Detection of vulnerabilities in theory and practice, or why there is no perfect static analyzer

Today, the development of high-quality software is difficult to imagine without the use of static code analysis methods . Static analysis of a program code can be embedded in the development environment (by standard methods or using plug-ins), can be performed by specialized software before running the code into commercial operation or “manually” by a full-time or external expert.
Often there is a reasoning that dynamic code analysis or penetration tests can replace static analysis, since these verification methods will reveal real problems and there will be no false positives. However, this is a controversial issue, because dynamic analysis, in contrast to static analysis, does not check all the code, but only checks the software's resistance to a set of attacks that mimic the actions of an attacker. An attacker may be more inventive than the verifier, regardless of who performs the verification: the person or the machine.
Dynamic analysis will be complete only if it is performed on a full test coverage, which, as applied to real-world applications, is a difficult task. The proof of the completeness of the test coverage is an algorithmically unsolvable problem.
Mandatory static analysis of software code is one of the necessary steps when commissioning software with increased requirements for information security.
At the moment, there are many different static code analyzers on the market, and more and more new ones are constantly appearing. In practice, there are cases when several static analyzers are used together to improve the quality of testing, since different analyzers look for different defects.
Why is there no universal static analyzer that completely checks any code and finds all defects in it without false positives and at the same time works quickly and does not require a lot of resources (CPU time and memory)?

A bit about the architecture of static analyzers
The answer to this question lies in the architecture of static analyzers. Almost all static analyzers are somehow built according to the principle of compilers, that is, their work contains the stages of transforming the source code - the same as the compiler does.
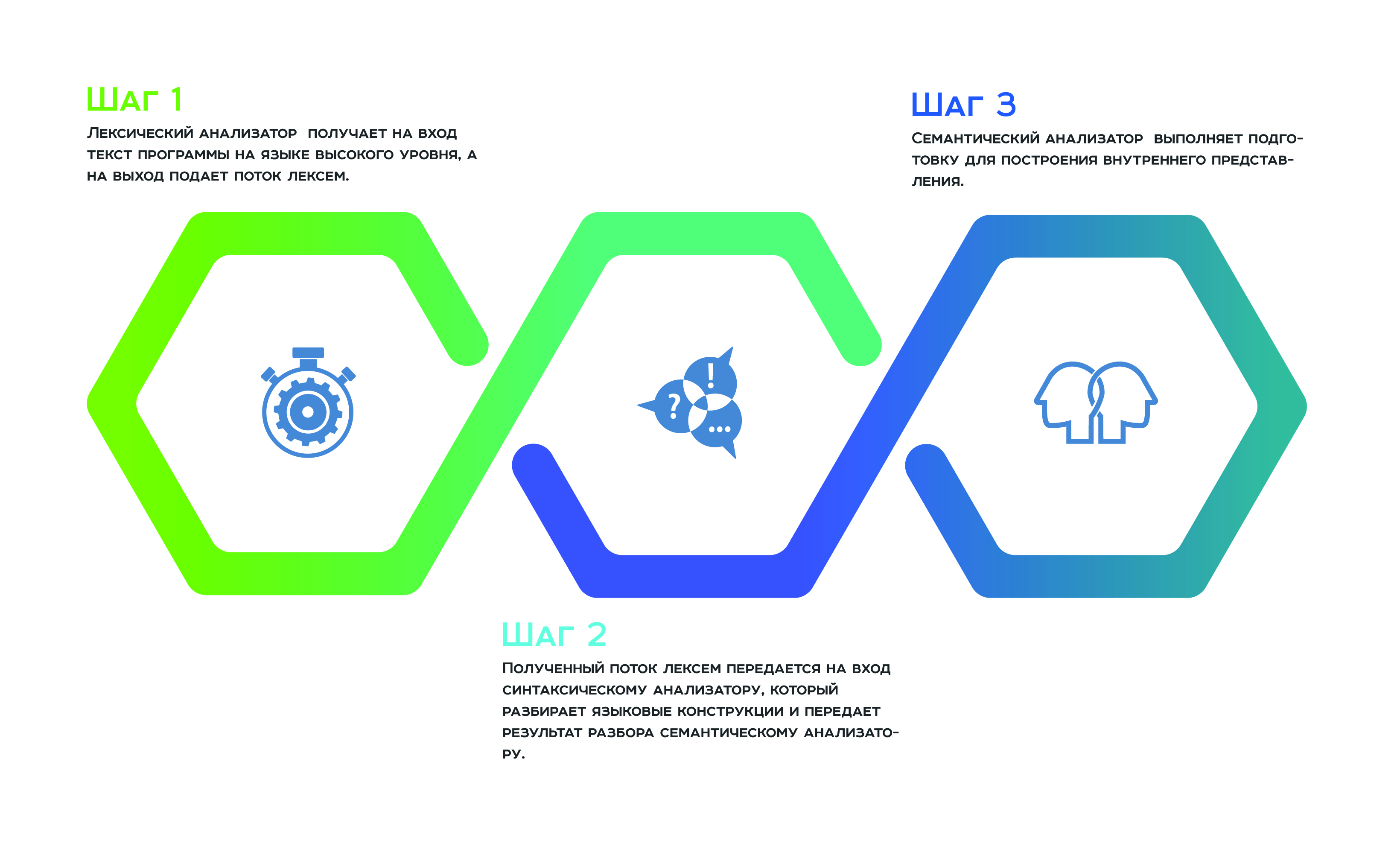
Everything begins with a lexical analysis , which receives the input of the program text in a high-level language, and a stream of lexemes delivers to the output. Then the resulting stream of tokens is passed to the input of the parser , which parses the language constructs and transfers the result of the parsing to the semantic analyzer., which as a result of its work performs the preparation for the construction of the internal representation. This internal representation is a feature of each static analyzer. The efficiency of the analyzer depends on how successful it is.
Many manufacturers of static analyzers state that they use a universal internal representation for all programming languages supported by the analyzer. In this way, they can analyze software code developed in several languages as a whole, and not as separate components. The “holistic approach” to the analysis allows you to avoid missing defects that arise at the interface between the individual components of the software product.
In theory, this is true, but in practice, a universal internal representation for all programming languages is difficult and inefficient. Every programming language is special. The internal representation is usually a tree whose vertices store attributes. By traversing such a tree, the analyzer collects and converts information. Therefore, each vertex of the tree must contain a uniform set of attributes. Since each language is unique, the uniformity of attributes can only be maintained by redundancy of the components. The more heterogeneous the programming languages, the more heterogeneous components in the characteristics of each vertex, and therefore, the internal representation is inefficient in memory. A large number of heterogeneous characteristics also affect the complexity of tree walkers, and therefore entails inefficiency in productivity.
Optimization Conversions for Static Analyzers
In order for a static analyzer to work efficiently in memory and time, one must have a compact universal internal representation, and this can be achieved by the fact that the internal representation is divided into several trees, each of which is developed for related programming languages.
The optimization work is not limited to the division of the internal representation into related programming languages. Next, manufacturers use various optimization pre- transformations - the same as in compiler technologies, in particular, optimization transformations of cycles. The point is that the goal of static analysis ideally is to carry out the promotion of the data on the program in order to evaluate their transformation during the execution of programs. Therefore, the data must be "advanced" through each turn of the cycle. So, if we save on these very turns and make them significantly less, then we will get significant benefits both in memory and in performance. It is for this purpose that such transformations are actively used, which with some probability carry out an extrapolation of data conversion to all turns of the cycle by the minimum number of passes.
You can also save on branching by calculating the likelihood that program execution will follow a particular branch. If the probability of passing through a branch is lower than the specified one, then this branch of the program is not considered.
Obviously, each of these transformations "loses" the defects that the analyzer must detect, but this is a "fee" for efficiency in terms of memory and performance.
What is a static code analyzer looking for?
Conventionally, defects that in one way or another interest intruders and, consequently, auditors, can be divided into the following groups:
- validation errors
- information leakage errors
- authentication errors.
Validation errors result from the fact that the input data are not sufficiently fully checked for correctness. An attacker may slip in as input data is not what the program expects, and thus get unauthorized access to control. The most common data validation errors are in injections and XSS.. Instead of valid data, the attacker delivers to the program's input specially prepared data that carries a small program. This program, being processed, is executed. The result of its execution can be the transfer of control to another program, data corruption and much, much more. Also, as a result of validation errors, substitution of the site with which the user works can be performed. Quality validation errors can be detected by static code analysis methods.
Information leakage errors- These are errors due to the fact that sensitive information from the user as a result of processing was intercepted and transmitted to the attacker. It may be the opposite: sensitive information that is stored in the system, in the process of its movement to the user is intercepted and transmitted to the attacker.
Such vulnerabilities are just as difficult to detect as validation errors. Detection of such errors requires tracking in the statics of promotion and transformation of data across the entire program code. This requires the implementation of methods such as taint analysis and interprocedural data analysis . The accuracy of the analysis depends on how well these methods are developed, namely, the minimization of false positives and missed errors.
Also, a significant role in the accuracy of the static analyzer is played by the library of defect detection rules, in particular, the format for describing these rules. All this is a competitive advantage of each analyzer and is carefully guarded from competitors.
Authentication errors are the most interesting errors for an attacker, since they are difficult to detect because they occur at the junction of components and are difficult to formalize. Attackers exploit these kinds of errors to escalate access rights. Authentication errors are not automatically detected, since it is not clear what to look for - these are errors of the program building logic.
Memory errors
They are difficult to detect, because for accurate identification it is required to solve a cumbersome system of equations, and this is expensive both in memory and in performance. Consequently, the system of equations is reduced, which means that accuracy is lost.
Typical memory errors include use-after-free , double-free , null-pointer-dereference and their variations, for example, out-of-bounds-Read and out-of-bounds-Write .
When the next analyzer failed to detect a memory leak, you can hear that such defects are difficult to exploit. The attacker must be highly qualified and apply a lot of skill to, first, to find out about the presence of such a defect in the code, and, secondly, to make an exploit. Well, and further the argument is: “Are you sure that your software product is interesting for a guru of this level?” ... However, history knows cases when memory errors were successfully exploited and caused considerable damage. Examples of such well-known situations include:
- CVE-2014-0160 - an error in the openssl library - a potential compromise of private keys required to reissue all certificates and regenerate passwords.
- CVE-2015-2712 - Error in js implementation in mozilla firefox - bounds check.
- CVE-2010-1117 - use after free in internet explorer - remotely exploitable.
- CVE-2018-4913 - Acrobat Reader - code execution.
More attackers like to exploit the defects associated with incorrect synchronization of the threads or processes. Such defects are difficult to identify in statics, because it is not an easy task to model the state of a machine without the concept of “time”. This is due to race-condition errors . Today, parallelism is used everywhere, even in very small applications.
Summarizing the above, it should be noted that the static analyzer is useful in the development process, if it is properly used. During operation, it is necessary to understand what to expect from it and how to deal with those defects that the static analyzer cannot identify in principle. If they say that a static analyzer is not needed during the development process, then it simply does not know how to exploit it.

How to properly operate a static analyzer, correctly and effectively work with the information that it gives out, read on in our blog.