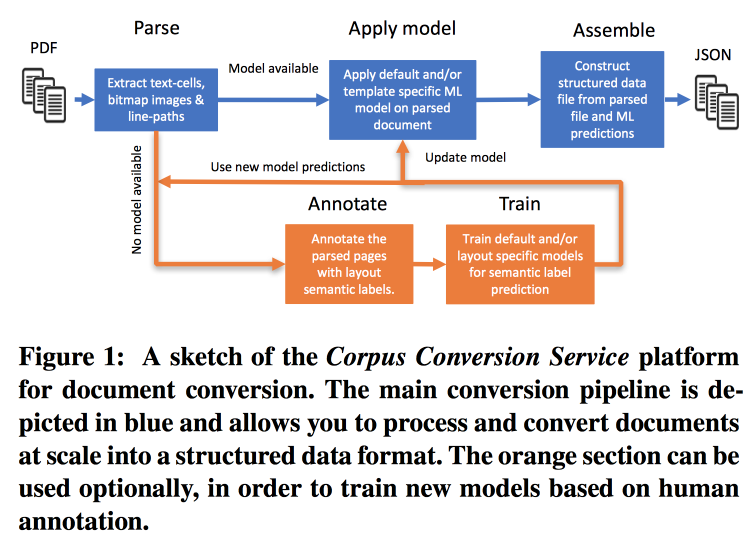
To train models, we start with clustering by structure. Within the cluster using crowdsourcing we mark several pages. It turns out to achieve accuracy> 98% when training on the markup of 200-300 documents. There is a strong class imbalance in the markup (almost everything is marked up as text), so you need to look at the accuracy of all classes and the confusion matrix.
Models have a hierarchical structure. For example, one model recognizes a table, and another cuts into rows / columns / headers (and yes, a table can be nested in a table). A convolutional network is used as a model.
For all this, we assembled a pipeline on Docker with Kubernetes and are ready for a reasonable fee to load your body of texts. They can work not only with text PDF, but also with scans, they support oriental languages. In addition to simply pulling out the text, they are working on extracting the knowledge graph, promising to give details on the next KDD.
Rare Query Expansion Through Generative Adversarial Networks in Search Advertising
Search engines earn the most money from advertising, and advertising is shown depending on what the user was looking for. But the comparison is not always obvious. For example, at the request of airline tickets, displaying cheap bus tickets advertising is not very correct, but expedia will go well, but you cannot understand this by keywords. Machine learning models can help, but they do not work well with rare queries.
To solve this problem for expanding the search query, we will train the Conditional GAN on the sequence-to-sequence model. We use recurrent networks (2-layer GRU) as architecture. We modify the min-max from GAN, trying to aim it at adding keywords for which there were clicks on advertising.
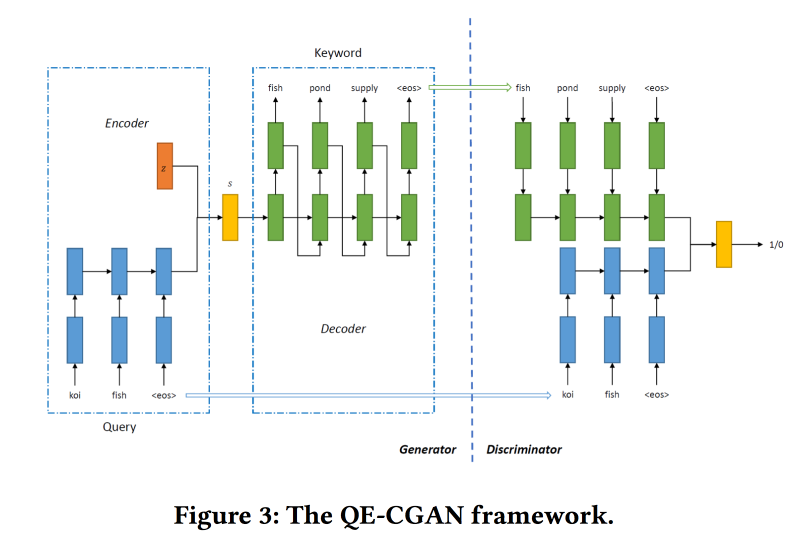
Dataset for training on 14 million requests and 4 million advertising keywords. The proposed model works best on the long tail of the query, for which it was done. But in my head the performance is not higher.
Collaborative Deep Metric Learning for Video Understanding
The work is presented by guys from Google AI. They want to build good embeddings for video, so that they can be used in similar videos, recommendations, automatic annotations, etc. Works as follows:
- From the video, sample frames are a picture and a piece of audio track.
- Extract images from features kotoyre previously learned Inception .
- We do the same with the audio fragment (the specific network architecture was not shown). On the received signs we hang fully connected grids with a frame pooling. Normalized to L2.
- Next interesting point - we are trying to ensure that similar videos are close to the point of view of collaborative similarity. To do this, we use triplet loss in training (we take an object, sample it similar and different, ensure that embeddings of the unlike are farther from the original than the similar). Do not forget that you need to use negative mining.

They are used for cold start in similar videos, but there are a couple of problems: by visual similarity, you can find video in another language or video on another topic (especially relevant for board and lecturer video). It is advised to use additional meta-information about the video.
There is a problem with recommendations: you need to match your browsing history and 5 billion videos from Youtube. To speed up the work, we predict for the user the vector of average embedding of viewed videos. Checked on movielens , dragged trailers from Youtube for analysis. It was shown that for users with a small number of ratings it works better.
In the task of annotating a video, the mixture of experts approach is used : they teach logreg on embedding for each possible annotation. Checked onYoutube-8 and showed a very good result.
Name Disambiguation in AMiner: Clustering, Maintenance, and Human in the Loop
AMiner is a graph for the academy that provides various services for working with literature. One of the problems is the collision of authors' names and entities. For the solution , an automatic algorithm is proposed with some form of active additional training.
The process consists of three stages: using text search, we collect candidates (documents with similar names of authors), cluster (with automatic determination of the number of clusters) and build profiles.

To consider the similarity in clustering, you need some kind of representation (emuding). It can be obtained using the global model (across the whole graph) or local (for those candidates that were sampled). Global catches patterns that can be transferred to new documents, and local helps to take into account individual features - we will combine. For global embeddings, they also use a Siamese network trained in triplet loss, and for local ones, they use a graph autoencoder (they left the pictures in the article for the sake of space).
The most painful question is how many clusters to do? X-means approachdoes not scale to a large number of clusters; RNN is used to predict their number: from the marked-up set, K clusters are first sampled, then N examples from these clusters. Train the network to reveal the original number of clusters.

The data arrive fairly quickly, 500 thousand per month, but the sweep of the entire model takes weeks. Used for quick initialization of the selection of candidates for text search and CNN for global embedding. An important point: the process of learning includes people who mark what should and what should not get into the cluster. The model is retrained on this data.
Rosetta: Large scale system
The guys from FB will present their decision to extract texts from pictures. The model works in two stages: the first network determines the text, the second recognizes it. Faster-RCNN was used as a detector with the replacement of ResNet by SuffleNet to speed up the work. ResNet18 was used for recognition and trained with CTC loss .
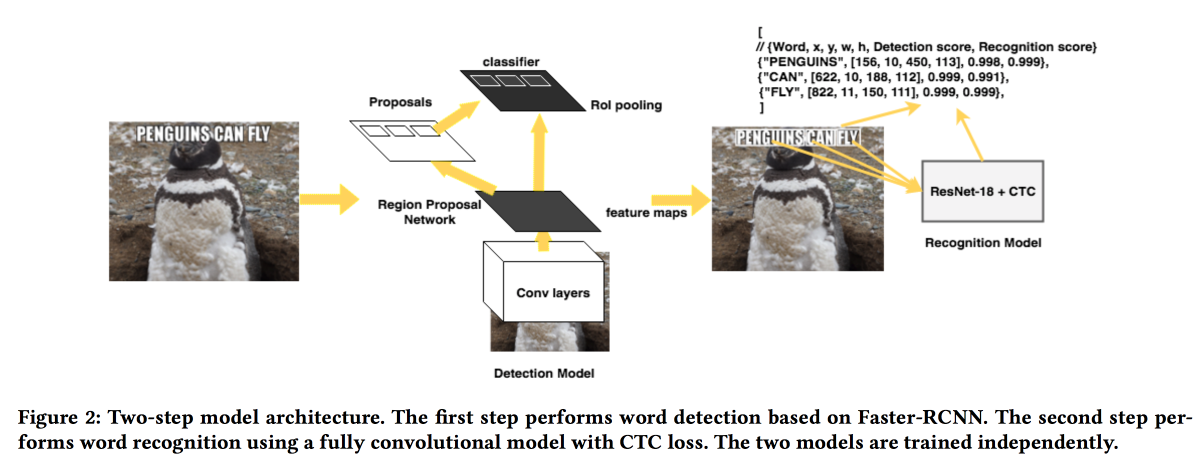
To improve the convergence used several tricks:
- When training, a little noise was introduced into the detector result.
- Spread the text horizontally by 20%.
- Used curriculum learning - gradually complicate the examples (by the number of characters).
Natural science
The last content section at the conference was devoted to the “natural sciences”. A little chemistry, football and more.
False Discovery Rate Control
Very interesting work on the analysis of A / B tests. The problem with most analysis systems is that they look at the average effect, whereas in reality, some users most often react positively to the change, and some negatively, and more can be achieved if you understand who has come in and who not.

It is possible to divide users into cohorts in advance and evaluate the effect by them, but as the number of cohorts increases, the number of false positives increases (you can try to reduce them using the Bonferoni method , but it is too conservative). In addition, you need to know the cohorts in advance. The guys propose to use a combination of several approaches: to combine a mechanism for detecting a heterogeneous effect (HTE) with methods of filtering false positives.
To detect a heterogeneous effect, a matrix is transformed with
x=0/1(in a group or not) and an effect into a matrix in which a 0/1number lies instead (x — p)/p(1-p), where pis the probability of inclusion in the test. Further, a model for predicting the effect of x(linear or lasso regression) is trained . Those users for whom the result is significantly different from the forecast are candidates for selection in the "heterogeneous" effect. Next, for the filter false positives tried two methods: Benjamini-Hochberg and Knockoffs . The first is much easier to implement, but the second is more flexible and showed more interesting results.
Winner's Curse: Online Controlled Experiments
The guys from AirBnB little talked about how the improved experimental analysis system. The main problem is that when experimenting a lot of bias, in this paper we considered selection bias - we select experiments with the best observable result, but this means that we will more often select experiments in which the observed result is overestimated relative to the real one.
As a result, when combining experiments, the final effect is less than the sum of the effects of the experiments. But knowing this bias, you can try to estimate and subtract it using a statistical apparatus (assuming that the difference between the real and observed effects is normally distributed). In short, something like this:

And if you add a bootstrapthen one can even build confidence intervals for the unbiased effect estimate.
Automatic Discovery of Tactics in Spatio-Temporal Soccer Match Data
Interesting work on the disclosure of football teams tactics. Match data is available in the form of sequences of actions (pass / touch / hit, etc.), about 2000 actions per match. Combine continuous (coordinates / time) and discrete (player) attributes. It is important to expand the data using knowledge of the subject area (add a player’s role and pass type, for example), but this does not always work. In addition, different types of users are interested in different types of patterns: the coach is successful, the attacker is protective, the journalist is unique.
The proposed method is as follows:
- We divide the flow into phases according to the transition of the ball between the teams.
- We cluster the phases as a distance using dynamic time warping . How to determine the number of clusters is not told.
- We rank the clusters according to the goal (for whom we are looking for tactics).
- Mine patterns inside the cluster (sequential pattern mining CM-SPADE ), disperse the coordinates on the field segments (left / right flank, middle, penalties).
- We rank the patterns again.
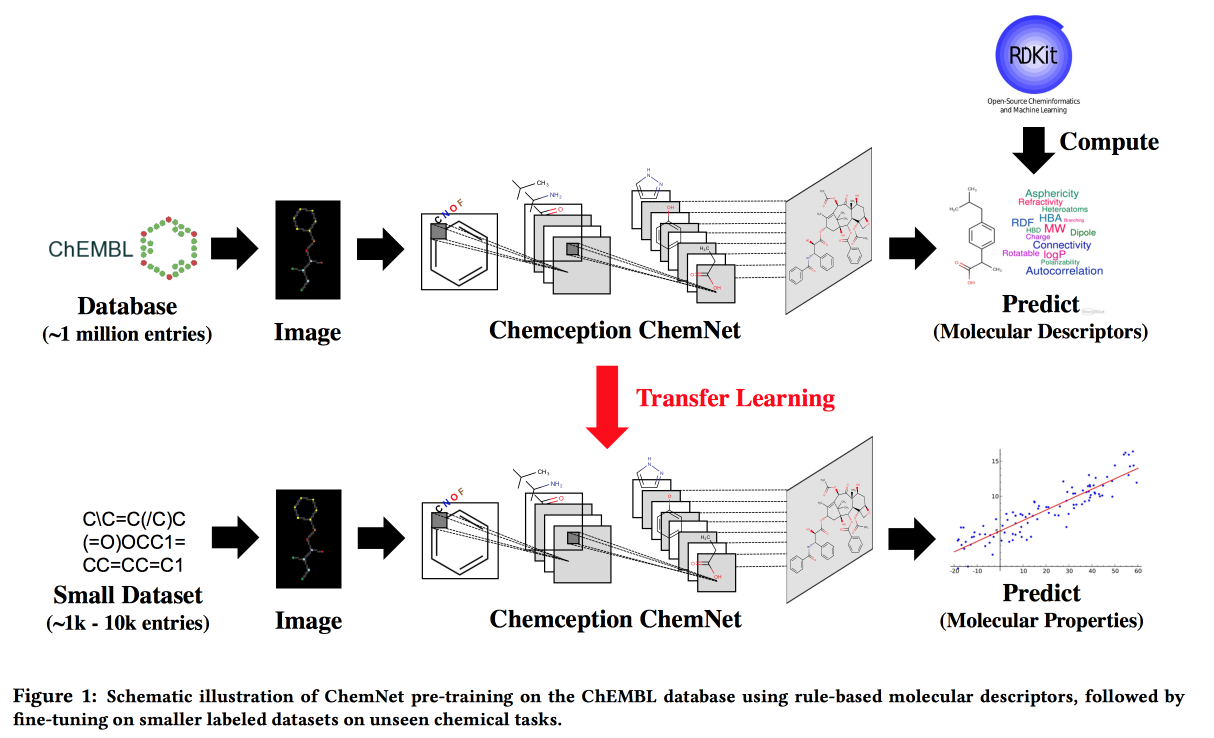
Using Rule-Based Labels for Weak Supervised Learning: A ChemNet for Transferable Chemical Property P
Work for situations where there is no big data, but there are theoretical models with hierarchical rules. Using theory, we build an "expert" neural network. Apply to the task of developing chemical compounds with desired properties.
I would like by analogy with pictures to get a network in which the layers will correspond to different levels of abstraction: atoms / functional groups / fragments / molecules. In the past, there were approaches for large tagged datasets, for example, SMILE2Vect: use SMILE to translate a formula into text, and then apply embedding techniques for texts.
But what to do if there is no big marked dataset? Learn ChemNet with RDKitfor those goals that he can predict, and then do transfer learning to solve the desired problem. We show that we can compete with models that are trained on labeled data. You can learn in layers, and thus achieve the goal - to divide the layers into levels of abstraction.
PrePeP - A Tool for the Identification of Pan Assay Interference Compounds
We develop drugs , use data science to select candidates. There are molecules that react with many substances. They can not be used as drugs, but often float in the initial stages of the test. Such PAINS molecules will be filtered.
There are difficulties: the data are sparse and arrogant (107 thousand), the classes are unbalanced (positives 0.5%), and chemists want to get an interpretable model. Combining data from graph structure ( gSpan ) molecules and chemical fingerprints. They struggled with balance using baging with undersampling negatives, taught trees, forecasts aggregated by a majority vote.