How we overclocked the work with the parameters of the configuration of the frontal system
Hi, Habr! My name is Sergey Lezhnin, I am a senior architect in Sbertech. One of the directions of my work is the Unified Frontal System. In this system there is a service for managing configuration parameters. It is used by many users, services and applications, which requires high performance. In this post, I will tell you how this service evolved from the first, simplest, to its current version and why we eventually deployed the entire architecture 180 degrees.

This is where we started - this is the first implementation of the parameter management service:
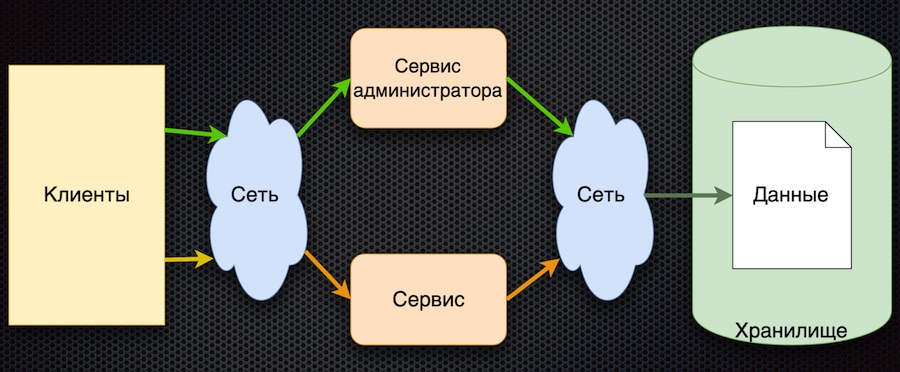
The client requests configuration settings from the service. The service translates the request to the database, receives the response and returns it to the client. In parallel, administrators can control the parameters using their own service: add new values, change current ones.
The advantage of this approach is one - simplicity. More disadvantages, even though they are all related:
To undergo load testing, this architecture had to provide a load of no more than that which goes through a direct access to the database. As a result, the load testing of this circuit failed.
Stage two: we decided to cache the data on the service side.

Here, the data is initially loaded into the shared cache upon request and returned from the cache upon subsequent requests. The service administrator not only manages the data, but also marks it in the cache so that it will be updated when changed.
So we reduced the number of calls to the repository. At the same time, data synchronization turned out to be simple, since the administrator service has access to the cache in memory and manages the reset of parameters. On the other hand, if a network failure occurs, the client will not be able to get the data. And in general, the logic of obtaining data becomes more complicated: if the data is not in the cache, you need to get it from the database, put it in the cache, and then return it. It is necessary to develop further.
The third stage of development is client-side data caching:
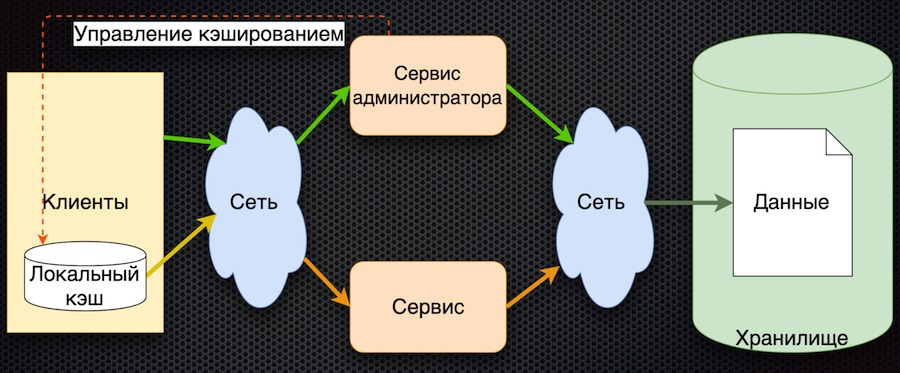
The client has a shell for accessing the service (“client module”), which hides the local data cache. If you do not find the required data in the cache, the service is accessed. The service requests parameters from the database and returns them. Compared to the previous scheme, caching management is complicated here. In order to reset the parameters, the service must inform the customers that a change has occurred in these parameters.
In this architecture, we reduce the number of calls to the service and to the database. Now, if the parameter is already requested, it will return to the client without accessing the network, even if the service or database is not available. On the other hand, the big minus is that the logic of data exchange with the client becomes complicated, it is necessary to notify him additionally through some service - for example, the message queue. The client must subscribe to the topic, he receives notification of changes in the parameters, and in his cache, the client must reset them to get new values. Quite a complicated scheme.
Finally, we come to the last stage at the moment. This helped us the basic principles formulated in Reactive Manifesto.
The scheme corresponding to this approach turned out to be quite simple:
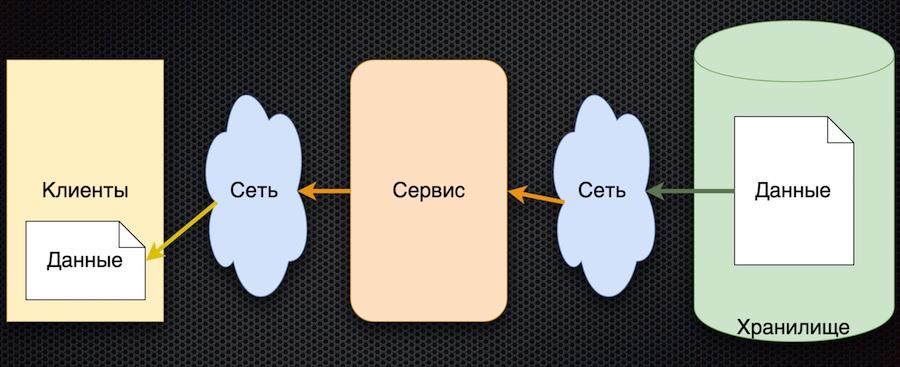
The general principle is this: the client subscribes to the configuration parameter, and when its values change, the server notifies the client about it. The scheme above is slightly simplified: it does not reflect that when a client signs up, he needs to initialize and get the initial value. But then there is the main thing in it: the arrows changed direction. Previously, the client or cache actively requested the service to change data, and now the service itself transmits data change events, and they are updated from the client.
This architecture has several important advantages. The number of calls to the service and storage is reduced, because the client is not actively requesting it. In fact, the call for each desired parameter occurs only once, when subscribing to it. The client then simply receives the stream of changes. The availability of data increases because the client always has a value — it is cached. On the whole, this parameter exchange scheme is quite simple.
The only drawback of such an architecture is uncertainty during initialization of data. Until the first subscription update was made, the value of the parameter remains undefined. But this can be solved by setting the client default values of the parameters, which are replaced by the actual when the first update.
Having approved the scheme, we began to search for products for its implementation. Choose between Vertx.io , Akka.io and Spring Boot .

The table summarizes the characteristics we were interested in. Vertx and Akka have actors, while Sping Boot has a microservice library that is essentially close to the actors. Similarly, with reactivity: Spring Boot has its own WebFlux library that implements the same features. Lightness, we estimated approximately within the table. As for languages, Vertx is considered polyglot of the three options: it supports both Java, and Scala, and Kotlin, and JavaScript. Akka has Scala and Java; Kotlin, probably, can also be used, but there is no direct support. Spring has Java, Kotlin and Groovy.
As a result, Vertx won. By the way, they talked a lot about him at the JUG conference, and indeed many companies use it. Here is a screenshot from the developer's website:

On Vertx.io, the scheme for implementing our solution is as follows:

We decided to store the parameters not in the database, but in the Git repository. We can easily use this relatively slow data source due to the fact that the client does not actively request parameters and the number of hits decreases.
A reader (verticle) reads data from a Git repository into the memory of an application to speed up user access to data. This is important, for example, when subscribing to parameters. In addition, the reader processes updates — rereads and marks data, replaces old data with new ones.
Event Bus is a Vertx service that sends events between verticals, as well as outside, through bridges. Including through the websocket-bridge, which is used in this case. When parameter change events arrive, the Event Bus sends them to the client.
Finally, on the client side, a simple web client is implemented here that subscribes to events (parameter changes) and displays these changes on the pages.
We show how everything works through a web application.
Launch the application page in the browser. Subscribe to change data by key. Then we go to the project page in the local GitLab, change the data in JSON format and save it to the repository. The application displays the corresponding change, which is what we needed.
That's all. You can find the source code of the demo in my git repository , and ask questions in the comments.
This is where we started - this is the first implementation of the parameter management service:
The client requests configuration settings from the service. The service translates the request to the database, receives the response and returns it to the client. In parallel, administrators can control the parameters using their own service: add new values, change current ones.
The advantage of this approach is one - simplicity. More disadvantages, even though they are all related:
- frequent access to the repository over the network,
- high competition of access to the database (it is located on one node),
- insufficient performance.
To undergo load testing, this architecture had to provide a load of no more than that which goes through a direct access to the database. As a result, the load testing of this circuit failed.
Stage two: we decided to cache the data on the service side.
Here, the data is initially loaded into the shared cache upon request and returned from the cache upon subsequent requests. The service administrator not only manages the data, but also marks it in the cache so that it will be updated when changed.
So we reduced the number of calls to the repository. At the same time, data synchronization turned out to be simple, since the administrator service has access to the cache in memory and manages the reset of parameters. On the other hand, if a network failure occurs, the client will not be able to get the data. And in general, the logic of obtaining data becomes more complicated: if the data is not in the cache, you need to get it from the database, put it in the cache, and then return it. It is necessary to develop further.
The third stage of development is client-side data caching:
The client has a shell for accessing the service (“client module”), which hides the local data cache. If you do not find the required data in the cache, the service is accessed. The service requests parameters from the database and returns them. Compared to the previous scheme, caching management is complicated here. In order to reset the parameters, the service must inform the customers that a change has occurred in these parameters.
In this architecture, we reduce the number of calls to the service and to the database. Now, if the parameter is already requested, it will return to the client without accessing the network, even if the service or database is not available. On the other hand, the big minus is that the logic of data exchange with the client becomes complicated, it is necessary to notify him additionally through some service - for example, the message queue. The client must subscribe to the topic, he receives notification of changes in the parameters, and in his cache, the client must reset them to get new values. Quite a complicated scheme.
Finally, we come to the last stage at the moment. This helped us the basic principles formulated in Reactive Manifesto.
- Responsive: the system responds as quickly as possible.
- Resilient: the system continues to respond even in the event of a failure.
- Elastic: the system uses resources according to the load.
- Message Driven: provides asynchronous and free messaging between system components.
The scheme corresponding to this approach turned out to be quite simple:
The general principle is this: the client subscribes to the configuration parameter, and when its values change, the server notifies the client about it. The scheme above is slightly simplified: it does not reflect that when a client signs up, he needs to initialize and get the initial value. But then there is the main thing in it: the arrows changed direction. Previously, the client or cache actively requested the service to change data, and now the service itself transmits data change events, and they are updated from the client.
This architecture has several important advantages. The number of calls to the service and storage is reduced, because the client is not actively requesting it. In fact, the call for each desired parameter occurs only once, when subscribing to it. The client then simply receives the stream of changes. The availability of data increases because the client always has a value — it is cached. On the whole, this parameter exchange scheme is quite simple.
The only drawback of such an architecture is uncertainty during initialization of data. Until the first subscription update was made, the value of the parameter remains undefined. But this can be solved by setting the client default values of the parameters, which are replaced by the actual when the first update.
Technology selection
Having approved the scheme, we began to search for products for its implementation. Choose between Vertx.io , Akka.io and Spring Boot .
The table summarizes the characteristics we were interested in. Vertx and Akka have actors, while Sping Boot has a microservice library that is essentially close to the actors. Similarly, with reactivity: Spring Boot has its own WebFlux library that implements the same features. Lightness, we estimated approximately within the table. As for languages, Vertx is considered polyglot of the three options: it supports both Java, and Scala, and Kotlin, and JavaScript. Akka has Scala and Java; Kotlin, probably, can also be used, but there is no direct support. Spring has Java, Kotlin and Groovy.
As a result, Vertx won. By the way, they talked a lot about him at the JUG conference, and indeed many companies use it. Here is a screenshot from the developer's website:
On Vertx.io, the scheme for implementing our solution is as follows:
We decided to store the parameters not in the database, but in the Git repository. We can easily use this relatively slow data source due to the fact that the client does not actively request parameters and the number of hits decreases.
A reader (verticle) reads data from a Git repository into the memory of an application to speed up user access to data. This is important, for example, when subscribing to parameters. In addition, the reader processes updates — rereads and marks data, replaces old data with new ones.
Event Bus is a Vertx service that sends events between verticals, as well as outside, through bridges. Including through the websocket-bridge, which is used in this case. When parameter change events arrive, the Event Bus sends them to the client.
Finally, on the client side, a simple web client is implemented here that subscribes to events (parameter changes) and displays these changes on the pages.
How things work
We show how everything works through a web application.
Launch the application page in the browser. Subscribe to change data by key. Then we go to the project page in the local GitLab, change the data in JSON format and save it to the repository. The application displays the corresponding change, which is what we needed.
That's all. You can find the source code of the demo in my git repository , and ask questions in the comments.