Switch for strings in C ++ 11
Unfortunately, the C ++ standard does not allow switch-case statements to be applied to string constants. Although in other languages, such as C #, this feature is available directly out of the box. Therefore, of course, many C ++ programmers tried to write their own version of “switch for strings” - and I am no exception.
For C ++ 03, the solutions did not differ in beauty and only complicated the code, additionally loading the application in runtime. However, with the advent of C ++ 11, it finally became possible to implement such code:
The implementation of this design is very simple. It is based on constexpr functions from C ++ 11, due to which almost all calculations are performed at the compilation stage. If someone is interested in its details, welcome to kat - the benefit on Habr about "switch for lines" for some reason does not say anything.
First of all, that it was a full-fledged switch , and not its “emulation” by hiding if-statements and functions for comparing strings inside macros, since comparing strings in runtime is an expensive operation, and it’s too wasteful for each line from CASE. Therefore, such a solution will not suit us - in addition, incomprehensible macros like END_STRING_SWITCH will inevitably appear in it.
In addition, it is very desirable to maximize the use of the compiler. For example, what will happen to a “normal” switch-case when the arguments of the two cases turn out to be the same? That's right, the compiler immediately scolds us: "duplicate case value", and stop compiling. And in the example at the above link, of course, no compiler can notice this error.
The final syntax is also important, simple and without unnecessary constructions. That is why the well-known version of " std :: map with a string key" does not suit us either: firstly, the case arguments in it do not look visual - and secondly, it requires mandatory initialization of the used std :: map in runtime. The function of this initialization can be anywhere, constantly looking into it is too tedious.
The last option remains: compute the hash of the string in switch , and compare it with the hash of each string in case . That is, it all comes down to comparing two integers for which the switch-case works great. However, the C ++ standard says that the argument of each case should be known even at compilation time - therefore, the function of "computing the hash from the string" should work in compile-time. In C ++ 03, it can only be implemented using templates, similar to CRC calculations in this article . But in C ++ 11, fortunately, more comprehensible constexpr functions appeared, the values of which can also be calculated by the compiler.
So, we need to write a constexpr function that would operate with char numeric codescharacters. As you know, the body of such a function is " return <expression known in compile-time> ". Let's try to implement its most “degenerate” version, namely, a function for calculating the length of const char * of a string. But already here the first difficulties await us:
The compiler does not swear, the function is correct. However, for some reason, she didn’t bring “6 6” to me, but “6 12”. Why so? And the thing is that I typed this source code under Windows in the "Linux" encoding UTF-8, and not in the standard Win-1251 - and therefore each "Cyrillic" character was perceived as two. Now, if you change the encoding to standard, then "6 6" will really be displayed. So it turns out our idea crashed? After all, this is not the case when different hashes produce different hashes ...
But why do we need Cyrillic or Asian characters? In the vast majority of cases, only English letters and standard punctuation characters are sufficient for the source code - that is, characters that fit in the range from 0 to 127 in the ASCII table . And their char codes will not change when changing the encoding - and therefore the hash from a string composed only of them will always be the same. But what if the programmer accidentally enters one of these characters? The following compile-time function comes to the rescue:
It checks if the string known at the compilation stage contains only characters from the range 0-127, and returns false if a “forbidden” character is found. Why do I need a forced cast to signed char ? The fact is that the C ++ standard does not specify what exactly the char type is - it can be either signed or unsigned. But its sizeof will always be equal to 1, which is why we are shifting to the right by one. Thus, the CASE macro we need will look like:
Here one more feature of C ++ 11 is used - assert at compilation. That is, if the argument string of the CASE macro contains at least one “forbidden” character, compilation will stop with a completely understandable error. Otherwise, a hash will be computed, the value of which will be substituted into case . This solution will save us from encoding problems. It remains only to write the str_hash () function itself, which will calculate the desired hash.
You can choose a hash function in different ways, and the most important question here is the possibility of collisions. If the hashes of two different lines match, then the program can jump from switch to a false case- tree. And the satellite will fall into the ocean ... Therefore, we will use a hash function that does not have collisions at all. Since we have already found that all the characters in the string are located in the range of 0-127, the function will be as follows: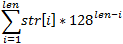 . Its implementation is as follows:
. Its implementation is as follows:
Here, raise_128_to () is the compile-time function of raising 128 to a power, and current_len is the length of the current line. Of course, the length can be calculated at each step of the recursion, but this will only slow down the compilation - it is better to count it before the first start of str_hash (), and then always substitute it as an additional argument. At what maximum line length does this function have no collisions? Obviously, only when the value obtained by it always fits in a range of type unsigned long long (also finally introduced in C ++ 11), that is, if it does not exceed 2 64 -1.
It can be calculated that this maximum length will be 9 (denote this number as MAX_LEN). But the maximum possible value of the hash will be exactly 2 63for a string, all characters of which have the code 127 (and are unreadable in ASCII, so under CASE we still will not drive it). But what if under CASE there will be a string of 10 characters? If we really do not want collisions, then we need to prohibit such a possibility - that is, to expand the static_assert that we already use :
All done with the CASE macro. It will either give us a compilation error or compute a unique hash value. Here, to calculate the hash in the SWITCH macro, we have to make a separate function, since it will work already in runtime. And if its argument string will have a length of more than 9 characters, then we will agree to return 2 64 -1 (we denote this number as N_HASH). So:
That's all. In runtime, the hash for the string in SWITCH will be calculated, and if one string in CASE has the same hash, execution will go to it. If some line from CASE contains “forbidden” characters, or its length is more than 9 characters, we will get a reliable compilation error. There is almost no load in runtime (with the exception of a single hash calculation for SWITCH), the readability of the code does not suffer. It remains only to overload the str_hash_for_switch () function for std :: string strings , and wrap everything inside the namespace.
The final source h-file is on Github . It is suitable for any compiler with C ++ 11 support. To use "switch for strings" just do the inclusion str_switch.hwherever you want, that's all - the SWITCH, CASE, and DEFAULT macros are in front of you. Do not forget about the string length limit in CASE (9 characters).
In general - I hope this implementation is useful to someone;)
PS Upd: a couple of inaccuracies were found in the code - so now it is updated, along with the article. The comments also suggested using another function to calculate the hash - of course, everyone can write their implementation.
For C ++ 03, the solutions did not differ in beauty and only complicated the code, additionally loading the application in runtime. However, with the advent of C ++ 11, it finally became possible to implement such code:
std::string month;
std::string days;
std::cout << "Enter month name: ";
std::cin >> month;
SWITCH (month)
{
CASE("february"):
days = "28 or 29";
break;
CASE("april"):
CASE("june"):
CASE("september"):
CASE("november"):
days = "30";
break;
CASE("january"):
CASE("march"):
CASE("may"):
CASE("july"):
CASE("august"):
CASE("october"):
CASE("december"):
days = "31";
break;
DEFAULT:
days = "?";
break;
}
std::cout << month << " has " << days << " days." << std::endl;
The implementation of this design is very simple. It is based on constexpr functions from C ++ 11, due to which almost all calculations are performed at the compilation stage. If someone is interested in its details, welcome to kat - the benefit on Habr about "switch for lines" for some reason does not say anything.
What do we want?
First of all, that it was a full-fledged switch , and not its “emulation” by hiding if-statements and functions for comparing strings inside macros, since comparing strings in runtime is an expensive operation, and it’s too wasteful for each line from CASE. Therefore, such a solution will not suit us - in addition, incomprehensible macros like END_STRING_SWITCH will inevitably appear in it.
In addition, it is very desirable to maximize the use of the compiler. For example, what will happen to a “normal” switch-case when the arguments of the two cases turn out to be the same? That's right, the compiler immediately scolds us: "duplicate case value", and stop compiling. And in the example at the above link, of course, no compiler can notice this error.
The final syntax is also important, simple and without unnecessary constructions. That is why the well-known version of " std :: map with a string key" does not suit us either: firstly, the case arguments in it do not look visual - and secondly, it requires mandatory initialization of the used std :: map in runtime. The function of this initialization can be anywhere, constantly looking into it is too tedious.
Start to calculate the hash
The last option remains: compute the hash of the string in switch , and compare it with the hash of each string in case . That is, it all comes down to comparing two integers for which the switch-case works great. However, the C ++ standard says that the argument of each case should be known even at compilation time - therefore, the function of "computing the hash from the string" should work in compile-time. In C ++ 03, it can only be implemented using templates, similar to CRC calculations in this article . But in C ++ 11, fortunately, more comprehensible constexpr functions appeared, the values of which can also be calculated by the compiler.
So, we need to write a constexpr function that would operate with char numeric codescharacters. As you know, the body of such a function is " return <expression known in compile-time> ". Let's try to implement its most “degenerate” version, namely, a function for calculating the length of const char * of a string. But already here the first difficulties await us:
constexpr unsigned char str_len(const char* const str)
{
return *str ? (1 + str_len(str + 1)) : 0;
}
std::cout << (int) str_len("qwerty") << " " << (int) str_len("йцукен") << std::endl; // проверяем
The compiler does not swear, the function is correct. However, for some reason, she didn’t bring “6 6” to me, but “6 12”. Why so? And the thing is that I typed this source code under Windows in the "Linux" encoding UTF-8, and not in the standard Win-1251 - and therefore each "Cyrillic" character was perceived as two. Now, if you change the encoding to standard, then "6 6" will really be displayed. So it turns out our idea crashed? After all, this is not the case when different hashes produce different hashes ...
Check the contents of the string
But why do we need Cyrillic or Asian characters? In the vast majority of cases, only English letters and standard punctuation characters are sufficient for the source code - that is, characters that fit in the range from 0 to 127 in the ASCII table . And their char codes will not change when changing the encoding - and therefore the hash from a string composed only of them will always be the same. But what if the programmer accidentally enters one of these characters? The following compile-time function comes to the rescue:
constexpr bool str_is_correct(const char* const str)
{
return (static_cast(*str) > 0) ? str_is_correct(str + 1) : (*str ? false : true);
}
It checks if the string known at the compilation stage contains only characters from the range 0-127, and returns false if a “forbidden” character is found. Why do I need a forced cast to signed char ? The fact is that the C ++ standard does not specify what exactly the char type is - it can be either signed or unsigned. But its sizeof will always be equal to 1, which is why we are shifting to the right by one. Thus, the CASE macro we need will look like:
#define CASE(str) static_assert(str_is_correct(str), "CASE string contains wrong characters");\
case str_hash(...)
Here one more feature of C ++ 11 is used - assert at compilation. That is, if the argument string of the CASE macro contains at least one “forbidden” character, compilation will stop with a completely understandable error. Otherwise, a hash will be computed, the value of which will be substituted into case . This solution will save us from encoding problems. It remains only to write the str_hash () function itself, which will calculate the desired hash.
Back to hash calculation
You can choose a hash function in different ways, and the most important question here is the possibility of collisions. If the hashes of two different lines match, then the program can jump from switch to a false case- tree. And the satellite will fall into the ocean ... Therefore, we will use a hash function that does not have collisions at all. Since we have already found that all the characters in the string are located in the range of 0-127, the function will be as follows:
. Its implementation is as follows: typedef unsigned char uchar;
typedef unsigned long long ullong;
constexpr ullong str_hash(const char* const str, const uchar current_len)
{
return *str ? (raise_128_to(current_len - 1) * static_cast(*str)
+ str_hash(str + 1, current_len - 1)) : 0;
}
Here, raise_128_to () is the compile-time function of raising 128 to a power, and current_len is the length of the current line. Of course, the length can be calculated at each step of the recursion, but this will only slow down the compilation - it is better to count it before the first start of str_hash (), and then always substitute it as an additional argument. At what maximum line length does this function have no collisions? Obviously, only when the value obtained by it always fits in a range of type unsigned long long (also finally introduced in C ++ 11), that is, if it does not exceed 2 64 -1.
It can be calculated that this maximum length will be 9 (denote this number as MAX_LEN). But the maximum possible value of the hash will be exactly 2 63for a string, all characters of which have the code 127 (and are unreadable in ASCII, so under CASE we still will not drive it). But what if under CASE there will be a string of 10 characters? If we really do not want collisions, then we need to prohibit such a possibility - that is, to expand the static_assert that we already use :
#define CASE(str) static_assert(str_is_correct(str) && (str_len(str) <= MAX_LEN),\
"CASE string contains wrong characters, or its length is greater than 9");\
case str_hash(str, str_len(str))
We make the finishing touches
All done with the CASE macro. It will either give us a compilation error or compute a unique hash value. Here, to calculate the hash in the SWITCH macro, we have to make a separate function, since it will work already in runtime. And if its argument string will have a length of more than 9 characters, then we will agree to return 2 64 -1 (we denote this number as N_HASH). So:
#define SWITCH(str) switch(str_hash_for_switch(str))
const ullong N_HASH = static_cast(-1); // по аналогии с std::string::npos
inline ullong str_hash_for_switch(const char* const str)
{
return (str_is_correct(str) && (str_len(str) <= MAX_LEN)) ? str_hash(str, str_len(str)) : N_HASH;
}
That's all. In runtime, the hash for the string in SWITCH will be calculated, and if one string in CASE has the same hash, execution will go to it. If some line from CASE contains “forbidden” characters, or its length is more than 9 characters, we will get a reliable compilation error. There is almost no load in runtime (with the exception of a single hash calculation for SWITCH), the readability of the code does not suffer. It remains only to overload the str_hash_for_switch () function for std :: string strings , and wrap everything inside the namespace.
The final source h-file is on Github . It is suitable for any compiler with C ++ 11 support. To use "switch for strings" just do the inclusion str_switch.hwherever you want, that's all - the SWITCH, CASE, and DEFAULT macros are in front of you. Do not forget about the string length limit in CASE (9 characters).
In general - I hope this implementation is useful to someone;)
PS Upd: a couple of inaccuracies were found in the code - so now it is updated, along with the article. The comments also suggested using another function to calculate the hash - of course, everyone can write their implementation.