Courier: Dropbox to gRPC migration
- Transfer

Translator's Note
Most modern software products are not monolithic, but consist of many parts that interact with each other. In this state of affairs, it is necessary that the interaction of interacting parts of the system take place in the same language (despite the fact that the parts themselves can be written in different programming languages and executed on different machines). GRPC, an open-source framework from Google, released in 2015, helps simplify the solution of this problem. He immediately solves a number of problems, allowing:
- use the language Protocol Buffers to describe the interaction of services;
- generate software code based on the described protocol for 11 different languages for both the client and server parts;
- implement authorization between interacting components;
- use both synchronous and asynchronous interaction.
gRPC seemed to be quite an interesting framework, and I was interested to learn about the actual experience of Dropbox in building a system based on it. The article has a lot of details related to the use of encryption, building a reliable, observable and productive system, the migration process from the old RPC solution to the new one.
Disclaimer
The original article does not contain a description of gRPC, and some points may seem incomprehensible to you. If you are not familiar with gRPC or other similar frameworks (for example, Apache Thrift), I recommend you to familiarize yourself with the basic ideas (you just need to read two small articles from the official site: "What is gRPC?" And "gRPC Concepts" ).
Thanks to Alexey Ivanov aka SaveTheRbtz for writing the original article and helping with the translation of difficult places.
Thanks to Alexey Ivanov aka SaveTheRbtz for writing the original article and helping with the translation of difficult places.
Dropbox manages a variety of services written in different languages and serving millions of requests per second. At the heart of our service-oriented architecture is Courier, a gRPC-based RPC framework. In the process of its development, we learned a lot about gRPC extensibility, speed optimization and transition from the previous RPC system.
Note: The post contains code snippets in Python and Go. We also use Rust and Java.
Road to gRPC
Courier is not the first Dropbox RPC framework. Even before we started splitting up the monolithic Python system into separate services, we needed a reliable basis for data exchange between services - especially since the choice of the framework will have remote consequences.
Prior to that, Dropbox experimented with different RPC frameworks. At first we had an individual protocol for manual serialization and deserialization. Some services, such as Scribe-based logging tools , used Apache Thrift . At the same time, our main RPC framework was the HTTP / 1.1 protocol with messages serialized using Protobuf.
Creating a framework, we chose from several options. We could enter Swagger (now known asOpenAPI ), introduce a new standard or build a framework based on Thrift or gRPC. The main argument in favor of gRPC was the ability to use pre-existing protobufs. Also, multiplex HTTP / 2 and two-way data transfer were useful for our tasks.
Note: if fbthrift existed at that time, we might have looked more closely at the Thrift solutions.
What Courier brings to gRPC
Courier is not an RPC protocol; it is a means of integrating gRPC into the existing infrastructure. The framework was supposed to be compatible with our tools for authentication, authorization and discovery of the service, as well as collecting statistics, logging and tracking. So we created Courier.
Although in some cases we use Bandaid as a gRPC proxy, most of our services interact with each other directly to minimize the effect of RPC on latency.
For us it was important to reduce the amount of routine code that needs to be written. Since Courier serves as a general framework for developing services, it contains the features necessary for everyone. Most of them are enabled by default and can be controlled by command line arguments, and some are ticked by a flag.
Security: Service Identification and TLS Mutual Authentication
Courier implements our standard service identification mechanism. Each server and client is assigned an individual TLS certificate issued by our own certification authority. The certificate encodes a personal identifier that is used for mutual authentication — the server verifies the client, the client verifies the server.
In TLS, where we control both sides of the connection, we have imposed tight restrictions. All internal RPCs require PFS encryption. The required TLS version is 1.2 and higher. We also limited the number of symmetric and asymmetric algorithms, preferring ECDHE-ECDSA-AES128-GCM-SHA256 .
After passing the authentication and decrypting the request, the server checks if the client has the necessary permissions. Access control lists (ACLs) and speed limits can be configured for services as a whole or for individual methods. Their parameters can also be changed through our distributed file system (AFS). Due to this, service owners can relieve the load in seconds, even without restarting the processes. Courier will take care of the notification subscription and configuration updates.
The Identity service is a global identifier for ACL, speed limits, statistics, etc. Plus, it is cryptographically secure.
Here is an example of the configuration of the ACL and the speed limit used in our optical image recognition service :
limits:
dropbox_engine_ocr:
# All RPC methods.
default:
max_concurrency: 32
queue_timeout_ms: 1000
rate_acls:
# OCR clients are unlimited.
ocr: -1
# Nobody else gets to talk to us.
authenticated: 0
unauthenticated: 0
We are considering the possibility of switching to the SVID format ( SPIFFE cryptographically verifiable document ), which will help to combine our framework with many open source projects.
Observability: statistics and tracking
With just one identifier, you can easily find logs, statistics, trace files and other data about Courier.
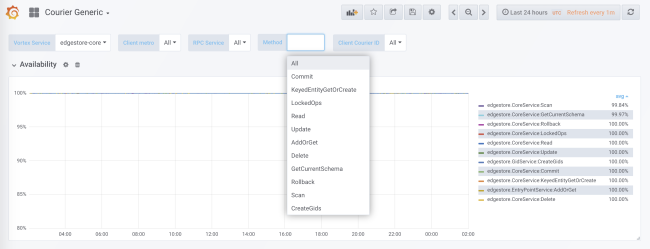
When code generation, statistics collection is added for each service and each method both on the client side and on the server side. Server-side statistics are divided by client ID. In the standard configuration, you will receive detailed load, error, and delay data for each service using Courier.
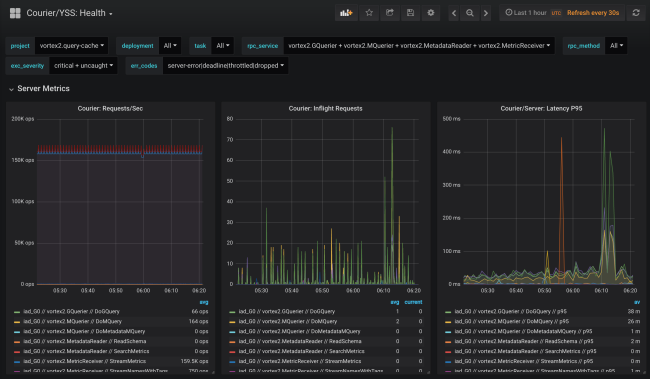
Courier statistics include data on availability and latency on the client’s side, as well as on the number of requests and queue size on the server side. There are other useful graphs, in particular histograms of response time for each method and TLS handshakes for each client.
One of the advantages of our code generation is the possibility of static initialization of data structures such as histograms and trace graphs. This minimizes the impact on performance.
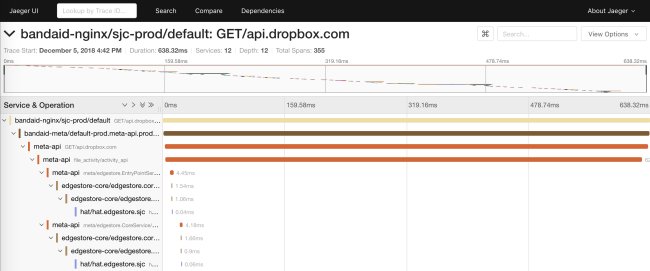
The former RPC system only distributed the request_id via API. This made it possible to combine data from the logs of different services. In Courier, we presented an API based on a subset of the OpenTracing specifications . We wrote our own libraries on the client side, and on the server side implemented a solution based on Cassandra and Jaeger .

Tracing allows us to generate service dependency diagrams at runtime. This helps engineers to see all the transitive dependencies of a particular service. In addition, the feature is useful for tracking unwanted dependencies after deployment.
Reliability: deadlines and disconnection
Courier provides a central place for implementing common client functions (for example, time-outs) in different languages. We gradually added various possibilities, often based on the results of a “post-mortem” analysis of emerging problems.
Deadlines
Each gRPC request has a deadline indicating client waiting time. Since Courier stubs automatically distribute known metadata, the deadline for the query is even passed outside the API. Inside the process, deadlines get a native mapping. For example, in Go, they are represented by the context.Context result from the WithDeadline method .
In fact, we were able to fix whole classes of reliability problems, forcing engineers to set deadlines in determining the corresponding services.
This approach goes even beyond RPC. For example, our ORM MySQL serializes the RPC context along with the deadline in the SQL query comment. Our SQL proxy can parse comments and “kill” requests when deadline occurs. And as a bonus when debugging database access, we have a SQL query binding to a specific RPC query.
Disconnection
Another common problem faced by customers of the previous RPC system is the implementation of an algorithm for individual exponential delay and oscillations when re-requesting.
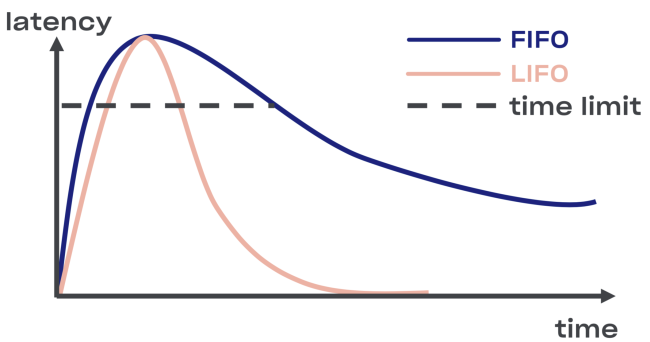
We tried to find an intelligent solution to the problem of disconnecting in Courier, starting with the implementation of the LIFO buffer (last in, first out) between the service and the task pool.
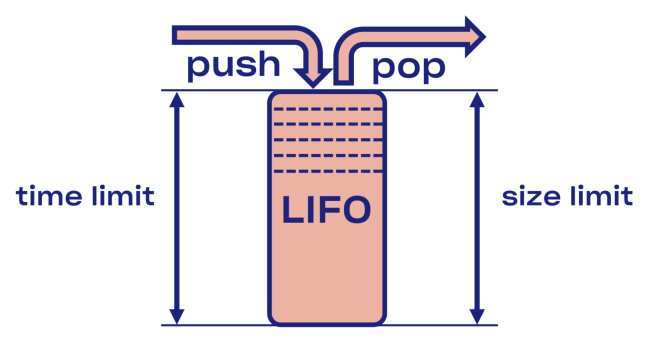
In the event of an overload, the LIFO will automatically break the connection. The queue, which is important, is limited not only in size, but also in time (a request can only spend a certain amount of time in a queue).
Minus LIFO - change the order of processing requests. If you want to keep the original order, use CoDel . There is also the possibility of breaking the connection, and the order of processing requests will remain the same.
Introspection: debug endpoints
Although debug endpoints are not directly part of Courier, they are widely used throughout Dropbox and are too useful not to mention.
In order to ensure security, you can open them on a separate port or in a Unix-socket (to control access using file permissions). You should also consider mutual TLS authentication, with which developers will have to provide their certificates for access to endpoints (primarily not only readable).
Execution
The ability to analyze the status of the service during its operation is very useful for debugging. For example, dynamic memory and CPU profiles can be accessed via HTTP or gRPC endpoints .
We plan to use this feature in the canary verification procedure - to automate the search for the difference between the old and new versions of the code.
Endpoints make it possible to modify the state of the service during execution. In particular, Golang-based services can dynamically configure GCPercent .
Library
The function of automatically exporting data related to a specific library in the form of an RPC endpoint may be useful for library developers. For example, the malloc library can dump internal statistics into a dump . Another example: a debug endpoint can change the level of service logging on the fly.
RPC
Of course, troubleshooting the encrypted and encrypted protocols is not easy. Therefore, implementing as many tools as possible at the RPC level is a good idea. One example of this introspective API is Channelz .
Application level
The ability to examine application-level settings can also be useful. A good example is endpoint with general information about the application (with the hash of the source or build files, the command line, etc.). It can be used by the orchestration system to check the integrity when deploying a service.
Performance optimization
By expanding our gRPC framework to the required scale, we found several bottlenecks specific to Dropbox.
Resource Consumption TLS-handshakes
In services that serve many interconnections, as a result of TLS handshakes, the cumulative CPU load can be quite serious (especially when restarting a popular service).
In order to improve the performance in the implementation of the signature, we replaced the RSA-2048 key pairs with ECDSA P-256. Here are examples of their performance (note: signature verification is faster with RSA).
RSA:
~/c0d3/boringssl bazel run -- //:bssl speed -filter 'RSA 2048'
Did ... RSA 2048 signing operations in .............. (1527.9 ops/sec)
Did ... RSA 2048 verify (same key) operations in .... (37066.4 ops/sec)
Did ... RSA 2048 verify (fresh key) operations in ... (25887.6 ops/sec)ECDSA:
~/c0d3/boringssl bazel run -- //:bssl speed -filter 'ECDSA P-256'
Did ... ECDSA P-256 signing operations in ... (40410.9 ops/sec)
Did ... ECDSA P-256 verify operations in .... (17037.5 ops/sec)
Since verification with RSA-2048 is about three times faster than with ECDSA P-256, you can choose RSA for root and end certificates for increased performance. But from a security point of view, things are not so simple: you will build chains of various cryptographic primitives, and therefore the level of the resulting security parameters will be the lowest. And if you want to improve speed, we do not recommend using certificates of version RSA-4096 (and higher) as root and end.
We also found that the choice of the TLS library (and the compilation flags) has a significant impact on both performance and security. Compare, for example, the LibreSSL build on macOS X Mojave with a self-written OpenSSL on the same hardware.
LibreSSL 2.6.4:
~ openssl speed rsa2048
LibreSSL 2.6.4
...
sign verify sign/s verify/s
rsa 2048 bits 0.032491s 0.001505s 30.8 664.3OpenSSL 1.1.1a:
~ openssl speed rsa2048
OpenSSL 1.1.1a 20 Nov 2018
...
sign verify sign/s verify/s
rsa 2048 bits 0.000992s 0.000029s 1208.0 34454.8However, the fastest way to create a TLS handshake is not to create it at all! We have included support for resuming the session in gRPC-core and gRPC-python, thereby reducing the load on the CPU during deployment.
Encryption is inexpensive
Many people mistakenly believe that encryption is expensive. In fact, even the most simple modern computers implement symmetric encryption almost at lightning speed. A standard processor is able to encrypt and authenticate data at a speed of 40 Gb / s per core:
~/c0d3/boringssl bazel run -- //:bssl speed -filter 'AES'
Did ... AES-128-GCM (8192 bytes) seal operations in ... 4534.4 MB/sNevertheless, we still had to configure gRPC for our memory blocks operating at 50 Gb / s. We found that if the encryption speed is approximately equal to the copy speed, then it is important to minimize the number of memcpy operations . In addition, we made some changes to gRPC itself.
Authenticated and encrypted protocols avoided many unpleasant problems (for example, data corruption by the processor, DMA or network). Even if you do not use gRPC, we recommend using TLS for internal contacts.
High latency data links (BDP)
Translator's note: in the original subtitle, the term bandwidth-delay product was used , which does not have a well-established Russian translation.
Dropbox's core network includes many data centers . Sometimes nodes located in different regions have to be communicated via RPC, for example, for replication. When using TCP, the system core is responsible for limiting the amount of data transmitted on a particular connection (within / proc / sys / net / ipv4 / tcp_ {r, w} mem ), although the gRPC based on HTTP / 2 also has its own flow control. The upper limit of the BDP in grpc-go is strictly limited to 16 MB , which can provoke a bottleneck.
net.Server Golang or grpc.Server
Initially, in our Go code, we supported HTTP / 1.1 and gRPC using one net.Server . The solution made sense in terms of maintaining the program code, but it didn’t work perfectly. The distribution of HTTP / 1.1 and gRPC across different servers and the transition of gRPC to grpc.Server have significantly improved throughput and memory utilization by Courier services.
golang / protobuf or gogo / protobuf
Switching to gRPC may increase the cost of marshaling and unmarshaling. For the Go code, we were able to significantly reduce the CPU load on the Courier servers by going to gogo / protobuf .
As always, the transition to gogo / protobuf was accompanied by some concerns , but if you reasonably limit the functionality, there should be no problems.
Implementation details
In this section, we will penetrate deeper into the Courier device, consider protobuf schemes and examples of stubs from various languages. All examples are taken from the Test service that we used during Courier integration testing.
Service Description
Take a look at an excerpt from the definition of the Test service:
service Test {
option (rpc_core.service_default_deadline_ms) = 1000;
rpc UnaryUnary(TestRequest) returns (TestResponse) {
option (rpc_core.method_default_deadline_ms) = 5000;
}
rpc UnaryStream(TestRequest) returns (stream TestResponse) {
option (rpc_core.method_no_deadline) = true;
}
...
}As stated above, the presence of deadline is mandatory for all Courier methods. With the following option you can set a deadline for the entire service:
option (rpc_core.service_default_deadline_ms) = 1000;At the same time, each method can have its own deadline, which cancels the deadline of the entire service (if there is one):
option (rpc_core.method_default_deadline_ms) = 5000;In rare cases, when the deadline does not make sense (for example, when tracking a resource), the developer can turn it off:
option (rpc_core.method_no_deadline) = true;In addition to this, the service description should contain detailed API documentation, possibly with examples of use.
Generation stubs
To provide greater flexibility, Courier generates its own stubs, without relying on the interceptor functionality provided by gRPC (with the exception of Java, in which the interceptor API has sufficient power). Let's compare our stubs with standard Golang stubs.
This is how the default stubs of the gRPC server look like:
func _Test_UnaryUnary_Handler(srv interface{}, ctx context.Context, dec func(interface{})error, interceptorgrpc.UnaryServerInterceptor) (interface{}, error) {
in := new(TestRequest)
if err := dec(in); err != nil {
returnnil, err
}
if interceptor == nil {
return srv.(TestServer).UnaryUnary(ctx, in)
}
info := &grpc.UnaryServerInfo{
Server: srv,
FullMethod: "/test.Test/UnaryUnary",
}
handler := func(ctx context.Context, req interface{})(interface{}, error) {
return srv.(TestServer).UnaryUnary(ctx, req.(*TestRequest))
}
return interceptor(ctx, in, info, handler)
}All processing takes place inside: decoding protobuf, launching interceptors (see variable
interceptor in code), launching UnaryUnary handler. Now look at the Courier stubs:
func _Test_UnaryUnary_dbxHandler(
srv interface{},
ctx context.Context,
dec func(interface{})error,
interceptorgrpc.UnaryServerInterceptor) (
interface{},
error) {
defer processor.PanicHandler()
impl := srv.(*dbxTestServerImpl)
metadata := impl.testUnaryUnaryMetadata
ctx = metadata.SetupContext(ctx)
clientId = client_info.ClientId(ctx)
stats := metadata.StatsMap.GetOrCreatePerClientStats(clientId)
stats.TotalCount.Inc()
req := &processor.UnaryUnaryRequest{
Srv: srv,
Ctx: ctx,
Dec: dec,
Interceptor: interceptor,
RpcStats: stats,
Metadata: metadata,
FullMethodPath: "/test.Test/UnaryUnary",
Req: &test.TestRequest{},
Handler: impl._UnaryUnary_internalHandler,
ClientId: clientId,
EnqueueTime: time.Now(),
}
metadata.WorkPool.Process(req).Wait()
return req.Resp, req.Err
}There's a lot of code here, so let's break it down.
First, we postpone the call to the panic handler, which is responsible for automatically collecting errors. This will allow us to collect all uncaught exceptions in the central repository for subsequent aggregation and reporting:
defer processor.PanicHandler()
Another reason why we run our own panic handler is to make sure that in case of an error, the application will crash. The standard golang / net HTTP handler will then ignore the problem and continue to serve new requests (even those that are corrupted and mismatched).
Then we pass the context further, redefining the values based on the incoming request metadata:
ctx = metadata.SetupContext(ctx)
clientId = client_info.ClientId(ctx)We also create (and cache for greater efficiency) server-side client statistics for more detailed aggregation:
stats := metadata.StatsMap.GetOrCreatePerClientStats(clientId)
This line creates statistics for each client (i.e. TLS-identifier) during execution. We also have statistics on all methods for each service. Since the stub generator has access to all methods during code generation, we can pre-statically create them, thereby avoiding deceleration of program execution.
After that we create the request structure, transfer it to the task pool and wait for the execution:
req := &processor.UnaryUnaryRequest{
Srv: srv,
Ctx: ctx,
Dec: dec,
Interceptor: interceptor,
RpcStats: stats,
Metadata: metadata,
...
}
metadata.WorkPool.Process(req).Wait()Note that by this time we have not done the decoding of the protobuf, nor the launch of the interceptor. Before this, access checks, prioritization and limiting the number of queries to be performed must be passed inside the task pool.
Note that the gRPC library supports the TAP interface, which allows you to intercept requests with great speed. The interface provides the infrastructure for building effective speed limiters with minimal resource consumption.
Specific error codes for different applications
Our stub generator also allows developers to assign application-specific error codes using special options:
enum ErrorCode {
option (rpc_core.rpc_error) = true;
UNKNOWN = 0;
NOT_FOUND = 1 [(rpc_core.grpc_code)="NOT_FOUND"];
ALREADY_EXISTS = 2 [(rpc_core.grpc_code)="ALREADY_EXISTS"];
...
STALE_READ = 7 [(rpc_core.grpc_code)="UNAVAILABLE"];
SHUTTING_DOWN = 8 [(rpc_core.grpc_code)="CANCELLED"];
}Within the service, both gRPC and application errors are propagated, and on the API boundary all errors are replaced with UNKNOWN. Due to this, we can avoid transferring the problem to other services, which may result in a change in their semantics.
Changes regarding Python
Python stubs add an explicit context parameter to all Courier handlers:
from dropbox.context import Context
from dropbox.proto.test.service_pb2 import (
TestRequest,
TestResponse,
)
from typing_extensions import Protocol
classTestCourierClient(Protocol):
defUnaryUnary(
self,
ctx, # type: Context
request, # type: TestRequest
):
# type: (...) -> TestResponse
...At first it looked weird, but over time, the developers got used to the explicit ctx just as they used to self .
Please note that our stubs are fully typed for mypy , which is compensated during major refactoring. In addition, integration with some IDEs (eg, PyCharm) is simplified.
Continuing to follow the trend for static typing, we add mypy annotations to the protocols themselves:
classTestMessage(Message):
field: int
def__init__(self,
field : Optional[int] = ...,
) -> None: ...
@staticmethod
defFromString(s: bytes) -> TestMessage: ...These annotations will allow you to avoid many common bugs, such as assigning a value of None to a string type , for example .
This code is available by reference .
Migration process
Creating a new RPC stack is not an easy task, but it is not even close to the process of a full transition to it, when viewed from the point of view of operating complexity. Therefore, we have tried to simplify for developers the transition from the old RPC to the Courier. Since migrations are often accompanied by errors, we decided to implement it in stages.
Step 0: Freeze Old RPC
First of all, we froze the old RPC so as not to shoot at a moving target. This also pushed people to move to Courier, because all new features like tracing were available only in services on Courier.
Step 1: Common Interface for Old RPC and Courier
We started by setting a common interface for the old RPC and Courier. Our code generation had to ensure that both versions of stubs match this interface:
type TestServer interface {
UnaryUnary(
ctx context.Context,
req *test.TestRequest) (
*test.TestResponse,
error)
...
}
Step 2: Migrate to New Interface
After that, we began to switch each service to a new interface, while continuing to use the old RPC. Often the code changes represented a huge diff affecting all the methods of the service and its clients. Since this stage is the most problematic, we wanted to completely eliminate the risk, changing only one thing at a time.
Simple services with a small number of methods and the right to error can be migrated simultaneously, without paying attention to our warnings.
Step 3: Migrate Clients to RPC Courier
During the migration process, we started simultaneously launching both old and new servers on different ports of the same machine. Switching the RPC implementation on the client side was done by changing one line:
classMyClient(object):
def__init__(self):
- self.client = LegacyRPCClient('myservice')
+ self.client = CourierRPCClient('myservice')Please note that with this model you can transfer one client at a time, starting with those who have a lower SLA level.
Step 4: Cleaning
After all the clients have been migrated, it's time to make sure that the old RPC is no longer in use (this can be done statically with code inspection and at run time using server statistics). After that, developers can start cleaning - removing outdated code.
findings
So, Courier is a unified RPC framework, which accelerates the development of services, simplifies operation and improves the reliability of Dropbox.
Here are the conclusions we made when developing and deploying Courier:
- Observability is a huge plus. Having all the necessary statistics will be indispensable for diagnosing and troubleshooting.
- Standardization and homogeneity are very important - they reduce cognitive load, simplify the operation and maintenance of the code.
- Try to minimize the amount of routine code created by developers. Codegen will help you with this.
- Make the migration process as simple as possible. Perhaps it will take more time than the development itself. In addition, remember: the migration is completed after the removal of the old code.
- In the RPC framework, you can include improvements for the entire infrastructure — mandatory deadlines, overload protection, etc. Common problems with reliability can be identified during the study of quarterly reports.
Future changes
Courier, like gRPC as a whole, does not stand still, so we end the article with plans for teams responsible for the execution environment and reliability.
In the near future, we want to introduce a conflict resolution mechanism into the gRPC code in Python, switch to C ++ bindings in Python and Rust, and add full support for the pattern of breaking the connection and introducing faults. Toward the end of the year, we plan to study the ALTS protocol and bring the TLS handshake into a separate process (perhaps even beyond the limits of the service container).