PLC program error search sequence
Introduction
Quite often in the literature I came across descriptions of errors and even classifying them by type.
Although, I must admit, I can’t really recall a single case when it would help me to know which type the particular error belongs to. Unless after clarifying the reasons for explaining them to others.
But how people calculated the place and got to the bottom of the error was always interesting to me.
System Information and Error
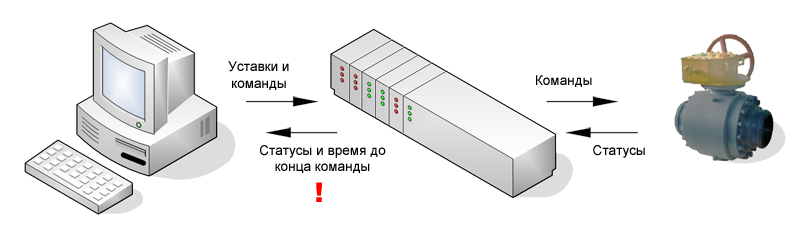
The settings (times, mode flags) and commands to the device are sent to the PLC from the computer.
Signals of the device status and the time until the end of the command for this device are issued from the PLC to the computer. Signals are packed into words to minimize the amount of reception and transmission.
Commands are issued from the PLC to the device.
The device issues its status to the PLC.
Initially, everything worked, but after some time when giving commands, the statuses on the computer in SCADA began to blink out of business and generally behave extremely unfriendly. And only in one place, at one object.
But "saber dancing" appeared stably, with each team, which was very pleased.
Search
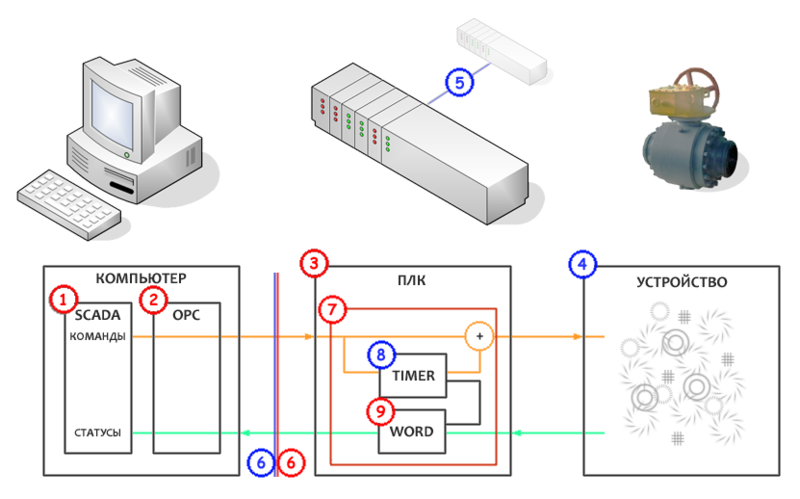
The numbers in parentheses indicate the locations of the checks corresponding to the numbers in the diagram below.
The principles and dependencies of blinking are not immediately understood. Perhaps due to fatigue, perhaps due to a lack thereof.
It was found that the error is present not only in SCADA (1) (where it was actually detected), but also in the OPC server (2) .
Further analysis showed that the error is also present in the PLC, at least in the word formed for the computer (3) .
Checking for an error in the status coming from the device - marks the device as a possible source of the problem.
Manual status changes from a device do not change anything. When changing the status from the device by forcing (forcedly, constantly) the error is still saved.
Accordingly, these are not impulses that are not visible during monitoring (4) .
Comparison with codes of other objects on which this error is not present - does not produce differences. Complete identity. The probability of error in the PLC program is reduced (5) .
The computer shuts down, as a possible source of error, recording something in this memory area. The error is saved. The probability of error due to the computer tends to zero. Accordingly, no matter what, the problem is still in the PLC (6) .
Note: It was also possible, by disabling the PLC, manually changing the status in the OPC. But this option was technically more difficult, and in general, these two checks are almost equivalent.
Transferring the status word transferred from the PLC to the computer to another area of the PLC memory does nothing. The error is saved.
Transferring a piece of code with an error to another block (conditionally a function) also does not affect the error. Accordingly, the likelihood that this is influenced by some other extraneous team writing there something of their own is negligible. The point is this piece.
Codes are gradually removed, and there remains almost a minimum at which an error is saved (7)
- Submission of a command (without it it is not clear how to check).
- The timer from which the time is taken before the command is reset.
- Formation of a word on the computer from the status and time to reset the command.
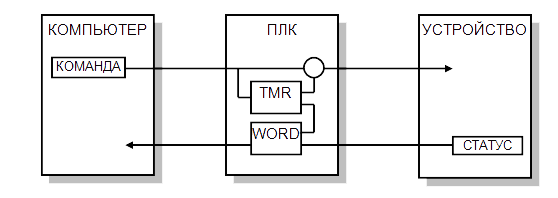
The timer is deleted. The command is not reset, but the error disappears and the statuses stop jumping.
A new timer is inserted instead. Carefully inspected for absurdities. The timer is the most ordinary, nothing unusual. There are 200 more of them in the program. But an error appears (8)
The signal formation from the PLC is considered as the most likely candidate for the source of the error. The signal is packed for compactness in one word, status bits in high byte, time in low. Three teams:
- Writing device statuses to the low byte of a word.
- Replacing high and low bytes with SWAP_WORD command (statuses are transferred to high byte)
- By AND write time to the least significant byte of the word
It seems nothing unusual, and a completely identical system works with dozens of identical devices around. The brain creaks and refuses to help.
The sequence of packing instructions per word is replaced by one that works identically, but consisting of other operators (9):
- Writing device time to the least significant byte of a word.
- In an intermediate variable, statuses are multiplied by 256, shifting to the high byte of the word.
- By OR, status is recorded in the high byte of the word.
Everything worked.
After analysis - the situation becomes completely clear.
The reason for the error:
Operators increased the standard timeout time from 1.5 to 10 minutes.
And if 1.5 minutes is 90 seconds, then 10 minutes is 600 seconds.
600 seconds did not fit into the low byte (maximum 256), and part of the time was written in the high byte.
The essence of the last check:
When recording the time first, and only then the status - the status was blocked by overflow bits coming from the time value. And with the reverse sequence of commands, time, on the contrary, scored status with its bits.
Decision:
Time and statuses were divided into 2 words. Local engineers were asked to perform maintenance or replace the device with a timeout exceeding the standard time by more than 5 times.
conclusions
The described error is not particularly complicated, but in my opinion is pretty nice in terms of indicativeness.
In fact, it is not very important where exactly the error is sought - in electronics, in the PLC, on the computer or elsewhere. General principles are always about the same:
- To the maximum, collect information about the problem - where and how it appears. Oscilloscopes, sniffers, utilities from Rusinovich, logs, thermometers, in general, everything that can be used in this case. Does it depend on the time of year, the arrival of a cleaning lady, or barometric pressure.
- Get out of suspicion as much as possible. Cutting tracks on printed circuit boards, disabling tags, removing individual computers from the system. Worse, if there are any feedbacks and other handshakes. Then you can either try to organize the test taking into account the absence of a part of the system, or try to emulate a part, for example, artificially supplying a signal to the feedback input. In general, think.
- If possible, bring each test to the end, even if suddenly a “thought!” Appears. Because the “thought!” May not work (and it often doesn’t work offensively), but you’ll lose the results of the check.
- In the remaining piece - to change everything that causes suspicion. If this software - try reinstalling or replacing it with a similar one. In principle, there is an option to start from this point. I personally saw an engineer repairing a board with 40-50 chips of the K155 series, biting them all and soldering new ones. But this, in my opinion, is rather an example of how not to do it. Because even if everything works, you won’t get specifics. Moreover, in the described case, this option did not pass and the malfunction persisted. In general - I did not say that.
Although, of course, recipes for some situations can be completely useless in relation to others.
But all errors have a specific reason, and this reason can always be clarified.
For example, the tractor driver with a harrow driving over the cable was somehow the reason. And although there were no difficulties in eliminating it, they were enough in the process of writing a recommendation to avoid repetition ... I
apologize for the likely difficulty of reading.
The topic is not very artistic, plus I tried to reduce it by skipping not very significant points, such as the forced abandonment of BreakPoints, due to the cyclical execution of the program in the PLC and the presence of a timer.