Scalable fault-tolerant file service based on CTDB, GlusterFS
This article is a step-by-step guide to building a scalable fault-tolerant file storage, access to which will be implemented using the Samba, NFS protocols. As a file system that will be directly responsible for saving and scaling the file balls, we will use GlusterFS, which has already been fairly written about by the habrasociety. Since GlusterFS is part of Red Hat Storage , the tutorial is written for RH - like systems.

I use version 3.3.1, rpm-ki downloaded from the official site. After creating a volume, the client can access it in several ways:
We will use the first option, since in this case the client establishes a connection with all the servers and if the server to which we were mounted fails, we receive data from the working servers:
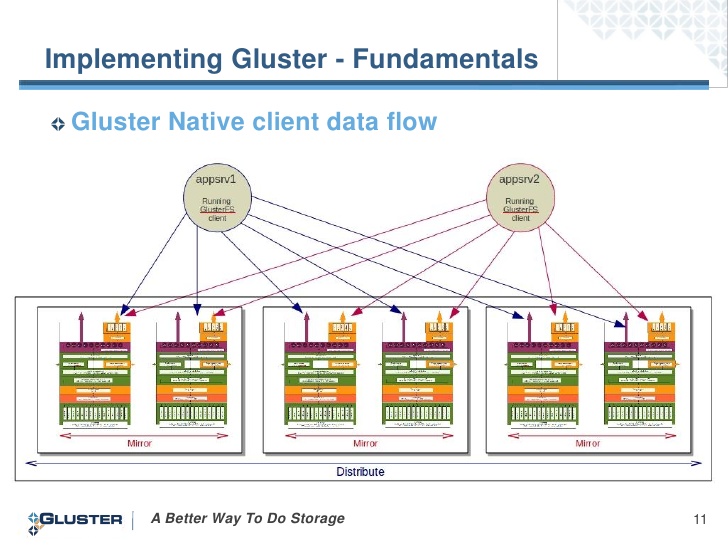
Excellent mechanics are described in this post. I would like to add that the load balancing on the cluster using LVS in the documentation is prescribed only for the NAT network, so we will use Round Robbin DNS. There are in standard repositories, as well as SMB, NFS:
Let's say we have 2 nodes:
We also need a couple of IPs that will implement fault tolerance - migrate between servers.
RR DNS for the data domain looks like this:
I will not go into creating volume for GlusterFS. I will say that we need a distributed replication partition (distributed + replicated volume). Let's call it smb . To begin with, we mount it locally for each node:
Each server uses its own hostname as an option . Do not forget to write the entry in / etc / fstab.
Now edit the Samba configuration (on each server) .
...
# The main parameter, is responsible for clustering.
# Communication with the database, which stores user requests (see the link about the mechanics of work)
# Folder, with configuration files
And add the section of the balls there:
The folder will be shared, accessed by smbcli without authorization. We’ll create it later and assign rights.
Now on one of the servers we create a folder in which we will place some CTDB configuration files
And add a file:
CTDB configuration file on each server we bring to the form:
# A file that is executed every time a CTDB cluster node changes its status (for example, send a letter)
We indicate our public adresses (on each server) :
We specify the nodes of the CTDB cluster (on each server) :
I disable SElinux, IPtables look like this (of course, for each server):
# Instead of the name of the chains, you can simply specify ACCEPT.
Let's go back to Samba and the smbcli user (on each server) :
The penultimate touches:
Now we can observe the
List of public migrating IPs and their belonging to the servers we get with the command
Mount the client using the SMB or NFS protocol using the commands:
From personal experience I can say that I’m still testing network drops , the result is very tolerable. A broken connection is barely noticeable. All explains AndreyKirov
Have a nice coding!
How do these services interact?
GlusterFS
I use version 3.3.1, rpm-ki downloaded from the official site. After creating a volume, the client can access it in several ways:
# mount.glusterfs# mount -o mountproto=tcp,async -t nfs# mount.cifs
We will use the first option, since in this case the client establishes a connection with all the servers and if the server to which we were mounted fails, we receive data from the working servers:
CTDB
Excellent mechanics are described in this post. I would like to add that the load balancing on the cluster using LVS in the documentation is prescribed only for the NAT network, so we will use Round Robbin DNS. There are in standard repositories, as well as SMB, NFS:
# yum install ctdb samba nfs-utils cifs-utils Let's get started
Let's say we have 2 nodes:
gluster1, 192.168.122.100gluster2, 192.168.122.101 We also need a couple of IPs that will implement fault tolerance - migrate between servers.
192.168.122.200192.168.122.201RR DNS for the data domain looks like this:
; zone file fragmentdata. 86400 IN A 192.168.122.200data. 86400 IN A 192.168.122.201I will not go into creating volume for GlusterFS. I will say that we need a distributed replication partition (distributed + replicated volume). Let's call it smb . To begin with, we mount it locally for each node:
# mount.glusterfs gluster1:smb /mnt/glustersmb Each server uses its own hostname as an option . Do not forget to write the entry in / etc / fstab.
Now edit the Samba configuration (on each server) .
# vim /etc/samba/smb.conf...
[global]# The main parameter, is responsible for clustering.
clustering = yes# Communication with the database, which stores user requests (see the link about the mechanics of work)
idmap backend = tdb2# Folder, with configuration files
private dir = /mnt/glustersmb/lockAnd add the section of the balls there:
[pub]path = /mnt/glustersmb/lockbrowseable = YESforce user = smbcliforce group = smbcliwritable = yesguest ok = yes guest account = smbcliguest only = yesThe folder will be shared, accessed by smbcli without authorization. We’ll create it later and assign rights.
Now on one of the servers we create a folder in which we will place some CTDB configuration files
# mkdir /mnt/glustersmb/lockAnd add a file:
# touch /mnt/glustersmb/lock/lockfileCTDB configuration file on each server we bring to the form:
# vim /etc/sysconfig/ctdbCTDB_RECOVERY_LOCK=/mnt/glustersmb/lock/lockfileCTDB_PUBLIC_ADDRESSES=/etc/ctdb/public_addressesCTDB_MANAGES_SAMBA=yesCTDB_NODES=/etc/ctdb/nodesCTDB_MANAGES_NFS=yes# A file that is executed every time a CTDB cluster node changes its status (for example, send a letter)
CTDB_NOTIFY_SCRIPT=/etc/ctdb/notify.shWe indicate our public adresses (on each server) :
# vim /etc/ctdb/public_addesses192.168.122.200/24 eth0 192.168.122.201/24 eth0 We specify the nodes of the CTDB cluster (on each server) :
# vim /etc/ctdb/nodes192.168.122.100192.168.122.101I disable SElinux, IPtables look like this (of course, for each server):
# vim /etc/sysconfig/iptables-A INPUT -p tcp --dport 4379 -j ctdb-A INPUT -p udp --dport 4379 -j ctdb-A INPUT -p tcp -m multiport --ports 137:139,445 -m comment --comment "SAMBA" -j SMB-A INPUT -p udp -m multiport --ports 137:139,445 -m comment --comment "SAMBA" -j SMB-A INPUT -p tcp -m multiport --ports 111,2049,595:599 -j NFS-A INPUT -p udp -m multiport --ports 111,2049,595:599 -j NFS-A INPUT -p tcp -m tcp --dport 24007:24220 -m comment --comment "Gluster daemon" -j ACCEPT-A INPUT -p tcp -m tcp --dport 38465:38667 -m comment --comment "Gluster daemon(nfs ports)" -j ACCEPT# Instead of the name of the chains, you can simply specify ACCEPT.
Let's go back to Samba and the smbcli user (on each server) :
# useradd smbcli# chown -R smbcli.smbcli /mnt/glustersmb/pubThe penultimate touches:
# chkconfig smbd off# chkconfig ctdb on# service ctdb startNow we can observe the
# ctdb statusNumber of nodes:2pnn:0 192.168.122.100 OK (THIS NODE)pnn:1 192.168.122.101 OKGeneration:1112747960Size:2hash:0 lmaster:0hash:1 lmaster:1Recovery mode:NORMAL (0)Recovery master:0List of public migrating IPs and their belonging to the servers we get with the command
# ctdb ipPublic IPs on node 0192.168.122.200 node[1] active[] available[eth0] configured[eth0]192.168.122.201 node[0] active[eth0] available[eth0] configured[eth0]Mount the client using the SMB or NFS protocol using the commands:
# mount.cifs data:smb /mnt # mount -o mountproto=tcp,async -t nfs data:smb /mnt From personal experience I can say that I’m still testing network drops , the result is very tolerable. A broken connection is barely noticeable. All explains AndreyKirov
Educational program
A node that has taken over the IP address of another only knows what they were about the old TCP connections and does not know the “TCP squence number” of the connections. Accordingly, he cannot continue them. Like the client, it does not know that the connections are now made to another node.
In order to avoid delays associated with switching the connection, the following technique is used. To understand this technique, you need to understand the basic principles of the functioning of the TCP protocol.
Having received an ip address, the new node sends a packet with the ACK flag to the client and the obviously wrong “squence number” equal to zero. In response, the client, in accordance with the rules of the TCP protocol, sends back the ACK Reply packet with the correct "squence number". Having received the correct “squence number”, the node forms a packet with the RST flag and this “squence number”. Upon receiving it, the client immediately restarts the connection.
Have a nice coding!