The main problems affecting the performance of the computing kernel and applications and methods for solving them by the compiler
I continue the discussion about application optimization that began here in the post “Is there a simple assessment of the quality of application optimization?”
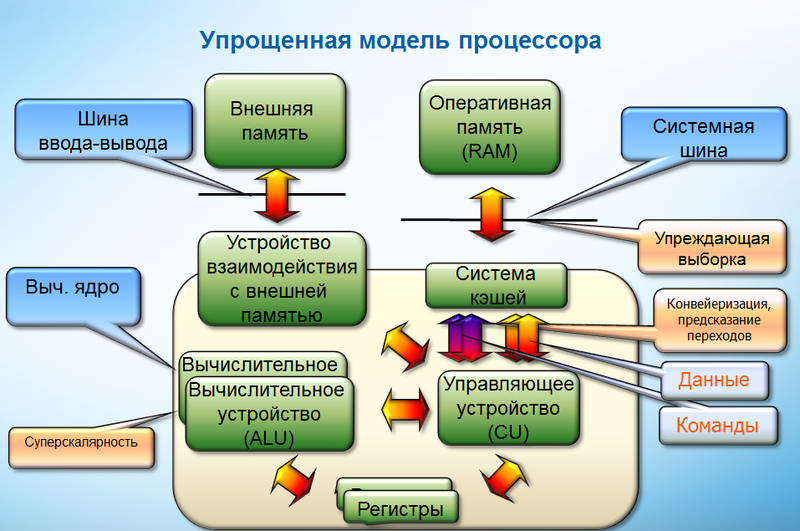
You can talk a lot about processors in great detail and, for sure, among the readers of Habré there are a lot of people who are capable of such conversations. But my point of view on the processor is purely pragmatic. Since I'm interested in application performance, through the prism of processor performance, I just need to understand the basic principles of the computing core. As well as the methods that exist to influence these basic principles. I will focus on the Intel64 architecture. This is because in our performance analysis team we are analyzing the work of the Intel optimizing compiler, mainly for this architecture. In the market of computing systems for high-performance computing, this and compatible architectures occupy the lion's share, so most of the performance problems have a fairly common nature.
Instruction Concurrency Level
The modern computing core is characterized by the presence of a pipeline (pipelining), superscalarity. The computing core has a mechanism for defining independent commands and scheduling instructions. Those. these mechanisms look at the buffer of instructions arriving for processing and select them for execution if there are suitable computing power and the instructions are not dependent on other instructions not yet executed. Thus, Intel64 architecture is characterized by out-of-order execution. Those. for such an architecture, the compiler does not need to deal with the detailed determination of the order of instructions. The load level of the pipeline will be determined by how many independent instructions get into processing, the so-called level of instruction parallelism.
The number of conditional transitions and the quality of the transition predictor
The execution order of various commands is determined by the control flow graph, which connects straight sections of the code. In places where branching of the control flow occurs, as a rule, various conditional transitions are used. That is, until the condition is calculated, it is not clear which instruction should be executed next. To ensure that the pipeline does not interrupt, there is a branch prediction mechanism in the computing core that selects one of the possible control transfer paths and continues to deliver instructions from this direction to the computing pipeline. Already completed instructions await the validation that occurs after the condition is calculated. If the predictor made a mistake, there is a delay in the work of the computational core caused by the need to clear the buffers of the computational core and load new instructions into them. This situation is called branch misprediction. The branch prediction mechanism is quite complex and includes both the static part, which makes an attempt to guess the direction at the first encounter with a conditional transition, and the dynamic one, accumulating and using statistics.
The quality of the memory subsystem
Since all the main data and instructions are located in RAM, it is important for performance how long this data can be delivered to the computing device. In this case, the delay in receiving data from the main memory is hundreds of processor cycles. To speed up the processor, it has a cache or a subsystem of caches. The cache stores copies of frequently used data from main memory. For modern multi-core processors, a situation is typical when the kernel owns a cache of the first and second levels, and the processor also has a cache of the third level, which the cores share. The first level cache is the smallest in size and fastest, the caches of the upper hierarchy are slower, but larger. Intel64 processors have an inclusive cache. This means that if some address is presented in a cache of any level, then it is also contained in the caches of the upper hierarchy. Therefore, if it is necessary to obtain data from memory, the memory subsystem sequentially checks for addresses in the cache of the first, second and third levels. In the case of a cache miss (i.e., the lack of necessary information in the cache), in each subsequent case, the delay will be greater. For example, for Nehalem, the approximate access time to caches of different levels will be as follows: 4 for the cache in the first level and, respectively, 11 and 38 for the caches of the second and third levels. The delay in accessing RAM is approximately 100 to 200 cycles. To understand the operation of the memory subsystem, it is important that the transmission and storage of the necessary information in the cache occurs in packets of a fixed length, which are called cache lines and are (for now?) 64 bytes. When a specific memory address is requested, some “neighboring” data is downloaded “along the way” to the cache. The system bus transfers data between the cache subsystem and the CPU. An important characteristic of the memory subsystem is the bus bandwidth, i.e. how many cache lines can be transferred to the cache per unit of time. Accordingly, the operation of the system bus often becomes a bottleneck in the execution of an application.
In connection with such a cache organization, such a factor as the principle of locality (locality of reference) used by the program data plays a large role. Distinguish between temporary locality (temporal locality), characterizing the reuse in the process of the application of the main objects and data and spatial locality (spatial locality) - the use of data having relatively close storage areas. And in the computing core, mechanisms are implemented to support the principle of locality. Temporary locality is supported by a caching mechanism that seeks to cache the most frequently used data in caches. When the question arises of the need to free the cache line to load a new one, the line that has not been used the most time is deleted. For spatial locality, the forward-looking mechanism works which seeks to determine in advance the memory addresses that will be required for subsequent work. At the same time, the higher the spatial locality (access to neighboring elements is in progress), the less data needs to be downloaded to the cache, the less load on the system bus.
You can also mention here the registers of the computational core, as the fastest memory. It is advantageous to store reused data in registers. There is such a performance problem as register spilling, when the data is constantly copied from registers to the stack and back during calculations.

Using vectorization
Intel64 processors support vector instructions. Those. there is the possibility of creating vectors of various types and applying instructions to them that work with vectors and receive a vector of results at the output. These are SSE family instructions. A set of instructions is being developed, supplemented by new commands and capabilities. SSE2, SSE3, SSE4, AVX - extensions of the original idea. The problem is that our programming languages are initially scalar and we need to make some efforts to use this feature of computing cores. Vectorization is a code modification that replaces a scalar code with a vector one. Those. scalar data is packed into vectors and scalar operations are replaced by operations with vectors (packets). You can use xmmintrin.h to program vectorization manually, use some kind of optimizing compiler with auto-vectorization or optimized libraries with utilities that use vector instructions. There are many restrictions on the possibility of applying this modification. In addition, there are many factors determining its profitability. That's why I wrote a modification, because optimization is what improves performance. In order for its vectorization to improve, certain conditions must be met. Those. vectorization is just an “opportunity”. It is necessary to work hard to translate this opportunity into real achievements. because optimization is what improves performance. In order for its vectorization to improve, certain conditions must be met. Those. vectorization is just an “opportunity”. It is necessary to work hard to translate this opportunity into real achievements. because optimization is what improves performance. In order for its vectorization to improve, certain conditions must be met. Those. vectorization is just an “opportunity”. It is necessary to work hard to translate this opportunity into real achievements.
Using multi-threaded computing
The presence of several computing cores on a modern processor makes it possible to achieve high application performance by distributing computing between these cores. But this is just an “opportunity”. The presence of a million highly professional programmers does not give hope that they will be able to implement an optimizing compiler in an hour. Converting single-threaded code to multi-threaded code requires serious efforts. Some optimizing compilers have an auto-parallelizer that reduces the process of creating a multi-threaded application to the process of adding a single option during compilation. But there are so many pitfalls on the path of the auto-parallelizer that in many cases the optimizing compiler needs help, and in many it is simply powerless. Great success can be achieved using OpenMP directives. But in most cases, efforts are required to parallelize the initially single-threaded algorithm. I will not mention other parallelization methods here, since in my opinion they are associated with serious changes in the calculation algorithms and are beyond what can be called non-algorithmic code optimization.
Based on the listed problems, 3 main characteristics can be distinguished that determine the performance of the running application and 2 great features that can be implemented:
1.) The quality of the memory subsystem.
2.) The number of conditional transitions and the quality of the transition predictor.
3.) The level of instructional parallelism.
4.) Use of vectorization.
5.) The use of multi-threaded computing.
Optimizations
What tools do the compiler and the programmer have to act on the listed characteristics of the calculation?
Many loop optimizations, such as swapping loops, splitting loops into blocks (loop blocking), combining and splitting loops (loop fusion / distribution), are called upon to improve the performance of the memory subsystem. These optimizations have a drawback. Not all cycles are suitable for such optimizations, and they are mainly found in computing programs in C and Fortran. The compiler may try to help the prefetch mechanism and automatically insert prefetch program instructions, but then again, this is a very specialized operation requiring a favorable arrangement of stars. If an executable module is being built, then with a dynamic profiler, the compiler is able to improve the spatial locality of application data by rearranging the fields of structures and moving cold regions into separate structures. There’s even such an optimization, like moving fields from one structure to another. It is quite difficult for the compiler to prove the correctness and profitability of such optimizations, but it is much easier for the programmer to do such things, the main thing is to understand the idea of this or that code modification.
An important role in improving data locality can be played by scalar optimizations, i.e. optimizations involved in the analysis of data flow, pulling constants, optimizing the control graph, removing common subexpressions, deleting dead code. These optimizations reduce the amount of computation that an application needs to perform. As a result, the number of instructions is reduced and data locality is improved, since instructions also need to be stored in the cache. The quality of execution of these optimization methods can be called computing efficiency. Interprocedural analysis helps all of these optimizations. If used, the analysis of the data flow becomes global, i.e. It analyzes the transfer of properties of objects not only at the level of a specific procedure being processed by the compiler, but also within the entire program. The properties of specific arguments with which this procedure was called from different places of the application are studied and used inside the procedure, the properties of global objects are studied, a list of objects is created for each function that can be used or modified inside this function, etc. Substitution of the function body ( inlining) and partial substitution can also have a positive effect on data locality. You can’t make many of the above optimizations by hand, since the effect of each outstretched constant can be meager, but as a result, pulling constants gives a good overall effect and often makes it possible to apply and more correctly evaluate the effect of more complex optimizations. for each function, a list of objects is created that can be used or modified inside this function, etc. Inlining the body of the function and partial substitution can also positively affect the locality of the data. You can’t make many of the above optimizations by hand, since the effect of each outstretched constant can be meager, but as a result, pulling constants gives a good overall effect and often makes it possible to apply and more correctly evaluate the effect of more complex optimizations. for each function, a list of objects is created that can be used or modified inside this function, etc. Inlining the body of the function and partial substitution can also positively affect the locality of the data. You can’t make many of the above optimizations by hand, since the effect of each outstretched constant can be meager, but as a result, pulling constants gives a good overall effect and often makes it possible to apply and more correctly evaluate the effect of more complex optimizations.
In addition, the optimizing compiler pays a lot of attention to register allocation.
The optimizing compiler can perform certain actions to reduce the number of conditional branches and the quality of the transition predictor. The most trivial is to improve the performance of the static branch predictor by changing the condition under which the transition occurs. The static predictor assumes that if a downward transition is possible during branching of the control graph, it will not be executed. If the compiler believes that the probability of the if branch is less than for else, then he can swap them. A very strong optimization is the removal of an invariant check from cycles. Another well-known optimization is loop unrolling. There is a useful scalar optimization that stretches conditions along the control graph, which allows you to remove redundant checks, combine them and simplify the control graph. Also, the compiler is able to recognize certain patterns and replace branches with the use of instructions such as cmov. You can probably give more examples, but this one also shows that the optimizing compiler has methods to deal with delays due to incorrect predictions.
To improve instructional parallelism, scheduling is used, which is performed at the last stages of the compiler's work during code generation.
To improve application performance through the use of vectorization, our compiler has an automatic vectorizer that performs vectorization of loops and replaces scalar code with vector code. This compiler component is constantly evolving, implementing new features of vector extensions, increasing the number of recognized idioms, vectorizing mixed data loops, etc. In addition, the vectorizer inserts various runtime checks into the code and creates multi-version code, since the efficiency of vectorization envy from the number of iterations in the loop, from the location of various objects in memory, from the multimedia extension used. For more efficient operation, vectorizer interaction with other cycle optimizations is necessary. The compiler is not always able to prove the validity of vectorization,
Intel compiler offers developers to use auto-parallelization - a mechanism for automatic parallelization of loops. This, in fact, the cheapest way to create a multi-threaded application in terms of labor costs, is to start building the application with a special option. But from the point of view of the optimizing compiler, this is not an easy task. It is necessary to prove the feasibility of optimization, it is necessary to correctly evaluate the amount of work performed inside the loop, so that the decision on parallelization improves productivity. Automatic parallelization as well as auto-vectorization should interact with other loop optimizations. Probably, in this area the best optimization algorithms have not yet been written, and the scope for experiments and innovative ideas is still great. To develop parallelization methods that are more visual for programmers, new language extensions and various support libraries are created, such as CILK + or Threading Building Blocks. Well, the good and trusted OPENMP is also too early to discount.
Conclusion:
In a previous post, I suggested that there is no simple criterion for understanding how well an application is optimized. This comes from the fact that there are many different performance optimizations that can only be used if certain conditions are met. Whether these conditions are met, is there an opportunity to do this or that optimization - to understand this issue and it is necessary in the process of analyzing application performance. Therefore, in my opinion, the analysis of application performance comes down to identifying application areas critical for performance, determining the causes of possible delays in the processor in these areas, trying to determine whether it is possible to use optimizations that affect the identified cause,
Is vectoring vectorized (a small example of analysis)
Sometimes even the same application can show absolutely amazing results when analyzing performance. Here, for example, we ask ourselves whether the vector is vectorized? Consider this test:
#include
using namespace std;
int main ()
{
vector myvector;
vector::iterator it;
for(int j=0; j<1000; j++) {
it = myvector.end();
it = myvector.insert ( it , j );
}
for (int i=1; i < myvector.size(); ++i)
myvector[i]++;
printf("%f\n",myvector[0]);
return 0;
}
I use the Intel compiler integrated in VS2008 to compile this text. In this case, I am interested in the question of whether the cycle is published in line 14 of the code. We use the –Qvec_report3 option to view the autovectorizer report:
icl -Qvec_report3 -Qipo -Qansi_alias vector.cpp
Intel C ++ Intel 64 Compiler XE for applications running on Intel 64, Version Mainline Beta Build x
...
... \ vector.cpp (14): (col. 30) remark: loop was not vectorized: unsupported loop structure.
...
Now I use the same compiler, but already integrated into VS2010.
icl -Qvec_report3 -Qipo -Qansi_alias vector.cpp
...
... \ vector.cpp (14): (col. 30) remark: LOOP WAS VECTORIZED.
...
I will not talk here about the ways in which one can get to the bottom of the reason for the different behavior of the compiler when compiling the same program. (You can see the assembler, you can preprocess the code). Since the Intel compiler is integrated into different versions of VS, in this case different versions of the STL library are used. In the STL version of VS2008, the [] operator contains a check for going beyond the boundaries of the array. As a result, a call to the __invalid_parameter_noinfo procedure appears inside the loop and exits the program, and the compiler is unable to vectorize such a loop. But in VS2010, such a check is no longer there. I wonder why?
It's funny that if you remove the –Qansi_alias option, then the vectorization also disappears. The same thing happens if you create a vector to store integers, not real ones. But the reasons for these "miracles" are an occasion for a separate article.
Primary Sources
Research literature on various performance issues: The Software Optimization Cookbook, Second Edition, or The Software Vectorization Handbook.
Basic sources for various optimization techniques: Randy Allen, Ken Kennedy. Optimizing compilers for modern architectures, as well as David F. Bacon, Susan L. Graham, Oliver J. Sharp. Compiler transformations for High-Performance Computing.
For programmers interested in programmatically improving code, you can recommend the book Agner Fog,Optimizing software in C ++: An optimization guide for Windows, Linux and Mac platforms.
I did not hesitate to copy some thoughts from my article “Optimizing Compilers” in the journal “Open Systems”.