ITIL (Problem Management) using OTRS

Let me remind you that the main goal of Incident Management is to restore the service as quickly as possible, which sometimes becomes like trying to extinguish a forest fire with a shovel. Since, having extinguished the ignition on a single hill, we will not eliminate the general calamity, but having extinguished the entire area of ignition, we will not solve the problem of the appearance of a new outbreak in the next season or even the next day. It is necessary to deal with the cause of the fire, whether it is tourists and it is necessary to conduct agitation (training), or it is a swampy, dry forest, and it is necessary to carry out its cleaning (modernization).
Or, for example, a case in life: when printing on a printer with several trays, paper jammed from one tray, as a result, the trays changed within the framework of Incident Management, thereby temporarily eliminating the problem of jamming. And this situation was repeated for several days, causing inconvenience to users, and distracting IT professionals. In this example, Problem Manegement showed that the cause was the wear of the paper feed rollers and after replacing them, the printer began to operate normally.
Go deeper!

Bit of theory
According to ITIL, a problem is an unknown cause of one or more incidents. Just what you need!
So, and if you look at the main task of Problem Management - to prevent the occurrence of problems, eliminate the occurrence of recurring incidents and minimize the impact of incidents that cannot be prevented.
Why it is necessary to manage problems from a business point of view, probably, it is a higher availability of IT services, higher productivity of staff, including IT, cost reduction due to the absence of repeated incidents.
Here we will consider reactive problem management, i.e., response to the fact that a problem is detected.
Let's move on to implementation
- What, problems?

How are we looking for problems? Here, we are assisted by monitoring tools, ServiceDesk, incidents, data from suppliers or data received from Proactive Problem Management.
When it became clear that we are actually registering a problem in the agent interface, for this it is necessary to perform a number of manipulations in the admin part of OTRS.
To register problems, you need to activate the Problem application type.
Next, you must hide the types of applications from users.
Ticket -> Frontend :: Customer :: Ticket :: ViewNew set the parameter Ticket :: Frontend :: CustomerTicketMessage ### TicketType - No
Thus, simplifying the task for the user and complicating the task ServiceDesk.
To unload the agent interface, we enter the queue "Problem Queue". Now all problems are available only to those agents who are allowed on a separate tab.
In this case, we assign the description of the application to ServiceDesk or to Problem Manager in the case of a description of the problem. that is, add for the agent the right to the “Queue of problems”
Classification

We decided to focus on the classification of services, although it can be classified in turn. The classification should be the same as in Incident Management for more convenient presentation and further debriefing together with Incident Management.
In the right window “Application Information” contains information about the service, SLA, the time of decision on the application in accordance with the SLA.
The bottom part displays incidents that relate to this problem, ConfigItem is also attached, that is, the printer we are working on in the context of this problem, when we click on the link, we can see additional information on it.
Priorities
Level 5. Major problem - requiring immediate solution, as a rule - these are problems affecting top management, or affecting a large number of users.
Level 2-4 All other problems
Level 1. Affecting a small number of users.
Search for a reason
This is where the work itself begins. It is necessary to determine the cause of the problem.
All work performed is recorded through notes, replenishing the problem log, which can talk about the effectiveness of IT service employees, as well as come in handy when similar problems occur. It also records the time spent on the work. The total time for the problem is summed from the time for all notes.
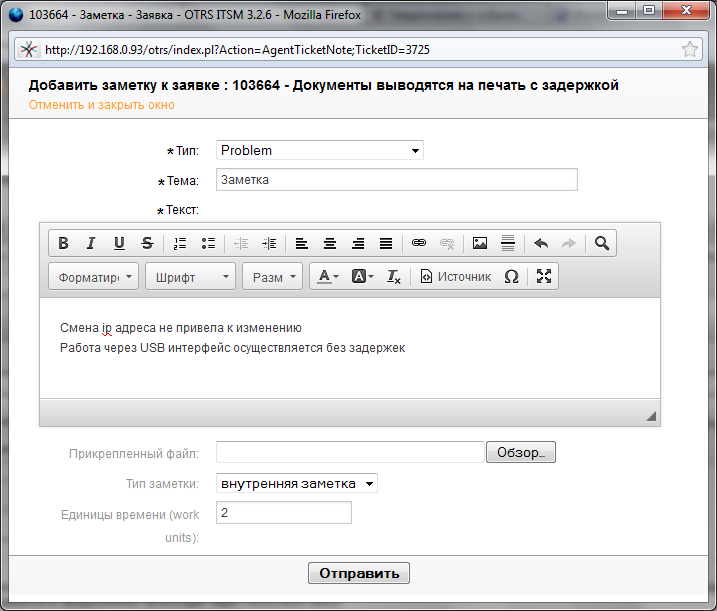
If we are lucky and we determined the reason, we go to the agent interface and describe it.
You must provide a reason code for a global analysis of the causes of all problems, adding a description if necessary.
If we haven’t got to the root of the problem yet, but have found a workaround, it is necessary to fix it in order to increase the time needed to resolve new incidents. ITIL recommends creating a Known Error Record. However, I am using the change of the request type from Problem to Problem.Known Error.
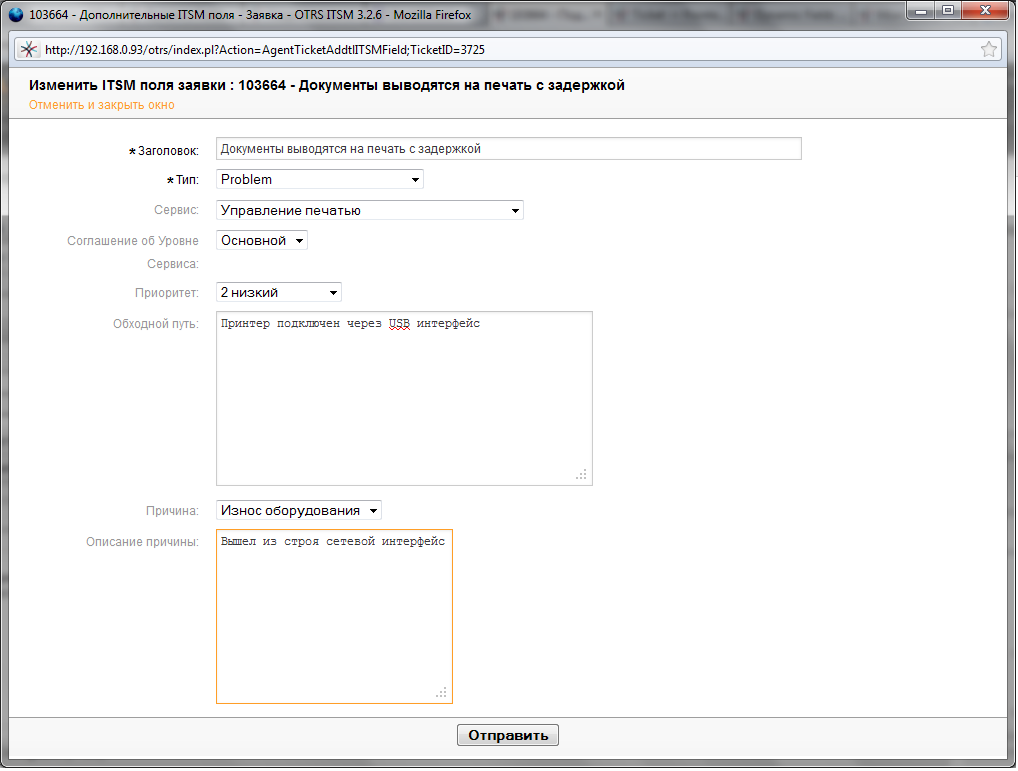
Again, we are doing some manipulations, namely, adding the necessary fields for applications and their values.
DynamicField (Dynamic Fields) is responsible for these settings, the revised functionality that appeared in version 3.2 of OTRS
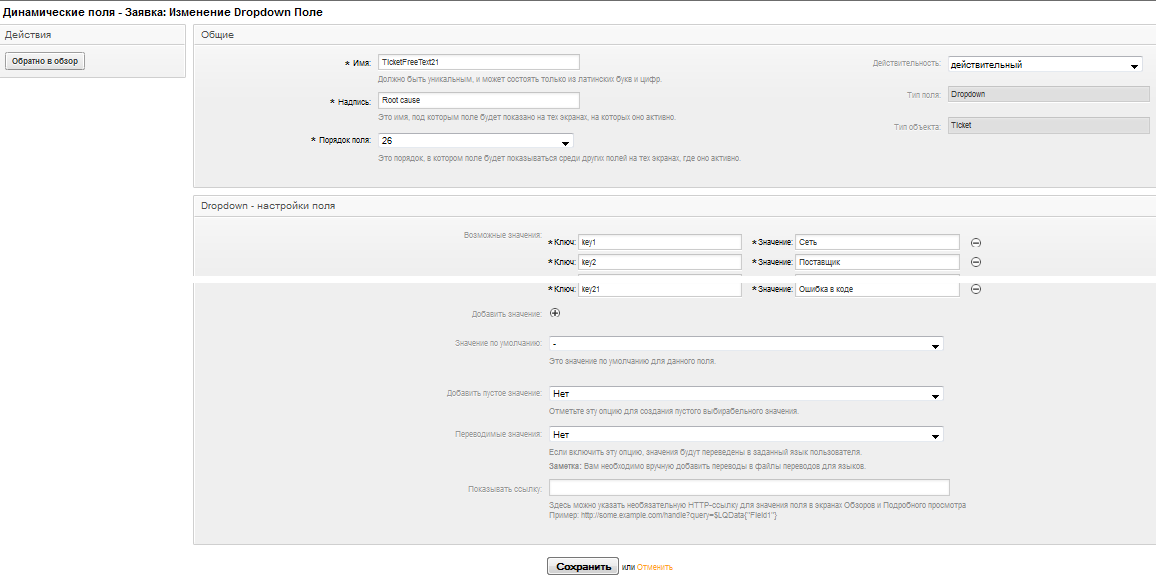
We need the fields Cause (Dropdown), Description of the cause (TextArea), Workaround (TextArea) The
description of all fields is done in English, and the translation is done through a file ru.pm located in the folder / opt / otrs / Kernel / Language /
We set predefined values for the Dropdown field.
Add in the configuration Ticket -> Frontend :: Agent :: Ticket :: ViewAddtlITSMField

This is how it looks in the agent interface.
Decision
After a solution to the problem is found, we must formally close the problem by changing its status to "Closed successfully."
Reporting
Management reporting
- The number of problems recorded over a given period.
- The cost of solving problems for the reporting period
- % problems with priority 5
Reporting Problem Manager
- The cause of the problems for a certain period, by services, by type CI.
PS In version 3.2, a new feature appeared: ProcessManagment, which allows you to manage applications using WorkFlow, so you have to return to the Request Fulfillment process