World of Tanks Server Reliability
Today's topic - the reliability of World of Tanks Server - is quite slippery. The reliability of the game - it is trade off, because in the development of games you need to do everything quickly and quickly change. The load on the servers is large, and users tend to break something just out of interest. Levon Avakian at RHS ++ told what Wargaming is doing to ensure reliability.
Usually, when they talk about reliability, monitoring, load testing, etc. are mentioned all the time. There is nothing supernatural in this, and the report was devoted to moments specific to Tanks.

About Speaker: Levon Avakian works at Wargaming in the position of Head of WoT Game Services and Reliability and deals with the reliability problems of the tank server.
Today I will talk about how we do it, including what the World Of Tanks server is all about, what it consists of, what it is built for so that you understand the subject of conversation. Next, consider what can go wrong inside and around the server itself, because the game is already more than a server. And also let's talk a little bit about the processes, because many people forget that a well-adjusted process in production is part of the success not only in terms of saving resources (many practices came from real production), but it affects the quality and reliability of the solution.

Usually, when they talk about reliability, monitoring, load testing, etc. are mentioned all the time. I didn’t include it here because I think it’s boring. We haven't discovered anything supernatural in this. Yes, we also have a monitoring system, we do load testing with stress tests in order to increase the reliability of the system and know where it can fall off. But today I will talk about what is more specific for tanks.
BigWorld Technology
This backend engine, as well as tools for creating MMO.
This rather old BigWorld Server engine (born in the late 90s - early 2000s) is a collection of various processes that support the game. Processes run on a cluster of machines connected to each other in a network. Interacting with each other, the processes show the user some kind of game mechanics.
The engine is called BigWorld, because it is very good to make games in which there is a large field (space) in which hostilities take place (battles). For Tanks it fits perfectly.
From the point of view of reliability, the following main features were embedded in BigWorld:
- Load balancing The engine allocates resources, trying to achieve two goals:
- use as few cars as possible;
- while not loading their applications so that their load exceeds a certain limit.
- Scalable. We added a car to the cluster, launched processes on it - it means you can cheat more fights and accept players.
- High availability. If, say, one car fell off or something went wrong with one of the game processes that serves the game itself, there is nothing to worry about - the game will not notice, it will be restored in another place and it will work.
- Maintain integrity and consistency of data. This is the second level of fault tolerance. If there are several clusters, like in Tanki, and there was some kind of disaster in the data center or on the backbone channel, this does not mean that we will completely lose the game data that the person played. We will recover, the consistency will be.
Processes that exist in our system and their functions
- CellApp is the process responsible for processing the game space or part of it.
- CellAppMgr is the CellApp coordinating process for load balancing.
- BaseApp manages entities, isolates clients from working with CellApp.
- ServiceApp is a specialized BaseApp that implements some kind of service.
- BaseAppMgr manages BaseApp and ServiceApp because there are too many of them.
- LoginApp creates new connections from clients and also proxies users to BaseApp.
- DBApp implements the storage access interface (databases). We work with Percona, but it could be another database.
- DBAppMgr coordinates DBApp work.
- InterClusterMgr manages intercluster communication.
- Reviewer - process inspector, can restart processes.
- BWMachineD is a daemon that runs on each cluster machine to coordinate its work. It allows all BaseApp managers to communicate with each other.
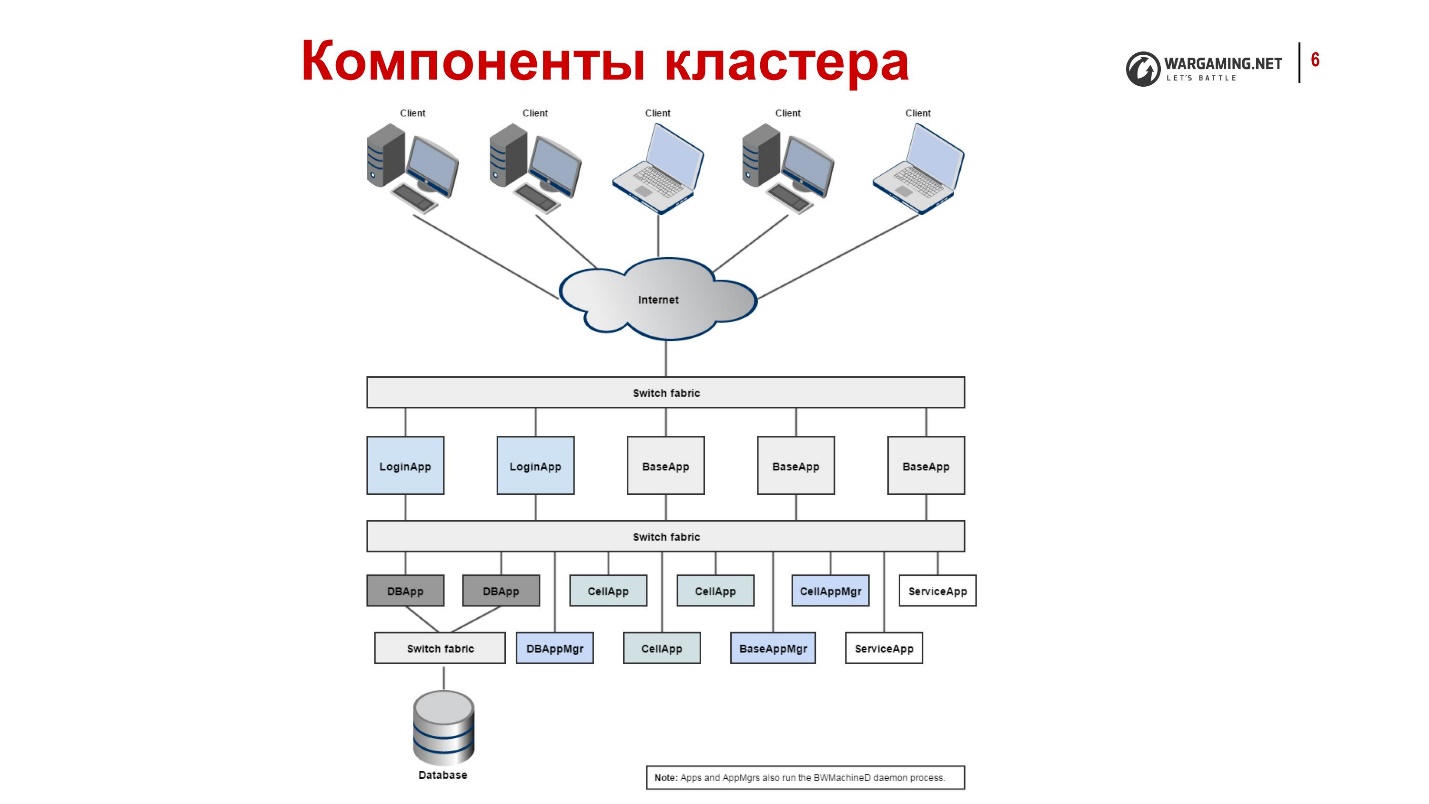
Tanks look like this from the inside, if very briefly:
- Clients connect via the Internet, get on LoginApp.
- LoginApp authorizes them using DBApp and provides an address from BaseApp.
- Then clients play on them.
All this is scattered across a variety of machines, each of which has a BWMachineD that can manage, orchestrate all of this, etc.
Ecosystem World of Tanks
What's around? It would seem that there is a game server and players - chose a tank, went to play. But, unfortunately (or fortunately), the game is developing, and one game mechanic "just shooting" is not enough. Accordingly, the game server has become overgrown with various services, some of which could not be done inside the server at all, while others began to be specially brought out in order to increase the speed of content delivery to the player. That is, it is faster to write a small service in Python that does some kind of game mechanics than to do it inside the server on all BaseAPPs, to support clusters, etc.
Some things, for example, payment systems were originally made. Others we endure, because Wargaming is developing more than one game in the end. This is a trilogy: Tanks, Airplanes, Ships, and there are Blitz and plans for new games. If they were inside BigWorld, then they could not be conveniently used in other products.
Everything went fairly quickly and chaotically, which resulted in some zoo technologies that are used in our tank ecosystem.
The main technologies and protocols:
1. Python 2.7, 3.5;
2. Erlang;
3. Scala;
4. JavaScript;
Framework:
5. Django;
6. Falcon;
7. asyncio;
Storage:
8. Postgres;
9. Percona.
10. Memcached and Redis for caching.
All together for the player this is the tank server:
- Single authorization point;
- Chat;
- Clans;
- Payment system;
- Tournament system;
- Meta Games (Global Map, Fortified Areas);
- Tank Portal, Clan Portal;
- Content management, etc.
But if you look, these are slightly different things written on different technologies. This causes some reliability issues.
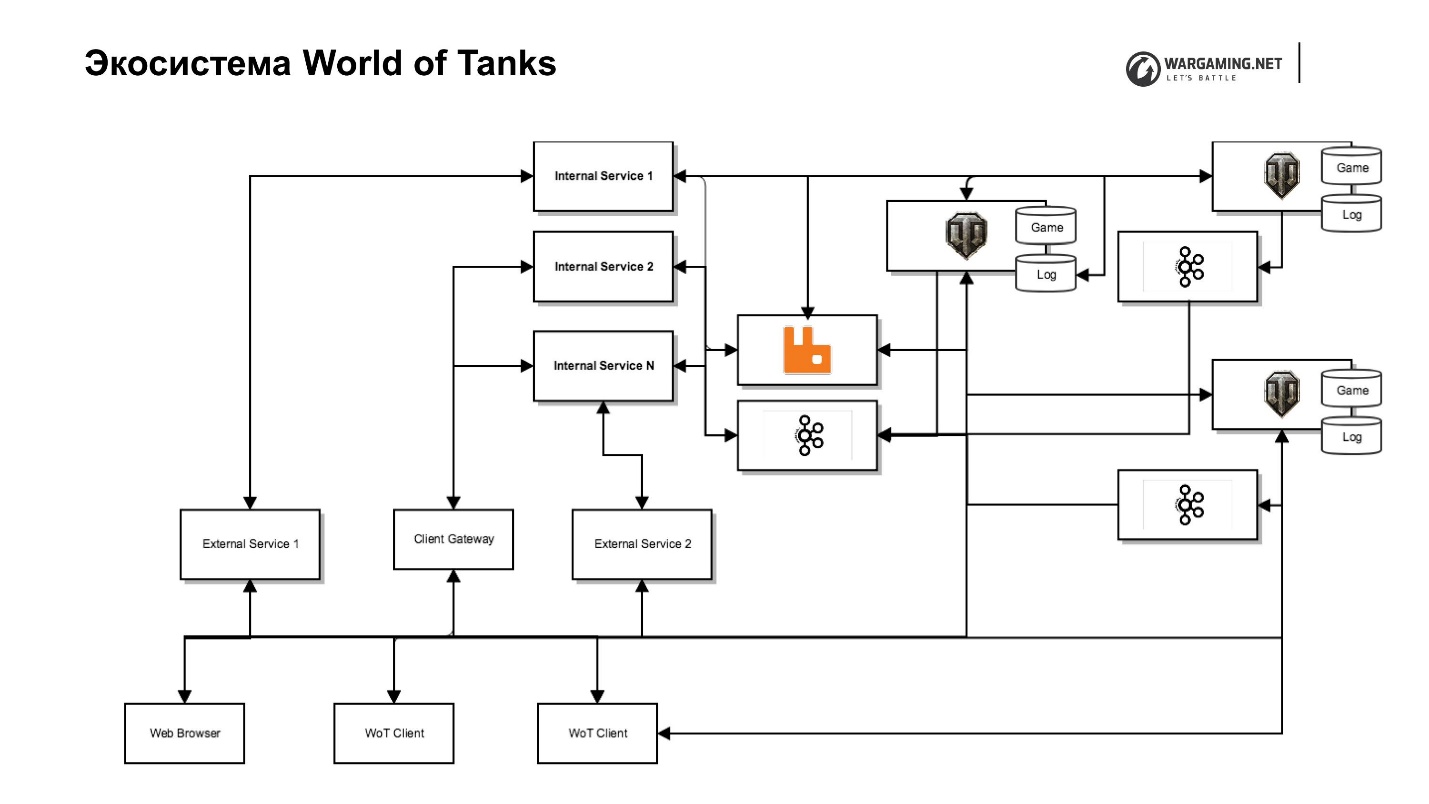
The diagram shows our tank server along with its ecosystem. There is a game server, web-services (internal and external), including very special services that are located in the back-end network and perform service functions, and services for them that actually implement the interfaces. For example, there is a clan service with its own clan portal, which allows you to manage this clan, there is a portal of the game itself, etc.
This separation allows us to worry less about security, because no one has access to the internal network - fewer problems. But this leads to additional efforts, because we need proxies that will give access if we need to throw it outwards.
I have already said that we decided to take a part of the game logic and other things from the server. There was a task to include it all in a client. We have an excellent Client Gateway, which allows a tank client directly, bypassing the server, to access some of the APIs of these Internal Services — the same clans or the API of our meta-games.
Plus, we pushed the Chromium Embedded Framework (CEF) inside the tank client. We now open the same browser. The player does not distinguish it from the game window. This allows you to work with the entire infrastructure, bypassing the work with the game server.
We have a lot of clusters - it turned out - I will tell you later why. This is what the CIS region looks like.
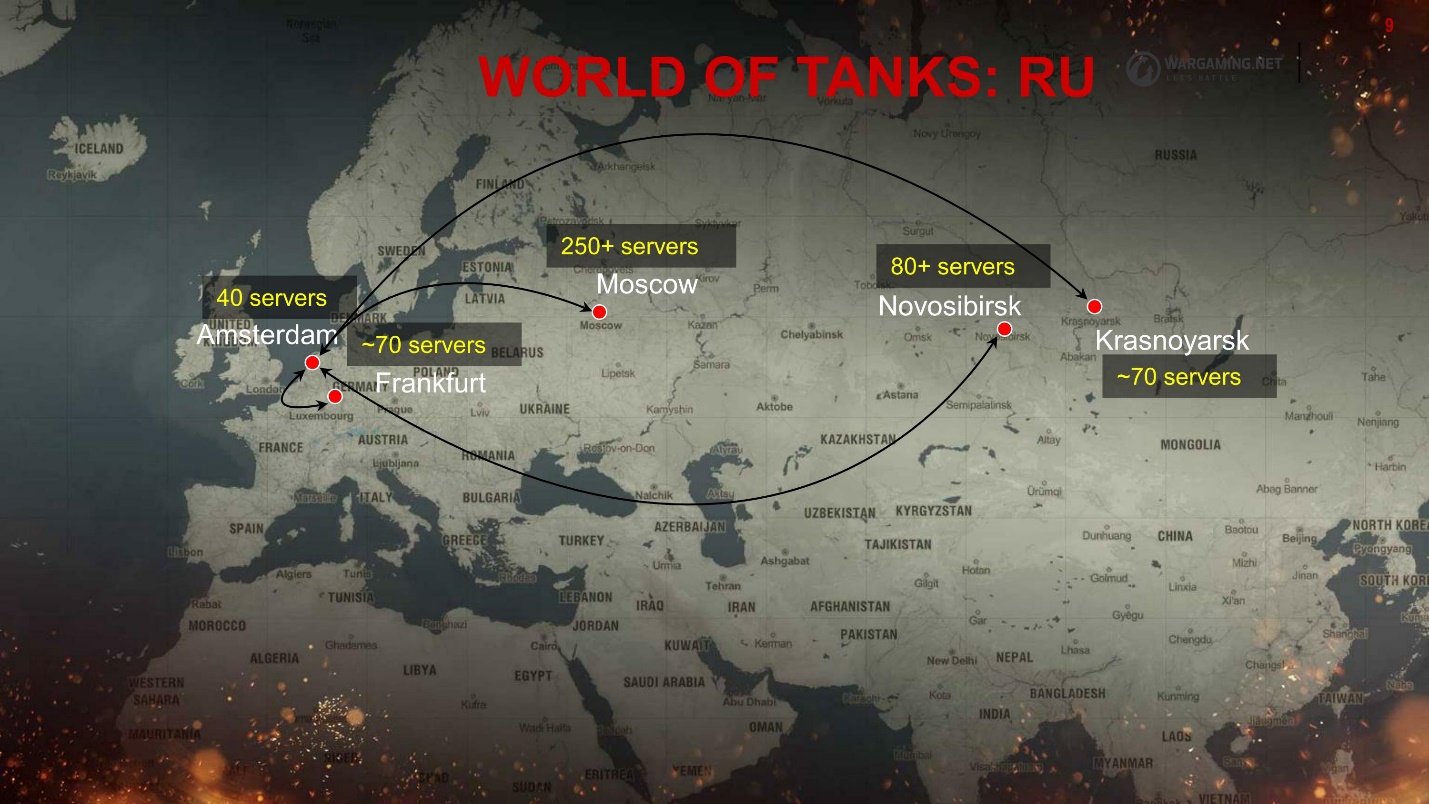
Everything is scattered around the data centers. Players, depending on where the ping is better, are connected to the location. But the whole ecosystem does not scale so much; it is mainly located in Europe and in Moscow, which also adds to us some problems with reliability — extra latency and forwarding.
This is the ecosystem of World of Tanks.
What can go wrong with all this stuff? Anything! And it goes J. But let's break it down into pieces.
The main points of failure within the cluster
Failure of one machine or process
The simplest option that we can predict is the failure of a single machine or process within a cluster. We have clusters from 10 to 100 machines - anything can fly out. As I said, BigWorld itself provides out of the box mechanisms that allow us to be more reliable.
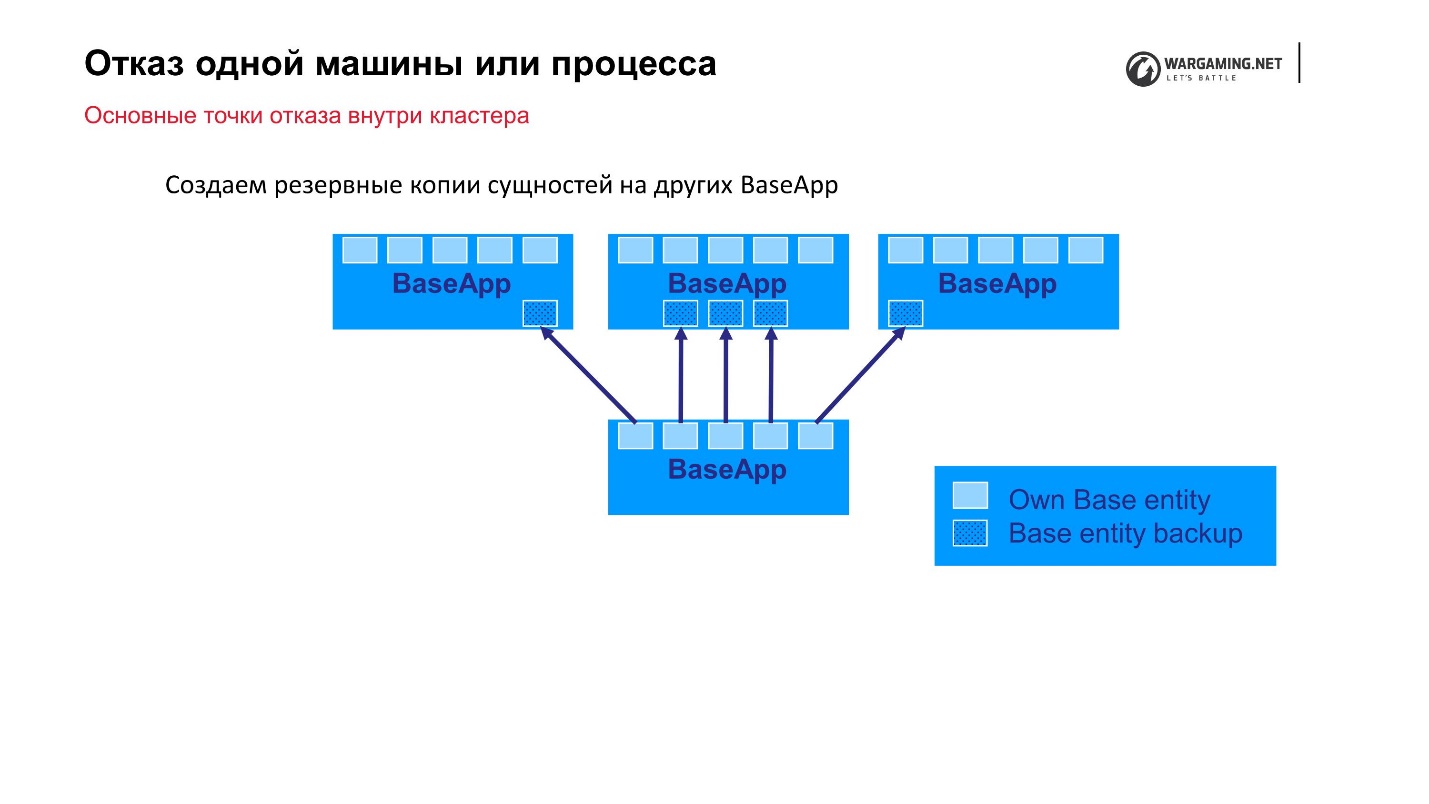
Standard scheme: there are BaseApps that are spread out on different machines. On these BaseApps, there are entities that hold state entities. Each BaseApp backs up itself with Round Robin on others.
Suppose we had a file and some BaseApp died, or the whole car died - no big deal! On the remaining BaseApps, these entities remain, they will be restored, and the gameplay for the player will not suffer.
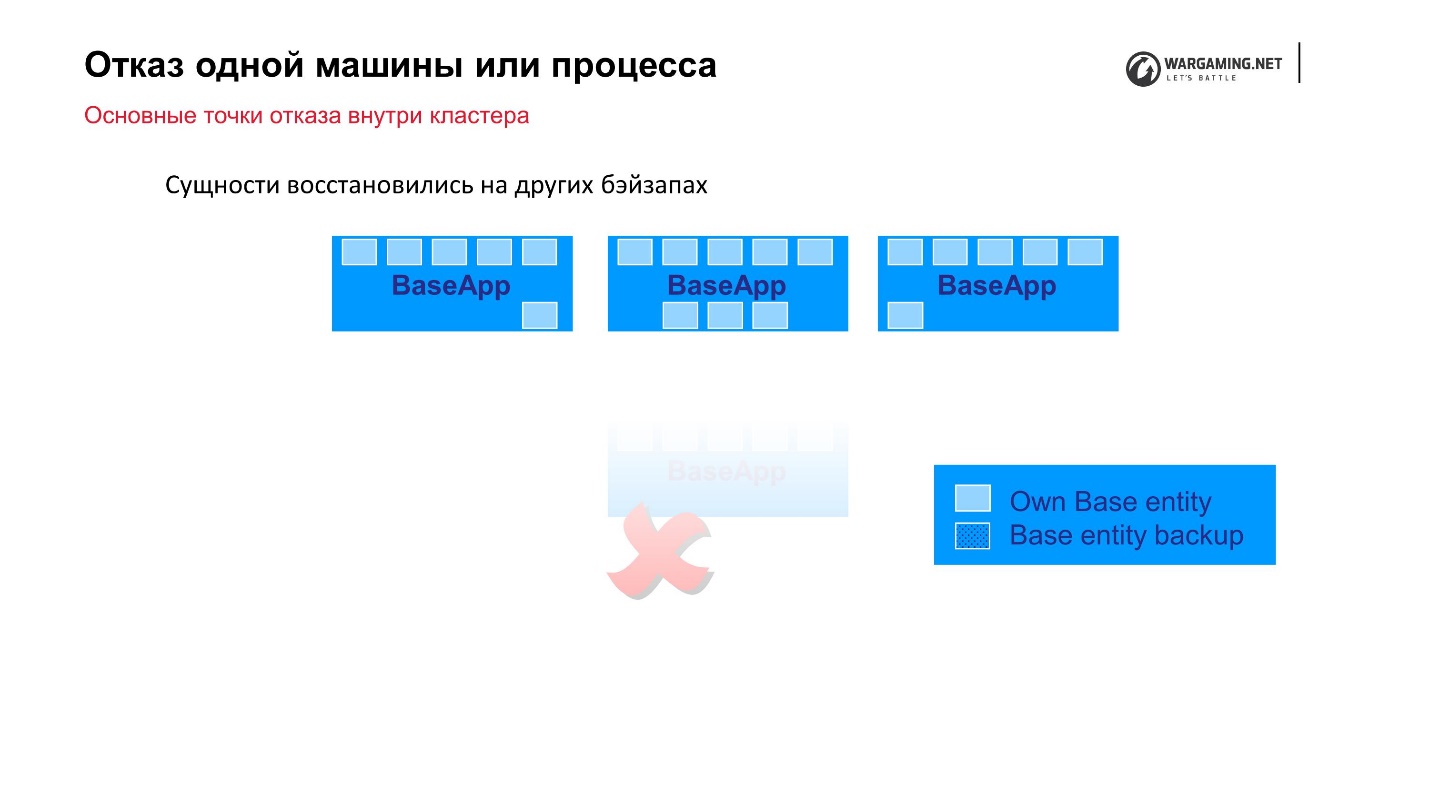
CellAPPs do exactly the same, the only thing is that they store their states on BaseApps too, and not on other CellAPPs.
It seems to be a reliable mechanism, but ...
You have to pay for everything
Over time, we began to observe the following.
• Creating backup copies of entities begins to take away more and more system resources and network traffic.
In fact, the backup process itself begins to affect the stability of the system when, within a cluster, most of the network is busy transmitting copies to Round Robin.
• The size of entities increases over time, as new attributes and game mechanics are added.
But the most unpleasant thing is that the sizes of these entities grow like an avalanche. For example, a player performs some actions (buys gaming property), and this operation has begun to slow down. We have not yet performed it, but have saved the changes to these attributes. That is, the system is so bad, and we are still starting to increase the size of the backup that needs to be done. There is a snowball effect.
• The stability of the system as a whole falls
Due to the fact that we are trying to escape from the fall of a single machine or process, we drop the stability of the entire system.
What have we done to cope with it ? We decided for each entity to allocate what really needs to be backed up. We have divided the attributes into mutable and immutable, and we copy not the entire entity, but make a backup copy of its mutable attributes only. By this we simply reduced the amount of information that really needs to be saved. Now, when adding a new attribute, the one who is involved in this should more clearly look at where it belongs. But in general, the situation has saved us.
If we are to be completely frank, this mechanism is incorporated in BigWorld, but in Tanki at some point it was no longer supported until the end, and not every entity can recover from its backup. In Ships, for example, the guys support it. There you can safely turn off the machine - the information will simply be restored on other machines, and the client will not notice anything. Unfortunately, it is not always the case in Tanki, but we will achieve the return of all this functionality so that it works as it should.
Failure of the data center. Multi-cluster
If suddenly not 1-2 cars fell, but we started to lose the whole data center, that is, the cluster completely, what should the system properties have in order for the game not to fall in such a situation?
- Each cluster must be independent, that is:
- must have its own database;
- The cluster processes only its own spaces (battle arenas).
- Clusters must communicate with each other so that one can say to the second: “I fell!” When it rises, the data will be recovered from saved copies.
- It is also desirable that you can transfer a user from a cluster to a cluster.
At the moment, our multi-cluster scheme looks like this.
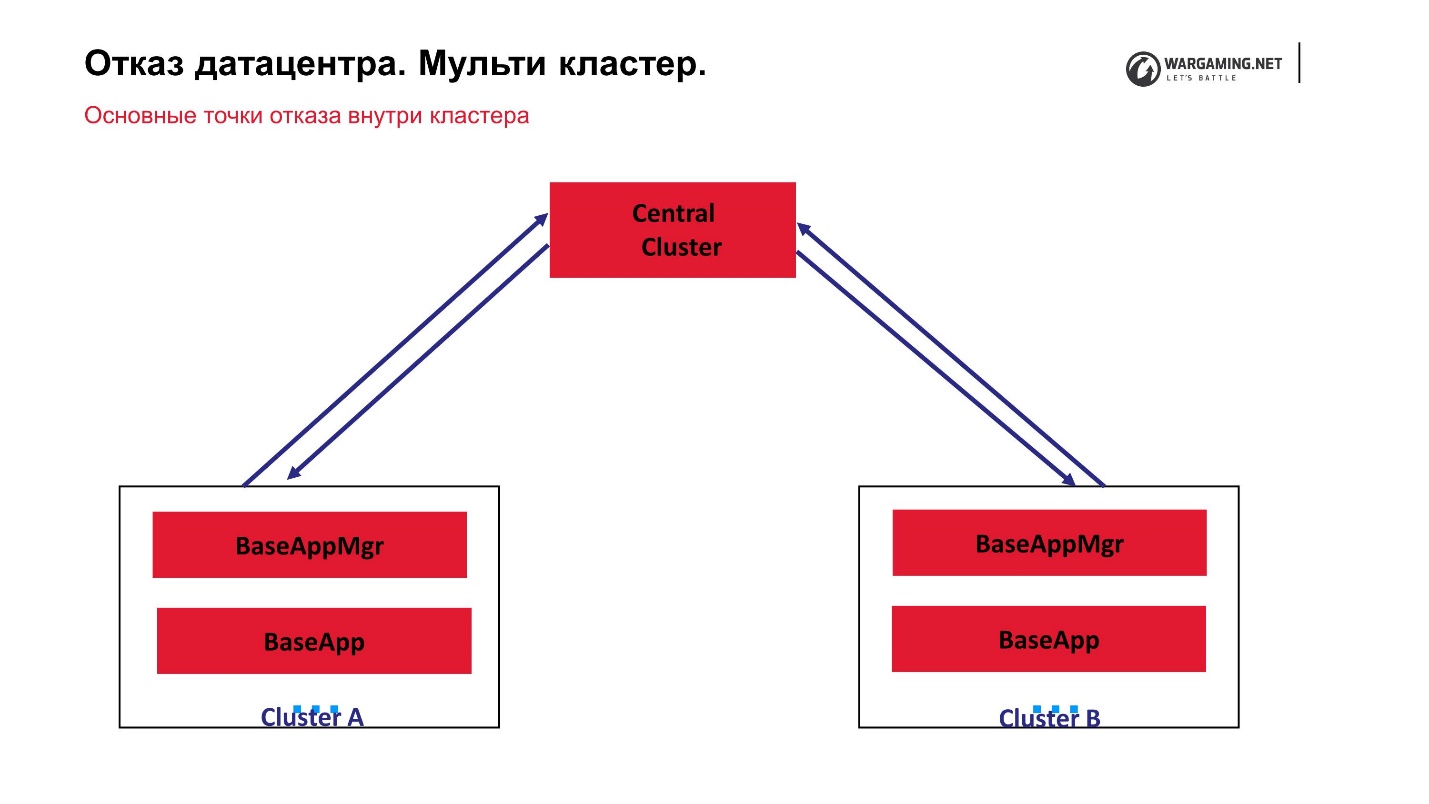
We have a central cluster and what we call peripherals, on which the battles are actually conducted. CellApp is not running on the central cluster, otherwise it is absolutely the same as everyone else. It is the central point of processing accounts: they rise there, are sent to the periphery, and the person already plays on the periphery. That is, the failure of any of the clusters does not lead to the loss of the entire game. Even the failure of the central cluster simply will not allow new players to log in, but those who are already playing on the periphery can continue the game.
The fact that everything works for us through the central cluster turned out because in general the BigWorld technology itself assumes that there is a special managing process inter claster manager. In fact, such inter claster managers can be somewhat raised.
Historically, Tanks need a multi-cluster, because they began to grow online like an avalanche. When we reached the peak of 200 thousand players, the incoming traffic from them simply ceased to fit into the data center over the network. We literally had to come up with a solution on our knees, so that players could be launched into several data centers.
In fact, we only won because we now have a multi-cluster. It also became useful for players, because ping, that is, availability over the network, greatly affects the gameplay. If the delay is more than 50-70 ms, it already begins to affect the quality of the game itself, because in Tanki everything is calculated on the server. There are no calculations on the client. Therefore, please note that there is almost nothing you can do. Of course, some fashions are made there, but they do not affect the process itself. You can try to guess what will happen, but to influence the game-mechanic itself - no.
Due to this approach, our central cluster has become a point of failure.. Everything was closed on it. We decided - since these machines and a large game den base are standing there, let our periphery be engaged exclusively in servicing fights. Then there really is no need to store large amounts of information - the battles themselves are played and played - let's close everything up there.
To rewrite absolutely everything in order to get away from the concept of the central cluster, now there is neither time nor special desire. But we decided, first, to teach peripheral clusters to communicate with each other. Next, we sawed a hole in them so that we could influence them with the help of third-party services.
For example, in order to create a battle earlier, it was necessary to tell the central cluster that it was necessary to create a battle on one of the peripheries. Further, the internal mechanisms of the entity moved, created the essence of the arena, etc.
Now there is an opportunity to directly access the periphery, bypassing the central cluster. So we remove from him extra work. But so far there is no desire to completely switch to a scheme in which all clusters are practically peer-to-peer, and all this is controlled by some processes, but not by a cluster.
I remind you that in addition to the game cluster with its BaseApps, CellApps and the rest, we have an ecosystem.
We try to do so that the performance of the ecosystem does not affect the gameplay. In the worst case, let's say, the tournament system does not work, but you can play random with the game - still, most people play random. Yes, the quality we have lowered, but in general, you can survive a few hours without tournaments.
It doesn't always work that way. First, there are already web services that are deep enough into the game. For example, a single authorization point is a service that allows you to log in on the web or somewhere in one place, and in fact be authorized in the entire Wargaming universe.
The second example is a service that serves game purchases and transactions. He, too, had to be brought inside the game just because we needed to trace the player’s purchases. The fact is that in some regions we are obliged to display information to the client about which gaming property was bought for real money, and which for gaming. The system initially did not anticipate this, no one laid down on it 5 years ago, but the law is harsh: you need to do it - do it .
Points of failure in the World of Tanks ecosystem
Problem number 1. Increased load
We have a multi-cluster, in which 10 clusters with a huge number of machines. The players play them, and the web is small. No one buys five more machines in each data center. But at the same time we provide all the same functionality and everything that is needed right inside the client. This is the main problem.
Interface interactivity and reactivity are the main source of increased stress on the ecosystem.
I will give two examples from the clan service:
- You want to invite another player to the clan. Of course, I want the guest to receive a notification immediately, and he would be able to join you. To implement this, you need to make it so that the clan service somehow could notify the client, or let the client ask the web service from time to time: “Has anything changed? Do I have new invitations? ”This is the first option, where the extra load can come from.
- In the tanks there is a regime of fortified areas. Suppose that not one person plays it, but several. All players have an open window with fortified areas. The commander built the building. It is desirable that everyone who has this open window, the building immediately appeared.
The solution to the forehead with the survey is not very good. In fact, it is working, just the power it needs to allocate so much that this feature will not bring any profit for the company. And if the feature does not bring profit, then it is not necessary to do it.
My personal advice is how to cope with this: the best way to make the system safer under load is to reduce the load altogether somehow logically.
It is not necessary to put iron on it, invent new-fangled systems, optimize something - all the same, the greater the load, the more artifacts will appear from which you cannot escape. And the artifacts will occur at more and lower levels of abstraction - first with applications, then with different web services, then you will go to the network (cisco, etc.). At some level, you simply cannot solve problems.
If you think carefully, you can simply avoid them.
The first thing we did was learn how to notify clients through the game server.using its infrastructure. For example, when an invitation comes to a clan, we say to the server: “We invited such people”, and then the cluster cluster itself finds the person to whom the notification should be sent, especially since they have a connection. That is, we are pushing from the service, and not someone constantly “flashing” us. This allows you to make a service that can send notifications from the ecosystem through the server to the client, which dramatically reduces the load on the ecosystem itself. We can now, throwing notifications to the client, practically manage it from outside.
The second is Web sockets (nginx-pushstream). For example, in fortifications we began to use Web-sockets. As I said, in the client we have the Chromium Embedded Framework - the browser rises when the window opens, Web-sockets connects to Nginx. There is pushstream, which allows us to send changes to the fortified state of a particular player to the Web-sockets connection.
Problem number 2. Difficult data path
The next problem that the infrastructure faces is that the ecosystem is microservices . They are still fashionable, and they used to be fashionable, there are a lot of them - the data path is thorny. And the longer the data path, the more points of failure , cyclic dependencies appear.
Why is this so? There are many options: something has developed historically, something arises, because we are trying to make a decision on the web not only for one game, but for many games. Accordingly, there are some abstractions, interfaces, proxies. This complicates all the work.
In terms of reliability, it looks like this.

I figured that in our ecosystem about 120 services work around Tanks to provide Game Play.. Therefore, the graph is so terrible. I will not touch upon the aspects of building the right architectures here, because this is a given, which I cannot change at all. But I draw your attention to the fact that there are communication channels between all microservices and the server itself. We will talk about them.
Ways of communication
There are 3 main channels that we use:
- HTTP API;
- RabbitMQ - Message Manager;
- Apache Kafka last year used as a tire.
Initially, I planned to compare them, but I, frankly, did not succeed, because this is how to compare a bulldozer, a race car and a tractor. It seems that they are all cars, the goal is the same, plus or minus, to drive, but it's difficult to compare them. Therefore, I had an idea on my own experience from Tanks to tell how to use these communication channels correctly.
Proper use
1. HTTP
The simplest option is HTTP. It is out of the box, always works, native for the web developer, so it is always used here. But it is important to remember the following about him:
- Requests should not be blocking (both on the client and server side).
It is desirable that this be asynchronous if we are talking about a reliable loaded system. There are my favorite incidents, when we have, say, synchronous Django, and one of the 100 or 200 requests that are inside the API, just slows down. Requests clog up all the kernels, the queues start to accumulate, and literally because of the 30-40 requests that users sent in a minute, the whole system is added up. This is a typical case, a typical sore - asynchronism in this sense helps.
- No response or error should be processed.
The second thing that people often forget about when they use HTTP is that it is actually not very reliable. Timeouts and errors need to be handled correctly. It is usually considered - pulled - always received. In my opinion, developers are optimistic, and reliability, on the contrary, suggests pessimism .
- It is necessary to monitor the volume of messages.
This item refers to the previous one. Often the following. There is some kind of service that represents some kind of API - most often it is an API that allows you to retrieve data from a certain database.
I will give an example again from the clans - I talk about them all the time, because I used to work on the reliability of the clans. For example, there is a good query that allows you to get data on the clan. Suppose a developer provides an opportunity to ask about 10 clans, and some bad consumer asks about 100 clans or about 500. Accordingly, you begin to push megabytes of data into one HTTP request. Nginx is bad for this and generally everyone, just because of the timeout you don’t get through - again a crash.
In principle, I have nothing against HTTP, I just need to use it carefully and in the right places.
2. RabbitMQ
By itself, RabbitMQ from the box went to BigWord as a means of communication with the cluster.
- Good to use for smoothing the load.
It works well for us to smooth the load - some peak came, lies in a queue, when we could, read it.
- A good option is "bus" if you have a service that you would like to subscribe to and receive events for.
Again an example about clans: we want to follow the composition of clans. When one service is monitored, it can request via the API: “Give me the clan's membership before the N event and after it — I will handle it.” Then the second service appears, which wants to know about a particular clan, the third, fourth, fifth - as a result, the load on the clan service begins to grow. And you can not especially cache, because it is desirable to give fresh data.
Put a "rabbit", write there "eventiki", everyone willing to subscribe - you removed the load cheaply and reliably enough.
- It is undesirable to accumulate large volumes of messages.
RabbitMQ is good for everyone, but personally I don’t like the fact that when there is a problem with its clustering, if there is a large number of messages in it, it starts to fall apart, and not just falls and lies, but tries to rise.
My advice is do not accumulate large volumes of messages in RabbitMQ for a long time.
3. Kafka
The third way to communicate with the cluster, and within the server to which we arrived, is to use Kafka. This happened because in RabbitMQ you can not keep something for a long time and write large volumes.
- Producer writes a large amount of data.
We had large volumes when we decided to write services around the server, and not inside it, and receive combat statistics. There is a lot of fighting, statistics, too, getting it from the databases is not very convenient. Plus, many services want to do this. It is logical to use Kafka. It is like a big hole - we just write there, and everyone reads.
- Data can not be read immediately.
Plus you can write a lot, the data is stored there for some time. If you fell and could not read them right away, or there is too much data, you need to chew them for a while, then they can be stored for days.
I can talk about Kafka for a long time, we spent a whole year in order to put its use in order so that it became a more or less reliable source of data, and we could rely on it. But this is beyond the scope of this article.
Manager note
Like a little cherry on a cake - how we design Tanks.

Difficulties:
- Tanks makes distributed development . There is the main Minsk team and teams in other locations that make some features, models, etc.
- We have a heterogeneous environment - many teams, languages, technologies, consumers.
- The game industry makes its contribution - business and players demand everything at once , you need to do everything quickly. If you cannot quickly make features, then you will quickly degrade, and players will scatter.
This all puts pressure on the development. We start to score on reliability, as, for example, with entity backups. But this is bad. We seem to be saving, but such things start to accumulate, and as a result, it only gets worse for everyone.
DLC
We came to the conclusion that we invented the DLC (Development Lifecycle) - or rather, did not invent it, but simply fixed it.
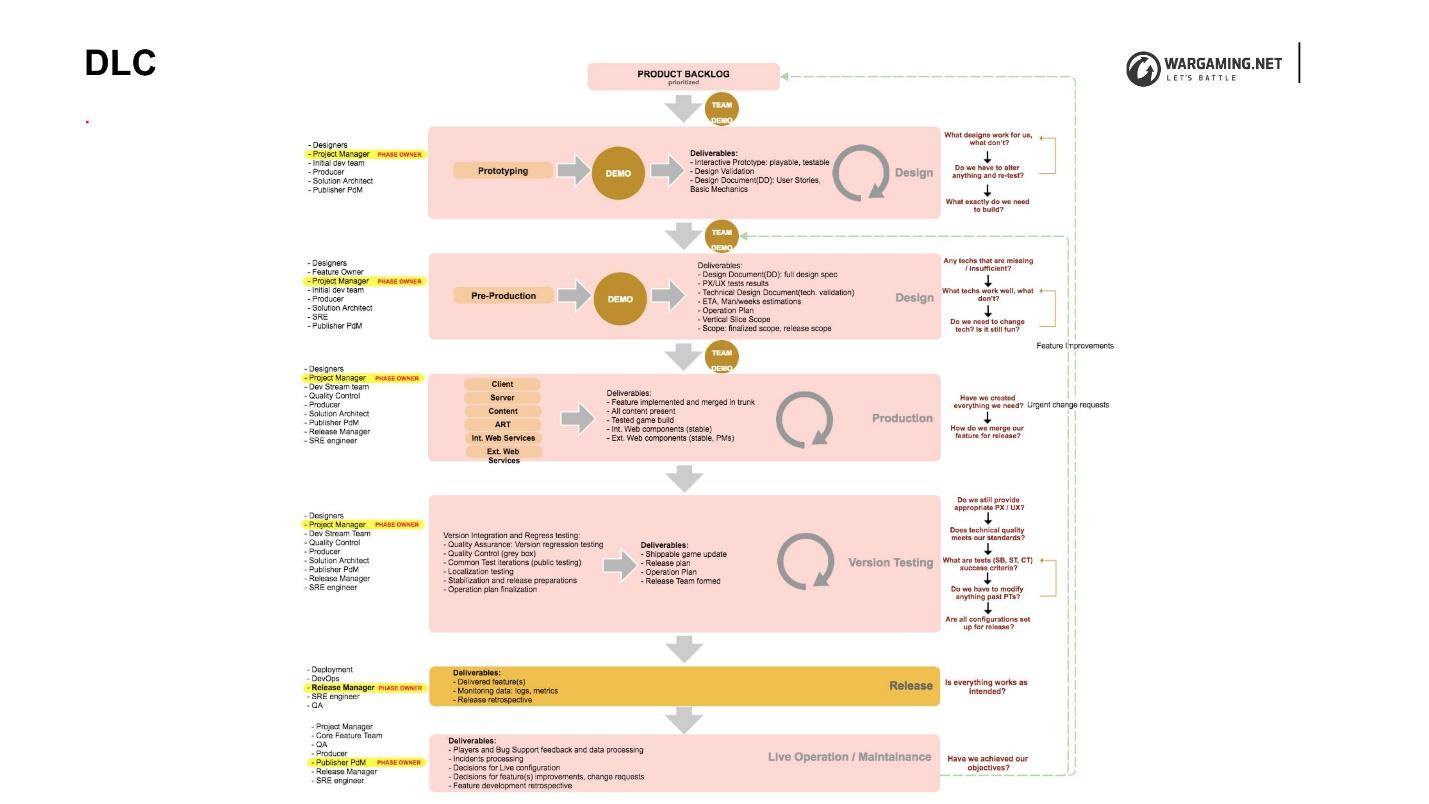
It is quite large and complex, but it is important that it is. DLC consists of phases, and an important aspect in this case is that each of them describes the input and output artifacts. Within the phase, each team can do whatever it wants. The main thing is that she give out at the exit what was agreed upon by everyone inside the tank design, and the company as a whole.
In fact, we are now at the stage of pilot introducing DLC, because there are opponents of this scheme. But on smaller projects, on which I tried to work on such a system, this was more beneficial than negative.
If you are building your DLC, it is worth considering the difficulties we faced:
•Phases should not be missed (even if we are in a hurry and really want to).
If you have agreed on a process, how you will work, even in favor of “very, very necessary, we will finish it later,” the phases should not be missed. You must form a set of artifacts that goes from one command to another, fix, and everyone must agree that they work that way.
• From the very first phase should be involved technical specialists: Architect and SRE.
An important aspect is that the solution-architect, technical-owner, reability-engineers — technical specialists should participate from the very first phase, when pre-production and prototyping go, because often game designers and marketers gush forth with ideas. Ideas seem to be good, it is clear that this is all in order to make the game better and to please the players. But sometimes some little thing, if it does not process a technical specialist, can greatly complicate the system, or simply do not fit into what is already written. Returning back is much more expensive than if we do it right away.
• SRE is involved in all phases.
This item is very similar to the topic of monitoring - which business features we should monitor. If no one asks it at the very initial stage of development, then often no one pledges to it. This is one of the cases why SRE should participate at the pre-production level. SRE should participate in the development itself, because developers always say: “It works for me on a laptop, and what is your capacity, what virtualization you have, how you roll it out - no one is interested!” If you follow right away and do, then it will be easier.
If at the testing stage we work with QA, we help organize load testing, some additional things, for example, testing non-functional requirements, it will also be easier for everyone.
Summarize
BigWorld Technology from the box provides excellent mechanisms to ensure the reliability of the game. We do not fully use them, but we promise. But it still does not save us from problems. There is no “silver bullet” to make the system more reliable.
The principle of "divide and conquer" works fine as long as you control all the components, that is, you actually rule. The second part - “divide” (render, parallelize) - gives a good effect of labor productivity. We can do it faster and better, but from the point of view of reliability, the control becomes much more complicated. Accordingly, somewhere it is necessary to concede.
Bonus: This report was the final on the first day of the festival RIT ++. No one was in a hurry to disperse, and Levon answered questions about reliability for another 40 minutes, and just about Tanks. You can skip right awayat the end of the report and listen, maybe aspects you are interested in were discussed.
The RootConf conference is undergoing rebranding - now it's DevOpsConf Russia . We decided to organize a separate professional conference on DevOps on October 1 and 2 in Moscow , in Infospace. We plan to discuss all topics that are relevant for specialists in information systems. See what applications for reports the Program Committee has received - there is plenty to choose from!