Bidirectional Transactional Data Replication
“MSSQL load balancing on 2 servers”
Good afternoon, hawkers, I decided to write about my story “MSSQL load balancing on 2 servers using bidirectional transactional data replication”. Yes, not just 2 servers, but what would they work like mirrors. Anyone interested, I invite you to read.
Who wants to get down to business immediately
And of course, data replication came to the rescue. After reviewing the types of replication, we went on to consider the architecture that suits us best.
In our case, we were chasing load balancing between 2 servers. Well, we went through the logical chain “load balancing - 2 mirror servers - minimal delays - transactional replication”. And since there
First, in front of me was the type of transactional replication as "Peer-to-peer transactional replication ." I don’t know how many, but I often first look at the topology in the form of a diagram, and then I just read it. This time, again, I got caught on my own mistake.
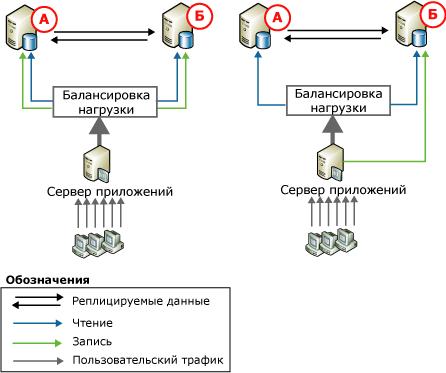
I looked at this topology, well, I liked it that on the left there is a “read-write” to both servers, everything is beautiful, the load is distributed. In the event of a fall, for a while, one server will cope.
Well, for the joys, I began to tune, or rather to read the tuning and try on test bases. First I visited this pageand I really liked the phrase “ When setting up the topology of active databases to add the first and second nodes (node A and node B), the following procedure is used. The next procedure is then used to add the C node and all subsequent nodes . ” In particular, these 2 phrases “ next procedure ” and “ next procedure ” and hereinafter referred to as a three-node peer topology.
And here, by a lucky coincidence, I decided to return to the page with which I started and read about this topology, and again the key phrase “On the left, update operations are partitioned between two servers. If the database contains a product catalog, you can, for example, create a custom application that directs updates of product names starting with letters from "A" to "M" to node A, and updates of products starting with letters from "H" to "Z" "- to node B. Then the updates are replicated to another node ." So this is not at all what I wanted, and that means when the server “A” crashes, there will be only a part of the data.
And again, in sadness and sorrow, a long surf through the expanses of links, although the solution was under my breath. I come across the article " Bidirectional Transactional Replication ". And again a smile on his face, and again his hands are torn into battle. And when I read the settingof this replication, a little smile subsides, and I understand that I don’t understand anything in setting up replication. After several hours of reading, trial and error, the situation begins to clear up. In setting up bi-directional replication, most of it is described in setting up through the procedures, I will show my setup method by which such a topology works for me.
Well, let's get started. I advise you first to do this on test bases . Basically I will throw links, well, and describe the " pitfalls " that may occur on the way
- 1. Configure distribution . Run on both servers (distributor (publisher) and subscriber). In this part, I did not encounter any particular problems, the distribution server and the publisher, in my case the same. When setting the folder for snapshots, you must specify the local folder (specify a link to the shared folder, which will be accessible for both servers). Further, since the publisher and the distributor are the same server, we leave unchanged. And the last thing is to enter the password between the distributor and the publisher (in our case, we will not use the password further).
- 2. Next, add publications and articles (on both servers). "Replication - Local Publications - Create Publication." We select the base, the publication type “Transaction Publishing”, and select the available objects, you can skip the agent configuration, and fill out the agent’s security.PebbleOne of the conditions of the article is the Primary Key in the table.
When creating a Primary key, I advise you to check that there is no clustered index by the key field, and if so, delete it. When creating a key, this index will be created, and if you do not delete it, it will no longer be clustered and data processing will be increased due to the presence of 2 identical indexes. - 3. At the stage of creating subscriptions, I was confused at the beginning, but I will try to explain clearly.
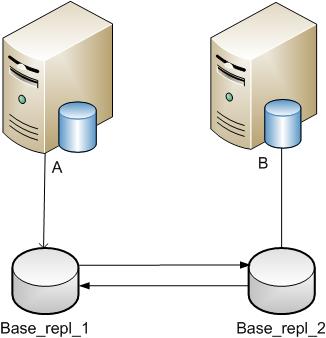
Let's start sequentially:- On server A:(1) Create a subscription procedure
EXEC sp_addsubscription @publication = 'А_ Base_repl_1', --Имя публикации на текущем сервере созданной на шаге 2. @article = N'all', @subscriber = 'B', -- Имя сервера подписки @destination_db = N'Base_repl_2', --Имя базы на сервере B @sync_type = N'none', @status = N'active', @update_mode = N'read only', @loopback_detection = 'true'; -- параметр двунаправленной публикации.(2) Turn on the agentEXEC sp_addpushsubscription_agent @publication = 'А_ Base_repl_1', -- Имя публикации на текущем сервере созданной на шаге 2. @subscriber = 'B', --Имя сервера подписки A @subscriber_db = N'Base_repl_2', --Имя базы на сервера подписки @job_login = 'domain\user', --логин домена @job_password = 'pass'; --пароль домена - On server B:(1) Create a subscription procedure
EXEC sp_addsubscription @publication = 'B_ Base_repl_2', --Имя публикации на текущем сервере созданной на шаге 2. @article = N'all', @subscriber = 'A', -- Имя сервера подписки @destination_db = N'Base_repl_1', --Имя базы на сервере B @sync_type = N'none', @status = N'active', @update_mode = N'read only', @loopback_detection = 'true'; -- параметр двунаправленной публикации.(2) Turn on the agentEXEC sp_addpushsubscription_agent @publication = 'B_ Base_repl_2', -- Имя публикации на текущем сервере созданной на шаге 2. @subscriber = 'A', --Имя сервера подписки A @subscriber_db = N'Base_repl_1', --Имя базы на сервера подписки @job_login = 'domain\user', --логин домена @job_password = 'pass'; --пароль домена
- On server A:
- 4. To create stored procedures used for articles, you can use the article . I think it is not in demand, since for each table manually creating 3 procedures (ins, upd, del) is very expensive. Therefore, I used the following sp_scriptpublicationcustomprocs procedure
on Server A:sp_scriptpublicationcustomprocs @publication ='А_ Base_repl_1' -- Имя публикации на текущем сервере
then we copy the result of the procedure and execute it on server “B” in the database “Base_repl_2”
on server B:sp_scriptpublicationcustomprocs @publication ='B_ Base_repl_2' -- Имя публикации на текущем сервере
then we copy the result of the procedure and execute it on server “A” in the database “Base_repl_1”
Well, that’s all. I will be glad to any advice and criticism.