Anatomy of Recommended Services (Part 1)
We are glad to publish an interesting, in our opinion, article by our friend Nikolai Mikhailovsky (habro- user nickm197 ). We think that it will be interesting to everyone who works professionally in ecommerce.
Introduction
When we come to potential customers to talk about the crossss personalization service , one of the common questions is: “How is it arranged inside?” Using CentroBit’s friendly blog, I’ll talk a little bit about the theory and practice of recommending services devices.

It so happened that in the course of writing the article began to get too big, so I decided to limit myself to the first part, after which I will have to write at least one more, or even two.
Let's start with the basics and philosophy.
What is personalization?
The tape that you see on Facebook or VKontakte is only yours, no one else has it. Why do all the other sites look the same for me and for you? The answer is that social networks are naturally personalized, and other sites, as a rule, are not.
Thus, the personalization of the website is its automatic adjustment to the current needs of a particular visitor.
In personalization, two opposing approaches can be divided.
 The first is expanding personalization, when, based on some knowledge about the user, he is offered additional information that is supposedly useful to him. A typical example is the product recommendations that are most often found in online stores, for example, with the inscription “They buy this product”.
The first is expanding personalization, when, based on some knowledge about the user, he is offered additional information that is supposedly useful to him. A typical example is the product recommendations that are most often found in online stores, for example, with the inscription “They buy this product”.
The second is narrowing personalization. A typical example of it is the Facebook feed algorithm, which selects and displays to the user only those posts that are supposed to most likely involve him from the stream of friend posts.
These two approaches solve opposite problems. The first one offers previously unknown information. The second - on the contrary, saves from information overload.
What is a recommendation system?
The recommendation system is a software package that determines the interests and preferences of the visitor and gives recommendations in accordance with them.
There are various approaches to the development of recommendation systems, which can be applied depending on:
• available data about users and recommended entities
• types of explicit and implicit user feedback
• subject area
The purpose of the classic recommendation system is to recommend products previously unknown to the user, but useful or interesting in the current context.
In other words, the recommendation system answers the question about a specific visitor to the site: “What product does this visitor want to buy right now?”
There can be several different points of view on this main goal of the recommendation system, which determine different criteria for evaluating the success of the recommendation system:
From the visitor’s point of view, how much he likes the recommended products. The metrics for this are the quality of the approximation of the estimate or CTR by the recommendation system and the percentage of visitors who bought the recommended product.
From the point of view of an online store or online publication - maximizing expected user revenue or viewing depth.
Paradigms of recommendation systems

An ideal recommendation system for building recommendations uses data about the current user, the behavior of all users in general, the properties of the recommended products and the context of the user's current interest. So, for example, we act in http://crossss.ru . But for this it is necessary to process gigantic data arrays, therefore historically, until this possibility appeared literally several years ago, recommendation systems used subsets of such data arrays. And today, such systems are still quite common.
I will describe the main approaches to building recommendation systems for online stores and online publications.
Manual Recommendations
If you look at the recommendation blocks in Russian online stores, then most of them are manually filled lists of related products. If the product range is small and rarely changes, then this can be a good solution. If he is great, and the connections between the goods are not obvious, then selecting recommendations becomes excessively laborious, or they become ineffective.
Content recommendation systems
Systems based solely on product properties are called content systems.
For example, the WordPress Yet Another Related Posts Plugin (YARPP) plugin is widely distributed (over 2 million installations ). In the video http://wordpress.tv/2011/01/29/michael-%E2%80%9Cmitcho%E2%80%9D-erlewine-the-yet-another-related-posts-plugin-algorithm-explained/The author explains the principle of his work.
Another purely Russian, and quite unique example of a content recommendation system is http://similar4.ru/ of the Kuznech company . In it, the recommended clothes and shoes are selected according to the principle of visual similarity to the current subject.
Let us examine in a little more detail how the content recommender engine of the openrec openrecorded recommender system easyrec is arranged ( http://easyrec.sourceforge.net ).
In eacyrec, you can embed various recommendation engines as plug-ins in a common framework. This, in particular, is due to the fact that easyrec (apparently) is used as a framework by the commercial SmartEngine system, which has about 10 clients in Russia and a client in Singapore (although the developers are Austrians).
One of the 4 algorithms available in the easyrec open source delivery is the Profile Similarity Calculator . For his work, profiles of goods are required in which the properties of the goods are stored.
Product profiles are described, for example, as follows:
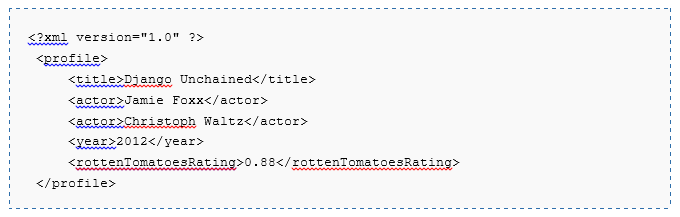
These product properties are loaded by the plugin, and a quick duke deduplicator is used to calculate the similarity measure for each product property . It uses comparators to compare each of the properties. The comparator should return 0 if the properties are completely different, and 1 if identical. For example, if you want to compare two strings, you can use ExactComparator, which returns 1 if the strings are identical, and 0 otherwise. Alternatively, you can use the comparator for Levinstein's distance (specifically put a separate link to Vladimir Iosifovich), weighted Levinstein distance, Yaro-Winkler measure , Q-grams, as well as many specialized measures, starting with numerical and ending with geo-positioning and phonetic comparison.
From individual measures of similarity of properties a general measure of similarity of goods is derived. For each pair of goods for which the similarity measure exceeds a certain threshold, a recommendation link is established between the goods (if there is such a link between goods A and B, then A is recommended to B, and vice versa).
The pros and cons of such recommendation systems are understandable. On the one hand, they are relatively easy to compute - recalculation of the relevance of items / articles is done when new items are added, which happens infrequently. At the same time, the same recommendations are shown to all visitors. On the other hand, the assumption that the current page fully determines the needs of the user is in many cases an exaggeration.
Collaborative Product Filtering (Item-To-Item Collaborative Filtering)
Collaborative filtering (CF) methods generate recommendations based on data on the valuation or use of goods (purchase of goods, watching movies, reading articles) regardless of the characteristics of a particular product.
The collaborative filtering of goods, as well as the basis of content systems, is based on the idea that interest in a particular product is an indicator that the user will also be interested in another product (as a substitute or complement to the current product). I will leave my dear readers to ponder over the extent to which this assumption is true.
Such methods gained popularity after Amazon employees Greg Linden, Brent Smith, and Jeremy York published an article on Amazon.com Recommendations: Item-to-Item Collaborative Filtering in IEEE INTERNET COMPUTING in early 2003 .
In order to get recommendations, collaborative product filtering systems link two main entities: users and products. The simplest way to communicate is the user’s rating (rating) of the product clearly indicated.
If we have data on the valuation of goods by various users, then we get the user-goods matrix:

Question: what product to recommend if the user is currently watching Product1? The answer given by Item-to-Item CF is the one that most closely resembles Item1. In a more mathematical language, this means that there is a metric of proximity between products based on user ratings.
The simplest measure of proximity is the cosine of the angle between the corresponding evaluation vectors for the product by users:

For example, in our case, the cosines between the vector of Product1 and other products are as follows:

Thus, the closest in our metric to Product1 is Product5.
However, in real applications, difficulties begin to arise, for example, due to the fact that different products are evaluated by a different number of users, and the ratings of each user are often shifted in one direction. In order to get around this problem, you can apply a modified cosine metric:

where U is the set of users who rated both a and b.
Further problems arise when large applications discover that only a very small number of products can get an estimate from each user. Thus, implicit ones should be added to explicit estimates based on what products the visitor looked at, how long he bought, etc. Naturally, the interpretation of implicit data is a more complicated task, and its solution is always approximate, which means that it leads to noise.
Thus, in real-world tasks, the user-product matrix is
1. Huge
2. Very sparse
3. Noisy
Fortunately, applied mathematics has long known what to do with such matrices. Namely, the singular decomposition is remarkable in that it optimally approximates the given matrix by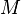 another matrix of a
another matrix of a  lower rank
lower rank 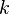 .:
.:
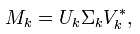
where are the matrices ,
,  and
and 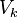 are obtained from the corresponding matrices in the singular decomposition of the matrix by trimming to exactly the first columns (the matrix elements are
are obtained from the corresponding matrices in the singular decomposition of the matrix by trimming to exactly the first columns (the matrix elements are  ordered by non-increasing).
ordered by non-increasing).
Thus, we perform a kind of compression of the information contained in. This compression occurs with losses - in the approximation only the most significant part of the matrix is preserved , and the noise is filtered out. Another look at such an approximation is that all products are projected into a space of lower dimension , in which the distance between them is determined.
A fairly large number of recommendation systems work according to this pattern.
In the following series: “How to compare people with refrigerators?”, “What did Yandex lose to Tencent?” and answers to other burning questions.
Introduction
When we come to potential customers to talk about the crossss personalization service , one of the common questions is: “How is it arranged inside?” Using CentroBit’s friendly blog, I’ll talk a little bit about the theory and practice of recommending services devices.
It so happened that in the course of writing the article began to get too big, so I decided to limit myself to the first part, after which I will have to write at least one more, or even two.
Let's start with the basics and philosophy.
What is personalization?
“If I have 3 million customers on the Web, I should have 3 million stores on the Web.”
–Jeff Bezos, CEO of Amazon.comThe tape that you see on Facebook or VKontakte is only yours, no one else has it. Why do all the other sites look the same for me and for you? The answer is that social networks are naturally personalized, and other sites, as a rule, are not.
Thus, the personalization of the website is its automatic adjustment to the current needs of a particular visitor.
In personalization, two opposing approaches can be divided.
The first is expanding personalization, when, based on some knowledge about the user, he is offered additional information that is supposedly useful to him. A typical example is the product recommendations that are most often found in online stores, for example, with the inscription “They buy this product”.The second is narrowing personalization. A typical example of it is the Facebook feed algorithm, which selects and displays to the user only those posts that are supposed to most likely involve him from the stream of friend posts.
These two approaches solve opposite problems. The first one offers previously unknown information. The second - on the contrary, saves from information overload.
What is a recommendation system?
The recommendation system is a software package that determines the interests and preferences of the visitor and gives recommendations in accordance with them.
There are various approaches to the development of recommendation systems, which can be applied depending on:
• available data about users and recommended entities
• types of explicit and implicit user feedback
• subject area
The purpose of the classic recommendation system is to recommend products previously unknown to the user, but useful or interesting in the current context.
In other words, the recommendation system answers the question about a specific visitor to the site: “What product does this visitor want to buy right now?”
There can be several different points of view on this main goal of the recommendation system, which determine different criteria for evaluating the success of the recommendation system:
From the visitor’s point of view, how much he likes the recommended products. The metrics for this are the quality of the approximation of the estimate or CTR by the recommendation system and the percentage of visitors who bought the recommended product.
From the point of view of an online store or online publication - maximizing expected user revenue or viewing depth.
Paradigms of recommendation systems
An ideal recommendation system for building recommendations uses data about the current user, the behavior of all users in general, the properties of the recommended products and the context of the user's current interest. So, for example, we act in http://crossss.ru . But for this it is necessary to process gigantic data arrays, therefore historically, until this possibility appeared literally several years ago, recommendation systems used subsets of such data arrays. And today, such systems are still quite common.
I will describe the main approaches to building recommendation systems for online stores and online publications.
Manual Recommendations
If you look at the recommendation blocks in Russian online stores, then most of them are manually filled lists of related products. If the product range is small and rarely changes, then this can be a good solution. If he is great, and the connections between the goods are not obvious, then selecting recommendations becomes excessively laborious, or they become ineffective.
Content recommendation systems
Systems based solely on product properties are called content systems.
For example, the WordPress Yet Another Related Posts Plugin (YARPP) plugin is widely distributed (over 2 million installations ). In the video http://wordpress.tv/2011/01/29/michael-%E2%80%9Cmitcho%E2%80%9D-erlewine-the-yet-another-related-posts-plugin-algorithm-explained/The author explains the principle of his work.
Another purely Russian, and quite unique example of a content recommendation system is http://similar4.ru/ of the Kuznech company . In it, the recommended clothes and shoes are selected according to the principle of visual similarity to the current subject.
Let us examine in a little more detail how the content recommender engine of the openrec openrecorded recommender system easyrec is arranged ( http://easyrec.sourceforge.net ).
In eacyrec, you can embed various recommendation engines as plug-ins in a common framework. This, in particular, is due to the fact that easyrec (apparently) is used as a framework by the commercial SmartEngine system, which has about 10 clients in Russia and a client in Singapore (although the developers are Austrians).
One of the 4 algorithms available in the easyrec open source delivery is the Profile Similarity Calculator . For his work, profiles of goods are required in which the properties of the goods are stored.
Product profiles are described, for example, as follows:
These product properties are loaded by the plugin, and a quick duke deduplicator is used to calculate the similarity measure for each product property . It uses comparators to compare each of the properties. The comparator should return 0 if the properties are completely different, and 1 if identical. For example, if you want to compare two strings, you can use ExactComparator, which returns 1 if the strings are identical, and 0 otherwise. Alternatively, you can use the comparator for Levinstein's distance (specifically put a separate link to Vladimir Iosifovich), weighted Levinstein distance, Yaro-Winkler measure , Q-grams, as well as many specialized measures, starting with numerical and ending with geo-positioning and phonetic comparison.
From individual measures of similarity of properties a general measure of similarity of goods is derived. For each pair of goods for which the similarity measure exceeds a certain threshold, a recommendation link is established between the goods (if there is such a link between goods A and B, then A is recommended to B, and vice versa).
The pros and cons of such recommendation systems are understandable. On the one hand, they are relatively easy to compute - recalculation of the relevance of items / articles is done when new items are added, which happens infrequently. At the same time, the same recommendations are shown to all visitors. On the other hand, the assumption that the current page fully determines the needs of the user is in many cases an exaggeration.
Collaborative Product Filtering (Item-To-Item Collaborative Filtering)
Collaborative filtering (CF) methods generate recommendations based on data on the valuation or use of goods (purchase of goods, watching movies, reading articles) regardless of the characteristics of a particular product.
The collaborative filtering of goods, as well as the basis of content systems, is based on the idea that interest in a particular product is an indicator that the user will also be interested in another product (as a substitute or complement to the current product). I will leave my dear readers to ponder over the extent to which this assumption is true.
Such methods gained popularity after Amazon employees Greg Linden, Brent Smith, and Jeremy York published an article on Amazon.com Recommendations: Item-to-Item Collaborative Filtering in IEEE INTERNET COMPUTING in early 2003 .
In order to get recommendations, collaborative product filtering systems link two main entities: users and products. The simplest way to communicate is the user’s rating (rating) of the product clearly indicated.
If we have data on the valuation of goods by various users, then we get the user-goods matrix:
Question: what product to recommend if the user is currently watching Product1? The answer given by Item-to-Item CF is the one that most closely resembles Item1. In a more mathematical language, this means that there is a metric of proximity between products based on user ratings.
The simplest measure of proximity is the cosine of the angle between the corresponding evaluation vectors for the product by users:
For example, in our case, the cosines between the vector of Product1 and other products are as follows:
Thus, the closest in our metric to Product1 is Product5.
However, in real applications, difficulties begin to arise, for example, due to the fact that different products are evaluated by a different number of users, and the ratings of each user are often shifted in one direction. In order to get around this problem, you can apply a modified cosine metric:
where U is the set of users who rated both a and b.
Further problems arise when large applications discover that only a very small number of products can get an estimate from each user. Thus, implicit ones should be added to explicit estimates based on what products the visitor looked at, how long he bought, etc. Naturally, the interpretation of implicit data is a more complicated task, and its solution is always approximate, which means that it leads to noise.
Thus, in real-world tasks, the user-product matrix is
1. Huge
2. Very sparse
3. Noisy
Fortunately, applied mathematics has long known what to do with such matrices. Namely, the singular decomposition is remarkable in that it optimally approximates the given matrix by
another matrix of a lower rank .:where are the matrices
, and are obtained from the corresponding matrices in the singular decomposition of the matrix by trimming to exactly the first columns (the matrix elements are ordered by non-increasing). Thus, we perform a kind of compression of the information contained in
. This compression occurs with losses - in the approximation only the most significant part of the matrix is preserved , and the noise is filtered out. Another look at such an approximation is that all products are projected into a space of lower dimension , in which the distance between them is determined. A fairly large number of recommendation systems work according to this pattern.
In the following series: “How to compare people with refrigerators?”, “What did Yandex lose to Tencent?” and answers to other burning questions.