Pure pragmatic architecture. Brainstorm
Did you get the idea to rewrite your fat enterprise application from scratch? If from scratch, then it's woo hoo. At least the code will be two times less, right? But a couple of years will pass, and it will also grow, it will become a legacy ... there is not much time and money for rewriting to make it perfect.
Calm down, the authorities still will not give anything to rewrite. It remains to refactor. What is the best way to spend your small resources? How exactly to refactor, where to clean?
The title of this article - including a reference to Uncle Bob ’s Pure Architecture , was made based on the remarkable Victor Rentea report ( twitter , website) at the JPoint (under the cut, he will speak from the first person, but for now, finish reading the introductory one). Reading smart books is not a substitute for this article, but it’s written very well for such a short description.
The idea is that popular things like “Clean Architecture” are really useful. Surprise. If you need to solve a very specific problem, a simple elegant code does not require super efforts and over-engineering. Pure architecture says that you need to protect your domain model from external effects, and tells you exactly how to do this. An evolutionary approach to increasing the volume of microservices. Tests that make refactoring less scary. You know all this already? Or you know, but you are afraid to even think about it, because this is a horror then what will you have to do?
Who wants to get a magic anti-procrastination pill that will help to stop shaking and start refactoring - welcome to the video report or under the cat.
My name is Victor, I'm from Romania. Formally, I am a consultant, technical leader and leading architect at IBM in Romania. But if I were asked to define my activities myself, then I am a clean code evangelist. I love to create a beautiful, clean, supported code - as a rule, I tell about it on reports. Even more, I am inspired by teaching: training for developers in the areas of Java EE, Spring, Dojo, Test Driven Development, Java Performance, as well as in the field of evangelism mentioned above - the principles of cleanliness of code patterns and their development.
The experience on which my theory is based is mainly the development of enterprise applications for the largest IBM client in Romania, the banking sector.
The plan for this article is:
But first, let's remember those main principles that we, as developers, should always remember.

In other words, quantity vs quality. As a rule, the more functionality your class contains, the worse it is in quality terms. When developing large classes, the programmer gets confused, makes mistakes in building dependencies, and large code, among other things, is harder to debug. It is better to break such a class into several smaller ones, each of which will be responsible for a certain subtask. Let it be better you have several strongly connected modules, than one - large and clumsy. Modularity also makes it possible to reuse logic.

The degree of binding is a characteristic of how closely your modules interact with each other. It shows how widely the effect of the changes you make at any one point in the system can spread. The higher the binding, the more difficult it is to implement modifications: you change something in one module, and the effect spreads far and not always in the expected way. Therefore, the binding rate should be as low as possible - this will give you greater control over the system undergoing modifications.

Your own implementations may be good today, but not so good tomorrow. Do not allow yourself to copy your own work and thus distribute them on the code base. You can copy from StackOverflow, from books - from any reputable sources that (as you know for sure) offer an ideal (or close to that) implementation. It is very tiring to modify your own implementation, which occurs not only once, but multiplied throughout the code base.

In my opinion, this is the main principle that must be followed in engineering and software development. “Premature encapsulation is the root of evil,” said Adam Bien. In other words, the root of evil is "re-engineering." The author of the quote, Adam Bien, was at one time engaged in taking legacy applications and, completely rewriting their code, received a code base 2-3 times smaller than the original one. Where does so much extra code come from? After all, it does not just happen. It is generated by the fears we experience. It seems to us that, piling up patterns in a large number, producing indirectness and abstraction, we provide our code with protection — protection from the unknowns of tomorrow and tomorrow's requirements. After all, in actual fact, today we do not need any of this, we invent all this just for the sake of some “future needs”. And it is possible that these data structures will subsequently interfere. Frankly, when some developer comes up to me and voices that he came up with something interesting that you can add to the production code, I always answer the same way: “Boy, this will not be useful for you.”
There should not be a lot of code, but the one that is should be simple - only in this way can it work normally. This is a concern for your developers. You have to remember that they are the key figures for your system. Try to reduce their energy costs, reduce the risks with which they will have to work. This does not mean that you will have to create your own framework, moreover, I would not advise you to do this: there will always be bugs in your framework, everyone will need to learn it, etc. It is better to use existing funds, of which there is a mass today. These should be simple solutions. Register global error handlers, apply aspect technology, code generators, Spring extensions or CDI, configure Request / Thread scopes, use bytecode and manipulation on the fly, etc.
In particular, I would like to show you the use of Request / Thread areas. I have often observed how this thing simplified corporate applications in an incredible way. The bottom line is that it gives you the opportunity, being logged in by the user, to store RequestContext data. Thus, RequestContext will store user data in a compact form.

As you can see, the implementation takes only a couple of lines of code. By writing the request to the desired annotation (it is easy to do if you use Spring or CDI), you will forever free yourself from having to pass a user login to the methods and whatever else: the metadata stored in the context will move the application transparently. Scoped proxy allows you to access the metadata of the current request at any time.

Developers are afraid of the requirements being updated because they are afraid of the refactoring procedure (code modification). And the easiest way to help them is to create a reliable set of tests for regression testing. With it, the developer will be able to test his work at any time - to make sure that it does not break the system.
The developer should not be afraid to break anything. You must do everything so that refactoring is perceived as something good.
Refactoring is a crucial aspect of development. Remember, exactly at the moment when your developers are afraid of refactoring, the application can be considered to have passed into the category of "Legacy."
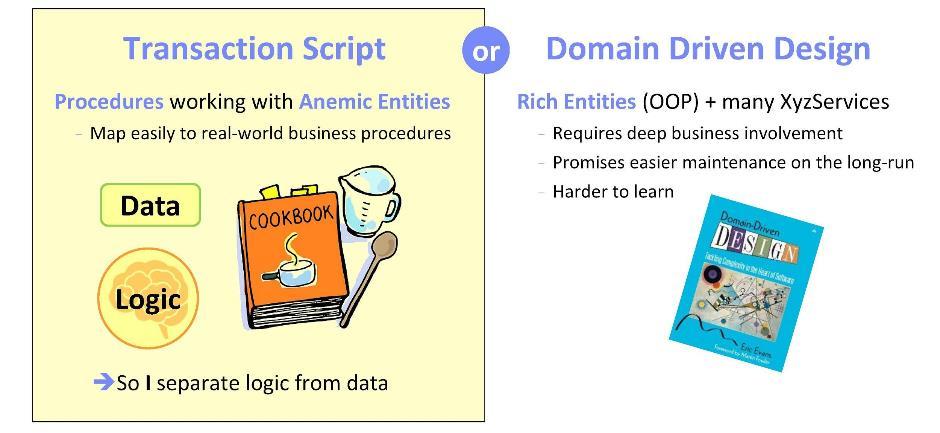
Starting the implementation of any system (or system components), we ask ourselves the question: where is it better to implement the domain logic, that is, the functional aspects of our application? There are two opposite approaches.
The first one is based on the philosophy of Transaction Script . Here, logic is implemented in procedures that work with anemic entities (that is, with data structures). Such an approach is good because in the course of its implementation it is possible to rely on formulated business objectives. While working on applications for the banking sector, I have repeatedly observed the transfer of business procedures to software. I can say that it is really very natural to correlate scripts with software.
An alternative approach is to use Domain-Driven Design principles.. Here, you will need to relate the specifications and requirements with the object-oriented methodology. It is important to think carefully over the objects, and to ensure good business involvement. The advantage of the systems so designed is that they are easily maintained in the future. However, in my experience, it is rather difficult to master this methodology: you feel more or less brave no sooner than after six months of studying it.
For my development, I always chose the first approach. I can assure you that in my case it worked perfectly.
How do we simulate data? As soon as the application accepts more or less decent sizes, persistent data is sure to appear . This is the data that you need to keep longer than others - they are the domain entities (domain entities) of your system. Where to store them — whether in a database, in a file, or directly managing memory — does not matter. What matters is how you will store them — in which data structures.

As a developer, this choice is given to you, and it only depends on you whether these data structures will work for you or against you in the implementation of functional requirements in the future. For everything to be fine, you must implement the entities, laying in them the nuggets of reused domain logic.. How exactly? I will demonstrate several ways by example.

Let's see what I have provided with the Customer entity. First, I implemented a synthetic getter
Perhaps you are using some kind of ORM like Hibernate. Suppose you have two entities with two-way communication. Initialization must be performed on both sides, otherwise, as you understand, you will encounter problems when accessing this data in the future. But developers often forget to initialize an object from one of the parties. You, developing these entities, can provide special methods that will guarantee two-way initialization. Look at

As you can see, this is a completely ordinary entity. But inside it laid the domain logic. Such entities should not be scanty and superficial, but they should not be overflowed with logic. Logic overflow occurs more often: if you decide to implement all the logic in the domain, then for each use-case there will be a temptation to implement some specific method. And use-cases, as a rule, are many. You will not get an entity, but one big pile of all sorts of logic. Try to observe a measure here: only reusable logic is placed in the domain and only in a small amount.
In addition to the entities you'll likely also need the value objects (object values). This is nothing more than a way to group the domain data in order to move it along the system together.
The value object must be:

And if you add a method call to the constructor
Value objects differ from entities in that they do not have a permanent ID. In entities there will always be fields associated with the foreign key of some table (or other storage). Object values do not have such fields. The question arises: do the procedures for checking for equality of two value objects and two entities differ? Since value objects have no ID field in order to conclude that two such objects are equal, it is necessary to compare the values of all their fields in pairs (that is, to inspect the entire contents). When comparing entities, it suffices to conduct a single comparison — across the ID field. It is in the comparison procedure that the main difference between entities and value objects lies.

What is the interaction with the user interface (UI)? You must give him the data to display . Will another structure be needed? And there is. That's because the user interface is not your friend. He has his own requests: he needs the data to be stored in accordance with how they should be displayed. This is so wonderful - what exactly user interfaces and their developers require from us. Then they need to get data for five lines; then it occurs to them to create a boolean field for an object
The question is, is it possible to trust our entities with them? Most likely, they will change them, and in the most undesirable way for us. Therefore, we will provide them with something else - Data Transfer Objects (DTO). They will be adapted specifically for external requirements and for logic that is different from ours. Some examples of the DTO structures are: Form / Request (come from the UI), View / Response (sent to the UI), SearchCriteria / SearchResult, etc. You can in a sense call this an API model.
The first important principle: DTO must contain a minimum of logic.
Here is an example implementation
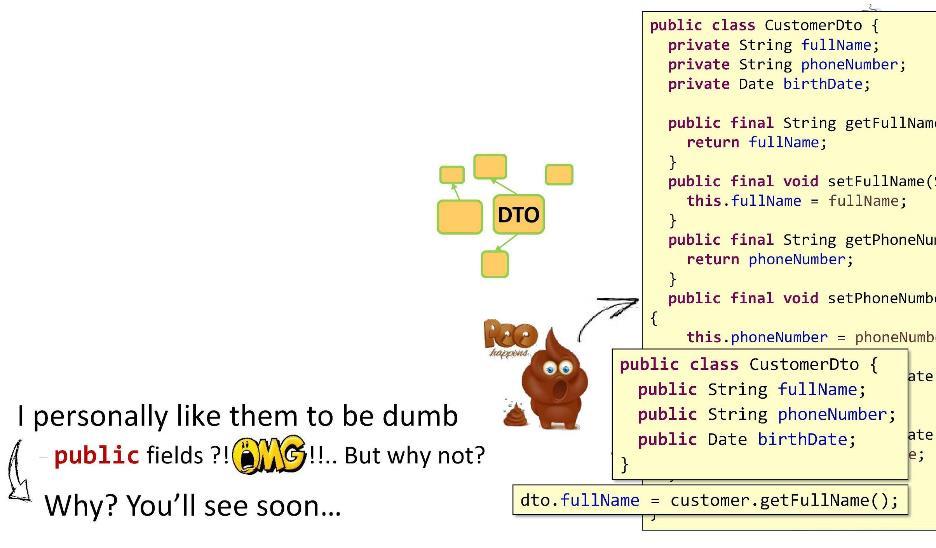
Content: private , public-getters and setters for them. It seems to be all super. OOP in all its glory. But one thing is bad: in the form of getters and setters, I implemented too many methods. In DTO, the logic should be as small as possible. And then what is my way out? I make the fields public! You will say that it does not work well with method references from Java 8, that restrictions will arise, etc. But believe it or not, I did all my projects (10-11 pieces) with such DTOs. Brother is alive. Now, since my fields are public, I have the opportunity to easily assign a value
So, we have a task: we need to transform our entities into a DTO. We implement the transformation as follows:
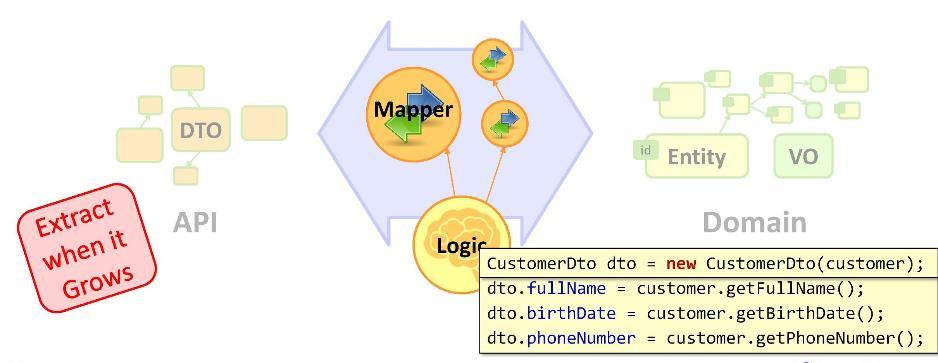
As you can see, by declaring a DTO, we proceed to mapping operations (assignment of values). Do I need to be a senior developer to write ordinary assignments in such a quantity? For some, it is so unusual that they begin to change their shoes on the go: for example, to copy data using some kind of mapping framework using reflex. But they miss the main point - that sooner or later the UI will interact with the DTO, as a result of which the entity and the DTO will diverge in their meanings.
We could, for example, put mapping operations in a constructor. But this is not possible for any mapping; in particular, the designer cannot access the database.
Thus, we have to leave the mapping operations in the business logic. And if they have a compact look, then there is nothing wrong with that. If the mapping does not take a couple of lines, but more, then it is better to put it in the so-called mapper . Mapper is a class specifically designed for copying data. This is, in general, antediluvian thing and a boilerplate. But behind them, you can hide our numerous assignments - to make the code cleaner and slimmer.
Remember: the code that has grown too much, you need to make a separate structure . In our case, the mapping operations were really a bit much, so we carried them into a separate class - to the mapper.
Do mappers allow database access? You can allow it by default - this is often done for reasons of simplicity and pragmatics. But it puts you at some risk.
I will illustrate with an example. Create an entity based on the existing DTO
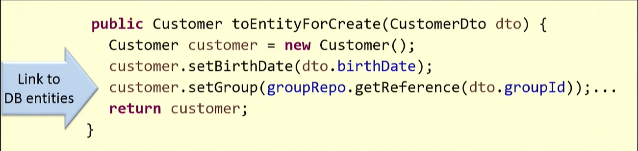
For mapping, we need to get a link to the customer group from the database. So I run the method
But trouble awaits us not here, but in the method that performs the inverse operation — transformation of the entity into DTO.

With the help of a cycle, we go through all the addresses associated with the existing Customer, and convert them into DTO addresses. If you use ORM, then, probably, a
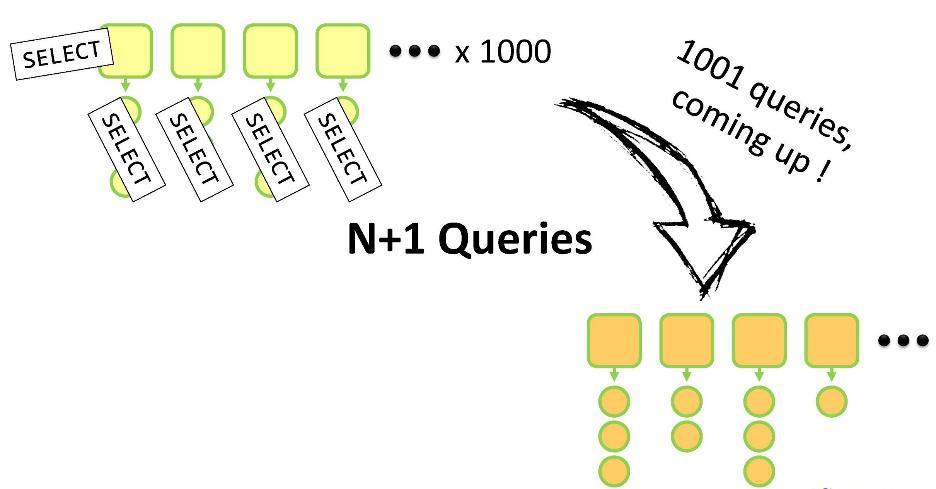
You have a set of parents, each of whom has children. For all this, you need to create your own analogs inside the DTO. You will need to perform one
Suppose, nevertheless, our method
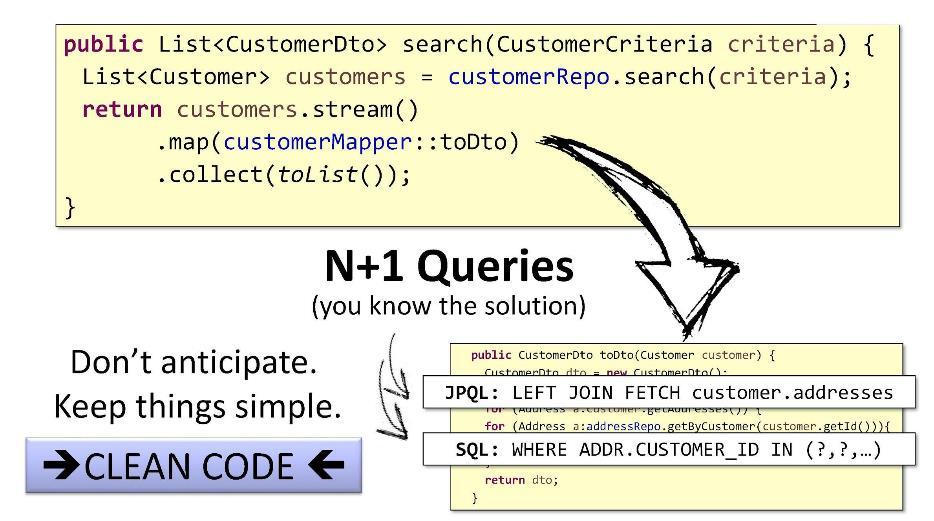
The problem with N + 1 queries has simple sample solutions: in JPQL, you can use
But I would have done differently. You can find out what is the maximum length of the list of children (this can be done, for example, on the basis of a search with pagination). If there are only 15 entities in the list, then we need only 16 requests. Instead of 5ms, we will spend on everything, say, 15ms - the user will not notice the difference.
I would not advise you to look at the performance of the system at the initial stage of development. As Donald Knud said: "Premature optimization is the root of evil." You can not optimize from the beginning. This is exactly what needs to be left for later. And what is especially important: no assumptions - only measurements and measurement of measurements!
Are you sure that you are competent, that you are a real expert? Be modest in assessing yourself. Do not think that you understood the work of the JVM until you read at least a couple of books about JIT compilation. It happens that the best programmers from our team come up to me and say that, as it seems to them , they have found a more efficient implementation. It turns out that they again invented something that only complicates the code. Therefore, I answer time after time: YAGNI. We do not need it.
Often for corporate applications no optimization of algorithms is required at all. The bottleneck for them, as a rule, is not a compilation, and not what concerns the operation of the processor, but various input-output operations. For example, reading a million lines from a database, volume records to a file, interaction with sockets.
Over time, you begin to understand what bottlenecks the system contains, and, having backed up all the measurements, you will begin to gradually optimize. Until then, keep the code as clean as possible. You will find that such code is much easier to further optimize.
Let's return to our DTO. Suppose we have defined such a DTO: We

may need it in a variety of workflows. But these streams are different and, most likely, each use-case will imply a different degree of field filling. For example, we obviously need to create a DTO earlier than when we have complete information about the user. You can temporarily leave the field blank. But the more fields you ignore, the more you will want to create a new, more restrictive DTO for a given use-case.
Alternatively, you can create copies of an excessively large DTO (in the number of available use cases) and then remove the extra fields from each copy. But for many programmers, by virtue of intelligence and literacy, it really hurts to press Ctrl + V. Axiom says that copy-paste is bad.
You can resort to the inheritance principle known in OOP theory : we simply define a certain basic DTO and for each use-case we create a successor.
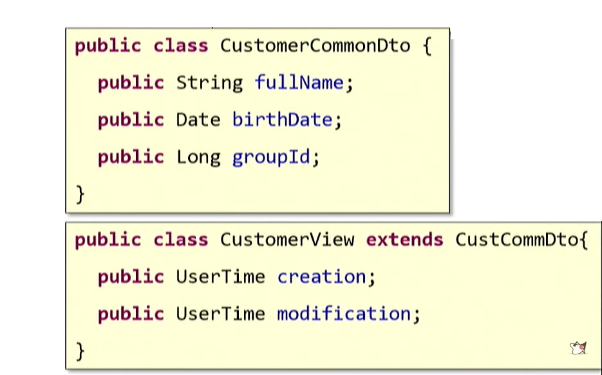
The well-known principle says: "Prefer composition to inheritance." Read what it says: "extends . " It seems that we had to "expand" the original class. But if you think about it, what we have now done is not at all an “extension”. This is the most real "repetition" - the same copy-paste, side view. Therefore, we will not use inheritance.
But how then can we be? How to go to the composition? Let's do it like this: write a field in the CustomerView that points to the base DTO object.
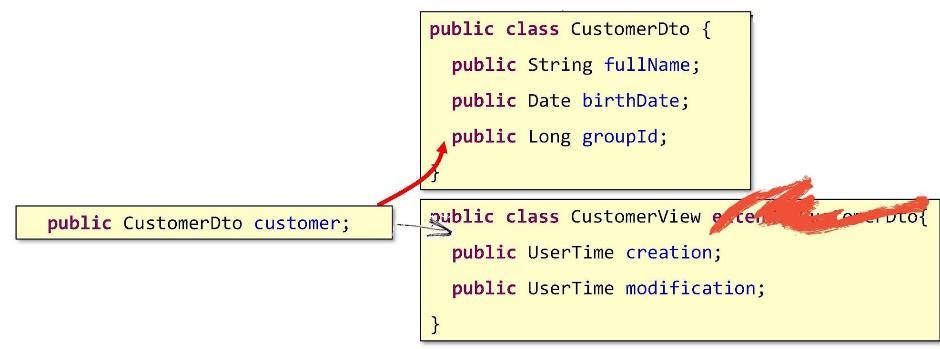
Thus, our basic structure will be embedded inside. This is how the real composition will come out.
Whether we use inheritance or solve the problem of composition - these are all particulars, subtleties that have arisen deeply in the course of our implementation. They are very fragile . What do fragile mean? Look closely at this code:

Most of the developers with whom I showed it immediately blurted out that the number “2” is repeated, so it needs to be rendered as a constant. They did not notice that the two in all three cases has a completely different meaning (or "business value") and that its repetition is nothing more than a coincidence. Making a deuce in a constant is a legitimate solution, but very fragile. Try not to allow fragile logic to the domain. Never work from it with external data structures, in particular, with DTO.
So, why is the work on the elimination of inheritance and the introduction of the composition is useless? It is precisely because we create DTO not for ourselves, but for an external client. And how the client application will parse the DTO received from you - you just have to guess. But it is obvious that this will have little to do with your implementation. Developers on the other side may not make a distinction for the basic and non-basic DTOs that you have so carefully thought out; for sure they use inheritance, and perhaps stupidly copy-paste that’s all.

Let's return to the overall picture of the application. I would advise you to implement domain logic through the Facade pattern , expanding the facades with domain services as needed. Domain service is created when too much logic accumulates in the facade, and it is more convenient to put it into a separate class.
Your domain services must speak the language of your domain model (its entities and value objects). In no case should they work with DTO, because, as you remember, DTO are structures that are constantly changing on the client side, too fragile for a domain.
What is the purpose of the facade?
Just a couple of words about this principle. If the class has reached some size that is inconvenient for me (say, 200 lines), then I should try to break it apart. But it is not always easy to select a new class from the existing one. We need to come up with some universal ways. One of these ways is to search for names: you try to pick a name for a subset of the methods in your class. As soon as you manage to find the name - feel free to create a new class. But this is not so easy. In programming, as you know, there are only two difficult things: it is cache invalidation and inventing names. In this case, inventing a name is associated with the identification of a subtask - hiding and therefore not previously identified.
Example:
In the original facade
Another example:

Suppose there is a class in our system
The division into levels of abstraction always assumes that the class being extracted becomes an addiction , and the extraction is carried out for reuse .
The extraction task is not always easy. It can also entail some difficulties and require some refactoring of unit tests. Nevertheless, according to my observations, it is even harder for developers to search for any kind of functionality based on the huge monolithic code base of the application.
Many consultants will tell you about pair programming, about the fact that this is a universal solution to any problems of IT development today. During it, programmers develop their technical skills and functional knowledge. In addition, the process itself is interesting, it rallies the team.
If we speak not as consultants, but humanly, the most important thing here is: pair programming improves the “bus factor”. The essence of the “bus factor” is that there should be as many people with knowledge about the system as possible . Losing these people means losing the last keys to this knowledge.
Re-factoring in the pair programming format is an art that requires experience and training. Here, for example, the practice of aggressive refactoring, hacking, coding, coding dojos, etc. are useful.
Pair programming works well in cases where you need to solve problems of high complexity. The process of working together is not always easy. But he guarantees you that you will avoid "reengineering" - on the contrary, you will get an implementation that addresses the requirements with minimum complexity.

Organizing a convenient work format is one of your main responsibilities to the team. You must continue to take care of the working conditions of the developer - to provide them with full comfort and freedom of creativity, especially if they are required to increase the design architecture and its complexity.
This nonsense is periodically expressed publicly or behind the scenes. In today's practice, architects as such are less and less found. With the advent of Agile, this role was gradually transferred to the senior developers, because usually all the work, one way or another, is built around them. The size of the implementation is gradually increasing, and along with this, there is a need for refactoring and new functionality is being developed.
Lukovitsa is the purest architecture in Transaction Script philosophy. When building it, we are guided by the goal of protecting the code that we consider critical, and for this we move it to the domain module.

In our application, the most important are domain services: they implement the most critical flows. Move them to the domain module. Of course, here it is worth moving all your domain objects - entities and value objects. Everything else that we are today nakodili - DTO, mappers, validators, etc. - becomes, so to speak, the first line of defense from the user. Because as a user, alas, we are not a friend, and the system must be protected from it.
Attention here on this dependence:

The application module will depend on the domain module - just like that, and not vice versa. By registering such a connection, we guarantee that DTO will never break into the holy territory of the domain module: they are simply not visible and inaccessible from the domain module. It turns out that in some sense we have fenced the territory of the domain - we have limited access to outsiders to it.
However, the domain may need to interact with some external service. With external means with unfriendly, because it is equipped with its own DTO. What are our options?
First: skip the enemy inside the module.
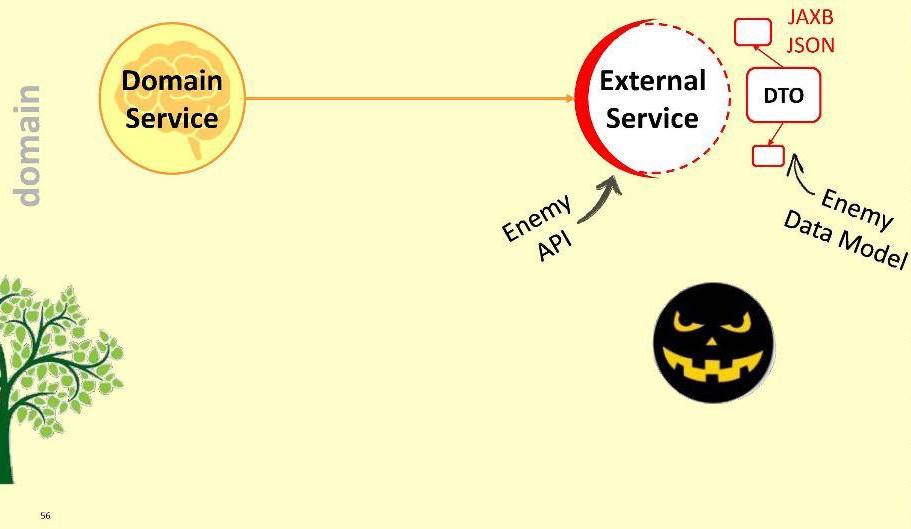
Obviously, this is a bad option: it is possible that tomorrow the external service will not upgrade to version 2.0, and we will have to redraw our domain. You can not let the enemy inside the domain!
I propose another approach: for interaction we will create a special adapter .
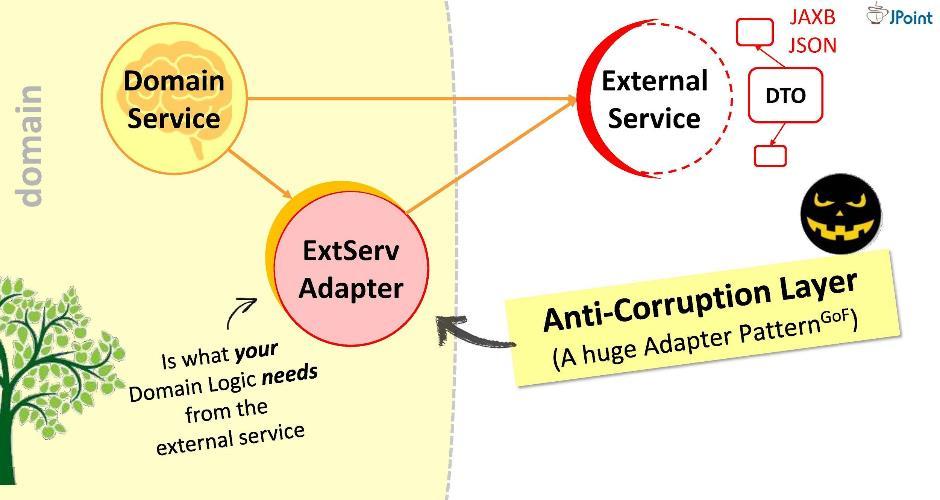
The adapter will receive data from the external service, extract those that are needed by our domain, and convert them to the required types of structures. In this case, all that is required of us during development is to match the calls to the external system with the requirements of the domain. Think of it as such a huge adapter . I call this layer "anti-corruption."
For example, we may need to perform LDAP query from a domain. To do this, we implement the "anti-corruption module

In the adapter, we can:
This is the purpose of the adapter. For good, at the junction with each external system with which you need to interact, should be wound up its adapter.

Thus, the domain will direct the call not to the external service, but to the adapter. For this, a corresponding dependency must be written in the domain (on the adapter or on the infrastructure module in which it is located). But is such a dependency safe? If you install it like this, DTO external service can get into our domain. This we should not allow. Therefore, I suggest you another way to model dependencies.
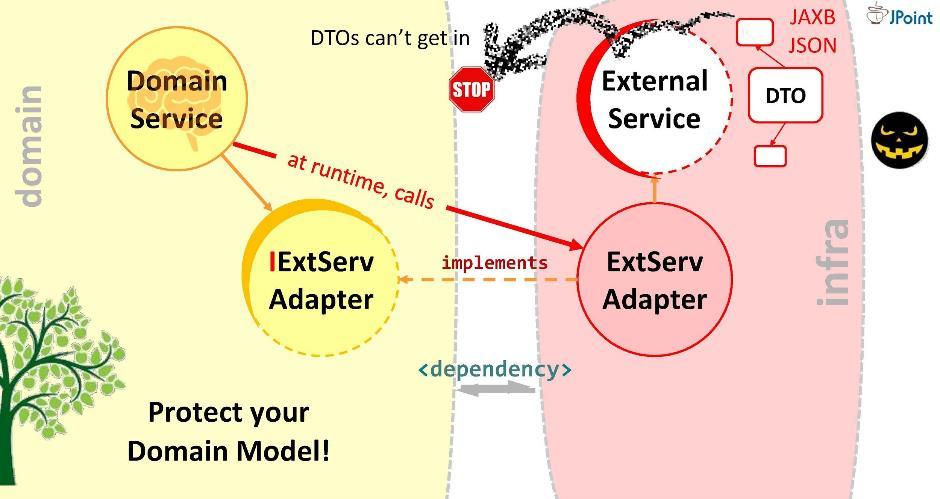
Create an interface, write the signature of the necessary methods in it and place it inside our domain. The task of the adapter is to implement this interface. It turns out that the interface is inside the domain, and the adapter is outside, in the infrastructure module that imports the interface. Thus, we turned the direction of dependence in the opposite direction. During execution, the domain system will call any class through the interfaces.
As you can see, by simply entering interfaces into the architecture, we were able to deploy dependencies and thereby secure our domain from foreign structures and APIs. This approach is called dependency inversion .
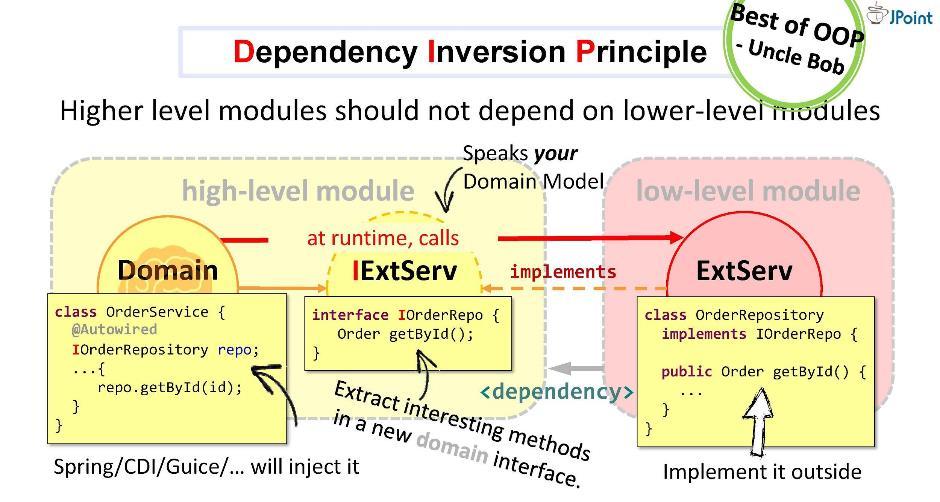
In general, dependency inversion assumes that you place the methods you are interested in the interface inside your high-level module (in the domain), and you implement this interface from the outside - in one or another low-level (infrastructure) ugly module.
The interface implemented inside the domain module must speak the domain language, that is, it will operate with its entities, its parameters and return types. During execution, the domain will call any class through a polymorphic call to the interface. The frameworks intended for dependency injection (for example, Spring and CDI) will provide us with a specific instance of the class right in runtime.
But the main thing is that during the compilation of the domain module will not see the contents of the external module. That is what we need. No external entity should be in the domain.
According to Uncle Bob , the principle of inversion of control (or, as he calls it, “plug-in architecture”) is perhaps the best that the OOP paradigm offers.
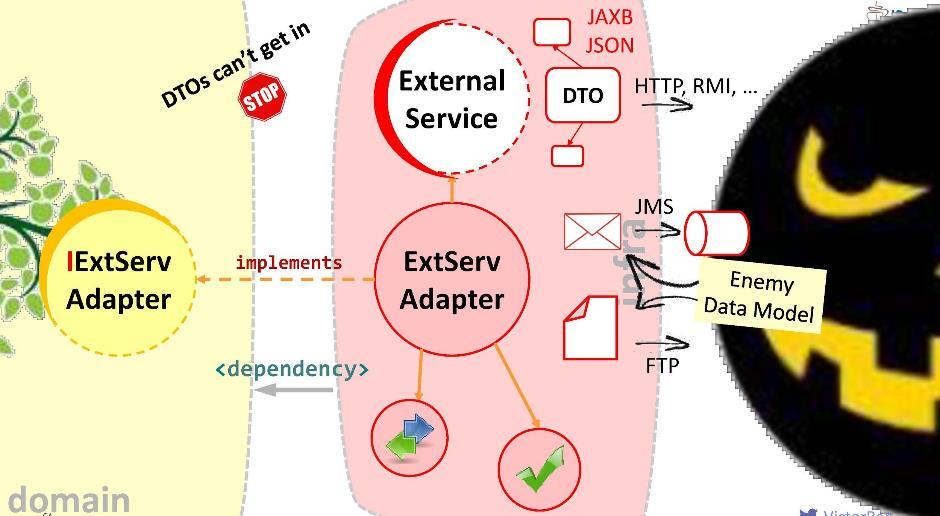
This strategy can be used for integration with any systems, for synchronous and asynchronous calls and messages, for sending files, etc.

So, we decided that we will protect the domain module. Inside it, there is a domain service, entities, value objects, and now interfaces for external services, plus interfaces for the repository (for interacting with the database).
The structure looks like this:
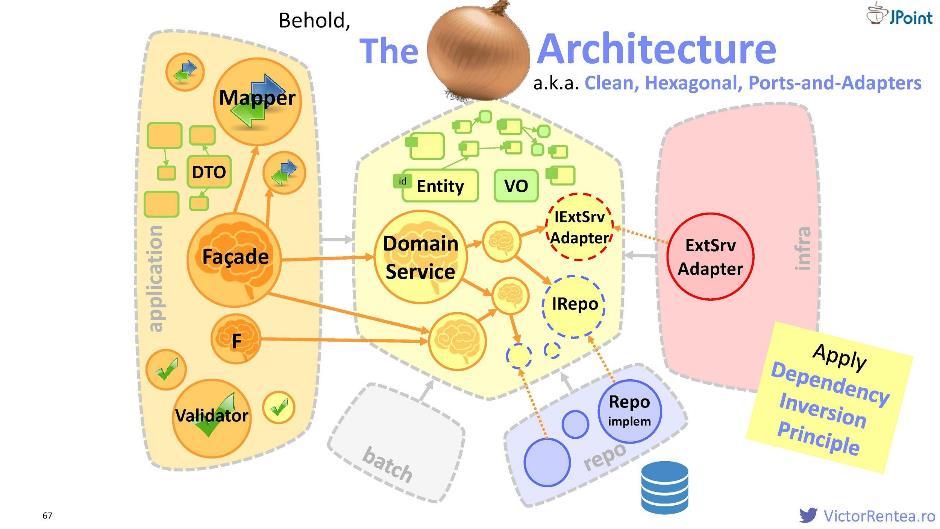
The application module, the infrastructure module (via dependency inversion), the repository module (we also consider the database an external system), the batch module, and possibly some other modules are declared as dependencies for the domain. This architecture is called "onion" ; it is also called “clean”, “hexagonal” and “ports and adapters”.
Briefly tell about the repository module. Whether to take it out of the domain is a question. The task of the repository is to make the logic cleaner by hiding from us the horror of working with persistent data. The option for the old school guys is to use to interact with the JDBC database:

You can also use Spring and its JdbcTemplate:
Or MyBatis DataMapper:

But this is so difficult and ugly that discourages any desire to do something further. Therefore, I suggest using JPA / Hibernate or Spring Data JPA. They will give us the opportunity to send requests that are not built on the database schema, but directly based on the model of our entities.
Implementation for JPA / Hibernate:

In the case of Spring Data JPA:
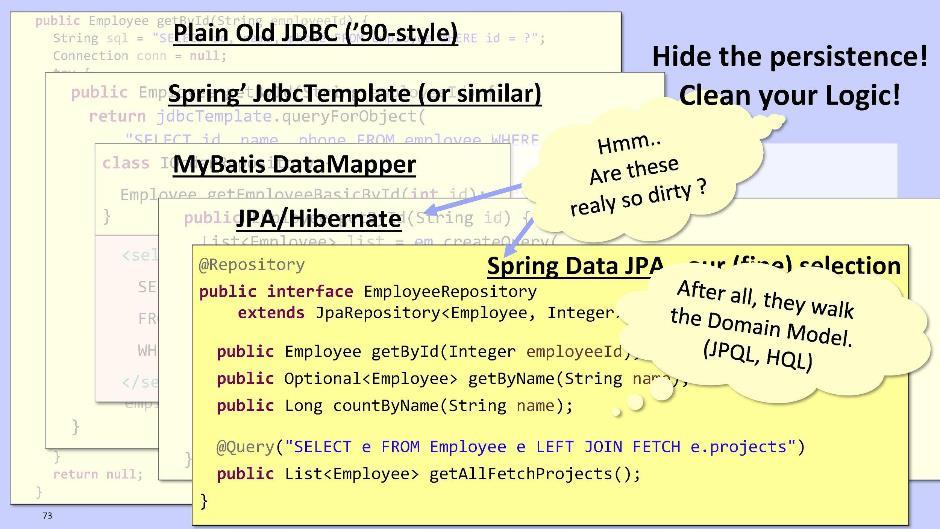
Spring Data JPA can automatically generate methods at runtime, such as, for example, getById (), getByName (). It also allows you to perform JPQL queries if necessary - and not to the database, but to your own entity model.
The Hibernate JPA and Spring Data JPA code really looks pretty good. Do we need to extract it from the domain at all? In my opinion, this is not so necessarily. Most likely, the code will be even cleaner if you leave this fragment within the domain. So act on the situation.

If you still create a repository module, then for the organization of dependencies it is better to use the principle of inversion of control in the same way. To do this, place an interface in the domain and implement it in the repository module. As for the repository logic, it is better to transfer it to the domain. This makes testing convenient, as in the domain you can use Mock objects. They allow you to test the logic quickly and repeatedly.
Traditionally, only one entity is created for the repository in the domain. It is broken only when it becomes too voluminous. Do not forget that classes should be compact.
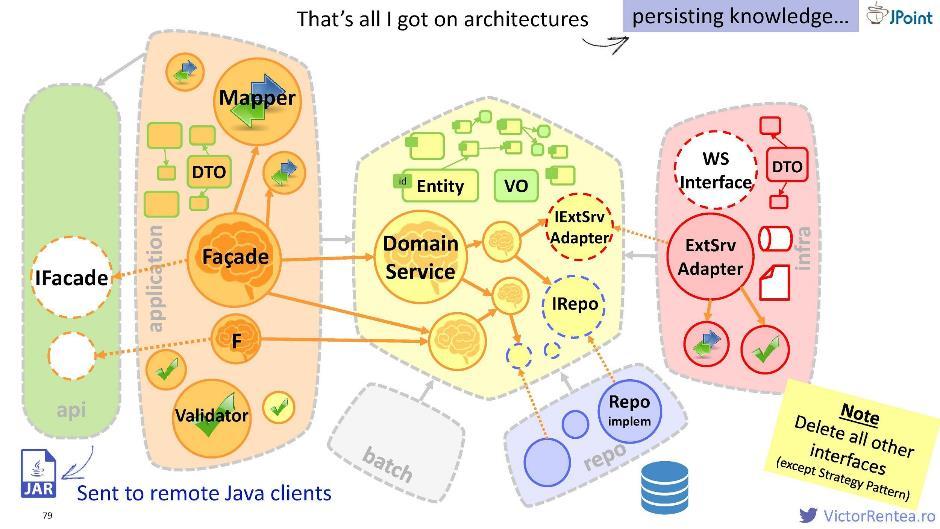
You can create a separate module, put the interface extracted from the facade and the DTOs that belong to it, then package it into a JAR, and send it to your Java clients in this form. Having this file, they will have the opportunity to send requests to the facades.
In addition to our “enemies” to whom we supply functionality, that is, clients, we have enemies and, on the other hand, those modules that we ourselves depend on. We also need to protect ourselves from these modules. And for this I offer you a slightly modified “onion” - in it the entire infrastructure is combined into one module.
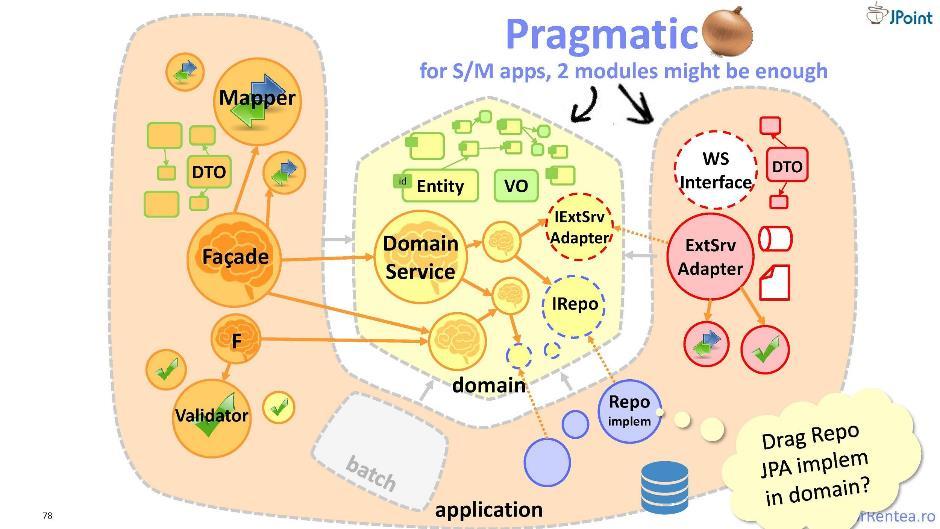
I call this architecture "pragmatic onion". Here, the separation of components takes place on the principle of “mine” and “integrable”: what is related to my domain is stored separately, and what is related to integration with external collaborators is stored separately. Thus, it turns out only two modules: domain and application. This architecture is very good, but only when the application module is small. Otherwise, you'd better go back to the traditional "onion."
As I said earlier, if your application is all afraid, consider that it has expanded the ranks of Legacy.
But tests are good. They give us a sense of confidence, thanks to which we can continue to work on refactoring. But unfortunately, this confidence may calmly be unjustified. I will explain why. TDD (development through testing) assumes that you are both the author of the code and the author of test cases at the same time: read the specifications, implement the functionality and immediately write the test suite for it. The tests, for example, will succeed. But what if you misunderstand the requirements of the specifications? Then the tests will not check what you need. So, your confidence is worth nothing. And all because you wrote both the code and the tests alone.
But let's try to close our eyes to this. Tests are still necessary, and in any case they give us confidence. Most of all, we, of course, love functional tests: they do not imply any side effects, no dependencies - only input and output data. To test the domain, you need to use mock objects: they will allow you to test classes in isolation.
As for queries to the database, then testing them is unpleasant. These tests are fragile, they require that you first add test data to the database - and only after that you can proceed to functionality testing. But as you understand, these tests are also necessary, even if you use JPA.

I would say that the strength of unit tests is not in the ability to run them, but in the process of writing them. While you are writing a test, you rethink and work through the code - reduce connectivity, break into classes - in short, perform the next refactoring. The code under test is pure code; it is simpler, its connectivity is reduced; in general, it is also documented (a well-written unit test perfectly describes how the class works). It is not surprising that writing unit tests is difficult, especially the first few pieces.
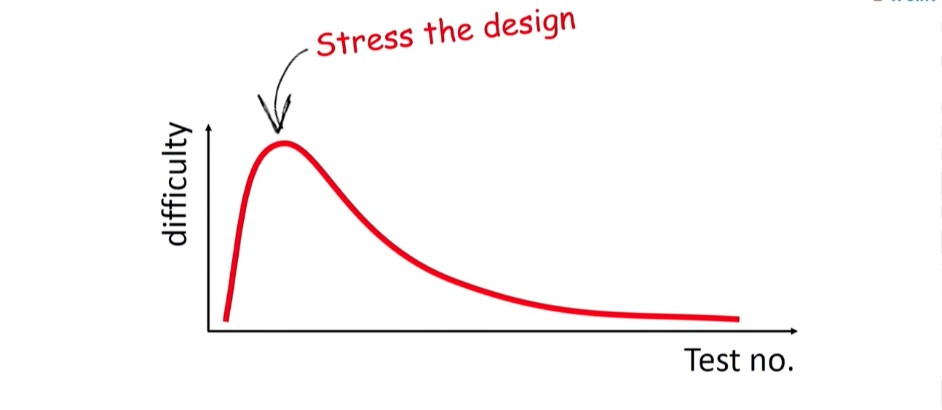
At the stage of the first unit-tests, many are really scared of the prospects that they really have to test something. Why are they so difficult?
Because these tests are the first load on your class. This is the first blow to the system, which may show that it is fragile and flimsy. But we must understand that these several tests are the most important for your development. They are, in essence, your best friends, because they will say it is as it is about the quality of your code. If you are afraid of this stage, you will not be able to go far. You need to run testing for your system. After that, the difficulty will subside, the tests will be written faster. By adding them one by one, you will create a reliable regression test base for your system.. And this is incredibly important for the further work of your developers. It will be easier for them to refactor; They will understand that the system can be tested regression at any time, which is why it is safe to work with the code base. And, I assure you, they will be much more willing to refactor.

My advice to you is: if you feel that today you have a lot of strength and energy, devote yourself to writing unit tests. And make sure that each of them is clean, fast, has its own weight and does not repeat the others.
Summarizing everything said today, I would like to admonish you with the following tips:
By doing these things, you will help your team and yourself. And then, when the day of delivery of the product comes, you will be ready for it.

Calm down, the authorities still will not give anything to rewrite. It remains to refactor. What is the best way to spend your small resources? How exactly to refactor, where to clean?
The title of this article - including a reference to Uncle Bob ’s Pure Architecture , was made based on the remarkable Victor Rentea report ( twitter , website) at the JPoint (under the cut, he will speak from the first person, but for now, finish reading the introductory one). Reading smart books is not a substitute for this article, but it’s written very well for such a short description.
The idea is that popular things like “Clean Architecture” are really useful. Surprise. If you need to solve a very specific problem, a simple elegant code does not require super efforts and over-engineering. Pure architecture says that you need to protect your domain model from external effects, and tells you exactly how to do this. An evolutionary approach to increasing the volume of microservices. Tests that make refactoring less scary. You know all this already? Or you know, but you are afraid to even think about it, because this is a horror then what will you have to do?
Who wants to get a magic anti-procrastination pill that will help to stop shaking and start refactoring - welcome to the video report or under the cat.
My name is Victor, I'm from Romania. Formally, I am a consultant, technical leader and leading architect at IBM in Romania. But if I were asked to define my activities myself, then I am a clean code evangelist. I love to create a beautiful, clean, supported code - as a rule, I tell about it on reports. Even more, I am inspired by teaching: training for developers in the areas of Java EE, Spring, Dojo, Test Driven Development, Java Performance, as well as in the field of evangelism mentioned above - the principles of cleanliness of code patterns and their development.
The experience on which my theory is based is mainly the development of enterprise applications for the largest IBM client in Romania, the banking sector.
The plan for this article is:
- Data modeling: data structures should not become our enemies;
- Logic organization: the principle of “code decomposition, of which there are too many”;
- Onion is the purest Transaction Script philosophy architecture;
- Testing as a way to deal with developer fears.
But first, let's remember those main principles that we, as developers, should always remember.
Principle of sole responsibility
In other words, quantity vs quality. As a rule, the more functionality your class contains, the worse it is in quality terms. When developing large classes, the programmer gets confused, makes mistakes in building dependencies, and large code, among other things, is harder to debug. It is better to break such a class into several smaller ones, each of which will be responsible for a certain subtask. Let it be better you have several strongly connected modules, than one - large and clumsy. Modularity also makes it possible to reuse logic.
Loose coupling of modules
The degree of binding is a characteristic of how closely your modules interact with each other. It shows how widely the effect of the changes you make at any one point in the system can spread. The higher the binding, the more difficult it is to implement modifications: you change something in one module, and the effect spreads far and not always in the expected way. Therefore, the binding rate should be as low as possible - this will give you greater control over the system undergoing modifications.
Do not repeat
Your own implementations may be good today, but not so good tomorrow. Do not allow yourself to copy your own work and thus distribute them on the code base. You can copy from StackOverflow, from books - from any reputable sources that (as you know for sure) offer an ideal (or close to that) implementation. It is very tiring to modify your own implementation, which occurs not only once, but multiplied throughout the code base.
Simplicity and conciseness
In my opinion, this is the main principle that must be followed in engineering and software development. “Premature encapsulation is the root of evil,” said Adam Bien. In other words, the root of evil is "re-engineering." The author of the quote, Adam Bien, was at one time engaged in taking legacy applications and, completely rewriting their code, received a code base 2-3 times smaller than the original one. Where does so much extra code come from? After all, it does not just happen. It is generated by the fears we experience. It seems to us that, piling up patterns in a large number, producing indirectness and abstraction, we provide our code with protection — protection from the unknowns of tomorrow and tomorrow's requirements. After all, in actual fact, today we do not need any of this, we invent all this just for the sake of some “future needs”. And it is possible that these data structures will subsequently interfere. Frankly, when some developer comes up to me and voices that he came up with something interesting that you can add to the production code, I always answer the same way: “Boy, this will not be useful for you.”
There should not be a lot of code, but the one that is should be simple - only in this way can it work normally. This is a concern for your developers. You have to remember that they are the key figures for your system. Try to reduce their energy costs, reduce the risks with which they will have to work. This does not mean that you will have to create your own framework, moreover, I would not advise you to do this: there will always be bugs in your framework, everyone will need to learn it, etc. It is better to use existing funds, of which there is a mass today. These should be simple solutions. Register global error handlers, apply aspect technology, code generators, Spring extensions or CDI, configure Request / Thread scopes, use bytecode and manipulation on the fly, etc.
In particular, I would like to show you the use of Request / Thread areas. I have often observed how this thing simplified corporate applications in an incredible way. The bottom line is that it gives you the opportunity, being logged in by the user, to store RequestContext data. Thus, RequestContext will store user data in a compact form.
As you can see, the implementation takes only a couple of lines of code. By writing the request to the desired annotation (it is easy to do if you use Spring or CDI), you will forever free yourself from having to pass a user login to the methods and whatever else: the metadata stored in the context will move the application transparently. Scoped proxy allows you to access the metadata of the current request at any time.
Regression tests
Developers are afraid of the requirements being updated because they are afraid of the refactoring procedure (code modification). And the easiest way to help them is to create a reliable set of tests for regression testing. With it, the developer will be able to test his work at any time - to make sure that it does not break the system.
The developer should not be afraid to break anything. You must do everything so that refactoring is perceived as something good.
Refactoring is a crucial aspect of development. Remember, exactly at the moment when your developers are afraid of refactoring, the application can be considered to have passed into the category of "Legacy."
Where to implement business logic?
Starting the implementation of any system (or system components), we ask ourselves the question: where is it better to implement the domain logic, that is, the functional aspects of our application? There are two opposite approaches.
The first one is based on the philosophy of Transaction Script . Here, logic is implemented in procedures that work with anemic entities (that is, with data structures). Such an approach is good because in the course of its implementation it is possible to rely on formulated business objectives. While working on applications for the banking sector, I have repeatedly observed the transfer of business procedures to software. I can say that it is really very natural to correlate scripts with software.
An alternative approach is to use Domain-Driven Design principles.. Here, you will need to relate the specifications and requirements with the object-oriented methodology. It is important to think carefully over the objects, and to ensure good business involvement. The advantage of the systems so designed is that they are easily maintained in the future. However, in my experience, it is rather difficult to master this methodology: you feel more or less brave no sooner than after six months of studying it.
For my development, I always chose the first approach. I can assure you that in my case it worked perfectly.
Data modeling
Entities
How do we simulate data? As soon as the application accepts more or less decent sizes, persistent data is sure to appear . This is the data that you need to keep longer than others - they are the domain entities (domain entities) of your system. Where to store them — whether in a database, in a file, or directly managing memory — does not matter. What matters is how you will store them — in which data structures.
As a developer, this choice is given to you, and it only depends on you whether these data structures will work for you or against you in the implementation of functional requirements in the future. For everything to be fine, you must implement the entities, laying in them the nuggets of reused domain logic.. How exactly? I will demonstrate several ways by example.
Let's see what I have provided with the Customer entity. First, I implemented a synthetic getter
getFullName() that will return me the concatenation of firstName and lastName. I also implemented a method activate()- to control the state of my entity, thus encapsulating it. In this method, I put, firstly, the operation on validation , and, secondly, the assignment of values to the status and activatedBy fields , so that it is not necessary to prescribe setters for them. I also added the essence of the Customer techniques isActive()andcanPlaceOrders()implementing lambda validation inside. This is the so-called predicate encapsulation. Such predicates are useful if you use Java 8 filters: you can pass them as arguments to filters. I advise you to use these helpers. Perhaps you are using some kind of ORM like Hibernate. Suppose you have two entities with two-way communication. Initialization must be performed on both sides, otherwise, as you understand, you will encounter problems when accessing this data in the future. But developers often forget to initialize an object from one of the parties. You, developing these entities, can provide special methods that will guarantee two-way initialization. Look at
addAddress().As you can see, this is a completely ordinary entity. But inside it laid the domain logic. Such entities should not be scanty and superficial, but they should not be overflowed with logic. Logic overflow occurs more often: if you decide to implement all the logic in the domain, then for each use-case there will be a temptation to implement some specific method. And use-cases, as a rule, are many. You will not get an entity, but one big pile of all sorts of logic. Try to observe a measure here: only reusable logic is placed in the domain and only in a small amount.
Value objects
In addition to the entities you'll likely also need the value objects (object values). This is nothing more than a way to group the domain data in order to move it along the system together.
The value object must be:
- Small . None
floatfor monetary variables! Be very careful when choosing data types. The more compact your object, the easier it will understand the new developer. This is the basis of the foundations for a comfortable life. - Unchangeable . If the object is really immutable, then the developer can be sure that your object will not change its value or break after creation. This lays the foundation for a calm, confident job.
And if you add a method call to the constructor
validate(), then the developer can be calm for the validity of the created entity (when transferring, say, a non-existent currency or a negative amount of money, the designer will not work).The difference of an entity from a value object
Value objects differ from entities in that they do not have a permanent ID. In entities there will always be fields associated with the foreign key of some table (or other storage). Object values do not have such fields. The question arises: do the procedures for checking for equality of two value objects and two entities differ? Since value objects have no ID field in order to conclude that two such objects are equal, it is necessary to compare the values of all their fields in pairs (that is, to inspect the entire contents). When comparing entities, it suffices to conduct a single comparison — across the ID field. It is in the comparison procedure that the main difference between entities and value objects lies.
Data Transfer Objects (DTOs)
What is the interaction with the user interface (UI)? You must give him the data to display . Will another structure be needed? And there is. That's because the user interface is not your friend. He has his own requests: he needs the data to be stored in accordance with how they should be displayed. This is so wonderful - what exactly user interfaces and their developers require from us. Then they need to get data for five lines; then it occurs to them to create a boolean field for an object
isDeletable(can an object have such a field in principle?), to know whether to make the “Delete” button active or not. But there is nothing to be outraged. User interfaces have other requirements.The question is, is it possible to trust our entities with them? Most likely, they will change them, and in the most undesirable way for us. Therefore, we will provide them with something else - Data Transfer Objects (DTO). They will be adapted specifically for external requirements and for logic that is different from ours. Some examples of the DTO structures are: Form / Request (come from the UI), View / Response (sent to the UI), SearchCriteria / SearchResult, etc. You can in a sense call this an API model.
The first important principle: DTO must contain a minimum of logic.
Here is an example implementation
CustomerDto. Content: private , public-getters and setters for them. It seems to be all super. OOP in all its glory. But one thing is bad: in the form of getters and setters, I implemented too many methods. In DTO, the logic should be as small as possible. And then what is my way out? I make the fields public! You will say that it does not work well with method references from Java 8, that restrictions will arise, etc. But believe it or not, I did all my projects (10-11 pieces) with such DTOs. Brother is alive. Now, since my fields are public, I have the opportunity to easily assign a value
dto.fullNameby simply putting an equal sign. What could be more beautiful and easier?Organization of logic
Mapping
So, we have a task: we need to transform our entities into a DTO. We implement the transformation as follows:
As you can see, by declaring a DTO, we proceed to mapping operations (assignment of values). Do I need to be a senior developer to write ordinary assignments in such a quantity? For some, it is so unusual that they begin to change their shoes on the go: for example, to copy data using some kind of mapping framework using reflex. But they miss the main point - that sooner or later the UI will interact with the DTO, as a result of which the entity and the DTO will diverge in their meanings.
We could, for example, put mapping operations in a constructor. But this is not possible for any mapping; in particular, the designer cannot access the database.
Thus, we have to leave the mapping operations in the business logic. And if they have a compact look, then there is nothing wrong with that. If the mapping does not take a couple of lines, but more, then it is better to put it in the so-called mapper . Mapper is a class specifically designed for copying data. This is, in general, antediluvian thing and a boilerplate. But behind them, you can hide our numerous assignments - to make the code cleaner and slimmer.
Remember: the code that has grown too much, you need to make a separate structure . In our case, the mapping operations were really a bit much, so we carried them into a separate class - to the mapper.
Do mappers allow database access? You can allow it by default - this is often done for reasons of simplicity and pragmatics. But it puts you at some risk.
I will illustrate with an example. Create an entity based on the existing DTO
Customer. For mapping, we need to get a link to the customer group from the database. So I run the method
getReference(), and it returns some entity to me. The request will most likely go to the database (in some cases this does not happen, and the stub function works). But trouble awaits us not here, but in the method that performs the inverse operation — transformation of the entity into DTO.
With the help of a cycle, we go through all the addresses associated with the existing Customer, and convert them into DTO addresses. If you use ORM, then, probably, a
getAddresses()lazy loading will be performed when the method is called . If you do not use ORM, then it will be an open request to all children of this parent. And here you run the risk of getting into the “N + 1 problem”. Why? You have a set of parents, each of whom has children. For all this, you need to create your own analogs inside the DTO. You will need to perform one
SELECTrequest for traversing N parent entities, and then N more SELECTrequests to bypass the children of each of them. Total N + 1 request. For 1000 parent entities, Customersuch an operation takes 5-10 seconds, which, of course, takes a long time. Suppose, nevertheless, our method
CustomerDto()is called inside the loop, converting the list of Customer objects into a list CustomerDto. The problem with N + 1 queries has simple sample solutions: in JPQL, you can use
FETCHthe customer.addresses to retrieve the children and then connect them with the help JOIN, and in SQL you can use the crawl INand operator WHERE. But I would have done differently. You can find out what is the maximum length of the list of children (this can be done, for example, on the basis of a search with pagination). If there are only 15 entities in the list, then we need only 16 requests. Instead of 5ms, we will spend on everything, say, 15ms - the user will not notice the difference.
About optimization
I would not advise you to look at the performance of the system at the initial stage of development. As Donald Knud said: "Premature optimization is the root of evil." You can not optimize from the beginning. This is exactly what needs to be left for later. And what is especially important: no assumptions - only measurements and measurement of measurements!
Are you sure that you are competent, that you are a real expert? Be modest in assessing yourself. Do not think that you understood the work of the JVM until you read at least a couple of books about JIT compilation. It happens that the best programmers from our team come up to me and say that, as it seems to them , they have found a more efficient implementation. It turns out that they again invented something that only complicates the code. Therefore, I answer time after time: YAGNI. We do not need it.
Often for corporate applications no optimization of algorithms is required at all. The bottleneck for them, as a rule, is not a compilation, and not what concerns the operation of the processor, but various input-output operations. For example, reading a million lines from a database, volume records to a file, interaction with sockets.
Over time, you begin to understand what bottlenecks the system contains, and, having backed up all the measurements, you will begin to gradually optimize. Until then, keep the code as clean as possible. You will find that such code is much easier to further optimize.
Prefer composition to inheritance.
Let's return to our DTO. Suppose we have defined such a DTO: We
may need it in a variety of workflows. But these streams are different and, most likely, each use-case will imply a different degree of field filling. For example, we obviously need to create a DTO earlier than when we have complete information about the user. You can temporarily leave the field blank. But the more fields you ignore, the more you will want to create a new, more restrictive DTO for a given use-case.
Alternatively, you can create copies of an excessively large DTO (in the number of available use cases) and then remove the extra fields from each copy. But for many programmers, by virtue of intelligence and literacy, it really hurts to press Ctrl + V. Axiom says that copy-paste is bad.
You can resort to the inheritance principle known in OOP theory : we simply define a certain basic DTO and for each use-case we create a successor.
The well-known principle says: "Prefer composition to inheritance." Read what it says: "extends . " It seems that we had to "expand" the original class. But if you think about it, what we have now done is not at all an “extension”. This is the most real "repetition" - the same copy-paste, side view. Therefore, we will not use inheritance.
But how then can we be? How to go to the composition? Let's do it like this: write a field in the CustomerView that points to the base DTO object.
Thus, our basic structure will be embedded inside. This is how the real composition will come out.
Whether we use inheritance or solve the problem of composition - these are all particulars, subtleties that have arisen deeply in the course of our implementation. They are very fragile . What do fragile mean? Look closely at this code:
Most of the developers with whom I showed it immediately blurted out that the number “2” is repeated, so it needs to be rendered as a constant. They did not notice that the two in all three cases has a completely different meaning (or "business value") and that its repetition is nothing more than a coincidence. Making a deuce in a constant is a legitimate solution, but very fragile. Try not to allow fragile logic to the domain. Never work from it with external data structures, in particular, with DTO.
So, why is the work on the elimination of inheritance and the introduction of the composition is useless? It is precisely because we create DTO not for ourselves, but for an external client. And how the client application will parse the DTO received from you - you just have to guess. But it is obvious that this will have little to do with your implementation. Developers on the other side may not make a distinction for the basic and non-basic DTOs that you have so carefully thought out; for sure they use inheritance, and perhaps stupidly copy-paste that’s all.
Facades
Let's return to the overall picture of the application. I would advise you to implement domain logic through the Facade pattern , expanding the facades with domain services as needed. Domain service is created when too much logic accumulates in the facade, and it is more convenient to put it into a separate class.
Your domain services must speak the language of your domain model (its entities and value objects). In no case should they work with DTO, because, as you remember, DTO are structures that are constantly changing on the client side, too fragile for a domain.
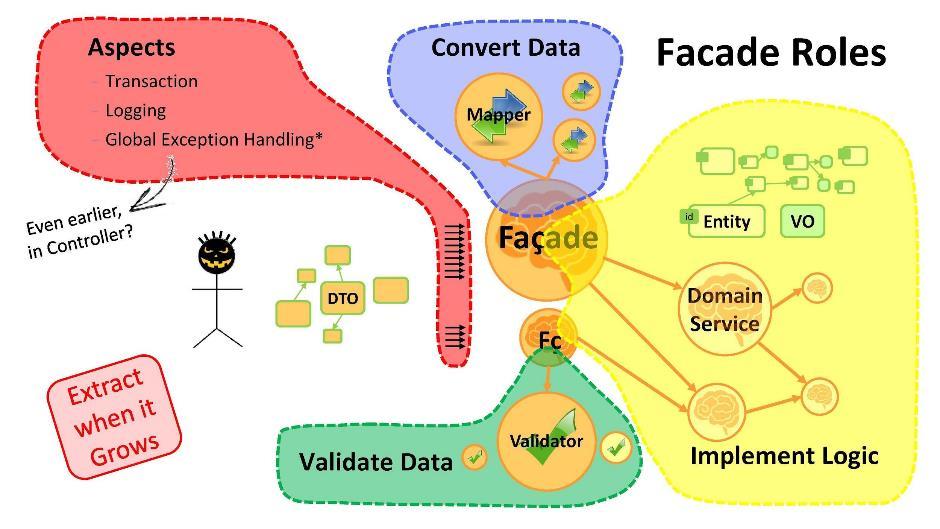
What is the purpose of the facade?
- Data conversion If we have entities from one end and DTO from the other, it is necessary to convert from one to the other. And this is the first thing for what facades are needed. If the conversion procedure has expanded in size - use mapping classes.
- The implementation of logic. In the facade you will begin to write the main logic of the application. As soon as it becomes a lot - take out the parts in the domain service.
- Validation of data. Remember that any data from the user by definition is incorrect (containing errors). The facade has the ability to validate the data. These procedures, when exceeding the volume, are taken to be validators .
- Aspects. You can go ahead and make each use-case pass through its facade. Then it will be possible to build on the facade methods such things as transactions, logging, global exception handlers, etc. I note that it is very important to have global exception handlers in any application that would catch all errors not caught by other handlers. They will greatly help your programmers - they will give them peace of mind and freedom of action.
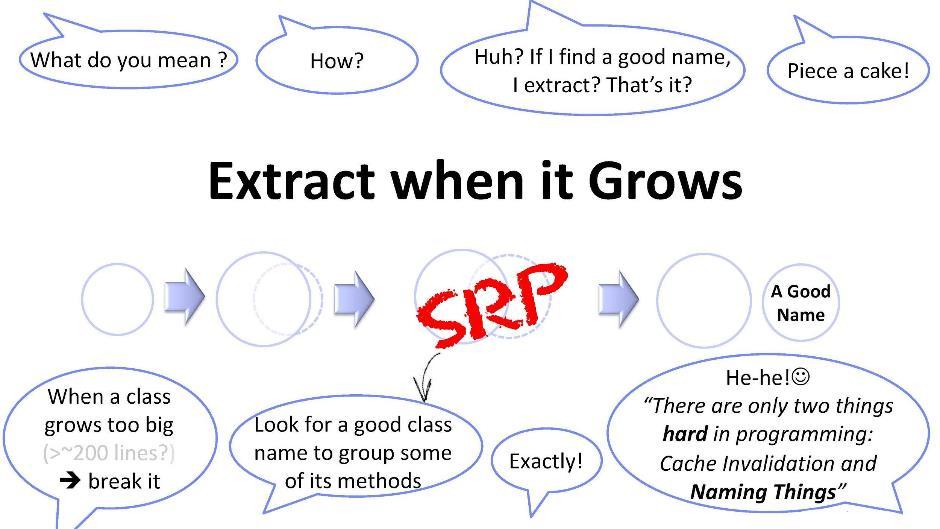
Code decomposition
Just a couple of words about this principle. If the class has reached some size that is inconvenient for me (say, 200 lines), then I should try to break it apart. But it is not always easy to select a new class from the existing one. We need to come up with some universal ways. One of these ways is to search for names: you try to pick a name for a subset of the methods in your class. As soon as you manage to find the name - feel free to create a new class. But this is not so easy. In programming, as you know, there are only two difficult things: it is cache invalidation and inventing names. In this case, inventing a name is associated with the identification of a subtask - hiding and therefore not previously identified.
Example:
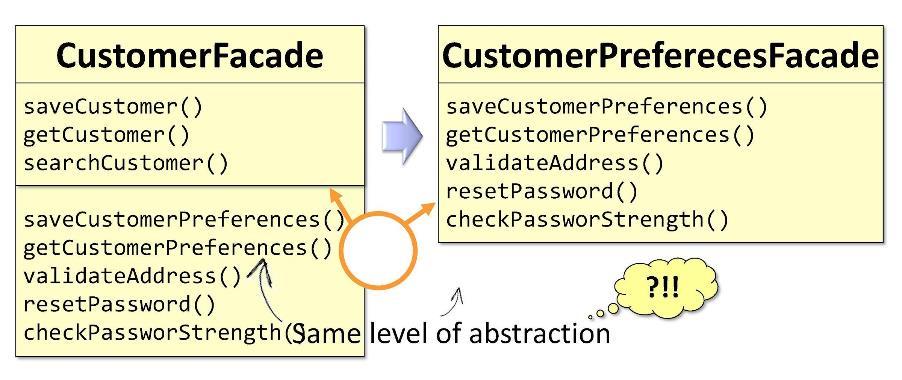
In the original facade
CustomerFacadeSome of the methods are directly related to the buyer, some - with the preferences of the buyer. Based on this, I will be able to split the class into two parts when it reaches critical sizes. I will receive two facades: CustomerFacadeand CustomerPreferencesFacade. The only bad thing is that both of these facades belong to the same level of abstraction. Separation by levels of abstraction suggests something else. Another example:
Suppose there is a class in our system
OrderServicein which we implemented an email notification mechanism. Now we are creating DeliveryServiceand would like to use the same notification mechanism here. Kopipast - excluded. Let's do this: extract the functionality of notifications to a new class AlertServiceand write it as a dependency for classes DeliveryServiceandOrderService. Here, in contrast to the previous example, the separation occurred precisely according to levels of abstraction. DeliveryServicemore abstract than AlertServicebecause it uses it as part of its workflow. The division into levels of abstraction always assumes that the class being extracted becomes an addiction , and the extraction is carried out for reuse .
The extraction task is not always easy. It can also entail some difficulties and require some refactoring of unit tests. Nevertheless, according to my observations, it is even harder for developers to search for any kind of functionality based on the huge monolithic code base of the application.
Pair programming
Many consultants will tell you about pair programming, about the fact that this is a universal solution to any problems of IT development today. During it, programmers develop their technical skills and functional knowledge. In addition, the process itself is interesting, it rallies the team.
If we speak not as consultants, but humanly, the most important thing here is: pair programming improves the “bus factor”. The essence of the “bus factor” is that there should be as many people with knowledge about the system as possible . Losing these people means losing the last keys to this knowledge.
Re-factoring in the pair programming format is an art that requires experience and training. Here, for example, the practice of aggressive refactoring, hacking, coding, coding dojos, etc. are useful.
Pair programming works well in cases where you need to solve problems of high complexity. The process of working together is not always easy. But he guarantees you that you will avoid "reengineering" - on the contrary, you will get an implementation that addresses the requirements with minimum complexity.
Organizing a convenient work format is one of your main responsibilities to the team. You must continue to take care of the working conditions of the developer - to provide them with full comfort and freedom of creativity, especially if they are required to increase the design architecture and its complexity.
“I am an architect. By definition, I'm always right. ”
This nonsense is periodically expressed publicly or behind the scenes. In today's practice, architects as such are less and less found. With the advent of Agile, this role was gradually transferred to the senior developers, because usually all the work, one way or another, is built around them. The size of the implementation is gradually increasing, and along with this, there is a need for refactoring and new functionality is being developed.
Architecture "onion"
Lukovitsa is the purest architecture in Transaction Script philosophy. When building it, we are guided by the goal of protecting the code that we consider critical, and for this we move it to the domain module.
In our application, the most important are domain services: they implement the most critical flows. Move them to the domain module. Of course, here it is worth moving all your domain objects - entities and value objects. Everything else that we are today nakodili - DTO, mappers, validators, etc. - becomes, so to speak, the first line of defense from the user. Because as a user, alas, we are not a friend, and the system must be protected from it.
Attention here on this dependence:
The application module will depend on the domain module - just like that, and not vice versa. By registering such a connection, we guarantee that DTO will never break into the holy territory of the domain module: they are simply not visible and inaccessible from the domain module. It turns out that in some sense we have fenced the territory of the domain - we have limited access to outsiders to it.
However, the domain may need to interact with some external service. With external means with unfriendly, because it is equipped with its own DTO. What are our options?
First: skip the enemy inside the module.
Obviously, this is a bad option: it is possible that tomorrow the external service will not upgrade to version 2.0, and we will have to redraw our domain. You can not let the enemy inside the domain!
I propose another approach: for interaction we will create a special adapter .
The adapter will receive data from the external service, extract those that are needed by our domain, and convert them to the required types of structures. In this case, all that is required of us during development is to match the calls to the external system with the requirements of the domain. Think of it as such a huge adapter . I call this layer "anti-corruption."
For example, we may need to perform LDAP query from a domain. To do this, we implement the "anti-corruption module
LDAPUserServiceAdapter. " In the adapter, we can:
- Hide ugly API calls (in our case, hide the method that accepts an array of Object);
- Pack exceptions into our own implementations;
- Convert foreign data structures into their own (in our domain objects);
- Check the validity of incoming data.
This is the purpose of the adapter. For good, at the junction with each external system with which you need to interact, should be wound up its adapter.
Thus, the domain will direct the call not to the external service, but to the adapter. For this, a corresponding dependency must be written in the domain (on the adapter or on the infrastructure module in which it is located). But is such a dependency safe? If you install it like this, DTO external service can get into our domain. This we should not allow. Therefore, I suggest you another way to model dependencies.
Dependency Inversion Principle
Create an interface, write the signature of the necessary methods in it and place it inside our domain. The task of the adapter is to implement this interface. It turns out that the interface is inside the domain, and the adapter is outside, in the infrastructure module that imports the interface. Thus, we turned the direction of dependence in the opposite direction. During execution, the domain system will call any class through the interfaces.
As you can see, by simply entering interfaces into the architecture, we were able to deploy dependencies and thereby secure our domain from foreign structures and APIs. This approach is called dependency inversion .
In general, dependency inversion assumes that you place the methods you are interested in the interface inside your high-level module (in the domain), and you implement this interface from the outside - in one or another low-level (infrastructure) ugly module.
The interface implemented inside the domain module must speak the domain language, that is, it will operate with its entities, its parameters and return types. During execution, the domain will call any class through a polymorphic call to the interface. The frameworks intended for dependency injection (for example, Spring and CDI) will provide us with a specific instance of the class right in runtime.
But the main thing is that during the compilation of the domain module will not see the contents of the external module. That is what we need. No external entity should be in the domain.
According to Uncle Bob , the principle of inversion of control (or, as he calls it, “plug-in architecture”) is perhaps the best that the OOP paradigm offers.
This strategy can be used for integration with any systems, for synchronous and asynchronous calls and messages, for sending files, etc.
Bulb Review
So, we decided that we will protect the domain module. Inside it, there is a domain service, entities, value objects, and now interfaces for external services, plus interfaces for the repository (for interacting with the database).
The structure looks like this:
The application module, the infrastructure module (via dependency inversion), the repository module (we also consider the database an external system), the batch module, and possibly some other modules are declared as dependencies for the domain. This architecture is called "onion" ; it is also called “clean”, “hexagonal” and “ports and adapters”.
Repository module
Briefly tell about the repository module. Whether to take it out of the domain is a question. The task of the repository is to make the logic cleaner by hiding from us the horror of working with persistent data. The option for the old school guys is to use to interact with the JDBC database:
You can also use Spring and its JdbcTemplate:
Or MyBatis DataMapper:
But this is so difficult and ugly that discourages any desire to do something further. Therefore, I suggest using JPA / Hibernate or Spring Data JPA. They will give us the opportunity to send requests that are not built on the database schema, but directly based on the model of our entities.
Implementation for JPA / Hibernate:
In the case of Spring Data JPA:
Spring Data JPA can automatically generate methods at runtime, such as, for example, getById (), getByName (). It also allows you to perform JPQL queries if necessary - and not to the database, but to your own entity model.
The Hibernate JPA and Spring Data JPA code really looks pretty good. Do we need to extract it from the domain at all? In my opinion, this is not so necessarily. Most likely, the code will be even cleaner if you leave this fragment within the domain. So act on the situation.
If you still create a repository module, then for the organization of dependencies it is better to use the principle of inversion of control in the same way. To do this, place an interface in the domain and implement it in the repository module. As for the repository logic, it is better to transfer it to the domain. This makes testing convenient, as in the domain you can use Mock objects. They allow you to test the logic quickly and repeatedly.
Traditionally, only one entity is created for the repository in the domain. It is broken only when it becomes too voluminous. Do not forget that classes should be compact.
API
You can create a separate module, put the interface extracted from the facade and the DTOs that belong to it, then package it into a JAR, and send it to your Java clients in this form. Having this file, they will have the opportunity to send requests to the facades.
"Pragmatic Onion"
In addition to our “enemies” to whom we supply functionality, that is, clients, we have enemies and, on the other hand, those modules that we ourselves depend on. We also need to protect ourselves from these modules. And for this I offer you a slightly modified “onion” - in it the entire infrastructure is combined into one module.
I call this architecture "pragmatic onion". Here, the separation of components takes place on the principle of “mine” and “integrable”: what is related to my domain is stored separately, and what is related to integration with external collaborators is stored separately. Thus, it turns out only two modules: domain and application. This architecture is very good, but only when the application module is small. Otherwise, you'd better go back to the traditional "onion."
Tests
As I said earlier, if your application is all afraid, consider that it has expanded the ranks of Legacy.
But tests are good. They give us a sense of confidence, thanks to which we can continue to work on refactoring. But unfortunately, this confidence may calmly be unjustified. I will explain why. TDD (development through testing) assumes that you are both the author of the code and the author of test cases at the same time: read the specifications, implement the functionality and immediately write the test suite for it. The tests, for example, will succeed. But what if you misunderstand the requirements of the specifications? Then the tests will not check what you need. So, your confidence is worth nothing. And all because you wrote both the code and the tests alone.
But let's try to close our eyes to this. Tests are still necessary, and in any case they give us confidence. Most of all, we, of course, love functional tests: they do not imply any side effects, no dependencies - only input and output data. To test the domain, you need to use mock objects: they will allow you to test classes in isolation.
As for queries to the database, then testing them is unpleasant. These tests are fragile, they require that you first add test data to the database - and only after that you can proceed to functionality testing. But as you understand, these tests are also necessary, even if you use JPA.
Unit tests
I would say that the strength of unit tests is not in the ability to run them, but in the process of writing them. While you are writing a test, you rethink and work through the code - reduce connectivity, break into classes - in short, perform the next refactoring. The code under test is pure code; it is simpler, its connectivity is reduced; in general, it is also documented (a well-written unit test perfectly describes how the class works). It is not surprising that writing unit tests is difficult, especially the first few pieces.
At the stage of the first unit-tests, many are really scared of the prospects that they really have to test something. Why are they so difficult?
Because these tests are the first load on your class. This is the first blow to the system, which may show that it is fragile and flimsy. But we must understand that these several tests are the most important for your development. They are, in essence, your best friends, because they will say it is as it is about the quality of your code. If you are afraid of this stage, you will not be able to go far. You need to run testing for your system. After that, the difficulty will subside, the tests will be written faster. By adding them one by one, you will create a reliable regression test base for your system.. And this is incredibly important for the further work of your developers. It will be easier for them to refactor; They will understand that the system can be tested regression at any time, which is why it is safe to work with the code base. And, I assure you, they will be much more willing to refactor.
My advice to you is: if you feel that today you have a lot of strength and energy, devote yourself to writing unit tests. And make sure that each of them is clean, fast, has its own weight and does not repeat the others.
Tips
Summarizing everything said today, I would like to admonish you with the following tips:
- Keep your simplicity as long as possible (and no matter what it takes ) : avoid “re-engineering” and late optimization, do not overload the application;
- Take care of your developers , take action to protect themselves and what they are doing;
- Identify "enemy" data structures and keep them at a safe distance from the domain - external structures must always remain outside ;
- If you think that the logic has grown and takes up a lot of space - decompose : formulate the names of the subtasks and implement them in a separate class;
- Remember about the architecture of the “onion”, or rather, about its main idea - placing only critical code in the domain and unavailability of external structures for the domain ;
- Do not be afraid of tests : give them the opportunity to bring down your system, feel all their benefits - after all, they are your friends because they can honestly point out problems.
By doing these things, you will help your team and yourself. And then, when the day of delivery of the product comes, you will be ready for it.
What to read
- 7 Virtues of a Good Object
- NULL is the worst mistake in computer science
- The clean architecture
- New Programming Jargon
- Code quality: WTFs / minute
- Why every single element of SOLID is wrong!
- Good software is written 3 times
Minute advertising. If you liked this report from the JPoint conference - note that on October 19-20, St. Petersburg will host Joker 2018 - the largest Java conference in Russia. His program will also have a lot of interesting things. The site already has the first speakers and reports.