Parsing pictures into text: a simple algorithm
The roots of history go back to those years when one of the clans of the ancient text-based game “Fight Club” ordered me, a young Perl programmer, to add captcha for the game. A couple of sleepless nights - and four even digits are ready, along with input verification.

A few days later another, no less respected clan came and ordered the parser of the same captcha. To analyze it, I had to spend much more time, there was no Ocrad then, but a very simple and working way was found.
A week later, the third, and most deserved clan in the game came, and ordered a new captcha. After a couple of months of pulling the blankets, almost all the top clans were enriched with new artifact pictures, their programmers on a pile of colorful pieces of paper, the project on a bunch of nonsense generators, and I personally had invaluable experience.
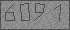


More recently, this experience came in handy for parsing thousands of phone numbers from one of the sites from an image back to text. The algorithm used is the same, and I want to share it. Here is a screwdriver and a hammer, and what you collect with them - a synchrophasotron or a gravitating gun - is already your own business.
I wrote all this first in Perl, and then in PHP, but it’s not worth it to bore anyone with listings, right?
Step 1. Image to the matrix.
We parse the image into a two-dimensional matrix of the form a xy , or a [x] [y], if you like it more.
We assign a value to each element of the matrix - the color of the pixel.
We count the number of pixels of different colors, the information about this is entered in a regular array.
Step 2. We get rid of excess.
An image, even if taken from a GIF that stores no more than 256 colors, still requires a reduction in the amount of information. Reduce the number of colors: we discard all values that are less than at least 50% of the color that has the most references in our array. From a seemingly monochrome image, usually four colors remain. This is a list of primary colors.
Step 3. Next is the funniest: make total Sharpen and Grayscale. Watch your hands:
Create a new two-dimensional matrix b [x] [y]. We will write the results in it.
Take four adjacent pixels - a square.
If at least one of the colors of these pixels remains in the list of primary colors - we write in the new matrix b [0] [0] = X. If there is none, write b [0] [0] = 0.
Take the following 4 pixels. Repeat until the end of the matrix, and in the case of large images, the operation can even be run twice. Just do not get carried away - the more complex the image, the more difficult it will be to compare further.
The result is such a beauty:
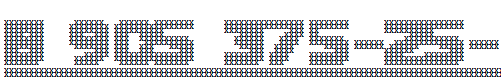
Something in this is from childhood, when school taught to write zip codes, right?
The simplest thing remains: to explain to the computer that the graphic image, consisting of crosses and zeros, may well be a decimal digit. To do this, we divide the matrix into pieces-submatrices by symbols, and compare them with the standard. Unfortunately, the standard for each captcha is different, and each time you have to adjust it, albeit slightly.
At the very end, we are saved by the Olivier algorithm for comparing similar strings, which is used in the finished PHP function int similar_text (str, str) . Of course, the shorter the length of the lines, the faster they are checked, so I compared the first line in the “recognized” character with the first line of the standard, the second with the second, and so on to the end.
Forty thousand phone numbers were recognized with an error of 1 piece. Now to make the algorithm more universal - and a million in our pocket, right?
A few days later another, no less respected clan came and ordered the parser of the same captcha. To analyze it, I had to spend much more time, there was no Ocrad then, but a very simple and working way was found.
A week later, the third, and most deserved clan in the game came, and ordered a new captcha. After a couple of months of pulling the blankets, almost all the top clans were enriched with new artifact pictures, their programmers on a pile of colorful pieces of paper, the project on a bunch of nonsense generators, and I personally had invaluable experience.
More recently, this experience came in handy for parsing thousands of phone numbers from one of the sites from an image back to text. The algorithm used is the same, and I want to share it. Here is a screwdriver and a hammer, and what you collect with them - a synchrophasotron or a gravitating gun - is already your own business.
I wrote all this first in Perl, and then in PHP, but it’s not worth it to bore anyone with listings, right?
Step 1. Image to the matrix.
We parse the image into a two-dimensional matrix of the form a xy , or a [x] [y], if you like it more.
We assign a value to each element of the matrix - the color of the pixel.
We count the number of pixels of different colors, the information about this is entered in a regular array.
Step 2. We get rid of excess.
An image, even if taken from a GIF that stores no more than 256 colors, still requires a reduction in the amount of information. Reduce the number of colors: we discard all values that are less than at least 50% of the color that has the most references in our array. From a seemingly monochrome image, usually four colors remain. This is a list of primary colors.
Step 3. Next is the funniest: make total Sharpen and Grayscale. Watch your hands:
Create a new two-dimensional matrix b [x] [y]. We will write the results in it.
Take four adjacent pixels - a square.
If at least one of the colors of these pixels remains in the list of primary colors - we write in the new matrix b [0] [0] = X. If there is none, write b [0] [0] = 0.
Take the following 4 pixels. Repeat until the end of the matrix, and in the case of large images, the operation can even be run twice. Just do not get carried away - the more complex the image, the more difficult it will be to compare further.
The result is such a beauty:
Something in this is from childhood, when school taught to write zip codes, right?
The simplest thing remains: to explain to the computer that the graphic image, consisting of crosses and zeros, may well be a decimal digit. To do this, we divide the matrix into pieces-submatrices by symbols, and compare them with the standard. Unfortunately, the standard for each captcha is different, and each time you have to adjust it, albeit slightly.
At the very end, we are saved by the Olivier algorithm for comparing similar strings, which is used in the finished PHP function int similar_text (str, str) . Of course, the shorter the length of the lines, the faster they are checked, so I compared the first line in the “recognized” character with the first line of the standard, the second with the second, and so on to the end.
Forty thousand phone numbers were recognized with an error of 1 piece. Now to make the algorithm more universal - and a million in our pocket, right?