Doom 3 BFG Source Code Review: Multithreading (Part 2 of 4)
- Transfer
 Part 1: Introduction
Part 1: Introduction Part 2: Multithreading
Part 3: Rendering (Note transl. - during translation)
Part 4: Doom classic - integration (Note transl. - during translation)
The engine for Doom III was written between 2000 and 2004, at a time when most PCs were single-processor. Although the idTech4 engine architecture was designed with SMP support in mind, it ended up doing multithreading support at the last minute ( see interview with John Carmack ).
Since then, much has changed, there is a good article from Microsoft " Programming for multi-core systems ":
Over the years, processor performance has been steadily increasing, and games and other programs have benefited from this increase in power without the need for effort.
The rules have changed. The performance of single-core processors is currently growing very slowly, if at all. However, the computing power of personal computers and consoles continues to grow. The only difference is that basically such an increase is now obtained due to the presence of multi-core processors.
The increase in processor power is as impressive as before, but now developers must write multi-threaded code in order to fully unlock the potential of this power.
Target platforms and Doom III BFG are multi-core:
- The Xbox 360 has one Xenon tri-core processor. The simultaneous multi-threading platform is 6 logical cores.
- The PS3 has a main unit (PPE) based on a PowerPC processor and eight synergistic cores (SPEs).
- A PC often has a quad-core processor. With Hyper-Threading, this platform gets 8 logical cores.
As a result, idTech4 was reinforced not only with multithreading support, but also with idTech5's Job Processing System, which adds support for multi-core systems.
Note: not so long ago, the specifications of the Xbox One and PS4 were announced: both will have eight cores. Another reason for any game developer to be good at multithreaded programming.
Doom 3 BFG Thread Model
 On a PC, the game runs in three threads:
On a PC, the game runs in three threads:- Backend Interface Rendering Stream (Sending GPU Commands)
- Stream of game logic and frontend interface rendering
- Data input stream from high frequency joystick (250Hz)
In addition, idTech4 creates two more workflows. They are needed to help any of the three main streams. They are managed by the scheduler whenever possible.
main idea
Id Software unveiled its 2009 multi-core programming solution in a presentation on Beyond Programming Shaders . Two main ideas here:
- Separate task processing for processing by different threads ("jobs" by "workers")
- Avoid delegating synchronization to the operating system: do it yourself for atomic operations
System components
The system consists of 3 components:
- Tasks (Jobs)
- Workers
- Synchronization
Tasks are exactly what you would expect:
struct job_t {
void (* function )(void *); // Job instructions
void * data; // Job parameters
int executed; // Job end marker...Not used.
};
Note: According to the comments in the code, “the task must last at least a couple of 1000 cycles in order to outweigh the switching costs. On the other hand, the task should not last more than a few 100,000 cycles in order to maintain a good load balance between several processes.
A handler is a thread that will remain inactive while waiting for a signal. When it is activated it tries to find a task. Handlers try to avoid synchronization using atomic operations, trying to get the task from the general list.
Synchronization is carried out through three primitives: signals, mutexes and atomic operations. The latter are preferred because it allows the engine to maintain the focus of the CPU. Their implementation is described in detail at the bottom of this page .
Architecture
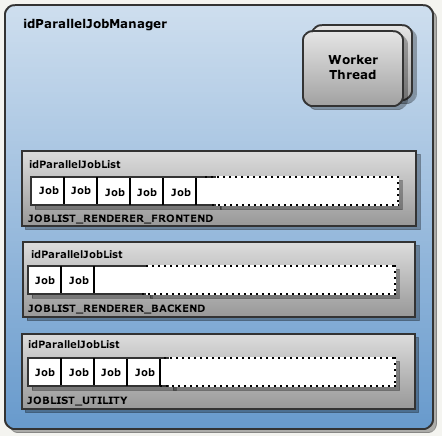 The brain of the subsystem is ParalleleJobManager. He is responsible for spawning thread handlers and creating queues in which tasks are stored.
The brain of the subsystem is ParalleleJobManager. He is responsible for spawning thread handlers and creating queues in which tasks are stored. And the first idea of bypassing synchronization: to divide the job lists into several sections, each of which is accessed by only one thread and, therefore, synchronization is not required. In the engine, such queues are called idParallelJobList.
There are only three sections in the Doom III BFG:
- Render frontend-a
- Render backend-a
- Utilities
On a PC, two workflows are created at startup, but probably more are created on the XBox360 and PS3.
According to the 2009 presentation, more sections were added to idTech5:
- Defect detection
- Animation processing
- Obstacle avoidance
- Texture processing
- Particle transparency processing
- Tissue simulation
- Water surface simulation
- Detailed model generation
Note: The presentation also mentions the concept of a one-frame delay, but this part of the code does not apply to Doom III BFG.
Task distribution
 Running handlers are constantly waiting for a job. This process does not require the use of mutexes or monitors: atomic increment distributes tasks without overlapping.
Running handlers are constantly waiting for a job. This process does not require the use of mutexes or monitors: atomic increment distributes tasks without overlapping.Using
Since tasks are divided into sections accessible only to one thread, synchronization is not necessary. However, providing tasks to the system handler does imply a mutex:
//tr.frontEndJobList is a idParallelJobList object.
for ( viewLight_t * vLight = tr.viewDef->viewLights; vLight != NULL; vLight = vLight->next ) {
tr.frontEndJobList->AddJob( (jobRun_t)R_AddSingleLight, vLight );
}
tr.frontEndJobList->Submit();
tr.frontEndJobList->Wait();
Methods:
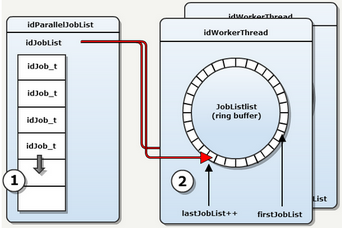
- Adding a task : there is no need for synchronization, tasks are added to the queue
- Dispatch : mutex synchronization, each handler replenishes the general JobLists from its local JobLists.
- Synchronization signal (OS delegation) :
How the handler is executed
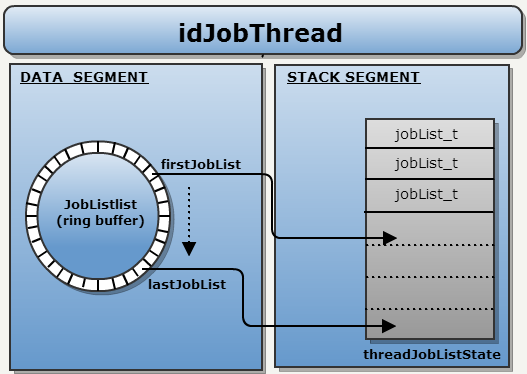
Handlers are executed in an infinite loop. In each iteration, a ring buffer is checked, and if the task is found, it is copied by reference to the local stack.
Local Stack: A thread stack is used to store JobLists addresses to prevent the mechanism from stopping. If the thread cannot “block” the JobList, it falls into RUN_STALLED mode. This stop can be canceled by moving the stack from the local JobLists to the general list.
The interesting thing is that everything will be done without any mutual mechanisms: only atomic operations.
Endless cycle
int idJobThread::Run() {
threadJobListState_t threadJobListState[MAX_JOBLISTS];
while ( !IsTerminating() ) {
int currentJobList = 0;
// fetch any new job lists and add them to the local list in threadJobListState
{}
if ( lastStalledJobList < 0 )
// find the job list with the highest priority
else
// try to hide the stall with a job from a list that has equal or higher priority
currentJobList = X;
// try running one or more jobs from the current job list
int result = threadJobListState[currentJobList].jobList->RunJobs( threadNum, threadJobListState[currentJobList], singleJob );
// Analyze how job running went
if ( ( result & idParallelJobList_Threads::RUN_DONE ) != 0 ) {
// done with this job list so remove it from the local list (threadJobListState[currentJobList])
} else if ( ( result & idParallelJobList_Threads::RUN_STALLED ) != 0 ) {
lastStalledJobList = currentJobList;
} else {
lastStalledJobList = -1;
}
}
}
Job launch
int idParallelJobList::RunJobs( unsigned int threadNum, threadJobListState_t & state, bool singleJob ) {
// try to lock to fetch a new job
if ( fetchLock.Increment() == 1 ) {
// grab a new job
state.nextJobIndex = currentJob.Increment() - 1;
// release the fetch lock
fetchLock.Decrement();
} else {
// release the fetch lock
fetchLock.Decrement();
// another thread is fetching right now so consider stalled
return ( result | RUN_STALLED );
}
// Run job
jobList[state.nextJobIndex].function( jobList[state.nextJobIndex].data );
// if at the end of the job list we're done
if ( state.nextJobIndex >= jobList.Num() ) {
return ( result | RUN_DONE );
}
return ( result | RUN_PROGRESS );
}
Id Software Sync Tools
Id Software uses three types of synchronization mechanisms:
1. Monitors (idSysSignal):
| Abstraction | Operation | Implementation | Note |
| idSysSignal | Event objects | ||
| Raise | SetEvent | Sets the specified event of the object to a signal state. | |
| Clear | ResetEvent | Sets the specified event of the object to a non-signal state. | |
| Wait | WaitForSingleObject | Waits until the specified object is in a signal state or until the timeout has expired. |
2. Mutexes (idSysMutex):
| Abstraction | Operation | Implementation | Note |
| idSysMutex | Critical section objects | ||
| Lock | EnterCriticalSection | Waits for the specified critical section object to be received. The function returns when the calling thread has acquired the property. | |
| Unlock | LeaveCriticalSection | Implements the receipt of the specified object of the critical section. | |
3. Atomic operations (idSysInterlockedInteger):
| Abstraction | Operation | Implementation | Note |
| idSysInterlockedInteger | Interlocked variables | ||
| Increasement | InterlockedIncrementAcquire | Incrementing the value of a given 32-bit variable as an atomic operation. The operation has semantics of “acquire”. | |
| Decrement | InterlockedDecrementRelease | Decrement the value of a given 32-bit variable as an atomic operation. The operation has the semantics of “release”. |