Why you should not throw out the Radeon, if you are carried away by machine learning?

I had to collect my workstation as a student. It is quite logical that I preferred AMD computing solutions. because itcheapprofitable in terms of price / quality ratio. I picked up the components for a long time, and eventually ended up at 40k with a set of FX-8320 and RX-460 2GB. At first this kit seemed perfect! My roommate and I had a little Monero mine, and my set showed 650h / s versus 550h / s on a set of i5-85xx and Nvidia 1050Ti. True, from my set in the room it was a little hot at night, but it was decided when I purchased a tower cooler for the CPU.
The tale is over
Everything was just like a fairy tale until I became interested in machine learning in the field of computer vision. Even more precisely - until I had to work with input images with a resolution of more than 100x100px (up to this point, my 8-core FX played up briskly). The first difficulty was the task of determining emotions. 4 layers of ResNet, an input image of 100x100 and 3000 images in a training set. And now - 9 hours of learning 150 epochs on the CPU.
Of course, because of this delay, the iterative development process suffers. At work, we had Nvidia 1060 6GB and training of a similar structure (although there was a regression study to localize objects) on it flew in 15-20 minutes - 8 seconds per era from 3.5k images. When you have such a contrast under your nose, breathing becomes even more difficult.
Well, guess my first move after all this? Yes, I went to bargain for 1050Ti from my neighbor. With arguments about the uselessness of CUDA for him, with the offer of exchange for my card with a surcharge. But all in vain. And now I'm posting my RX 460 on Avito and reviewing the cherished 1050Ti on Citylink and TechnoPoint sites. Even if the card was successfully sold, I would have to find another 10k (I am a student, albeit a working one).
Okay. I'm going to google how to use a radeon under Tensorflow. Knowing that this is an exotic task, I did not particularly hope to find something sensible. Collect under Ubuntu, start it or not, get a brick - phrases snatched from the forums.
And so I went the other way - I'm not googling "Tensorflow AMD Radeon", but "Keras AMD Radeon". I instantly throws on the page PlaidML . I get it in 15 minutes (although I had to drop Keras to 2.0.5) and put on a network to learn. The first observation is that the era is 35 seconds instead of 200.
Climb climb
The authors PlaidML - vertex.ai , included in the project group Intel (!). The goal of the development is maximum cross-platform. Of course, this adds confidence to the product. Their article says that PlaidML is competitive with Tensorflow 1.3 + cuDNN 6 due to "thorough optimization".
However, we will continue. Next articleto some extent reveals the internal structure of the library. The main difference from all other frameworks is the automatic generation of computing cores (in Tensorflow notation, “core” is the complete process of performing a specific operation in a graph). For the automatic generation of nuclei in PlaidML, the exact dimensions of all tensors, constants, steps, the dimensions of convolutions and the boundary values with which we will have to work further are very important. For example, it is argued that the further creation of effective kernels is different for batchsize 1 and 32, or for bundles of size 3x3 and 7x7. Having this data, the framework itself will generate the most efficient way to parallelize and execute all operations for a particular device with specific characteristics. If you look at Tensorflow,vary greatly for single-threaded, multi-threaded, or CUDA-compatible cores. Those. PlaidML is clearly more flexible.
We go further. The implementation is written in the Tile self-written language . This language has the following main advantages - the proximity of syntax to mathematical notations (and go crazy!):
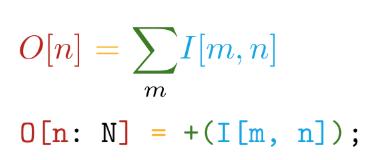
And automatic differentiation of all declared operations. For example, in TensorFlow, when creating a new user operation, it is strongly recommended to write a function for calculating gradients. Thus, when creating our own operations in the Tile language, we only need to say WHAT we want to calculate, without thinking about HOW to consider this with regard to hardware devices.
Additionally, optimization of work with DRAM and L1 cache analogue in the GPU is performed. Recall the schematic device:
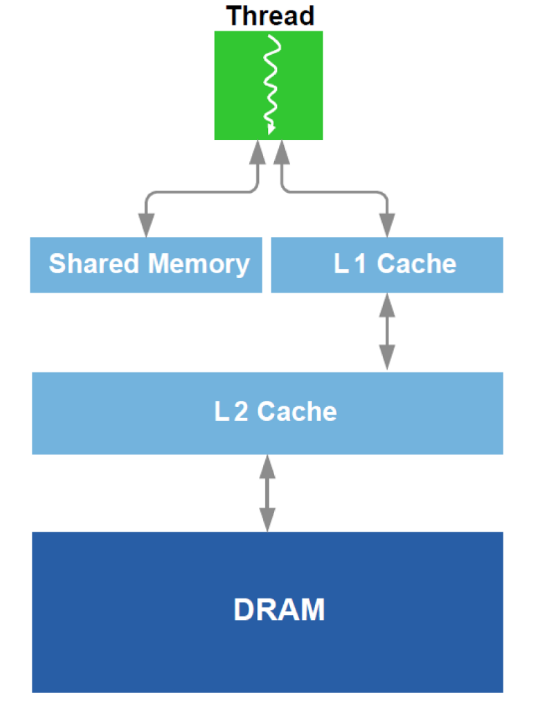
For optimization, all available hardware data is used — cache size, cache line width, DRAM bandwidth, and so on. The main methods are to ensure the simultaneous reading of sufficiently large blocks from DRAM (an attempt to avoid addressing in different areas) and to ensure that the data loaded into the cache is used several times (an attempt to avoid reloading the same data several times).
All optimizations take place during the first epoch of training, while greatly increasing the time of the first run:
In addition, it is worth noting that this framework is tied to OpenCL . The main advantage of OpenCL is that it is a standard for heterogeneous systems and nothing prevents you from running the kernel on the CPU . Yes, it is here that lies one of the main secrets of the cross-platform PlaidML.
Conclusion
Of course, training on the RX 460 is still 5-6 times slower than 1060, but you can compare the price categories of video cards! Then I got the RX 580 8gb (I was lent!) And the runtime of the epoch was reduced to 20 seconds, which is almost comparable.
The vertex.ai blog has honest graphics (more is better):
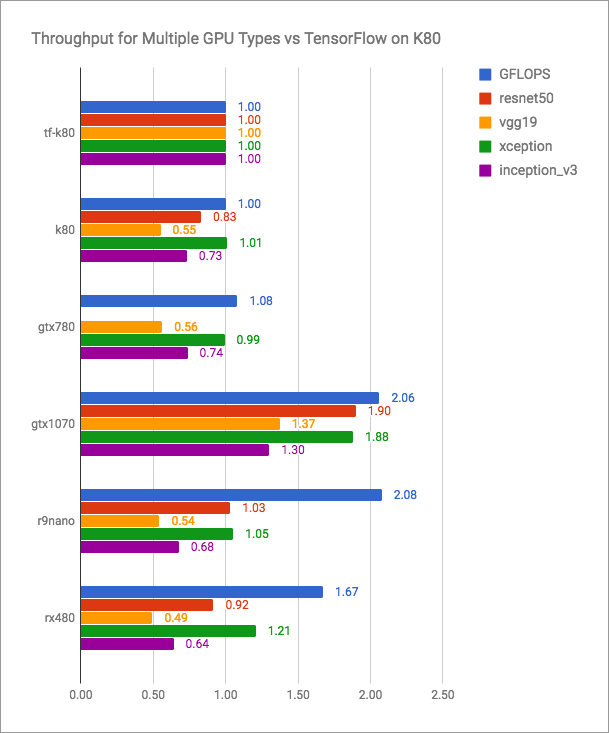
It can be seen that PlaidML is competitive with Tensorflow + CUDA, but not exactly faster for current versions. But PlaidML developers are probably not planning to enter into such an open fight. Their goal is versatility, cross-platform.
I'll leave here and not quite a comparative table with my performance measurements:
| Computing device | Epoch runtime (batch - 16), s |
|---|---|
| AMD FX-8320 tf | 200 |
| RX 460 2GB plaid | 35 |
| RX 580 8 GB plaid | 20 |
| 1060 6GB tf | eight |
| 1060 6GB plaid | ten |
| Intel i7-2600 tf | 185 |
| Intel i7-2600 plaid | 240 |
| GT 640 plaid | 46 |
The last article in the vertex.ai blog and the last edits in the repository are dated May 2018. It seems that if the developers of this tool do not stop releasing new versions and more and more people who are offended by Nvidia are familiar with PlaidML, then vertex.ai will soon be talked about much more often.
Uncover your Radeons!