What is TCHAR, WCHAR, LPSTR, LPWSTR, LPCTSTR (etc.)
- Tutorial

Many C ++ Windows programmers often get confused by these strange identifiers like TCHAR, LPCTSTR. In this article I will try in the best way to dot all I. And dispel the fog of doubt.
At one time, I spent a lot of time delving into the source code and did not understand what these mysterious TCHAR, WCHAR, LPSTR, LPWSTR, LPCTSTR mean.
Recently I found a very competent article and present its high-quality translation.
The article is recommended for those who sleep in C ++ codes sleepless nights.
You are interested ??
I ask for a cat !!!
In general, a string character can be represented as 1 byte and 2 bytes.
Typically, a single-byte character is an ANSI character encoding — all English characters are represented in this encoding. A 2-byte character is UNICODE encoding, in which all other languages in the world can be represented.
The Visual C ++ compiler supports char and wchar_t as built-in data types for ANSI and UNICODE encodings. Although there is a more specific Unicode definition, for understanding, Windows uses exactly 2 byte encoding for many language applications support.
Unicode Microsoft Windows uses UTF16 encoding to represent a 2-byte encoding.
Microsoft was one of the first companies to start implementing Unicode support in its operating systems (the Windows NT family).
What if you want your C / C ++ code to be independent of encodings and using different encoding modes?
TIP. Use common data types and names to represent characters and strings.
For example, instead of changing the following code:
char cResponse; // 'Y' or 'N'
char sUsername[64];
// str* functions (с типом char работают функции который начинаются с префикса str*)
On this!!!
wchar_t cResponse; // 'Y' or 'N'
wchar_t sUsername[64];
// wcs* functions (с типом wchar_t работают функции который начинаются с префикса wcs*)
In order to support multilingual applications (e.g. Unicode), you can write code in a more general manner.
#include // Implicit or explicit include
TCHAR cResponse; // 'Y' or 'N'
TCHAR sUsername[64];
// _tcs* functions (с типом TCHAR работают функции который начинаются с префикса _tcs*)
In the project settings, on the GENERAL tab, there is a CHARACTER SET parameter which indicates in which encoding the program will be compiled:
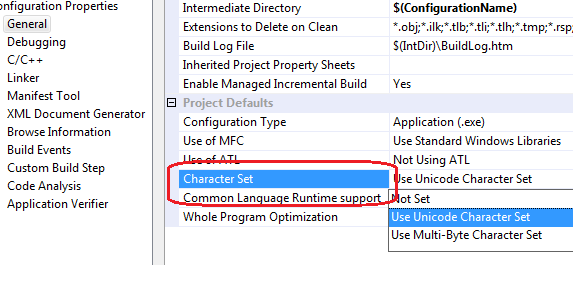
If the parameter “Use Unicode Character set” is specified, the TCHAR type will be translated into the wchar_t type. If the parameter "Use Multi-byte character set" is specified then TCHAR will be translated to type char. You can freely use the char and wchar_t types, and the project settings will in no way affect the use of these keywords.
TCHAR is defined as follows:
#ifdef _UNICODE
typedef wchar_t TCHAR;
#else
typedef char TCHAR;
#endif
The _UNICODE macro will be included if you specify “Use Unicode Character set” and then the TCHAR type will be defined as wchar_t. When you specify "Use Multi-byte character set" TCHAR will be defined as char.
In addition, in order to support multiple character sets using a common base code, and possibly support many language applications, use Specific Functions (i.e. macros).
Instead of using strcpy, strlen, strcat (including protected variants of the function with the _s prefix), or wcscpy, wcslen, wcscat (including protected variants), you better use the _tcscpy, _tcslen, _tcscat functions.
As you know, the strlen function is described like this:
size_t strlen(const char*);
And the wcslen function is described like this:
size_t wcslen(const wchar_t* );
You are better off using _tcslen, which is logically described like this:
size_t _tcslen(const TCHAR* );
WC is a Wide Character. Therefore, wcs functions will be for wide-character-string (that is, for large-character-string). Thus _tcs will mean _T character string. And as you know, lines with the _T prefix can be of type char or wchar_t.
But in reality, _tcslen (and other functions prefixed with _tcs) are not functions at all, they are macros. They are simply described as:
#ifdef _UNICODE
#define _tcslen wcslen
#else
#define _tcslen strlen
#endif
You can look at the header file TCHAR.H and look there for Macro descriptions similar to the above.
Thus, TCHAR is not a type at all, but an add-on on char and wchar_t types. Allowing us to choose a multi-language application, we will have, or all the same, one language.
You may ask why they are described as macros, and not as a full-fledged function ??
The reason is simple: A library or DLL can export a simple function with the same name and prototype (Excluding the concept of overloading in C ++).
For example, if you export a function:
void _TPrintChar(char);
How should her client call ?? How:
void _TPrintChar(wchar_t);
_TPrintChar can be magically converted to a function accepting a two byte character as an argument.
To do this, we will make two different functions:
void PrintCharA(char); // A = ANSI ( для однобайтового)
void PrintCharW(wchar_t); // W = Wide character (для двухбайтового)
And a simple macro will hide the difference between the two:
#ifdef _UNICODE
void _TPrintChar(wchar_t);
#else
void _TPrintChar(char);
#endif
The client will simply call the function as
TCHAR cChar;
_TPrintChar(cChar);
Note that TCHAR and _TPrintChar will now be comparable to UNICODE or ANSI, and the cChar variable and function parameter will be comparable to char or wchar_t data type.
Macros allow us to get around these difficulties, and allow us to use the ANSI or UNICODE functions for our characters and strings. Many Windows functions are described in this way, and for the programmer there is only one function (that is, a macro) and this is good.
I will give an example with SetWindowText:
// WinUser.H
#ifdef UNICODE
#define SetWindowText SetWindowTextW
#else
#define SetWindowText SetWindowTextA
#endif // !UNICODE
There are only a few functions that do not have such macros, and they are only with the suffix W or A. An example is the ReadDirectoryChangesW function, which has no equivalent in ANSI encodings.
As you know, we use double quotes to represent strings. The string represented in this manner is an ANSI string, 1 byte is used per character. I will give an example:
“Это ANSI строка. Каждый символ занимает 1 байт.”
The line above is not a UNICODE line, and is not suitable for many language support. In order to get a UNICODE string you need to use the prefix L.
I will give an example:
L”Это Unicode строка. Каждый символ которого занимает 2 байта, включая пробелы. ”
Put L in front and you get a UNICODE string. All characters (I repeat all characters) occupy 2 bytes, including English letters, spaces, numbers and the null character. The data volume of a Unicode string will always be a multiple of 2 bytes. A 7-character Unicode string will occupy 14 bytes. If a Unicode string takes 15 bytes then this is not a valid string, and it will not work in any context.
Also, the string will be a multiple of sizeof (TCHAR) in bytes.
When you need hard-coded code, you can write code like this:
"строка ANSI"; // ANSI
L"строка Unicode"; // Unicode
_T("Или строка, зависящая от компиляции"); // ANSI или Unicode
// или используйте макрос TEXT, если вам нужна хорошая читаемость кода
Lines without a prefix are ANSI lines, with an L prefix of a Unicode line, and lines with a _T and TEXT prefix are dependent on compilation. And again _T and TEXT are macros again. They are defined as follows:
// УПРОЩЕННАЯ
#ifdef _UNICODE
#define _T(c) L##c
#define TEXT(c) L##c
#else
#define _T(c) c
#define TEXT(c) c
#endif
The ## character is the token of the operator insertion, which turns _T ("Unicode") into L "Unicode", where the string is an argument for the macro, unless of course _UNICODE is defined.
If _UNICODE is not defined then _T ("Unicode") will turn it into "Unicode". The operator insert key even existed in C, and this is not a specific thing related to string encoding in VC ++.
For information, macros can be applied not only to strings but also to characters. For example, _T ('R') will turn this into L'R 'well or just' R '. That is, either a Unicode character or an ANSI character.
No and no again, you cannot use a macro to convert a character or string to Unicode and not Unicode text.
The following code will be incorrect:
char c = 'C';
char str[16] = "Habrahabr";
_T( c );
_T(str);
Lines _T (c); _T (str); compiled fine in ANSI mode, _T (x) will turn into x, and _T (c) along with _T (str) will simply turn into c and str.
But when you build the project in Unicode mode, the code does not compile with:
error C2065: 'Lc' : undeclared identifier
error C2065: 'Lstr' : undeclared identifier
I would not want to cause a stroke in your intellect and explain why this does not work.
There are several functions for converting Multibyte strings to UNICODE, which I will talk about shortly.
There is an important note, almost all functions that a string or character takes, priority in the Windows API, have a generic name in MSDN and elsewhere.
The SetWindowTextA / W function will be classified as:
BOOL SetWindowText(HWND, const TCHAR*);
But as you know, SetWindowText is just a macro, and depending on the project settings it will be considered as:
BOOL SetWindowTextA(HWND, const char*);
BOOL SetWindowTextW(HWND, const wchar_t*);
So do not puzzle if you can not get the address of this function:
HMODULE hDLLHandle;
FARPROC pFuncPtr;
hDLLHandle = LoadLibrary(L"user32.dll");
pFuncPtr = GetProcAddress(hDLLHandle, "SetWindowText");
//значение pFuncPtr будет null, потому что фунций с названием SetWindowText даже не существовало
In the User32.DLL library, there are 2 functions SetWindowTextA and SetWindowTextW that are exported, that is, there are no names with a generic name.
All functions that have ANSI and UNICODE versions, in general, have only UNICODE implementation. This means that when you call SetWindowTextA from your code, passing the ANSI parameter to a string - it converts ANSI to UNICODE calls SetWindowTextW.
The real work (setting the title / title / label of the window) is done only by the Unicode version!
Take another example that will receive window text using GetWindowText.
You call GetWindowTextA passing it an ANSI buffer as the destination buffer.
GetWindowTextA will first call GetWindowTextW, possibly allocating memory for the Unicode string (i.e. the wchar_t array).
It then converts Unicode to ANSI string for you.
These ANSI to Unicode conversions are not limited only by GUI functions, but the whole subset of the Windows API functions, which accepts strings and has two options.
I will give another example of such functions:
- Createprocess
- GetUserName
- Opendesktop
- DeleteFile
- etc
Therefore, it is highly recommended that you call Unicode functions directly.
In turn, this means that you should always focus on building the Unicode version, and not on building the ANSI version, given the fact that you are used to using ANSI strings for many years.
Yes, you can save and receive ANSI strings, for example, for writing to a file, or sending a chat message to your chat program. Conversion functions exist for such needs.
Note: There is another type description: its name is WCHAR - it is equivalent to wchar_t.
TCHAR is a macro for declaring a single character. You can also declare a TCHAR array. But what if, for example, you want to describe a pointer to characters or a constant pointer to characters.
I will give an example:
// ANSI символы
foo_ansi(char*);
foo_ansi(const char*);
/*const*/ char* pString;
// Unicode/wide-string
foo_uni(WCHAR*);
wchar_t* foo_uni(const WCHAR*);
/*const*/ WCHAR* pString;
// Независимые
foo_char(TCHAR*);
foo_char(const TCHAR*);
/*const*/ TCHAR* pString;
After reading the chips with TCHAR, you probably prefer to use it. There are still good alternatives for representing strings in your code. To do this, simply include Windows.h in the project.
Note: If your project includes windows.h (indirectly or directly), you should not include TCHAR.H in the project.
First, let's review the old function to make it easier to understand. Example strlen function.
size_t strlen(const char*);
Which may be presented differently.
size_t strlen(LPCSTR);
Where LPCSTR is described as:
// Simplified
typedef const char* LPCSTR;
LPCSTR is understood as follows.
• LP - Long Pointer (long pointer)
• C - Constant (constant)
• STR - String (string)
Essentially LPCSTR is a (Long) pointer to a string.
Let's change strcpy to match the new style of the type name:
LPSTR strcpy(LPSTR szTarget, LPCSTR szSource);
szTarget is of type LPSTR, without using the C language types. LPSTR is defined as follows:
typedef char* LPSTR;
Note that szSource is of type LPCSTR, since the strcpy function does not modify the source buffer, therefore the const attribute is set. The returned data type is not a constant string: LPSTR.
So, functions with the str prefix for manipulating ANSI strings. But we need another two byte Unicode strings. For the same large characters, there are equivalent functions.
For example, to calculate the character length of large characters (Unicode strings), you will use wcslen:
size_t nLength;
nLength = wcslen(L"Unicode");
The prototype of the wcslen function is:
size_t wcslen(const wchar_t* szString); // Или WCHAR*
And the code above can be represented differently:
size_t wcslen(LPCWSTR szString);
Where LPCWSTR is described like this:
typedef const WCHAR* LPCWSTR;
// const wchar_t*
LPCWSTR can be understood as follows:
LP - Long Pointer (Long pointer)
C - Constant (constant)
WSTR - Wide character String (string of large characters)
Similarly, strcpy is the equivalent of wcscpy, for Unicode strings:
wchar_t* wcscpy(wchar_t* szTarget, const wchar_t* szSource)
Which can be represented as:
LPWSTR wcscpy(LPWSTR szTarget, LPWCSTR szSource);
Where szTarget is not a constant large string (LPWSTR), but szSource is a constant large string.
There are a number of equivalent wcs functions for str functions. str functions will be used for simple ANSI strings, and wcs functions for Unicode strings.
Although I already advised that you should use native Unicode functions, not just ANSI or just synthesized TCHAR functions. The reason is simple - your application should only be Unicode, and you should not worry about whether they are sporting for ANSI. But for completeness, I mentioned these general display (projection) !!!
To calculate the length of a string, you can use the _tcslen function (macro).
Which is described as follows:
size_t _tcslen(const TCHAR* szString);
Or so:
size_t _tcslen(LPCTSTR szString);
Where the type name LPCTSTR can be understood as
LP - Long Pointer
C - Constant
T = TCHAR
STR = String (String)
Depending on the project settings, LPCTSTR will be projected into LPCSTR (ANSI) or in LPCWSTR (Unicode) .
Note: strlen, wcslen, or _tcslen will return the number of characters in a string, not the number of bytes.
The generic _tcscpy line copy operation is described as follows:
size_t _tcscpy(TCHAR* pTarget, const TCHAR* pSource);
Or in an even more generalized manner, like:
size_t _tcscpy(LPTSTR pTarget, LPCTSTR pSource);
You can guess what LPTSTR means))
Examples of using.
First, I’ll give an example of non-working code:
int main()
{
TCHAR name[] = "Saturn";
int nLen; // Or size_t
lLen = strlen(name);
}
On the ANSI build, this code successfully compiles because TCHAR will be of type char, and the variable name will be an array of char. Calling strlen for name will work just fine too.
So. Let's compile the same with UNICODE / _UNICODE enabled (in the project settings, select “Use Unicode Character Set”).
Now the compiler will throw this kind of error:
error C2440: 'initializing' : cannot convert from 'const char [7]' to 'TCHAR []'
error C2664: 'strlen' : cannot convert parameter 1 from 'TCHAR []' to 'const char *'
And programmers will begin to correct the error this way:
TCHAR name[] = (TCHAR*)"Saturn";
And this will not pacify the compiler, because converting from TCHAR * to TCHAR [7] is not possible. The same error will occur when embedded ANSI strings are passed to the Unicode function:
nLen = wcslen("Saturn");
// error: cannot convert parameter 1 from 'const char [7]' to 'const wchar_t *'
// Ошибка: не могу с конвертировать параметр 1 из 'const char [7]' в 'const wchar_t *'
Unfortunately (or fortunately), this error can be incorrectly corrected by simply casting the C language types.
nLen = wcslen((const wchar_t*)"Saturn");
And you think that you have increased the level of your experience when working with pointers. YOU are wrong - this code will give the wrong result, and in the majority you will receive Access Violation (access violation). Type casting in this way is like passing a float variable when a (logical) structure of 80 bytes was expected.
The string "Saturn" is a sequence of 7 bytes:
| 'S' (83) | 'a' (97) | 't' (116) | 'u' (117) | 'r' (114) | 'n' (110) | '\ 0' (0) |
But when you pass the same set of bytes to wcslen, it treats every 2 bytes as one character. Therefore, the first 2 bytes [97.83] will be considered as one character having a value of 24915 (97 << 8 | 83). This is a Unicode character ??? .. And the other following characters are treated as [117,116] and so on.
Of course you did not pass these Chinese characters, but type casting did it for you !!!
And therefore it is very important to know that type conversion will not work. So, to initialize the first line, you should do the following:
TCHAR name[] = _T("Saturn");
Which will translate to 7 or 14 bytes, depending on the compilation.
The wcslen call should be like this:
wcslen(L"Saturn");
In the program code example above, I used strlen, which causes errors when building Unicode.
I’ll give an example of a non-working solution with type casting of the C language:
lLen = strlen ((const char*)name);
On Unicode assemblies, the name variable will be 14 bytes in size (7 unicode characters, including null). Since the string
"Saturn" contains only English characters that can be represented using ASCII encoding, the Unicode character 'S' will be represented as [83, 0]. The following ASCII characters will be represented as zeros. Notice now the character 'S' is represented as a 2-byte value of 83. The end of the line will be represented as 2 bytes with a value of 0.
So, when you pass such a string to strlen, the first character (that is, the first byte) will be correct ('S' in the case of 'Saturn'). But the next character / byte will be identified as the end of the line. Therefore, strlen will return the wrong value 1.
As you know, a Unicode string can contain more than English characters, and the result of strlen will be even more undefined.
In short, type casting will not work.
You will either have to present the lines in the correct form, or use the ANSI to Unicode conversion functions, and vice versa.
Now, I hope you understand the following code:
BOOL SetCurrentDirectory( LPCTSTR lpPathName );
DWORD GetCurrentDirectory(DWORD nBufferLength,LPTSTR lpBuffer);
Continuing the topic. You probably saw some functions / methods that need to transmit the number of characters, or returning the number of characters. However, there is GetCurrentDirectory, in which you need to transfer the number of characters, not the number of bytes.
Example:
TCHAR sCurrentDir[255];
// Передавайте 255 а не 255*2
GetCurrentDirectory(sCurrentDir, 255);
On the other hand, if you need to allocate memory for the desired number of characters, you must allocate the proper number of bytes. In C ++, you can simply use the new operator:
LPTSTR pBuffer; // TCHAR*
pBuffer = new TCHAR[128]; // Выделяет 128 или 256 байт, в зависимости от компиляции.
But if you use memory allocation functions such as malloc, LocalAlloc, GlobalAlloc, etc., you must specify the number of bytes!
pBuffer = (TCHAR*) malloc (128 * sizeof(TCHAR) );
As you know, casting of the return value is necessary. The expression in the malloc argument ensures that it allocates the required number of bytes - and allocates space for the desired number of characters.
PS
Original article
All with NG !!!