ClassicAI genre: ML is looking for himself in poetry
 Now in the press often there are news like "AI learned to write in the style of the author X", or "ML creates art." Looking at this, we decided - it would be great if these loud statements could be tested in practice.
Now in the press often there are news like "AI learned to write in the style of the author X", or "ML creates art." Looking at this, we decided - it would be great if these loud statements could be tested in practice. Is it possible to arrange a bots fighting for writing poems? Is it possible to make a clear and repeatable competitive story out of this? Now you can say for sure that this is possible. And how to write your first algorithm for generating poems, read on.
Article layout
1. ClassicAI
The task of the participants
Under the terms of the competition, participants need to build a model that generates poems on a given topic in the style of one of the Russian classics. The theme and the author are served on the entry models, and a poem is expected at the exit. A full description is in the repository of the competition.
Subject conditions are mild: it can be a short sentence, a phrase or a few words. The only limitation is on the size: not more than 1000 characters. The topics on which algorithms will be tested will be compiled by experts. Some of the topics will be open and publicly available, but a hidden set of topics will be used to determine the best algorithm.
The global idea of the competition is this: for any poem, you can make a brief summary of several words. Let's show by example.
If you take an excerpt from"Eugene Onegin" A.S. Pushkin :
“... That year the autumn weatherThen briefly, the contents of it can fit in "Tatiana sees the first snow in the window." And then the ideal model of the poem for this input will give something very close to the original.
Was long in the yard,
Winter was waiting, nature was waiting.
Snow fell only in January
On the third in the night. Waking up early,
Tatiana saw the window.
In the morning the yard
became white, Curtains, roofs and a fence,
Light patterns on the glass,
Trees in winter silver,
Forty merry in the yard
And the softly lined mountains of
Winter with a brilliant carpet.
Everything is bright, everything is white all around ... ”1823–1830
For training in this competition, a dataset from more than 3000 works of five famous Russian poets is proposed :
1. Pushkin
2. Yesenin
3. Mayakovsky
4. Block
5. Tyutchev
The algorithm must be written so that it generates quickly enough and has the necessary interface. The speed can be equal to the power of medium modern PCs. The interface and limitations are described in detail in the "Decision Format" section.
In order to be able to track the progress of their decisions, as well as to compare them with other decisions of the participants, the markup of solutions through the chat bot will be held throughout the competition. The results of the algorithms will be evaluated according to two criteria:
- The quality of versification and compliance with the style of a given classical poet
- Completeness of the disclosure of a given topic in a poem
For each criterion, a 5-point scale will be provided. The algorithm will have to write poems for each topic from the test set. The topics on which algorithms will be tested will be compiled by experts. Some of the topics will be open and publicly available, but a hidden set of topics will be used to identify the best algorithm.
The resulting poem can be rejected for the following reasons:
- generated text is not a poem in Russian
- generated text contains obscene language
- generated text contains intentionally offensive phrases or subtext
Competition program
Unlike many, in this competition there is only one online stage: from 30.07 to 26.08.
During this period, you can send solutions daily with the following restrictions:
- no more than 200 decisions during the competition
- no more than 2 successful decisions per day
- do not take into account the daily limit of the decision, the check of which ended with an error
The prize fund corresponds to the complexity of the task: the first three places will receive 1,000,000 rubles!
2. Approaches to the creation of generators of poetry
As it became clear, the task is not trivial, but not new. Let's try to figure out how the researchers approached this problem earlier? Let's look at the most interesting approaches to the creation of generators of poems of the past 30 years.
1989
В журнале Scientific American N08, 1989 выходит статья А.К. Дьюдни “Компьютер пробует свои силы в прозе и поэзии”. Не будем пересказывать статью, здесь есть ссылка на полный текст, хотим лишь обратить ваше внимание на описание POETRY GENERATOR от Розмари Уэст.
Этот генератор был полностью автоматизированным. В основе этого подхода большой словарь, фразы из которого выбираются случайным образом, и из них формируются словосочетания по набору грамматических правил. Каждая строка делится на части предложения, а далее случайно заменяется другими словами.
Этот генератор был полностью автоматизированным. В основе этого подхода большой словарь, фразы из которого выбираются случайным образом, и из них формируются словосочетания по набору грамматических правил. Каждая строка делится на части предложения, а далее случайно заменяется другими словами.
1996
Более 20 лет назад выпускник известного московского вуза защитил диплом на тему «Лингвистическое моделирование и искусственный интеллект»: автор — Леонид Каганов. Вот ссылка на полный текст.
К 1996 году уже были написаны такие генераторы как:
В качестве основных преимуществ можно выделить то, что программа:
Алгоритм и код можно почитать здесь.
«Лингвистическое моделирование и искусственный интеллект» — так звучит
название моей темы. «Программа, которая сочиняет стихи» — так отвечаю я на
вопросы друзей. «Но ведь подобные программы уже есть?» — говорят мне. «Да — отвечаю я, — но моя отличается тем, что не использует изначальных шаблонов.»
(с) Каганов Л.А.
К 1996 году уже были написаны такие генераторы как:
- BRED.COM, создающий псевдонаучную фразу
- TREPLO.EXE, порождающий забавный литературный текст
- POET.EXE, сочиняющий стихи с заданным ритмом
- DUEL.EXE
«Например, в POET.EXE имеется словарь слов с проставленными ударениями и некоторой другой информацией о них, а также задается ритм и указывается какие строки рифмовать (например, 1 и 4). А все эти программы обладают одним общим свойством — они используют шаблоны и заранее подготовленные словари.»
В качестве основных преимуществ можно выделить то, что программа:
- использует ассоциативный опыт
- производит рифмовку самостоятельно
- имеет возможность тематического сочинения
- позволяет задавать любой ритм стиха
Алгоритм и код можно почитать здесь.
2016
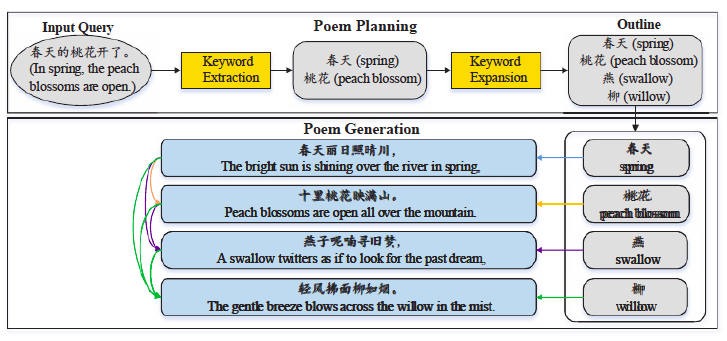
Ученые из Китая генерируют стихотворения на своем языке. У них есть живой репозиторий проекта, который может быть полезен в текущем соревновании.
Если очень коротко, то это работает так (ссылка на источник картинки):
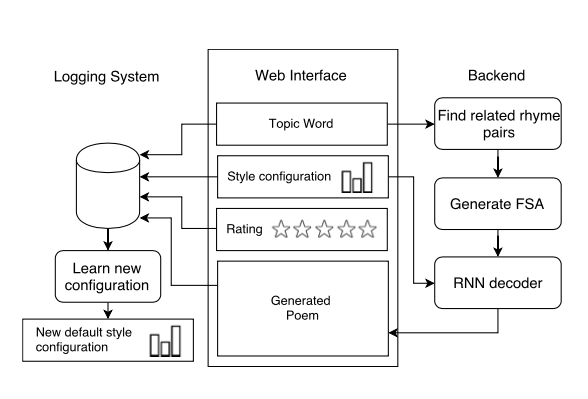
Также в 2016 еще одна группа представила свою разработку Hafez (репозиторий тут).
Этот генератор “сочиняет” стихи на заданную тему, используя:
Их алгоритм (ссылка на источник картинки):
Они обучили алгоритм не только на английском, но и на испанском. Обещают, что все должно работать почти везде. Заявление довольно громкое, так что рекомендуем относиться с осторожностью.
«Chinese Poetry Generation with Planning based Neural Network»
Ученые из Китая генерируют стихотворения на своем языке. У них есть живой репозиторий проекта, который может быть полезен в текущем соревновании.
Если очень коротко, то это работает так (ссылка на источник картинки):
Generating Topical Poetry
Также в 2016 еще одна группа представила свою разработку Hafez (репозиторий тут).
Этот генератор “сочиняет” стихи на заданную тему, используя:
- Словарь с учетом ударений
- Слова по теме
- Рифмующиеся слова из набора слов по теме
- Finite-state acceptor (FSA)
- Выбор лучшего пути через FSA, используя RNN
Их алгоритм (ссылка на источник картинки):
Они обучили алгоритм не только на английском, но и на испанском. Обещают, что все должно работать почти везде. Заявление довольно громкое, так что рекомендуем относиться с осторожностью.
2017
Напоследок хочется упомянуть об очень подробной статье на Хабре «Как научить свою нейросеть генерировать стихи». Если вы никогда не занимались подобными моделями, то вам сюда. Там про генератор стихов на нейроночках: про языковые модели, N-граммные языковые модели, про оценку языковых моделей, про то как запилить архитектуру и доработать входной и выходной слой.
Например, вот так слову добавляется морфологическая разметка (ссылка на источник картинки):

Та статья была написана совместно с Ильей Гусевым, у которого есть библиотека для анализа и генерации стихов на русском языке и поэтический корпус русского языка.
Например, вот так слову добавляется морфологическая разметка (ссылка на источник картинки):
Та статья была написана совместно с Ильей Гусевым, у которого есть библиотека для анализа и генерации стихов на русском языке и поэтический корпус русского языка.
3. Programming an artificial poet
An example of a simple poetic generator
Competition on the one hand may seem rather difficult, but for him it is quite possible to make a simple, but working baseline .
According to the condition, the author's identifier (author_id) and the text of the topic (seed) arrive at the input of this program, in response to this the model should return the poem.
Let's try to formalize the theme so that you can safely operate with it within a certain vector semantic space. The easiest way out of this is to get the semantic vector of each word (for example, Word2Vec) and then average them.
Thus, we get a kind of “seed2vec”, which allows us to translate the theme into a vector.
In fact, this opens a wide topic for research, because The task of highlighting a topic has been for scientists a long time ago, here are just a few examples:
- Selecting topics through LDA
- lda2vec
- sent2vec
- WMD
Now, you need to figure out how to use author_id to generate a poem in the style of this author.
Here, the idea is no less simple: let's take the author's random poem from the corpus of verses, after which we will replace each word with another, which is most consonant with the original (it has the same number of syllables, the same stress and the last three letters are most similar to the original by Levenshtein's distance) and it has the most similar vector with the theme vector. For example, for the “Football” theme and the “And glowed like amber” line, the output line could be “A was played as a goalkeeper”. Thus, we get a kind of stylization of the text.
As a base for replacement words, dataset was used, which contains small paragraphs of Wikipedia texts (a description of its use can be found in the baseline code on GitHub).
After such processing, there will be texts that will outwardly resemble the verses of the author, but at the same time contain some topic that the author did not lay.
Baseline work result:
Theme: Physics
Stylistics: The unit
will bring and bismuth units of the
buffalo of ancient nonlinear environments
I am on a Kelvin board on a particle of
my own phenomena my own scientific
faraday seville cradling
my Tver now invented the
environment phonon facet
positron ghost smoke
Topic: Mathematics
Stylistics: Block
as a leibniz circle among ideas
to learn curves and school,
but a flock of herds to study learn a
curve for examples children's brain
curves are taken a swimmer knows from a goba
and goes to the senate and goes to court in the senate
than the daughter is more ancient than goba
and surya
swimmer endangered the whole shadow learns over the Euclidean
title is published and it
masters the quotas by fastening the
joke to the professor with work
Obviously, baseline is not perfect, that's why it is baseline.
You can easily add a few features to help improve the generation and raise you in the top:
- It is necessary to remove repeated words, because rhyming a word to itself is not healthy for a good poet.
- Now the words are not consistent with each other, because we do not use information about parts of speech and cases of words
- You can use a richer corpus of words, such as a wikipedia dump.
- The use of other embendings can also improve, for example, FastText works not at the word level, but at the n-gram level, which allows it to do embeddings for unknown words.
- Use IDF as a weight when weighing words to calculate the theme vector.
Here you can add many more points, at your discretion.
Preparing the solution for shipment
After the model is trained, it is necessary to send the algorithm code packed in a ZIP archive to the testing system.
Solutions run in an isolated environment with Docker, time and resources for testing are limited. The solution must meet the following technical requirements:
It must be implemented as an HTTP server available on port 8000, which responds to two types of requests:
GET /readyThe request must be answered with the code 200 OK in case the solution is ready to work. Any other code means the solution is not ready yet. The algorithm has a limited time for preparation for work, during which you can read data from a disk, create the necessary data structures in RAM.
POST /generate/<poet_id>Request for poem generation. The ID of the poet, in the style of which you want to write, is listed in the URL. Request content - JSON with a single seed field containing the subject line:
{"seed": "регрессия глубокими нейронными сетями"}In response, it is necessary to provide JSON with the generated composition in the poem field in the allotted time:
{"poem": "Ведь были сети боевые\nДа говорят еще какие\n..."}The request and response must have Content-Type: application / json. It is recommended to use UTF-8 encoding.
The solution container is launched under the following conditions:
— решению доступны ресурсы:
— 16 Гб оперативной памяти
— 4 vCPU
— GPU Nvidia K80
— решение не имеет доступа к ресурсам интернета
— решению в каталоге /data/ доступны общие наборы данных
— время на подготовку к работе: 120 секунд (после чего на запрос /ready необходимо отвечать кодом 200)
— время на один запрос /generate/: 5 секунд
— решение должно принимать HTTP запросы с внешних машин (не только localhost/127.0.0.1)
— при тестировании запросы производятся последовательно (не более 1 запроса одновременно)
— максимальный размер упакованного и распакованного архива с решением: 10 Гб
Сгенерированное стихотворение (poem) должно удовлетворять формату:
— размер стиха — от 3 до 8 строк
— каждая строка содержит не более 120 символов
— строки разделяются символом \n
— пустые строки игнорируются
Тема сочинения (seed) по длине не превышает 1000 символов.
При тестировании используются стили только 5 перечисленных выше избранных поэтов.
— 16 Гб оперативной памяти
— 4 vCPU
— GPU Nvidia K80
— решение не имеет доступа к ресурсам интернета
— решению в каталоге /data/ доступны общие наборы данных
— время на подготовку к работе: 120 секунд (после чего на запрос /ready необходимо отвечать кодом 200)
— время на один запрос /generate/: 5 секунд
— решение должно принимать HTTP запросы с внешних машин (не только localhost/127.0.0.1)
— при тестировании запросы производятся последовательно (не более 1 запроса одновременно)
— максимальный размер упакованного и распакованного архива с решением: 10 Гб
Сгенерированное стихотворение (poem) должно удовлетворять формату:
— размер стиха — от 3 до 8 строк
— каждая строка содержит не более 120 символов
— строки разделяются символом \n
— пустые строки игнорируются
Тема сочинения (seed) по длине не превышает 1000 символов.
При тестировании используются стили только 5 перечисленных выше избранных поэтов.
Detailed information on sending the solution to the system with analysis of the most frequent errors is available here .
4. Hackathon platform
The platform with all the necessary information on this contest is on classic.sberbank.ai . Detailed rules can be found here . At the forum you can get an answer both on the task and on technical issues, if something goes wrong.

Creative competitions ML models are not easy. Many have come up to the task of generating poetry, but there is still no significant breakthrough. Already, on our classic.sberbank.ai platform, participants from all over Russia are competing to solve this complex task. We hope that the decisions of the winners will surpass all the decisions created earlier!
5. References
useful links
Платформа хакатона Классик AI
В Мире Науки — Компьютер пробует свои силы в прозе и поэзии
Hafez — Poetry Generation
Каганов Л.А. «Лингвистическое конструирование в системах искусственного интеллекта»
N+1 «Искусственный Пушкин»
Generating Poetry with PoetRNN
Подросток написал искусственный интеллект, который пишет стихи
«Стихи» искусственного интеллекта Google попали в сеть
Кибер-поэзия и кибер-проза: совсем чуть-чуть искусственного интеллекта
В Мире Науки — Компьютер пробует свои силы в прозе и поэзии
Hafez — Poetry Generation
Каганов Л.А. «Лингвистическое конструирование в системах искусственного интеллекта»
N+1 «Искусственный Пушкин»
Generating Poetry with PoetRNN
Подросток написал искусственный интеллект, который пишет стихи
«Стихи» искусственного интеллекта Google попали в сеть
Кибер-поэзия и кибер-проза: совсем чуть-чуть искусственного интеллекта