Slight discrepancy
- Transfer

This image shows a mesh tabletop in a patio, photographed after heavy rain. Drops of water lingered in some holes in the net. What about the distribution of these drops? Are they randomly scattered across the surface? The process of rain falling that arranged them seems rather random, but in my opinion, the pattern of places occupied in the grid looks suspiciously even and monotonous.
To simplify the analysis, I selected the square part of the photograph with the tabletop (removing the hole for the umbrella), and highlighted the coordinates of all the drops in this square. In total there are 394 drops, which I marked with blue dots:

I repeat the question: does this pattern look like the result of a random process?
I came to this question after writing an article for American Scientist , which explores two versions of simulated randomness: pseudo and quasi . Pseudo-randomness needs no introduction. The pseudo-random square selection algorithm seeks to ensure that all points have the same probability of selection, and that all choices are independent of each other. Here is an array of 394 pseudo-random points bounded by the membership of a beveled and rotated grid, similar to a mesh worktop:

Quasi-randomness is a less well-known concept. When choosing quasi-random points, the goal is not the equiprobability or independence, but the uniformity of distribution: the most uniform spread of the points along the surface of the square. However, it is not too obvious how to achieve this goal. For the 394 quasi random points shown below, the x coordinates form a simple arithmetic progression, but the y coordinates are changed by the process of mixing the numbers. (The corresponding algorithm was invented in the 1930s by the Dutch mathematician Johannes van der Corput, who worked on one-dimensional series, and was transferred into two dimensions by Klaus Friedrich Roth in the 1950s. For more details see my article for American Scientist on page 286 or in an amazing book Jiri Matuseka.)

Which of these sets of dots, pseudo or quasi , better matches raindrops? We can compare all three patterns in a reduced form:
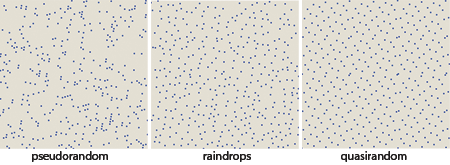
Each of the patterns has its own texture. In pseudo-random there are concentrated clusters and large gaps. Quasi-random points are arranged more evenly (although there are several close pairs of points), but they also create distinct small-scale repeating patterns, the most noticeable of which is the hexagonal structure, repeated with almost crystalline uniformity. As for the droplets, it seems that they are distributed over the area with an almost uniform density (in this resembling a quasi-random pattern), but the texture contains hints of bends rather than lattice structures (in this it looks more like a pseudorandom example).
Instead of studying the patterns “by eye”, you can try a quantitative approach to their description and classification. For this purpose, there are many tools: radial distribution functions, statistics of nearest neighbors, Fourier methods, but the main reason for solving this issue for me was primarily the opportunity to play with a new toy that I studied in the process of studying quasi-randomness. This quality, called discrepancy ( note transl.: Could not find the correct term in Russian, so write to me if you know it) , estimates the deviation of the set of points from the uniform distribution in space.
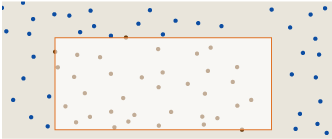
There are many variations in the concept of divergence, but I want to consider only one measurement scheme. The idea is to superimpose rectangles of various shapes and sizes on the pattern, the sides of which are parallel to the x and y axes . Here are three examples of rectangles superimposed on a drop pattern:

Now let's calculate the number of points enclosed in each rectangle, and compare them with the number of points that should be enclosed in it with the corresponding area if the distribution of points were perfectly uniform throughout the square. The absolute value of the difference is the discrepancy
 associated with the rectangle
associated with the rectangle  :
:
Where
 - the total number of points, and
- the total number of points, and  - amount of points
- amount of points  in the rectangle . For example, the rectangle in the upper left corner covers 10 percent of the square, that is, its “fair” fraction of points should be 0.1 × 394 = 39.4 points. In fact, the rectangle contains only 37 points, that is, the discrepancy associated with the rectangle is | 39.4 - 37 | = 2.4. The density of points in a rectangle can be more or less than the total average; in both cases the absolute value will give us a positive discrepancy.
in the rectangle . For example, the rectangle in the upper left corner covers 10 percent of the square, that is, its “fair” fraction of points should be 0.1 × 394 = 39.4 points. In fact, the rectangle contains only 37 points, that is, the discrepancy associated with the rectangle is | 39.4 - 37 | = 2.4. The density of points in a rectangle can be more or less than the total average; in both cases the absolute value will give us a positive discrepancy. For the pattern as a whole, we can specify the general discrepancy D as the worst value of its change, or, in other words, the maximum discrepancy taken for all possible rectangles superimposed on the square. Van der Korput wondered if sets of points could be created with an arbitrarily low divergence, so for
tending to infinity  always been below some fixed border. The answer is no in at least one or two dimensions; minimum growth rate is
always been below some fixed border. The answer is no in at least one or two dimensions; minimum growth rate is . Pseudorandom patterns generally have a higher variance
. Pseudorandom patterns generally have a higher variance .
. How to find a rectangle with maximum divergence for a given set of points? When I first read the definition of discrepancy, I thought that it would definitely be impossible to calculate it, because there are an infinite number of rectangles in question. But on reflection, I realized that there is only a finite set of candidate rectangles that can maximize the discrepancy. These are rectangles in which each of the four sides passes through at least one point. (Exception: Candidate rectangles may also have sides lying on the borders of the square.)
Suppose we meet the following rectangle:
The left, upper and lower sides pass through the point, but the right side lies in the “empty space”. Such a configuration cannot be a rectangle with maximum divergence. We can move the right edge to the left until it intersects with a point:

This change in shape reduces the area of the rectangle without changing the number of points enclosed in it, and therefore increases the density of the points. We can also move the edge to the other side:
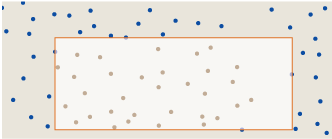
Now we have increased the area, again without changing the number of points enclosed in it, which means we have reduced the density. At least one of these actions will increase
, compared to the initial configuration. Therefore, each rectangle, all four sides of which touch the points or edges of the square, is the local maximum of the divergence function; listing all the rectangles in this finite set, we can find the global maximum. There is another annoying question: should the rectangle be considered “closed” (that is, points on the border are included in the area) or “open” (points on the borders are excluded). I avoided this task, presenting in a table the results for both closed and open borders. The closed form gives the greatest discrepancy for rectangles with a dense arrangement of points, and the open form maximizes the discrepancy at a low density of points.
Considering only the extrema of the divergence function, we make the calculation problem finite - but it's not so simple! How many rectangles need to be considered squared with
points (each of which has its own different coordinates  and
and  )? This turns out to be a very interesting small task with a simple combinatorial solution. I won’t explain the answer here, but if you don’t think you can handle it yourself, you can watch it at OEIS or read a short article by Benjamin, Quinn and Wurtz . What I can say is that for N = 394 the number of rectangles is 6,055,174,225 - or two times more if we separately take into account open and closed rectangles. For each rectangle, you need to find out how many of the 394 points are inside, and how many are outside. Pretty big job.
)? This turns out to be a very interesting small task with a simple combinatorial solution. I won’t explain the answer here, but if you don’t think you can handle it yourself, you can watch it at OEIS or read a short article by Benjamin, Quinn and Wurtz . What I can say is that for N = 394 the number of rectangles is 6,055,174,225 - or two times more if we separately take into account open and closed rectangles. For each rectangle, you need to find out how many of the 394 points are inside, and how many are outside. Pretty big job.One way to reduce computational costs is to return to a simpler measurement of discrepancy. Different literature on quasi-random patterns in two or more dimensions uses a quality called “star discrepancy,” or D * . The idea is to consider only the rectangles “attached” to the lower left corner of the square (which successfully coincides with the origin of the xy plane ). In this case, the number of rectangles is equal to the total
 , or about 150,000 for N = 394.
, or about 150,000 for N = 394. Here is a rectangle defining the global divergence-star of the raindrop pattern:

The dark green rectangle below covers about 55 percent of the square and should contain 216.9 points with a completely even distribution. In fact, it includes (assuming that it is a “closed” rectangle) 238 points, that is, the difference is 21.1. No other rectangle tied to the corner (0,0) will have a greater discrepancy. (Note: due to limitations of graphic resolution, it seems that the rectangle D * is stretched to the borders of the square, in fact, the right edge lies on x = 0.999395.)
What does this result tell us about the nature of the pattern of raindrops? Well, for starters, the discrepancy is pretty close to
 (which is equal to 19.8 at N = 394) and is not particularly close to
(which is equal to 19.8 at N = 394) and is not particularly close to  (which is 6.0 for natural logarithms). That is, we do not find confirmation that the droplet pattern is more quasi-random than pseudo-random. The D * values for the other patterns shown above are in the expected range: 25.9 for pseudo-random and 4.4 for quasi-random. Contrary to the external impression, the distribution of the raindrops seems to have more in common with the pseudo-random set of points than with the quasi- random - at least, according to the D * criterion .
(which is 6.0 for natural logarithms). That is, we do not find confirmation that the droplet pattern is more quasi-random than pseudo-random. The D * values for the other patterns shown above are in the expected range: 25.9 for pseudo-random and 4.4 for quasi-random. Contrary to the external impression, the distribution of the raindrops seems to have more in common with the pseudo-random set of points than with the quasi- random - at least, according to the D * criterion . What about calculating the unlimited divergence D , that is, studying all the rectangles, and not just the fixed rectangles D *? Upon reflection, we can conclude that a comprehensive enumeration of rectangles will not be able in this case to change the main conclusion; D can never be less than D * , and therefore we cannot hope to get closer from
to . But I was still interested in computing. Which of all these six billion rectangles will have the greatest discrepancy? Is it possible to answer this question without heroic deeds? The obvious and simple algorithm for D generates in turn all the candidate rectangles, measures their area, counts the points inside and tracks the marginal discrepancies found in the process. I found out that a program that implements this algorithm can determine the exact discrepancy of 100 pseudo-random or quasi-random points in a few minutes. This result may motivate us to take large values of N ; however, the execution time almost doubles every time N increases by 10, and this hints to us that for N= 394 calculations take a couple of centuries.
I spent several days trying to speed up the calculations. Most of the execution time is spent on a procedure that counts the points in each rectangle. Determining whether a given point is inside, outside, or on a border takes eight arithmetic comparisons; that is, for N= 394, more than 3,000 are executed for each of the six billion rectangles. The most effective way to save time that I discovered was the preliminary calculation of all comparisons. For each point that can become the lower left corner of the rectangle, I pre-compute a list of all the points in the pattern above and to the right. For each potential upper right corner of the rectangle, I put together a similar list of points below and to the left. These lists are stored in a hash table indexed by angle coordinates. For each triangle, I can calculate the number of interior points by simply taking the intersection of the sets of two lists.
Thanks to this trick, the expected execution time at N= 394 decreases from two centuries to about two weeks. This great optimization spurred me to spend another day on further improvements. Replacing the hash table with an N × N array improved the situation a bit . And then I found a way to ignore all the smallest triangles that cannot be probable rectangles with maximum D , because they contain too few points, or they have too little area. This improvement finally reduced lead time to one night. It took six hours to calculate the illustration showing the rectangle with the maximum divergence D for the raindrop pattern.

The rectangle with max- D obviously became a small refinement of the rectangle D * for the same set of points. Rectangle D “should” contain 204.3 points, but actually contains 229, which gives us a discrepancy of D = 24.7. Of course, knowing that the exact discrepancy is 24.7, not 21.1, tells us nothing about the nature of the raindrops pattern itself. In fact, it seems to me that as I conduct more and more calculations, I learn about it less and less.
When I started work on this project, I had my own theory about what can happen in the countertop to smooth out the distribution of drops and what makes the pattern more quasi- than pseudorandom. To begin with, I thought about drops lying on a smooth surface of glass, and not a metal grid. If two small droplets get close enough to touch, they will merge into one big drop, because this configuration has less energy associated with surface tension. If two adjacent mesh cells are filled with water, and if the metal between them is wet, then water can freely flow from one drop to another. A larger drop will almost certainly grow due to a smaller one, and the latter will disappear with time. Therefore, compared with a purely random distribution, we can expect a shortage of droplets in neighboring cells.
And this thought still seems very good to me. The only problem is that it explains a phenomenon that may not exist. I do not know if my calculations of the discrepancy revealed something important about these three patterns, but at least the measurements failed to prove that the distribution of the drops is different from the pseudo-random one. In fact, the patterns look different, but how much can we trust our sensory organs in such cases? If you ask people to draw dots randomly, most of them will do it poorly, usually the distribution will turn out to be too smooth and even. Perhaps the brain experiences similar difficulties in recognizing randomness.
However, I believe that there issome mathematical property that allows you to more effectively separate these patterns. If someone else decides to spend his time searching, then the xy coordinates for the three sets of points are in the text file .
Addendum : this is just a brief recommendation - if you read so far, continue reading comments. They have a lot of valuable. I want to thank all those who spent their time to offer alternative explanations or algorithms and to point out the weaknesses in my analysis. Special thanks to themathsgeek, who, 40 minutes after posting, wrote a much better program for calculating discrepancies. I also thank Iain, who tested my impromptu reasoning about perceiving random patterns with real experiments.