MIT course "Computer Systems Security". Lecture 4: "Separation of privileges", part 2
- Transfer
- Tutorial
Massachusetts Institute of Technology. Lecture course # 6.858. "Security of computer systems". Nikolai Zeldovich, James Mykens. year 2014
Computer Systems Security is a course on the development and implementation of secure computer systems. Lectures cover threat models, attacks that compromise security, and security methods based on the latest scientific work. Topics include operating system (OS) security, capabilities, information flow control, language security, network protocols, hardware protection and security in web applications.
Lecture 1: “Introduction: threat models” Part 1 / Part 2 / Part 3
Lecture 2: “Controlling hacker attacks” Part 1 / Part 2 / Part 3
Lecture 3: “Buffer overflow: exploits and protection” Part 1 /Part 2 / Part 3
Lecture 4: "Separation of privileges" Part 1 / Part 2 / Part 3
So, what else did we have on this list? Processes. Memory is something that happens simultaneously with the process. Thus, if you are not in this process, you cannot access its memory. Virtual memory perfectly enhances this isolation for us. In addition, the debugging mechanism allows you to "stick up" in the memory of another process, if you have the same user ID.
Next we go to the network. Networks in Unix do not quite correspond to the model described above, in part because the Unix operating system was first developed.and then a network appeared, which soon became popular. It has a slightly different set of rules. Therefore, the operations that we really need to take care of are connecting someone to the network if you control the network, or listening to a port if you act as a server. You may need to read or write data on this connection or send and receive raw packets.

Thus, networks in Unix are largely unrelated to the userid.. The rules are that anyone can always connect to any machine or any IP address or open a connection. If you want to listen on a port, in this case there is one difference, which is that most users are not allowed to listen on ports with a number below the “magic value” 1024. In principle, you can listen on such ports, but in this case you should be a special user called “super user” with uid = 0 .
And in general, in Unix there is the concept of an administrator, or superuser, which is represented by the identifier uid = 0, which can bypass almost all these checks, so if you work with root rights, you can read and write files, change access rights to them. The operating system will allow you to do this because it thinks you should have all the privileges. And such privileges you really need to listen to ports with the number <1024. What do you think about this strange restriction?
Audience: it defines specific port numbers for specific connections, for example, for http on port 80.
Prof: yes, by default HTTP protocoluses port 80. On the other hand, other services can use ports with a number above 1024, why do we need this restriction? What is the use?
Audience: because you do not want someone to accidentally listen on your HTTP .
Professor:Yes. I think the reason for this is that you used to have many users on the same machine. They logged in with their usernames, launched their applications, so you wanted to make sure that some random user, logging into the computer, would not be able to get hold of the web server running on it. Because external users do not know who is working on this port, and they simply connect to port 80. If I want to log into this machine and start my own web server, then I will simply transfer all web server traffic to this car. This is probably not a very good plan, but it is a way that the Unix network subsystem does not allow random users to control well-known services running on these low port numbers. That is the rationale for such a restriction.

In addition, in terms of reading and writing connection data, if you have a descriptor file for a particular socket, Unix will allow you to read and write any data on this TCP or uTP connection . Unix behaves paranoid about sending raw Unix packets , so it will not allow you to send random packets over the network. This should be inside the context of a special connection, except when you have root rights and you can do whatever you want.
So, one interesting question that you could ask is - where do all these userids come from ?
We are talking about processes that have a userid.or groupid . When you run PS on your computer, you will definitely see a series of processes with different uid values . Where did they come from?
We need some kind of mechanism to load all these userid values . In Unix, there are several system calls for this. Therefore, for the initial loading of these identifier values, there is a function called setuid (uid) , so you can assign the uid number of some current process to this value. In fact, this is a dangerous operation, like everything else in the Unix tradition , because you can do this only if your uid = 0. In any case, it should be so.
Thus, if you are a root user and have uid = 0 , then you can call setuid (uid) and switch the user to any process. There are a couple of other similar system calls for initializing gid related to the process: these are setgid and setgroups . Therefore, these system calls allow you to configure the privileges of the process.

The fact that your processes get the right access rights when you log into the system on a Unix machine does not happen because you have the same ID as the processes, because the system still does not know who you are. Instead on unixThere is some kind of login procedure when the SSH secure shell protocol starts the process for anyone who connects to the computer and tries to authenticate the user.
Thus, initially, this login process starts with uid = 0 as a user with root-rights, and then, when he receives a specific username and password, he checks them in his own database of accounts. As a rule, in Unix this data is stored in two files: / etc / password (for historical reasons, passwords are no longer stored in this file), and in the file / etc / shadow , in which passwords are stored. However, in the / etc / password filethere is a table displaying each username in the system as an integer value.
Thus, your username is matched to a specific integer in this / etc / password file , and then the login process checks if your password is correct according to this file. If it finds your integer uid , then it sets the setuid function to the value of the uid and starts the shell using the exec command (/ bin / sh) . You can now interact with the shell, but it works under your uid , so you cannot accidentally damage this machine.

Audience: is it possible to start a new process with uid = 0 , if yourIs uid not actually 0?
Professor: if you have root-rights, you can limit yourself to another uid , lower your privileges, but in any case you can create a process only with the same uid as yours. But it happens that for various reasons you want to increase your privileges. Suppose you need to install a package, for which you will need root privileges .
In unixThere are two ways to set privileges. One we have already mentioned, this is a file descriptor. So if you really want to increase your privileges, you can talk to someone who works under root-rights and ask them to open this file for you. Or you need to install some kind of new interface, then this helper opens the file for you and returns you the file descriptor using the fd transfer . This is one way to increase your privileges, but this is inconvenient, because in some cases there are processes running with a lot of privileges. For this, Unix has a clever, but at the same time, problem mechanism called "setuid binaries" . This mechanism is a regular executable files in the Unix file system., except when you run exec on a binary setuid file , for example, / bin / su on most machines, or sudo .
In a typical Unix system , there are a bunch of setuid binaries . The difference is that when you execute one of these binaries, it actually switches the userid process to the owner of this binary file. This mechanism seems strange when you first see it. As a rule, the ways to use it are that this “binary” most likely has an owner uid of 0, because you really want to restore many privileges.

You want to restore the root permissions so that you can run this su command , and the kernel, when you execute this binary file, switches the uid of the process to 0, so this program will now do some privileged things.
Audience: if you have uid = 0 , and you change the uid of all these setuid binaries to something not equal to 0, can you recover your privileges?
Professor: no, many processes will not be able to restore privileges when access levels are lowered, so you may be stuck in this place. This mechanism is not bound to uid = 0 . Like any Unix user, you can create any binary file, build a program, compile it, and set this setuid bit in the program itself. It belongs to you, the user, your user ID. And this means that anyone who runs your program will run this code with your user ID. Is there any problem with this? What should be done?
Audience: that is, if there was an error in your application, someone could do anything with it, acting with your privileges?
Professor: that's right, it happens if my application is “buggy”, or if it allows you to run whatever you want. Suppose I could copy the system shell and make it setuidfor me, but then anyone can run this shell under my account. This is probably not the best course of action. But such a mechanism does not create problems, because the only person who can set the setuid bit on a binary file is the owner of this file. You, as the owner of the file, have the uid privilege , so you can transfer your account to another person, but this other person will not be able to create a binary setuid file with your userid .
This setuid bit is stored next to these permission bits, that is , the setuid bit is also present in each inode , which says whether this executable should be or if the program has switched touid owner
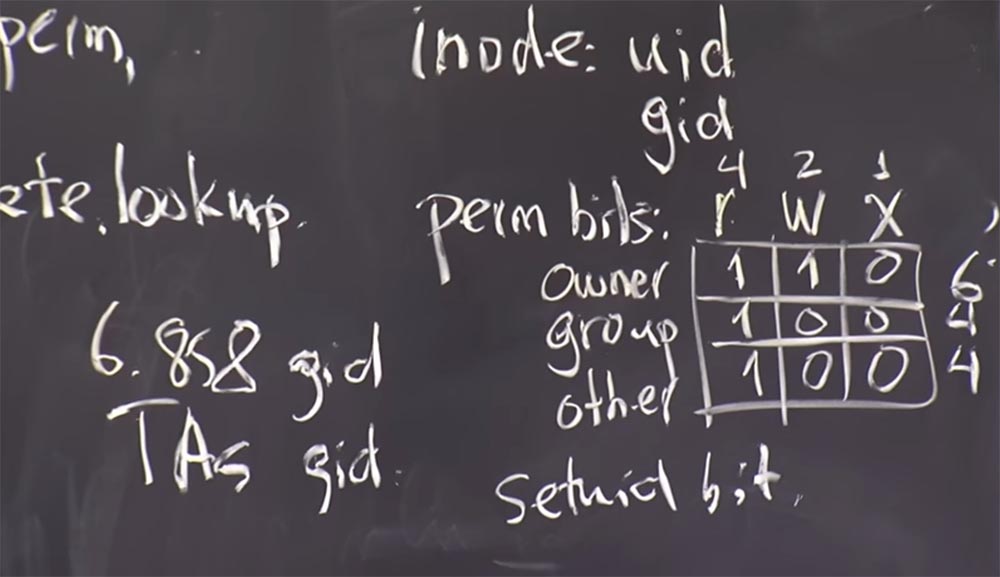
It turns out that this is a very tricky mechanism when used properly, and thanks to it the kernel implements the program correctly. In fact, this is fairly easy to do, because only one check is performed: if this setuid bit exists, then the process switches to uid . It is quite simple.
But it's safe to use it safely, because, as it was just stated, if this program contains errors or does something unexpected, then you get the ability to do arbitrary things under uid = 0 or under any other uid . In Unix, when you run a program, you inherit a lot of things from your parent process.
For example, you can pass environment variables to setuid binary files . The fact is that in Unix you can specify which shared library should be used for the process by setting the environment variable, and the setuid binaries do not care about filtering these environment variables.
For example, you can run bin / su , but use the shared libraries for the printf function , so your printf will start when bin / su prints something and you can run the shell instead of running printf .
There are many subtleties that you must understand correctly regarding the program’s distrust of the data that the user enters. Since you usually trust user input, the setuid mechanism has never been the safest part of an entire Unix system . Any questions about this?
Audience: does setuid also apply to groups or only to a user?
Professor: there is a setgid bit , a symmetrical setuid bit , which you can also set. If the file has a specific gid and this setgid bit is set when the program starts, then you will get it.
Setgidnot really used, but may be useful in cases where you want to provide very specific privileges. For example, bin / su probably requires a lot of privileges, but there may be some program that needs some additional privileges, for example, to write something in a special log file. Therefore, you probably want to give it a certain group and create for it a log file that can be written by this group. So even if the program is "buggy", then you will not lose anything except this group. This is useful as a mechanism, which for some reason is not used too often, because, after all, people should use more root-rights.
Audience: Are there restrictions on who can change access?
Professor: yes. Different implementationsUnix have different checks for this. The general rule is that only root can change the owner of the file, because you do not want to create files that will belong to someone else, and you certainly don’t want to appropriate other people's files. Therefore, if your uid is not 0, then you are stuck. You cannot change the ownership of any file. If your uid = 0 , you have root-rights and you can change the owner to anyone. There are some complications, if you have a binary setuid and you switch from one uid to another, this is pretty tricky, but basically you basically can’t change the owner of the file if you don’t have root privileges.
By all accounts, this is a bit outdated system. You could probably imagine a lot of ways that simplify the processes described above, but in fact, most advanced systems look like this because they evolve over time. But you can perfectly use these mechanisms as a sandbox.
It's just a kind of basic Unix principles that appear in almost every Unix-like operating system: Mac OS X , Linux , FreeBSD , Solaris , if someone else uses it, and so on. But in each of these systems there are more complex mechanisms that you could use. For example, in Linux there is a sandbox set COMP, Mac OS X uses the Seatbelt sandbox . Next week, I will give you examples of sandboxes available in each Unix based system .
So one of the last mechanisms we’ll look at before diving into OKWS explains how you need to deal with the setuid binaries and shows how you can protect yourself from existing security holes. The problem is that you will inevitably have some setuid binaries on your system, such as / bin / su , or sudo , or something else, and it is likely that there will be errors in your programs. Because of this, someone can execute a binary setuidand the process will be able to gain root access , something you don’t want to allow.

The Unix mechanism , which is often used to prevent a potentially malicious process from running using setuid binaries , is to use the file system namespace to modify it using the chroot system call, the root directory change operation. OKWS , being a web server specializing in creating fast and secure web services, uses it quite widely.

So, in Unix, you can chroot in a specific directory, so maybe you can chroot ("/ foo").
There are 2 explanations for what chroot does . The first one is just intuitive, it means that after running chroot , the root directory or the directory located after the slash is basically equivalent to what / foo used before you called the chroot . This looks like a namespace constraint below your / foo . Therefore, if you have a file that used to be called / foo / x , then after calling the chroot you can get this file by simply opening / x . So just limit your namespace to a subdirectory. This is what is the intuitive version.

Of course, not the intuitive version is important in security, but what exactly does the kernel do with this system call? And it does mostly two things. First, it changes the value of this slash, so whenever you access or when you start a directory name with a slash, the kernel includes any file that you have provided chroot operations . In our example, this is the file / foo before you call the chroot , that is, we get that / = / foo .

The next thing the kernel tries to do is to protect you from being able to “escape” from your / if you do /../ . Because in Unix, I could ask you, for example, to give me/../etc/password . So if I just added this line like this: /foo/../etc/password , this would not be good, because I could just exit / foo and go to getting / etc / password .
The second thing the kernel does with a Unix system call is that when you call a chroot for this particular process, it changes the way you evaluate /../ in this directory. Therefore, it modifies /../ so that / foopointed to itself. Thus, it does not allow you to "make an escape", and this change only applies to this process and does not affect the rest. What are your ideas on how to “escape” from the chroot environment using the way it is implemented?
Interestingly, the kernel tracks only one chroot directory , so perhaps you could perform the chroot = (/ foo) operation , but you would be glued to this location. So you want to get / etc / password , but how to do it? You can open the root directory right now by typing open (* / *) . This will give you a file descriptor describing what / foo is . Then you can callchroot again and execute chroot (`/ bar) .

So, now the kernel changes the plan: root is no longer / foo , but / foo / bar and this /../ redirect only applies to / foo / bar / ..

But know that you still have a file descriptor for / foo . So now you can change the directories in this file descriptor fchdir (fd) for this open call (* / *) , and now you can get chdir (..) .


That is, at first you were in / foo , and now you go to /../ . He no longer forces / foopoint at yourself and don't come back, because you have another root , so now you can escape from here.
Perhaps this is a good illustration of why the exact implementation mechanism is important. In this sense, this is not an intuitive explanation. Therefore, in Unix, only a user with root-rights can call chroot , otherwise chroot would be a rather pointless thing. Thus, in Unix you must have uid = 0 in order to perform a chroot operation on a process. This is a little disappointing. Because if you want to build a system with truly shared privileges, where everyone would have only the minimum set of necessary privileges, you need to use chroot , create new userid, and so on. But in order to do this in Unix , you must have a process running as root that has many privileges.
So this is an example of a slightly unsuccessful compromise, but this is probably the most reasonable way to design a system. One way to set up a chroot environment without creating a large number of copies of files is to create a directory with hard links. This is a pretty good solution.
Lecture hall:and what if the program gradually generates inod inodes , but does not give you a file descriptor?
Professor: this is a detail of great importance! You can access the file only by following the path of its name in the directory, and not, for example, by saying: “I want to open inode number 23”, because it may be some strange file in general outside of your hroot environment . Thus, in Unix , you can not open the inode by number inode , if you are, of course, are not endowed with root-rights.
I think we have enough cars to see how OKWS works . Briefly consider what to fear when workingOKWS .
An alternative design that virtually every web server follows is that you may have web browsers on the Internet that are going to connect to your server. And inside your server one process will be running, say, httpd , for example, on Apache .
And this process will work as one userid under the name www in / etc / password . It accepts all your connections, performs all processes, including SSL processing , including the execution of application code and PHP and so on, these are all parts of the same process. And if needed, this process connects to the database server, perhapsMySQL , which can work on the same machine or in another place. And this MySQL process actually writes data to disk. But to connect to this MySQL , you probably need to provide a username and password.
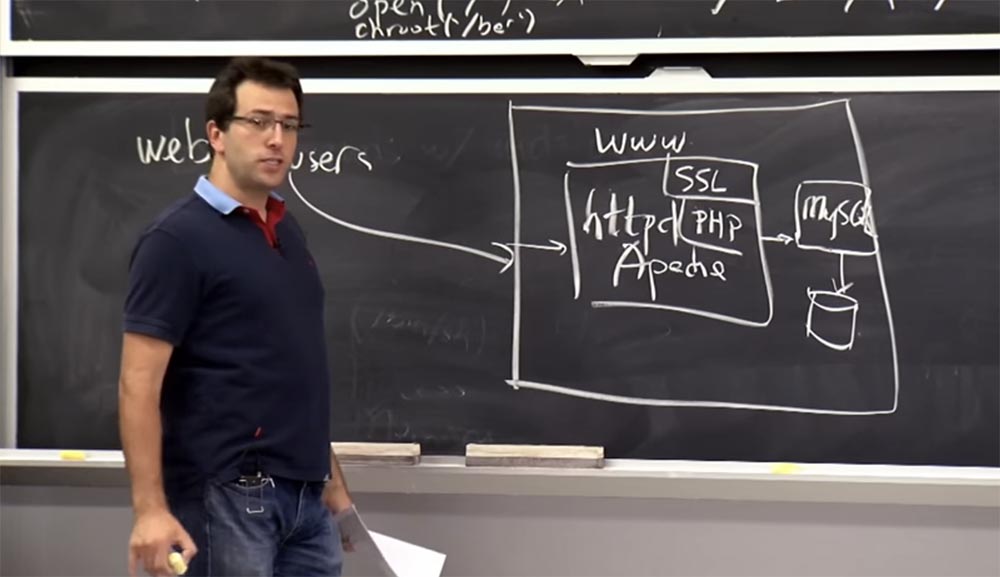
But, as a rule, applications are written in such a way that the MySQL server has one shared account for which the application knows the username and password, so you simply connect to it and get access to all your data.
So this solution is very convenient for writing a program, because you simply write any code you want and have access to any data in the database that you need. There is no real isolation, but it has security problems, possibly related to errors in Apache , or in SSL , or maybe in the application code or in the PHP interpreter . And if there are errors, it means that you can use them to get the entire contents of the application.
52:30 min.
Continued:
Course MIT "Security of computer systems." Lecture 4: "Separation of privileges", part 2
Full version of the course is available here .
Thank you for staying with us. Do you like our articles? Want to see more interesting materials? Support us by placing an order or recommending to friends, 30% discount for Habr users on a unique analogue of the entry-level servers that we invented for you: The whole truth about VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps from $ 20 or how to share the server? (Options are available with RAID1 and RAID10, up to 24 cores and up to 40GB DDR4).
Dell R730xd 2 times cheaper? Only we have 2 x Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 TV from $ 249 in the Netherlands and the USA! Read aboutHow to build the infrastructure of the building. class c using servers Dell R730xd E5-2650 v4 worth 9000 euros for a penny?