33 dual-unit servers for 13 TB of RAM and 0.6 PT of distributed storage - why is this a minimum for proactive UBA
Screenshot of data collected:

Modern security systems are VERY gluttonous to resources. Why? Because they consider more than many production server and business intelligence systems.
What do they think? I'll explain now. Let's start with the simple: conventionally, the first generation of protective devices was very simple - at the level of “let in” and “not let in”. For example, a firewall allowed traffic according to certain rules and did not allow traffic on others. Naturally, for this special computing power is not needed.
The next generation has gotten more complicated rules. Thus, reputation systems emerged that, depending on strange user actions and changes in business processes, assigned them a reliability rating based on predefined patterns and manually set trigger thresholds.
Now UBA systems (User Behavior Analytics) analyze the behavior of users, comparing them with other employees of the company, and evaluate the consistency and accuracy of each employee’s actions. This is done at the expense of Data Lake-methods and quite resource-intensive, but automated processing by machine learning algorithms is primarily because it takes several thousand man-days to prescribe all possible scenarios.
Until about 2016, the approach was considered progressive when all events from all network nodes are collected in one place where the analytics server is located. The analytics server is able to collect, filter events and map them to correlation rules. For example, if a massive recording of files on a workstation starts suddenly, then this may be a sign of the encryption virus, or it may not be. But the system will send a notification to the admin just in case. If there are several stations, the probability of malware deployment increases. It is necessary to raise the alarm.
If a user knocks on some strange domain, registered a couple of weeks ago, and after a couple of minutes all this color music went, then this is almost certainly a crypto virus. It is necessary to extinguish the workstation and isolate the network segment, simultaneously notifying admins.
SIEM compared data from DLP, firewall, antispam, and so on, and this made it possible to respond very well to various threats. The weak point was these patterns and triggers - what is considered a dangerous situation and what is not. Further - as in the case of viruses and various cunning DDoS - the specialists of the SOC-centers began to form their bases of signs of attacks. For each type of attack, a scenario was considered, symptoms were identified, additional actions were assigned to them. All this required continuous revision and system adjustment in the 24/7 mode.
That is why you can not do without UBA? The first problem is that it is impossible to register everything with your hands. Because different services behave differently - and different users too. If you register events for the average user within the company, support, accounting, the tender department and admins will be very allocated. From the point of view of such a system, the admin is obviously a malicious user, because he creates a lot and actively climbs into it. Support is malicious because it connects to everyone. Accounting transmits data on encrypted tunnels. And the tender department constantly merges outward the company data when publishing documentation.
Conclusion - it is necessary to prescribe resource usage scenarios for each. Then deeper. Then even deeper. Then something changes in the processes (and this happens every day) and you need to register again.
It would be logical to use something like a “moving average” when the user rate is determined automatically. To this we will return.
The second problem was that the attackers have become at times more careful. Previously, data dumping, even if you missed the moment of hacking itself, was quite easy to catch - for example, hackers could upload the file of interest to themselves in the mail or file sharing service and, at best, encrypt to the archive to avoid detection by the DLP system.
Now everything is more interesting. This is what we met in our SOC centers over the past year.
For penetration, usually strictly custom virus is used, made right under the users of the target company. And the attacks often go through an intermediate link. For example, at first the contractor is compromised, and then through it the malware is entered into the main company.
Viruses of the last years almost always sit strictly in the RAM and are deleted at the very first whistle - an emphasis on the absence of traces. Forensic in such conditions is very difficult.
The overall result - SIEM does not do well. A lot that goes out of sight. Approximately an empty space appeared on the market: so that the system should not be tuned to the type of attack, but she herself understood what was wrong.
The first reputational security systems were anti-fraud modules for protection against money laundering in banks. For a bank, the main thing is to identify all fraudulent transactions. That is, it is not a pity to go too far, the main thing is that the human operator understands what you need to look at first. And he was not overloaded with very minor alarms.
Systems work like this:
About the last talk in more detail.
Example 1. All your life you bought yourself a pie and a cola at McDonalds on Fridays, and then suddenly bought 500 rubles on Tuesday morning. Minus 2 points for non-standard time, minus 3 points for non-standard purchase. The alarm threshold for you is set to –20. Nothing happens.
For about 5-6 such purchases you will bring these points to zero, because the system will remember that to go to McDonald’s on Tuesday morning is normal. Of course, I greatly simplify, but the logic of the work is approximately the same.
Example 2All your life you bought yourself various small things as a regular user. Pay at the grocery store (the system already “knows” how much you usually eat and where you buy it most often — more precisely, it does not know, but simply writes it in a profile), then buy a ticket in the metro for a month, then order something small through the online store. And here you are buying a piano in Hong Kong for 8 thousand dollars. Could it? Could. Let's look at the points: –15 for what it looks like a standard fraud, –10 for a non-standard amount, –5 for a non-standard place and time, –5 for another country without buying a ticket, –7 for not having anything before They took abroad, +5 for their standard device, +5 for what other users of the bank bought there.
The alarm threshold for you is set to –20. The transaction is “suspended”, an employee of the Bank’s IB starts to understand the situation. This is a very simple case. Most likely, in about 5 minutes he will call you and say: “Did you really decide to buy something at a music store in Hong Kong for 8 thousand dollars at 4 am?” If you answer yes, you will miss the transaction. The data will form in the profile as once performed action, further for similar actions will be given less negative points, until they become the norm at all.
As I said, I am very, very simple. Banks have invested in reputation systems for years and for years have honed them. Otherwise, a bunch of mules would withdraw money really quickly.
On the basis of the antifraud and anti-money laundering algorithms, behavioral analysis systems appear. A complete user profile is collected: how quickly it prints, to which resources it accesses, with whom it interacts, which software it launches - in general, everything that a user does every day.
Example. The user often interacts with 1C and often enters the data there, and then suddenly begins to unload the entire database in dozens of small reports. His behavior goes beyond the standard behavior for such a user, but it can be compared with the behavior of similar profiles by type (most likely it will be other accountants) - it shows that they have a week of reports on certain dates and they do it. The numbers are the same, there are no other differences, the alarm does not rise.
Another example.The user worked all his life with the file ball, writing a couple of dozen documents a day, and then suddenly began to take hundreds and thousands of files from it. And the DLP says it sends something important out. Maybe the tender department started preparing for the competition, maybe the "rat" merges the data to competitors. The system, of course, does not know it, but simply describes its behavior and alerts the security personnel. In principle, the behavior of a new employee, technical support or general director, can differ little from the behavior of a “misguided kazachka”, and the task of the security men is to tell the system that this is normal behavior. The profile will be added anyway, and if the CEO’s account is compromised and the reputation jumps by the points down, the alarm will rise.
User profiles generate rules for a UBA system. More precisely, thousands of heuristics that change regularly. For each group of users has its own principles. For example, users of this type send 100 MB per day, users of another type - 1 GB per day, if this is not a weekend. And so on. If the first one sends 5 GB, it is suspicious. And if the second - then there will be negative points, but they do not break the threshold of anxiety. But if next to him he turned on DNS to suspicious new domains, then there will be a couple of negative points and the alarm will already happen.
The approach is that this is not the rule “if there were strange DNS queries and then traffic jumped, then ...”, and the rule “if the reputation reached –20, then ...” - each individual source of points for the user's reputation or process is independent and determined solely the norm of his behavior. Automatically.
At the same time, at first, the IB department helps to train the system and determine what is normal and what is not, and then the system adapts, gets trained on real traffic and user activity logs.
As a system integrator, we provide our customers with the service of operational information security management (managed by CROC SOC ). A key component, along with systems such as Asset Management, Vulnerability Management, Security Testing and Threat Intelligence, available from our cloud infrastructure, is a link between the classic SIEM and proactive UBA. At the same time, depending on the wishes of the customer, for UBA we can use both industrial solutions of large vendors and our own analytical system based on the Hadoop + Hive + Redis + Splunk Analytics for Hadoop (Hunk) bundle.
The following solutions are available for behavioral analysis from our cloud CROC SOC or on the premise model:
And for critical segments, whether it is a process control system or a key business butt, we place additional sensors to collect extended forensics and hanitopes to distract the hacker's attention from productive systems.
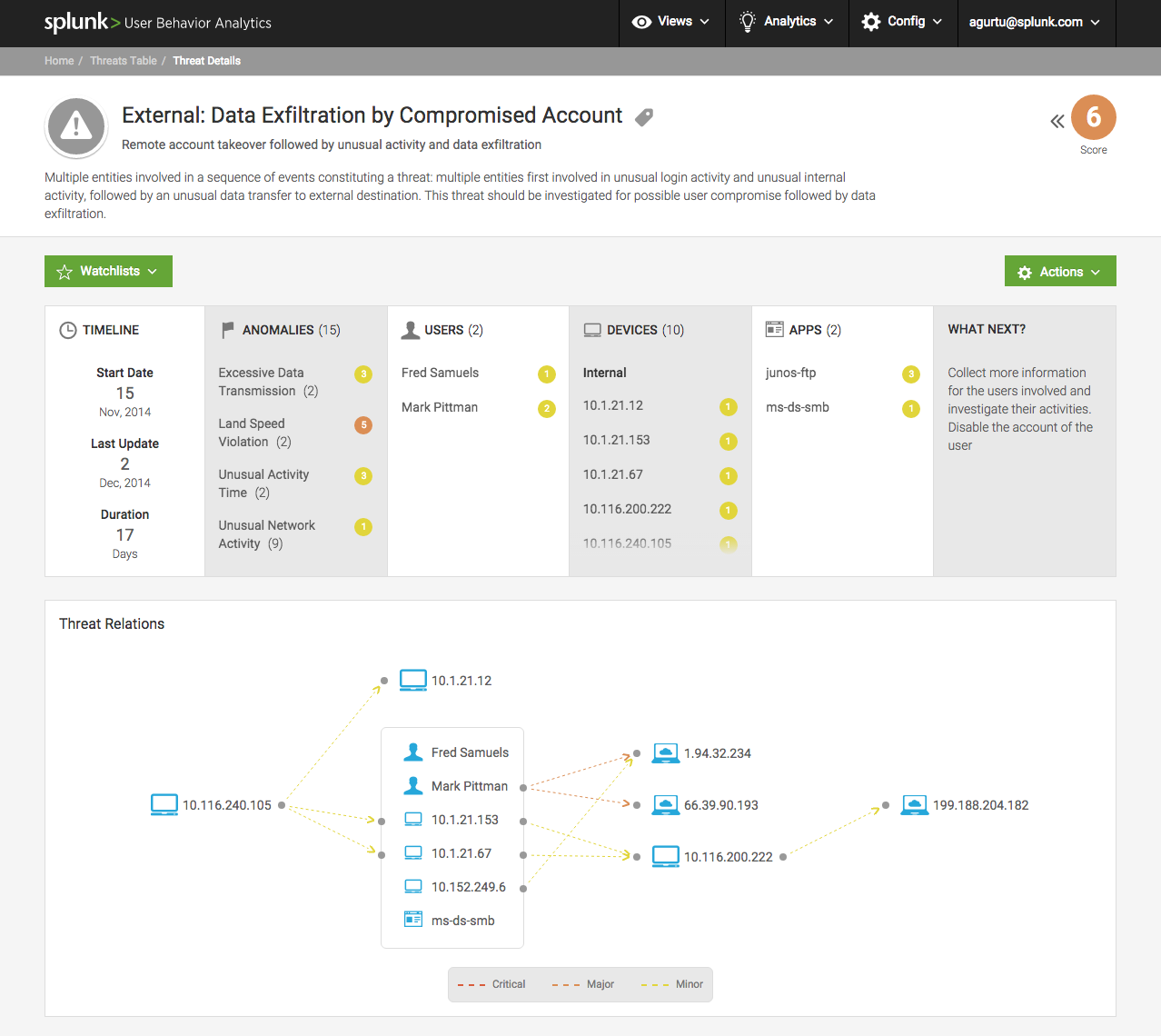
Because all events are written. It's like Google Analytics, only on the local AWP. In the local network, events are sent to Data Lake all, via Internet metadata about statistics and key events, but if the SOC operator wants to investigate the incident, there is also a complete log. Everything is collected: temporary files, registry keys, all running processes and their checksums, what is written in autoload, actions, screencast - anything. Below is an example of the data collected.
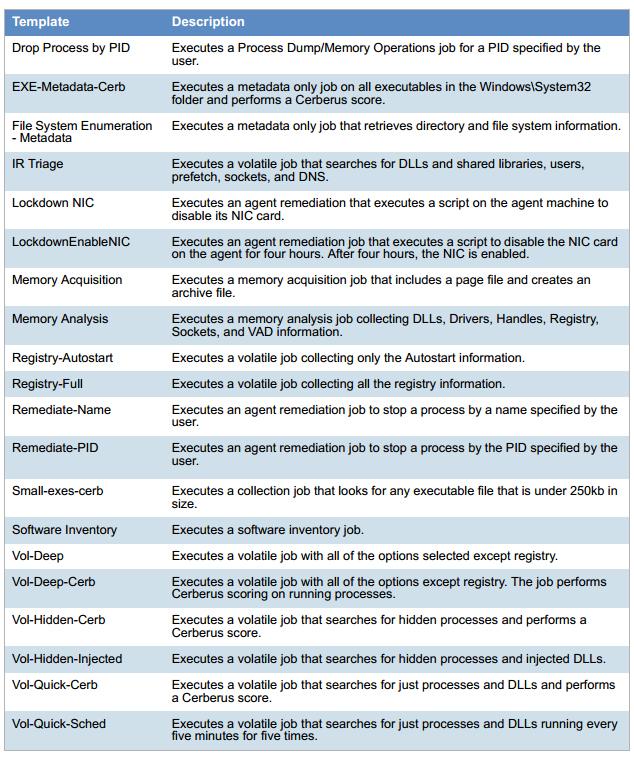
The list of parameters from the workstation:


Systems in terms of storage and RAM are much more complicated. Classic SIEM starts with 64 GB of RAM, a pair of processors and storage per half a byte. UBA is from terabyte of RAM and higher. For example, our last deployment was on 33 physical servers (28 computational nodes for data processing + 5 control nodes for load distribution), 150 TB lakes (600 TB in hardware, including fast cache on instances) and 384 GB of RAM each.
First of all, those who are in the “risk zone” and are constantly under attack are banks, financial institutions, the oil and gas sector, large retail and many others.
For such companies, the cost of leakage or data loss can amount to tens or even hundreds of millions of dollars. But installing a UBA system will be much cheaper. And of course, state-owned companies and telecom, because no one wants to at some point the data of millions of patients or the correspondence of tens of millions of people swim away into open access.
Modern security systems are VERY gluttonous to resources. Why? Because they consider more than many production server and business intelligence systems.
What do they think? I'll explain now. Let's start with the simple: conventionally, the first generation of protective devices was very simple - at the level of “let in” and “not let in”. For example, a firewall allowed traffic according to certain rules and did not allow traffic on others. Naturally, for this special computing power is not needed.
The next generation has gotten more complicated rules. Thus, reputation systems emerged that, depending on strange user actions and changes in business processes, assigned them a reliability rating based on predefined patterns and manually set trigger thresholds.
Now UBA systems (User Behavior Analytics) analyze the behavior of users, comparing them with other employees of the company, and evaluate the consistency and accuracy of each employee’s actions. This is done at the expense of Data Lake-methods and quite resource-intensive, but automated processing by machine learning algorithms is primarily because it takes several thousand man-days to prescribe all possible scenarios.
Classic SIEM
Until about 2016, the approach was considered progressive when all events from all network nodes are collected in one place where the analytics server is located. The analytics server is able to collect, filter events and map them to correlation rules. For example, if a massive recording of files on a workstation starts suddenly, then this may be a sign of the encryption virus, or it may not be. But the system will send a notification to the admin just in case. If there are several stations, the probability of malware deployment increases. It is necessary to raise the alarm.
If a user knocks on some strange domain, registered a couple of weeks ago, and after a couple of minutes all this color music went, then this is almost certainly a crypto virus. It is necessary to extinguish the workstation and isolate the network segment, simultaneously notifying admins.
SIEM compared data from DLP, firewall, antispam, and so on, and this made it possible to respond very well to various threats. The weak point was these patterns and triggers - what is considered a dangerous situation and what is not. Further - as in the case of viruses and various cunning DDoS - the specialists of the SOC-centers began to form their bases of signs of attacks. For each type of attack, a scenario was considered, symptoms were identified, additional actions were assigned to them. All this required continuous revision and system adjustment in the 24/7 mode.
Works - do not touch, well everything works!
That is why you can not do without UBA? The first problem is that it is impossible to register everything with your hands. Because different services behave differently - and different users too. If you register events for the average user within the company, support, accounting, the tender department and admins will be very allocated. From the point of view of such a system, the admin is obviously a malicious user, because he creates a lot and actively climbs into it. Support is malicious because it connects to everyone. Accounting transmits data on encrypted tunnels. And the tender department constantly merges outward the company data when publishing documentation.
Conclusion - it is necessary to prescribe resource usage scenarios for each. Then deeper. Then even deeper. Then something changes in the processes (and this happens every day) and you need to register again.
It would be logical to use something like a “moving average” when the user rate is determined automatically. To this we will return.
The second problem was that the attackers have become at times more careful. Previously, data dumping, even if you missed the moment of hacking itself, was quite easy to catch - for example, hackers could upload the file of interest to themselves in the mail or file sharing service and, at best, encrypt to the archive to avoid detection by the DLP system.
Now everything is more interesting. This is what we met in our SOC centers over the past year.
- Steganography by sending photos to Facebook. The malware registered with the FB and subscribed to the group. Each photograph published in the group was supplied with a built-in data chunk containing instructions for the malware. Taking into account losses during JPEG compression, it was possible to transfer about 100 bytes per image. Also, the malware itself spread out 2-3 photos per day to the social network, which was enough to transfer logins / passwords merged through mimikatz.
- Filling out forms on sites. The malware launched the user's actions simulator, went to certain sites, found feedback forms there and sent data through them, encoding binary data in BASE64. This we have already caught on the system of the new generation. On the classic SIEM, without knowing about this method of sending, most likely, they would not even notice anything.
- In a standard way, alas, in a standard way, the data was mixed into the DNS traffic. There are a lot of steganography technologies in DNS and in general tunneling through DNS; here the emphasis was not on a survey of certain domains, but on the types of request. The system raised a minor alarm on the growth of DNS traffic for the user. Data was sent slowly and at different intervals to make analysis more difficult with remedies.
For penetration, usually strictly custom virus is used, made right under the users of the target company. And the attacks often go through an intermediate link. For example, at first the contractor is compromised, and then through it the malware is entered into the main company.
Viruses of the last years almost always sit strictly in the RAM and are deleted at the very first whistle - an emphasis on the absence of traces. Forensic in such conditions is very difficult.
The overall result - SIEM does not do well. A lot that goes out of sight. Approximately an empty space appeared on the market: so that the system should not be tuned to the type of attack, but she herself understood what was wrong.
How did she “understand” herself?
The first reputational security systems were anti-fraud modules for protection against money laundering in banks. For a bank, the main thing is to identify all fraudulent transactions. That is, it is not a pity to go too far, the main thing is that the human operator understands what you need to look at first. And he was not overloaded with very minor alarms.
Systems work like this:
- They build a user profile using a variety of parameters. For example, how he usually spends money: what he buys, how he buys, how quickly he enters a confirmation code, from which devices he does it, etc.
- The logic layer checks whether it is possible to have time to get from the point where payment was made to another point on the transport during the period between transactions. If the purchase is in another city, it is checked whether the user often travels to other cities, if in another country - if the user often visits other countries, and a recently purchased air ticket adds chances that the alarm is not needed.
- Reputation module - if the user does everything within the framework of his normal behavior, then positive points are charged for his actions (very slowly), and if within the atypical - negative ones.
About the last talk in more detail.
Example 1. All your life you bought yourself a pie and a cola at McDonalds on Fridays, and then suddenly bought 500 rubles on Tuesday morning. Minus 2 points for non-standard time, minus 3 points for non-standard purchase. The alarm threshold for you is set to –20. Nothing happens.
For about 5-6 such purchases you will bring these points to zero, because the system will remember that to go to McDonald’s on Tuesday morning is normal. Of course, I greatly simplify, but the logic of the work is approximately the same.
Example 2All your life you bought yourself various small things as a regular user. Pay at the grocery store (the system already “knows” how much you usually eat and where you buy it most often — more precisely, it does not know, but simply writes it in a profile), then buy a ticket in the metro for a month, then order something small through the online store. And here you are buying a piano in Hong Kong for 8 thousand dollars. Could it? Could. Let's look at the points: –15 for what it looks like a standard fraud, –10 for a non-standard amount, –5 for a non-standard place and time, –5 for another country without buying a ticket, –7 for not having anything before They took abroad, +5 for their standard device, +5 for what other users of the bank bought there.
The alarm threshold for you is set to –20. The transaction is “suspended”, an employee of the Bank’s IB starts to understand the situation. This is a very simple case. Most likely, in about 5 minutes he will call you and say: “Did you really decide to buy something at a music store in Hong Kong for 8 thousand dollars at 4 am?” If you answer yes, you will miss the transaction. The data will form in the profile as once performed action, further for similar actions will be given less negative points, until they become the norm at all.
As I said, I am very, very simple. Banks have invested in reputation systems for years and for years have honed them. Otherwise, a bunch of mules would withdraw money really quickly.
How is this shifted to the IS of the enterprise?
On the basis of the antifraud and anti-money laundering algorithms, behavioral analysis systems appear. A complete user profile is collected: how quickly it prints, to which resources it accesses, with whom it interacts, which software it launches - in general, everything that a user does every day.
Example. The user often interacts with 1C and often enters the data there, and then suddenly begins to unload the entire database in dozens of small reports. His behavior goes beyond the standard behavior for such a user, but it can be compared with the behavior of similar profiles by type (most likely it will be other accountants) - it shows that they have a week of reports on certain dates and they do it. The numbers are the same, there are no other differences, the alarm does not rise.
Another example.The user worked all his life with the file ball, writing a couple of dozen documents a day, and then suddenly began to take hundreds and thousands of files from it. And the DLP says it sends something important out. Maybe the tender department started preparing for the competition, maybe the "rat" merges the data to competitors. The system, of course, does not know it, but simply describes its behavior and alerts the security personnel. In principle, the behavior of a new employee, technical support or general director, can differ little from the behavior of a “misguided kazachka”, and the task of the security men is to tell the system that this is normal behavior. The profile will be added anyway, and if the CEO’s account is compromised and the reputation jumps by the points down, the alarm will rise.
User profiles generate rules for a UBA system. More precisely, thousands of heuristics that change regularly. For each group of users has its own principles. For example, users of this type send 100 MB per day, users of another type - 1 GB per day, if this is not a weekend. And so on. If the first one sends 5 GB, it is suspicious. And if the second - then there will be negative points, but they do not break the threshold of anxiety. But if next to him he turned on DNS to suspicious new domains, then there will be a couple of negative points and the alarm will already happen.
The approach is that this is not the rule “if there were strange DNS queries and then traffic jumped, then ...”, and the rule “if the reputation reached –20, then ...” - each individual source of points for the user's reputation or process is independent and determined solely the norm of his behavior. Automatically.
At the same time, at first, the IB department helps to train the system and determine what is normal and what is not, and then the system adapts, gets trained on real traffic and user activity logs.
What do we put
As a system integrator, we provide our customers with the service of operational information security management (managed by CROC SOC ). A key component, along with systems such as Asset Management, Vulnerability Management, Security Testing and Threat Intelligence, available from our cloud infrastructure, is a link between the classic SIEM and proactive UBA. At the same time, depending on the wishes of the customer, for UBA we can use both industrial solutions of large vendors and our own analytical system based on the Hadoop + Hive + Redis + Splunk Analytics for Hadoop (Hunk) bundle.
The following solutions are available for behavioral analysis from our cloud CROC SOC or on the premise model:
- Exabeam: perhaps the most user-friendly UBA system in use that allows you to quickly investigate an incident using User Tracking technology, which links activity in the IT infrastructure (for example, local login to the database under the SA account) with a real user. It includes about 400 risk-scoring models that add penalties to the user for each strange or suspicious action;
- Securonix: a very voracious to resources, but extremely effective system of behavioral analysis. The system is placed on top of the Big Data platform, out of the box almost 1000 models are available. Most of them use proprietary user activity clustering technology. The engine is very flexible, you can track and cluster any field of the CEF format, starting with a deviation from the average number of requests per day in the logs of the web server and ending with the identification of new network interactions on user traffic;
- Splunk UBA: A Good Addition To Splunk ES. The base of rules out of the box is small, but linked to the Kill Chain, which allows you not to be distracted by minor incidents and focus your attention on the real hacker. And of course, at our disposal all the power of statistical data processing on the Splunk Machine Learning Toolkit and retrospective analysis of the entire volume of accumulated data.
And for critical segments, whether it is a process control system or a key business butt, we place additional sensors to collect extended forensics and hanitopes to distract the hacker's attention from productive systems.
Why a sea of resources?
Because all events are written. It's like Google Analytics, only on the local AWP. In the local network, events are sent to Data Lake all, via Internet metadata about statistics and key events, but if the SOC operator wants to investigate the incident, there is also a complete log. Everything is collected: temporary files, registry keys, all running processes and their checksums, what is written in autoload, actions, screencast - anything. Below is an example of the data collected.
The list of parameters from the workstation:
Systems in terms of storage and RAM are much more complicated. Classic SIEM starts with 64 GB of RAM, a pair of processors and storage per half a byte. UBA is from terabyte of RAM and higher. For example, our last deployment was on 33 physical servers (28 computational nodes for data processing + 5 control nodes for load distribution), 150 TB lakes (600 TB in hardware, including fast cache on instances) and 384 GB of RAM each.
Who needs it?
First of all, those who are in the “risk zone” and are constantly under attack are banks, financial institutions, the oil and gas sector, large retail and many others.
For such companies, the cost of leakage or data loss can amount to tens or even hundreds of millions of dollars. But installing a UBA system will be much cheaper. And of course, state-owned companies and telecom, because no one wants to at some point the data of millions of patients or the correspondence of tens of millions of people swim away into open access.
Links
- SOC Centers
- A big company that has not been engaged in information security for 5 years and survived
- Proprietary UBA Systems Website
- My mail for questions is dberezin@croc.ru