Jinja2 in the C ++ world, part two. Rendering
 This is the second part of the story about porting the Jinja2 template engine to C ++. You can read the first one here: Third-order templates, or how I ported Jinja2 to C ++ . It will focus on the process of rendering templates. Or, in other words, about writing from scratch an interpreter of a python-like language.
This is the second part of the story about porting the Jinja2 template engine to C ++. You can read the first one here: Third-order templates, or how I ported Jinja2 to C ++ . It will focus on the process of rendering templates. Or, in other words, about writing from scratch an interpreter of a python-like language.
Rendering as such
After parsing, the template turns into a tree containing nodes of three types: plain text , calculated expressions, and control structures. Accordingly, during the rendering process, plain text should be placed without any changes in the output stream, expressions should be calculated, converted into text, which will be placed in the stream, and control structures must be executed. At first glance, there was nothing complicated in implementing the rendering process: you just need to go around all the nodes of the tree, calculate everything, execute everything and generate text. Everything is simple. Exactly as long as two conditions are met: a) all work is done with strings of only one type (string or wstring); b) only very simple expressions and basic ones are used. Actually, it is with such restrictions that inja and Jinja2CppLight are implemented. In the case of my Jinja2Cppboth conditions do not work. Firstly, I initially laid down transparent support for both types of strings. Secondly, the whole development was started just for the sake of supporting the Jinja2 specification almost in full, and this, in essence, is a full-fledged scripting language. Therefore, I had to dig deeper with rendering than with parsing.
Expression Evaluation
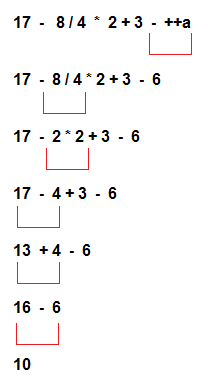 A template would not be a template if it could not be parameterized. In principle, Jinja2 allows the option of templates "in itself" - all the necessary variables can be set inside the template itself, and then render it. But working in a template with parameters obtained "outside" remains the main case. Thus, the result of evaluating an expression depends on which variables (parameters) with which values are visible at the points of calculation. And the catch is that in Jinja2 there are not just scope (which can be nested), but also with complicated rules of "transparency". For example, here is a template:
A template would not be a template if it could not be parameterized. In principle, Jinja2 allows the option of templates "in itself" - all the necessary variables can be set inside the template itself, and then render it. But working in a template with parameters obtained "outside" remains the main case. Thus, the result of evaluating an expression depends on which variables (parameters) with which values are visible at the points of calculation. And the catch is that in Jinja2 there are not just scope (which can be nested), but also with complicated rules of "transparency". For example, here is a template:
{% set param1=10 %}
{{ param1 }}As a result of its rendering, the text 10
Option will be obtained a little more complicated:
{% set param1=10 %}
{{ param1 }}
{% for param1 in range(10) %}-{{ param1 }}-{% endfor %}
{{ param1 }}It will be rendered already. 10-0--1--2--3--4--5--6--7--8--9-10
The cycle generates a new scope in which you can define your own variable parameters, and these parameters will not be visible outside the scope, just as they will not grind the values of the same parameters in the external one. Even trickier with extends / block constructs, but it’s better to read about this in the Jinja2 documentation.
Thus, the context of the calculations appears. Or rather, rendering in general:
class RenderContext
{
public:
RenderContext(const InternalValueMap& extValues, IRendererCallback* rendererCallback);
InternalValueMap& EnterScope();
void ExitScope();
auto FindValue(const std::string& val, bool& found) const
{
for (auto p = m_scopes.rbegin(); p != m_scopes.rend(); ++ p)
{
auto valP = p->find(val);
if (valP != p->end())
{
found = true;
return valP;
}
}
auto valP = m_externalScope->find(val);
if (valP != m_externalScope->end())
{
found = true;
return valP;
}
found = false;
return m_externalScope->end();
}
auto& GetCurrentScope() const;
auto& GetCurrentScope();
auto& GetGlobalScope();
auto GetRendererCallback();
RenderContext Clone(bool includeCurrentContext) const;
private:
InternalValueMap* m_currentScope;
const InternalValueMap* m_externalScope;
std::list m_scopes;
IRendererCallback* m_rendererCallback;
}; The context contains a pointer to a collection of values obtained when the rendering function was called, a list (stack) of scopes, the current active scope, and a pointer to a callback interface, with various functions useful for rendering. But about him a little later. The parameter search function sequentially goes up the list of contexts up to the external one until it finds the necessary parameter.
Now a little about the parameters themselves. From the point of view of the external interface (and its users), Jinja2 supports the following list of valid types:
- Numbers (int, double)
- Strings (narrow, wide)
- bool
- Arrays (more like dimensionless tuples)
- Dictionaries
- Reflected C ++ Structures
All this is described by a special data type created on the basis of boost :: variant:
using ValueData = boost::variant, boost::recursive_wrapper, GenericList, GenericMap>;
class Value {
public:
Value() = default;
template
Value(T&& val, typename std::enable_if, Value>::value>::type* = nullptr)
: m_data(std::forward(val))
{
}
Value(const char* val)
: m_data(std::string(val))
{
}
template
Value(char (&val)[N])
: m_data(std::string(val))
{
}
Value(int val)
: m_data(static_cast(val))
{
}
const ValueData& data() const {return m_data;}
ValueData& data() {return m_data;}
private:
ValueData m_data;
}; Of course, elements of arrays and dictionaries can be any of the types listed. But the problem is that for internal use this set of types is too narrow. To simplify the implementation, support was needed for the following additional types:
- String in target format. It can be narrow or wide depending on what type of template is being rendered.
- callable type
- AST tree assembly
- Key-value pair
Through this expansion, it became possible to transfer service data through the rendering context, which otherwise would have to be "shined" in public headers, as well as more successfully generalize some algorithms that work with arrays and dictionaries.
Boost :: variant was not chosen by chance. Its rich capabilities are used to work with parameters of specific types. Jinja2CppLight uses polymorphic classes for the same purpose, while inja uses the nlohmann json library type system. Both of these alternatives, alas, did not suit me. Reason: the possibility of n-ary dispatching for boost :: variant (and now - std :: variant). For a variant type, you can make a static visitor that accepts two specific stored types and set it against a pair of values. And everything will work as it should! In the case of polymorphic classes or simple unions, this convenience will not work:
struct StringJoiner : BaseVisitor<>
{
using BaseVisitor::operator ();
InternalValue operator() (EmptyValue, const std::string& str) const
{
return str;
}
InternalValue operator() (const std::string& left, const std::string& right) const
{
return left + right;
}
};Such a visitor is called very simply:
InternalValue delimiter = m_args["d"]->Evaluate(context);
for (const InternalValue& val : values)
{
if (isFirst)
isFirst = false;
else
result = Apply2(result, delimiter);
result = Apply2(result, val);
} Apply2here is a wrapper over boost::apply_visitor, which applies the visitor of the type specified by the template parameter to a pair of variant values, preliminarily making some transformations, if necessary. If the visitor’s designer needs parameters, they are passed after the objects to which the visitor applies:
comparator = [](const KeyValuePair& left, const KeyValuePair& right)
{
return ConvertToBool(Apply2(left.value, right.value, BinaryExpression::LogicalLt, BinaryExpression::CaseSensitive));
}; 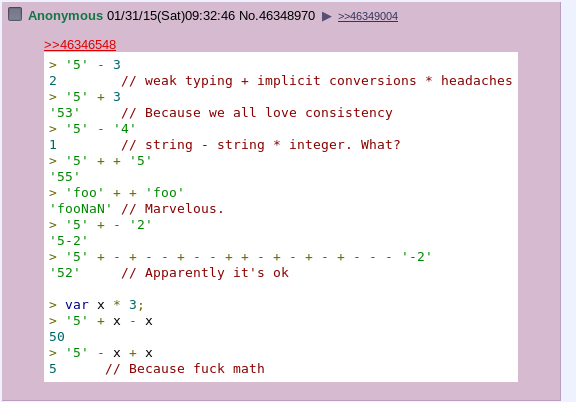 Thus, the logic of operations with parameters comes out as follows: variant (s) -> unpacking using visitor -> performing the desired action on specific values of specific types -> packing the result back into variant. And a minimum of magic undercover. It would be possible to implement everything as in js: perform operations (for example, additions) in any case, choosing a certain system of converting strings to numbers, numbers to strings, strings to lists, etc. And get strange and unexpected results. I chose a simpler and more predictable way: if an operation on a value (or a pair of values) is impossible or illogical, then an empty result is returned. Therefore, when adding a number to a string, you can get a string as a result only if the concatenation operation ('~') is used. Otherwise, the result will be an empty value. The priority of operations is determined by the grammar, therefore, no additional checks are required during AST processing.
Thus, the logic of operations with parameters comes out as follows: variant (s) -> unpacking using visitor -> performing the desired action on specific values of specific types -> packing the result back into variant. And a minimum of magic undercover. It would be possible to implement everything as in js: perform operations (for example, additions) in any case, choosing a certain system of converting strings to numbers, numbers to strings, strings to lists, etc. And get strange and unexpected results. I chose a simpler and more predictable way: if an operation on a value (or a pair of values) is impossible or illogical, then an empty result is returned. Therefore, when adding a number to a string, you can get a string as a result only if the concatenation operation ('~') is used. Otherwise, the result will be an empty value. The priority of operations is determined by the grammar, therefore, no additional checks are required during AST processing.
Filters and Tests
 What other languages call the "standard library" in Jinja2 is called "filters." In essence, a filter is a kind of complex operation on a value to the left of the '|' sign, the result of which will be a new value. Filters can be arranged in a chain by organizing a pipeline:
What other languages call the "standard library" in Jinja2 is called "filters." In essence, a filter is a kind of complex operation on a value to the left of the '|' sign, the result of which will be a new value. Filters can be arranged in a chain by organizing a pipeline: {{ menuItems | selectattr('visible') | map(attribute='title') | map('upper') | join(' -> ') }}
Here, only those elements with the visible attribute set to true will be selected from the menuItems array, then the title attribute will be taken from these elements, converted to upper case, and the resulting list of lines will be glued with a separator ' -> 'in one line. Or, say, as an example from life:
{% macro MethodsDecl(class, access) %}
{% for method in class.methods | rejectattr('isImplicit') | selectattr('accessType', 'in', access) %}
{{ method.fullPrototype }};
{% endfor %}
{% endmacro %}{% macro MethodsDecl(class, access) %}
{{ for method in class.methods | rejectattr('isImplicit') | selectattr('accessType', 'in', access) | map(attribute='fullPrototype') | join(';\n') }};
{% endmacro %}This macro iterates over all the methods of the given class, discards those for which the isImplicit attribute is set to true, selects the remaining ones for which the value of the accessType attribute matches one of the given ones, and displays their prototypes. Relatively clear. And it’s all easier than three-story cycles and if’s to fence. By the way, something similar in C ++ can be done within the range v.3 specification .
Actually, the main miss in time was associated with the implementation of about forty filters, which I included in the basic set. For some reason I took that I could handle it in a week or two. It was too optimistic. And although the typical implementation of the filter is quite simple: take a value and apply some functor to it, there were too many of them, and I had to tinker.
A separate interesting task in the implementation process was the logic of processing arguments. In Jinja2, as in python, arguments passed to the call can be either named or positional. And the parameters in the filter declaration can be either mandatory or optional (with default values). Moreover, unlike C ++, optional parameters can be located anywhere in the ad. It was necessary to come up with an algorithm for combining these two lists, taking into account different cases. Here, for example, is a function of range: range([start, ]stop[, step]). It can be called in the following ways:
range(10) // -> range(start = 0, stop = 10, step = 1)
range(1, 10) // -> range(start = 1, stop = 10, step = 1)
range(1, 10, 3) // -> range(start = 1, stop = 10, step = 3)
range(step=2, 10) // -> range(start = 0, stop = 10, step = 2)
range(2, step=2, 10) // -> range(start = 2, stop = 10, step = 2)Etc. And I would very much like that in the code for implementing the filter function it was not necessary to take all these cases into account. As a result, he settled on the fact that in the filter code, tester or function code, the parameters are obtained strictly by name. And a separate function compares the actual list of arguments with the expected list of parameters along the way by checking that all the required parameters are given in one way or another:
ParsedArguments ParseCallParams(const std::initializer_list& args, const CallParams& params, bool& isSucceeded)
{
struct ArgInfo
{
ArgState state = NotFound;
int prevNotFound = -1;
int nextNotFound = -1;
const ArgumentInfo* info = nullptr;
};
boost::container::small_vector argsInfo(args.size());
boost::container::small_vector posParamsInfo(params.posParams.size());
isSucceeded = true;
ParsedArguments result;
int argIdx = 0;
int firstMandatoryIdx = -1;
int prevNotFound = -1;
int foundKwArgs = 0;
// Find all provided keyword args
for (auto& argInfo : args)
{
argsInfo[argIdx].info = &argInfo;
auto p = params.kwParams.find(argInfo.name);
if (p != params.kwParams.end())
{
result.args[argInfo.name] = p->second;
argsInfo[argIdx].state = Keyword;
++ foundKwArgs;
}
else
{
if (argInfo.mandatory)
{
argsInfo[argIdx].state = NotFoundMandatory;
if (firstMandatoryIdx == -1)
firstMandatoryIdx = argIdx;
}
else
{
argsInfo[argIdx].state = NotFound;
}
if (prevNotFound != -1)
argsInfo[prevNotFound].nextNotFound = argIdx;
argsInfo[argIdx].prevNotFound = prevNotFound;
prevNotFound = argIdx;
}
++ argIdx;
}
int startPosArg = firstMandatoryIdx == -1 ? 0 : firstMandatoryIdx;
int curPosArg = startPosArg;
int eatenPosArgs = 0;
// Determine the range for positional arguments scanning
bool isFirstTime = true;
for (; eatenPosArgs < posParamsInfo.size(); ++ eatenPosArgs)
{
if (isFirstTime)
{
for (; startPosArg < args.size() && (argsInfo[startPosArg].state == Keyword || argsInfo[startPosArg].state == Positional); ++ startPosArg)
;
isFirstTime = false;
continue;
}
int prevNotFound = argsInfo[startPosArg].prevNotFound;
if (prevNotFound != -1)
{
startPosArg = prevNotFound;
}
else if (curPosArg == args.size())
{
break;
}
else
{
int nextPosArg = argsInfo[curPosArg].nextNotFound;
if (nextPosArg == -1)
break;
curPosArg = nextPosArg;
}
}
// Map positional params to the desired arguments
int curArg = startPosArg;
for (int idx = 0; idx < eatenPosArgs && curArg != -1; ++ idx, curArg = argsInfo[curArg].nextNotFound)
{
result.args[argsInfo[curArg].info->name] = params.posParams[idx];
argsInfo[curArg].state = Positional;
}
// Fill default arguments (if missing) and check for mandatory
for (int idx = 0; idx < argsInfo.size(); ++ idx)
{
auto& argInfo = argsInfo[idx];
switch (argInfo.state)
{
case Positional:
case Keyword:
continue;
case NotFound:
{
if (!IsEmpty(argInfo.info->defaultVal))
result.args[argInfo.info->name] = std::make_shared(argInfo.info->defaultVal);
break;
}
case NotFoundMandatory:
isSucceeded = false;
break;
}
}
// Fill the extra positional and kw-args
for (auto& kw : params.kwParams)
{
if (result.args.find(kw.first) != result.args.end())
continue;
result.extraKwArgs[kw.first] = kw.second;
}
for (auto idx = eatenPosArgs; idx < params.posParams.size(); ++ idx)
result.extraPosArgs.push_back(params.posParams[idx]);
return result;
} It is called this way (for, say range):
bool isArgsParsed = true;
auto args = helpers::ParseCallParams({{"start"}, {"stop", true}, {"step"}}, m_params, isArgsParsed);
if (!isArgsParsed)
return InternalValue();and returns the following structure:
struct ParsedArguments
{
std::unordered_map> args;
std::unordered_map> extraKwArgs;
std::vector> extraPosArgs;
ExpressionEvaluatorPtr<> operator[](std::string name) const
{
auto p = args.find(name);
if (p == args.end())
return ExpressionEvaluatorPtr<>();
return p->second;
}
}; the necessary argument from which it is taken simply by its name:
auto startExpr = args["start"];
auto stopExpr = args["stop"];
auto stepExpr = args["step"];
InternalValue startVal = startExpr ? startExpr->Evaluate(values) : InternalValue();
InternalValue stopVal = stopExpr ? stopExpr->Evaluate(values) : InternalValue();
InternalValue stepVal = stepExpr ? stepExpr->Evaluate(values) : InternalValue();A similar mechanism is used when working with macros and testers. And although there seems to be nothing complicated in describing the arguments of each filter and test, there is no (how to implement it), but even the “basic” set, which included about fifty of those and others, turned out to be quite voluminous for implementation. And this provided that it did not include all sorts of tricky things, like formatting strings for HTML (or C ++), outputting values in formats like xml or json, and the like.
In the next part, we will focus on the implementation of work with several templates (export, include, macros), as well as on fascinating adventures with the implementation of error handling and work with strings of different widths.
Traditionally, links: