I, RoboLoyer, or how to look for anomalies in documents
Can you imagine how many regulatory documents per hour a corporate lawyer has to look through and what consequences can his negligence lead to? A poor fellow lawyer should read into every contract, especially if there is no standard template for him, which happens often.
Looking into the tired eyes of our corporate lawyer, we decided to create a service that will find the problems in the documents and signal them to the dozing lawyer. As a result, we created a solution with the aggregation of knowledge on a certain base of contracts and tips for lawyers, to which we should pay special attention. Of course, not without magic. Mathematical magic called Anomaly Detection.
Basically, Anomaly Detection approaches are used to analyze the behavior of a variety of equipment to detect failures, or in the banking sector to identify fraud. And we tried to apply these algorithms for the analysis of legal documents. Follow the cat to find out how we did it.

We are lucky because the texts in the contracts are rather structured, dry and are drawn up according to certain templates. To work on the project, an idea was proposed to implement a prototype based on contracts and contracts from the website zakupki.gov.ru (we extracted 200,000 documents). For 170,000 treaties, we were able to distinguish the structure: preamble, chapters, clauses, and annexes to the treaty, taking into account key words, position in the text, and numbering.
It is necessary to take into account the fact that contracts can be of different types. All of them are very different in content, subject of the contract, the main chapters, etc. To optimize the analysis of each type of contract, it is necessary to work on their classification or clustering.
Perhaps you already know what types of contracts are present in your database, and you know the signs by which they can be determined. In our case, we have a raw corpus of contracts without any additional information about each contract and without any assumptions about the classification of procurement contracts. Therefore, we were forced to resort to the clustering of our database of contracts.
You can implement clustering standardly using tf-idf document presentation vector, but we decided to try the Doc2Vec algorithm, just for fun. Using the Doc2Vec algorithm, contracts were translated into vectors, and the resulting contract vectors were sent to the input to the clustering algorithm. We used the K-means algorithm for clustering vectors. Since the similarity is usually measured using a cosine distance, we used it instead of the Euclidean distance.
After receiving 20 clusters of documents, it was necessary to check the quality of clustering. Since we do not have any classification of contracts, we cannot compare the obtained clusters with the existing splitting. Then we decided to look at the words that describe the cluster. For this, they took the “Subject of the contract” clauses for each cluster, deleted stop words, numbers and words that are found in most clusters. Then we selected the 5 most common words for each cluster as keywords. In this simple way, one can subjectively evaluate the quality of clustering.
Examples of words that described clusters:
Let's determine which cases we consider to be abnormal and what we can do with them. We have identified the following scenarios:
As already mentioned, the contract consists of chapters, chapters are divided into clauses, each clause may contain sub-clauses, etc. To break the agreement into chapters and paragraphs, we took into account numbering, hyphenation, keywords: “Chapter,” “Article,” etc. Each item consists of one or more sentences. For splitting an item into sentences, used sent_tokenize from the nltk.tokenize module.
The contract itself contains several global chapters, the essence and content of which can be recognized by the headings: the subject of the contract, the rights and obligations of the parties, the price and the settlement procedure ... We tried to combine the chapters with the same headings and work with the various chapters independently. Chapter titles are often rephrased, have typos or extra punctuation. In order to make groups of chapters large enough, we combined into one group those headlines that were close in Levenshtein distance.
One of the problems that we can definitely face is a huge amount of named entities in contracts, which are often unique and can be mistaken for an anomaly. In contracts, there are many such entities as names, company names, dates, addresses, etc., which vary from contract to contract. It is necessary to find and eliminate such entities from the contract, i.e. to bring the contract to some kind of template. We were lucky with dataset, because in the unloading of contracts there was a large proportion of template contracts, the named entities in which were replaced with underscores. We found between what phrases underscores are usually found in order to find these phrases in the completed documents and remove named entities from them. It is clear that in this way we did not delete all the named entities. Therefore, we once again walked through the building of the Natasha library and deleted entities,
We were able to separate the contracts by type using clustering and were able to identify groups of similar chapters. Now, using the accumulated knowledge of a certain clause of a certain type of contract, we can understand what needs to be corrected in the current one. Let's calculate for each sentence of the chapter the probability of its anomaly.
For each group of chapters we keep all the offers that we met in our training set of documents from the State Procurement. Since there are quite a large number of them; for each group of chapters, the Word2Vec model was trained, and each sentence was assigned a vector of weighted (in tf-idf) sum of the vectors of its words. Next, the proposal vectors were divided into clusters in a similar way to the splitting of vectors for documents.
Now, when a proposal comes to us, we determine from which cluster of contracts it is, from which group of chapters, to which cluster of proposals it is closest, and in this cluster we find the nearest one. The distance to the nearest offer can be regarded as a measure of how abnormal the offer is. If the distance to the nearest offer is zero, then our offer is not abnormal. When increasing this distance, we are increasingly doubted that the proposal does not contain anomalies. Most likely something wrong with him.
We figured out how to find anomalous clauses in a contract, but did not learn to find anomalies in the form of missing sentences or clauses. Such an anomaly can be easily found if we have a template of this type of contract in our hands, but, for example, there are cases when another company sent us a contract drawn up according to its own template.
To detect such anomalies, we need to create a template for a contract with a set of mandatory offers / points, again based only on the existing base of contracts.
We invented and tested the template construction algorithm. This algorithm assumes that in our contract database there is a similar chapter with the correct set of items, which we want to identify and indicate as a template.
Algorithm:

Having received a template for each chapter, we can identify the missing points that are present in the template, but not in the current contract, and advise a lawyer to add them.
Let's summarize and collect all the steps together:
To assess the quality of the solutions to the problem, a test set of contracts was formed. Anomalies were artificially added to treaties in the form of deleting a part of words, inserting words / phrases into sentences, inserting sentences from other chapters, and deleting sentences. We evaluated the quality for each type of anomaly and obtained the following distributions of definition errors: That is, the proposed algorithm allows us to determine incorrect inclusions in 4 of 5 cases. It should be noted that with an increase in the size of the training sample and the clustering of contracts for different types, we can get an improvement to this estimate.


To visualize such a solution of the problem, a web interface was implemented in which you can download a new contract, the text of which will be displayed on the page and the anomalous sentences will be highlighted in color. The darker the color of the sentence, the more we are sure that it is anomalous. Since we have found the nearest offer, we suggest editing for the user in the form of this nearest offer, or we advise you to change the specific part of the offer if the closest one has a slight difference with the original one.

Practical application of the resulting service is most appropriate in cases where a “streaming” examination of the legal purity of a large number of similar documents is required: for example, when issuing mortgage loans to the public (mortgage, car loans and insurance). For example, in the case of a mortgage, these are real estate purchase and sale contracts, real estate and borrower insurance contracts, property valuation contracts, etc. - hundreds of pages of text in the file of each client, which can be analyzed almost instantly, and anomalous places will be “highlighted” to a lawyer for analysis on risks or fraud.
So, absolutely no lawyers from flesh and blood can not do, but modern technologies allow them to make life easier for them.
Material prepared by Elena Sannikova ( helen_sunny).
Looking into the tired eyes of our corporate lawyer, we decided to create a service that will find the problems in the documents and signal them to the dozing lawyer. As a result, we created a solution with the aggregation of knowledge on a certain base of contracts and tips for lawyers, to which we should pay special attention. Of course, not without magic. Mathematical magic called Anomaly Detection.
Basically, Anomaly Detection approaches are used to analyze the behavior of a variety of equipment to detect failures, or in the banking sector to identify fraud. And we tried to apply these algorithms for the analysis of legal documents. Follow the cat to find out how we did it.
1. We deal with structured information
We are lucky because the texts in the contracts are rather structured, dry and are drawn up according to certain templates. To work on the project, an idea was proposed to implement a prototype based on contracts and contracts from the website zakupki.gov.ru (we extracted 200,000 documents). For 170,000 treaties, we were able to distinguish the structure: preamble, chapters, clauses, and annexes to the treaty, taking into account key words, position in the text, and numbering.
2. Variety of contract types
It is necessary to take into account the fact that contracts can be of different types. All of them are very different in content, subject of the contract, the main chapters, etc. To optimize the analysis of each type of contract, it is necessary to work on their classification or clustering.
Perhaps you already know what types of contracts are present in your database, and you know the signs by which they can be determined. In our case, we have a raw corpus of contracts without any additional information about each contract and without any assumptions about the classification of procurement contracts. Therefore, we were forced to resort to the clustering of our database of contracts.
You can implement clustering standardly using tf-idf document presentation vector, but we decided to try the Doc2Vec algorithm, just for fun. Using the Doc2Vec algorithm, contracts were translated into vectors, and the resulting contract vectors were sent to the input to the clustering algorithm. We used the K-means algorithm for clustering vectors. Since the similarity is usually measured using a cosine distance, we used it instead of the Euclidean distance.
After receiving 20 clusters of documents, it was necessary to check the quality of clustering. Since we do not have any classification of contracts, we cannot compare the obtained clusters with the existing splitting. Then we decided to look at the words that describe the cluster. For this, they took the “Subject of the contract” clauses for each cluster, deleted stop words, numbers and words that are found in most clusters. Then we selected the 5 most common words for each cluster as keywords. In this simple way, one can subjectively evaluate the quality of clustering.
Examples of words that described clusters:
- tenant, landlord, apartment, rental, builder
- competence, teaching, educational, academic, full-time
- general contractor, subcontractor, general construction, designer, town planning
- pharmacy, quarantine, expend, phytosanitary, hermetic
- detective, guard, suppression, alarm, offense
- licensee, sublicensee, film, licensor, rebroadcast
- borrower, escrow, lender, loan, mortgagor
- centralized, energy supplying, intra-zone, water supply, sewer
3. What anomalies can we encounter in contracts
Let's determine which cases we consider to be abnormal and what we can do with them. We have identified the following scenarios:
- An extra point has been added to the contract, which has never been found anywhere else in this context. It is necessary to pay attention to him a lawyer.
- There is no clause in the agreement that was previously encountered in such agreements. We must advise a lawyer to add it.
- An item is similar to an item in a story, but is somehow rephrased, some words are added or deleted. You can inform the lawyer and advise the edit.
4. In what form to submit contracts
As already mentioned, the contract consists of chapters, chapters are divided into clauses, each clause may contain sub-clauses, etc. To break the agreement into chapters and paragraphs, we took into account numbering, hyphenation, keywords: “Chapter,” “Article,” etc. Each item consists of one or more sentences. For splitting an item into sentences, used sent_tokenize from the nltk.tokenize module.
The contract itself contains several global chapters, the essence and content of which can be recognized by the headings: the subject of the contract, the rights and obligations of the parties, the price and the settlement procedure ... We tried to combine the chapters with the same headings and work with the various chapters independently. Chapter titles are often rephrased, have typos or extra punctuation. In order to make groups of chapters large enough, we combined into one group those headlines that were close in Levenshtein distance.
One of the problems that we can definitely face is a huge amount of named entities in contracts, which are often unique and can be mistaken for an anomaly. In contracts, there are many such entities as names, company names, dates, addresses, etc., which vary from contract to contract. It is necessary to find and eliminate such entities from the contract, i.e. to bring the contract to some kind of template. We were lucky with dataset, because in the unloading of contracts there was a large proportion of template contracts, the named entities in which were replaced with underscores. We found between what phrases underscores are usually found in order to find these phrases in the completed documents and remove named entities from them. It is clear that in this way we did not delete all the named entities. Therefore, we once again walked through the building of the Natasha library and deleted entities,
5. Definition of anomalous clauses in the contract
We were able to separate the contracts by type using clustering and were able to identify groups of similar chapters. Now, using the accumulated knowledge of a certain clause of a certain type of contract, we can understand what needs to be corrected in the current one. Let's calculate for each sentence of the chapter the probability of its anomaly.
For each group of chapters we keep all the offers that we met in our training set of documents from the State Procurement. Since there are quite a large number of them; for each group of chapters, the Word2Vec model was trained, and each sentence was assigned a vector of weighted (in tf-idf) sum of the vectors of its words. Next, the proposal vectors were divided into clusters in a similar way to the splitting of vectors for documents.
Now, when a proposal comes to us, we determine from which cluster of contracts it is, from which group of chapters, to which cluster of proposals it is closest, and in this cluster we find the nearest one. The distance to the nearest offer can be regarded as a measure of how abnormal the offer is. If the distance to the nearest offer is zero, then our offer is not abnormal. When increasing this distance, we are increasingly doubted that the proposal does not contain anomalies. Most likely something wrong with him.
6. What to do with items that are missing
We figured out how to find anomalous clauses in a contract, but did not learn to find anomalies in the form of missing sentences or clauses. Such an anomaly can be easily found if we have a template of this type of contract in our hands, but, for example, there are cases when another company sent us a contract drawn up according to its own template.
To detect such anomalies, we need to create a template for a contract with a set of mandatory offers / points, again based only on the existing base of contracts.
We invented and tested the template construction algorithm. This algorithm assumes that in our contract database there is a similar chapter with the correct set of items, which we want to identify and indicate as a template.
Algorithm:
- On each group of chapters in advance to train a model based on the MinHashLSH algorithm, which allows you to quickly find similar texts.
- For each chapter of the loaded contract find a list of paragraphs close to it from the base.
- Based on the obtained close paragraphs, construct a language model and select as the template paragraph with the highest probability predicted by the language model.
Having received a template for each chapter, we can identify the missing points that are present in the template, but not in the current contract, and advise a lawyer to add them.
7. Full Pipeline
Let's summarize and collect all the steps together:
I. Collection, processing and storage of the body of contracts
A. Собрать корпус типовых договоров.
B. Выполнить классификацию/кластеризацию договоров по типам.
C. Разбить договора на главы, пункты и предложения.
D. Удалить именованные сущности из договоров.
E. Сгруппировать главы по их заголовкам.
F. Для каждой группы глав обучить Word2Vec.
G. Сопоставить каждому предложению вектор взвешенной суммы векторов входящих в него слов.
H. Кластеризовать полученные вектора предложений и хранить каждый кластер отдельно для быстрого поиска ближайшего вектора в ближайшем кластере.
I. Для каждой группы глав обучить MinHashLSH.
B. Выполнить классификацию/кластеризацию договоров по типам.
C. Разбить договора на главы, пункты и предложения.
D. Удалить именованные сущности из договоров.
E. Сгруппировать главы по их заголовкам.
F. Для каждой группы глав обучить Word2Vec.
G. Сопоставить каждому предложению вектор взвешенной суммы векторов входящих в него слов.
H. Кластеризовать полученные вектора предложений и хранить каждый кластер отдельно для быстрого поиска ближайшего вектора в ближайшем кластере.
I. Для каждой группы глав обучить MinHashLSH.
II. Search for anomalies in the new document
A. Выделение аномальных пунктов
1. Определить тип договора (класс или кластер)
2. Разбить документ на главы, пункты и предложения
3. Для каждой главы найти соответствующую группу глав в базе
4. Сопоставить каждому предложению вектор
5. Найти для каждого предложения договора ближайший кластер предложений, а в нем ближайшее предложение
6. Рассчитать расстояния между векторами предложений и раскрасить предложения на основе полученных расстояний.
7. Раскрасить только части предложений, если с ближайшим они отличаются в нескольких словах.
8. Посоветовать правку в виде ближайшего предложения.
B. Поиск отсутствующих пунктов
1. Для каждой главы построить шаблон
2. Посоветовать добавить недостающие пункты из шаблона
1. Определить тип договора (класс или кластер)
2. Разбить документ на главы, пункты и предложения
3. Для каждой главы найти соответствующую группу глав в базе
4. Сопоставить каждому предложению вектор
5. Найти для каждого предложения договора ближайший кластер предложений, а в нем ближайшее предложение
6. Рассчитать расстояния между векторами предложений и раскрасить предложения на основе полученных расстояний.
7. Раскрасить только части предложений, если с ближайшим они отличаются в нескольких словах.
8. Посоветовать правку в виде ближайшего предложения.
B. Поиск отсутствующих пунктов
1. Для каждой главы построить шаблон
2. Посоветовать добавить недостающие пункты из шаблона
8. Quality assessment
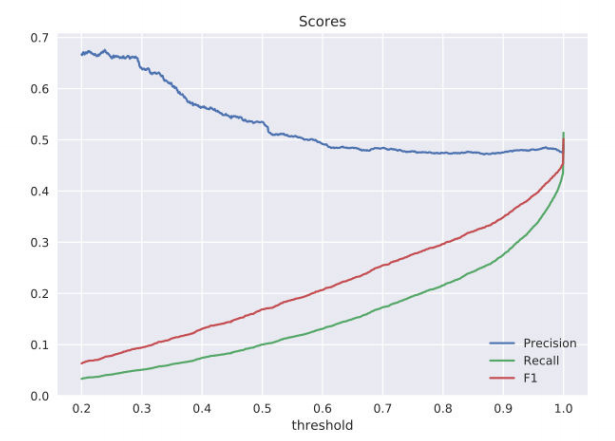
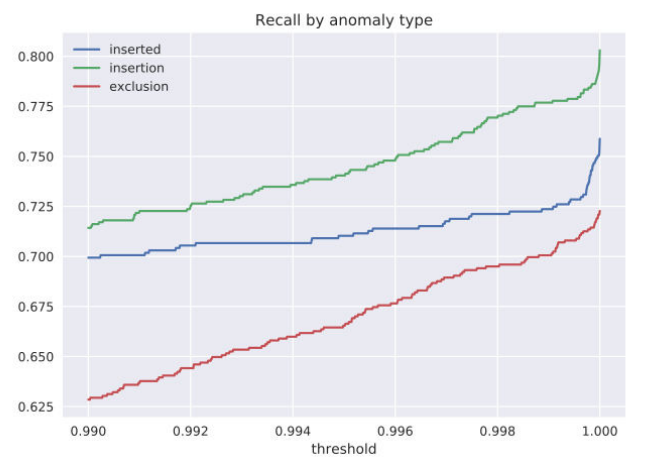
To assess the quality of the solutions to the problem, a test set of contracts was formed. Anomalies were artificially added to treaties in the form of deleting a part of words, inserting words / phrases into sentences, inserting sentences from other chapters, and deleting sentences. We evaluated the quality for each type of anomaly and obtained the following distributions of definition errors: That is, the proposed algorithm allows us to determine incorrect inclusions in 4 of 5 cases. It should be noted that with an increase in the size of the training sample and the clustering of contracts for different types, we can get an improvement to this estimate.
9. Visualization
To visualize such a solution of the problem, a web interface was implemented in which you can download a new contract, the text of which will be displayed on the page and the anomalous sentences will be highlighted in color. The darker the color of the sentence, the more we are sure that it is anomalous. Since we have found the nearest offer, we suggest editing for the user in the form of this nearest offer, or we advise you to change the specific part of the offer if the closest one has a slight difference with the original one.
10. Where applicable?
Practical application of the resulting service is most appropriate in cases where a “streaming” examination of the legal purity of a large number of similar documents is required: for example, when issuing mortgage loans to the public (mortgage, car loans and insurance). For example, in the case of a mortgage, these are real estate purchase and sale contracts, real estate and borrower insurance contracts, property valuation contracts, etc. - hundreds of pages of text in the file of each client, which can be analyzed almost instantly, and anomalous places will be “highlighted” to a lawyer for analysis on risks or fraud.
So, absolutely no lawyers from flesh and blood can not do, but modern technologies allow them to make life easier for them.
Material prepared by Elena Sannikova ( helen_sunny).