Tele2 hackathon report

On August 18-19, Tele2 organized the Hakaton on Data Science. This hackathon is focused on analyzing technical support dialogs in social networks, speeding up and simplifying interaction with customers.
The task did not have a specific metric that needs to be optimized; the task could have been thought up by oneself. The main thing is to improve the service. The jury of the competition was the director of various areas of Tele2, as well as the famous Kaggle grandmaster in the Data Science community Pavel Pleskov.
Under the cut the story of the team that took 1st place.
When a colleague invited me to participate in this hackathon, I agreed rather quickly.
I was interested in the topic of NLP, and there were also some neural network developments that I wanted to test in practice.
The hackathon organizers in advance sent out small fragments of datasets, which gave an idea of exactly which data would be available at the event itself.
The data turned out to be rather dirty, outside trolls got into the dialogues, it was not always obvious what kind of question the operator answers.
It became clear that implementing the conceived idea in the allotted 24 hours would not be easy, so I took 1 day of work off at work and spent it on preparing the neural network I wanted to try. This made it possible not to waste the time of the hackathon on the search for bugs, but to focus on the use of and non-carrying cases.
The tele2 office is located on the territory of New Moscow in the Rumyantsevo business park. As for me, getting there for quite some time, but the impression is that the business park produces a good one (with the exception of power lines).

Power lines on the background of the business center
The organizers met us right at the metro station, showed us how to get to the office. The building of the business center itself occupies a number of companies, the Tele2 office is located on the 5th floor. The hackathon participants were assigned a special area inside the office, there was a kitchen, a rest area with a PlayStation and ottomans. Particularly pleased with the speed of wi-fi, no problems inherent in mass events, was not observed.

Breakfast
Real Dataset, which Tele2 provided, consisted of 3 large CSV files with technical support dialogs: social network dialogs, telegram and email. A total of more than 4 million hits is what you need to train a neural network.
What was the neural network?
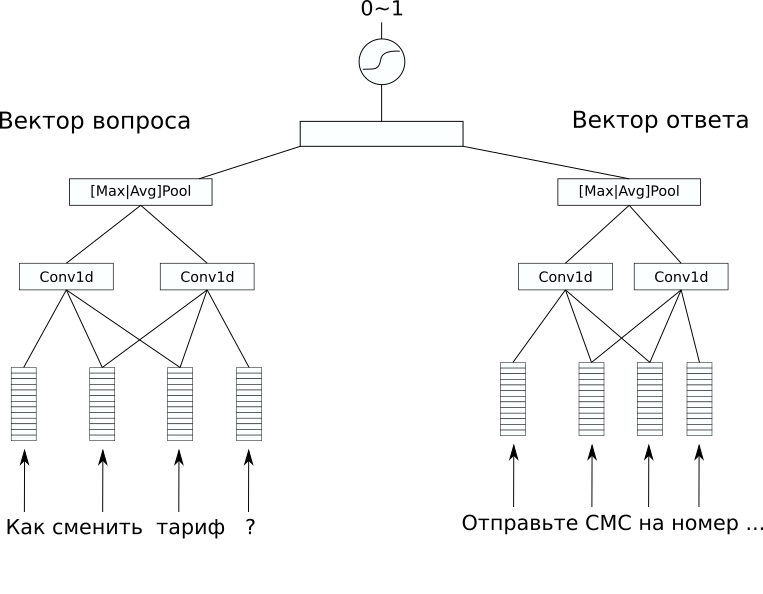
Network Architecture
In dataset, there was no additional markup that would be interesting to predict, but I wanted to solve a supervised task. Therefore, we decided to try to predict the answers to the questions, so at least a simple chat bot can be made from such a model. For this, we chose the architecture CDSSM (Convolution Deep Semantic Similarity Model). This is one of the simplest neural network models for comparing texts according to the meaning that was originally proposed by Microsoft for ranking the search results Bing.
Its essence is as follows: first, each text is converted into a vector using a sequence of convolution and pooling layers.
Then the obtained vectors are compared in some way. In our problem, a good linear result was given by an additional linear layer that combines both vectors with a sigmoid as an activation function. The weights of the network encoding sentences in a vector may be the same for a pair of texts (such networks are called Siamese), or they may differ.
In our case, the variant with different weights gave the best result, since the texts of the question and answer were significantly different.
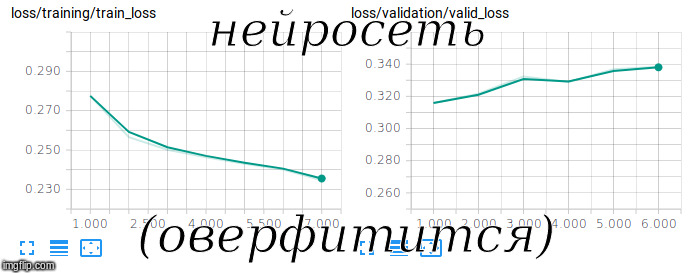
Attempting to train the Siamese network.
FastText with RusVectōrēs was used as a pre-trained embedding , it is resistant to typos that are often encountered in user questions.
In order to train such a model, it needs to be trained not only on positive, but also on negative examples. To do this, we added a random 1: 10 question-answer pair to the training sample.
To assess the quality of this non-balanced sample, we used the ROC-AUC metric. After 3 hours of training on the GPU, we managed to reach a value of 0.92 for this metric.
With this model, you can solve not only the direct problem - choose the appropriate answer to the question, but also the opposite - find the mistakes of the operators, poor-quality and strange answers to the users' questions.
We managed to find some such answers right on the hackathon and include them in the final presentation. It seems to me that this made the greatest impression on the jury.
An interesting application can also be found in the vector representation of the texts that the network generates in the course of its work.
With it, you can search for anomalies in questions and answers using various unsupervised methods .
As a result, our decision was well received both from a technical point of view and from a business point of view. The rest of the teams mainly tried to solve the problem of tonality analysis and thematic modeling, so our solution differed favorably. As a result, we took the 1st place, we were happy and tired.

On the photo (from left to right): Alexander Abramov, Konstanin Ivanov, Andrey Vasnetsov (author) and Shvetsov Egor