Glusterfs + erasure coding: when you need a lot, cheap and reliable
Glaster in Russia has very few people, and any experience is interesting. We have it big and industrial and, judging by the discussion in the last post , it is in demand. I talked about the very beginning of the experience of transferring backups from Enterprise Storage to Glusterfs.
This is not hardcore enough. We did not stop and decided to collect something more serious. Therefore, we will discuss such things as erasure coding, sharding, rebalancing and throttling, load testing, and so on.

The task is simple: to collect a cheap but reliable stack. As cheap as possible, reliable — so that it is not scary to keep our own files on sale. Until. Then, after long tests and backups to another storage system, it is also client-side.
Application (sequential IO) :
- Backups
- Test infrastructures
- Test repository for heavy media files.
We are here.
- Combat file dumping and serious test infrastructures
- Storage for important data.
Like last time, the main requirement is the network speed between instances of Glaster. 10G at first is normal.
Dispersed volume is based on erasure coding (EC) technology, which provides quite effective protection against disk or server failures. It's like RAID 5 or 6, but not quite. It stores the encoded file fragment for each brik in such a way that only a subset of the fragments stored on the remaining bricks is required to restore the file. The number of bricks that may be unavailable without losing access to the data is configured by the administrator during volume creation.
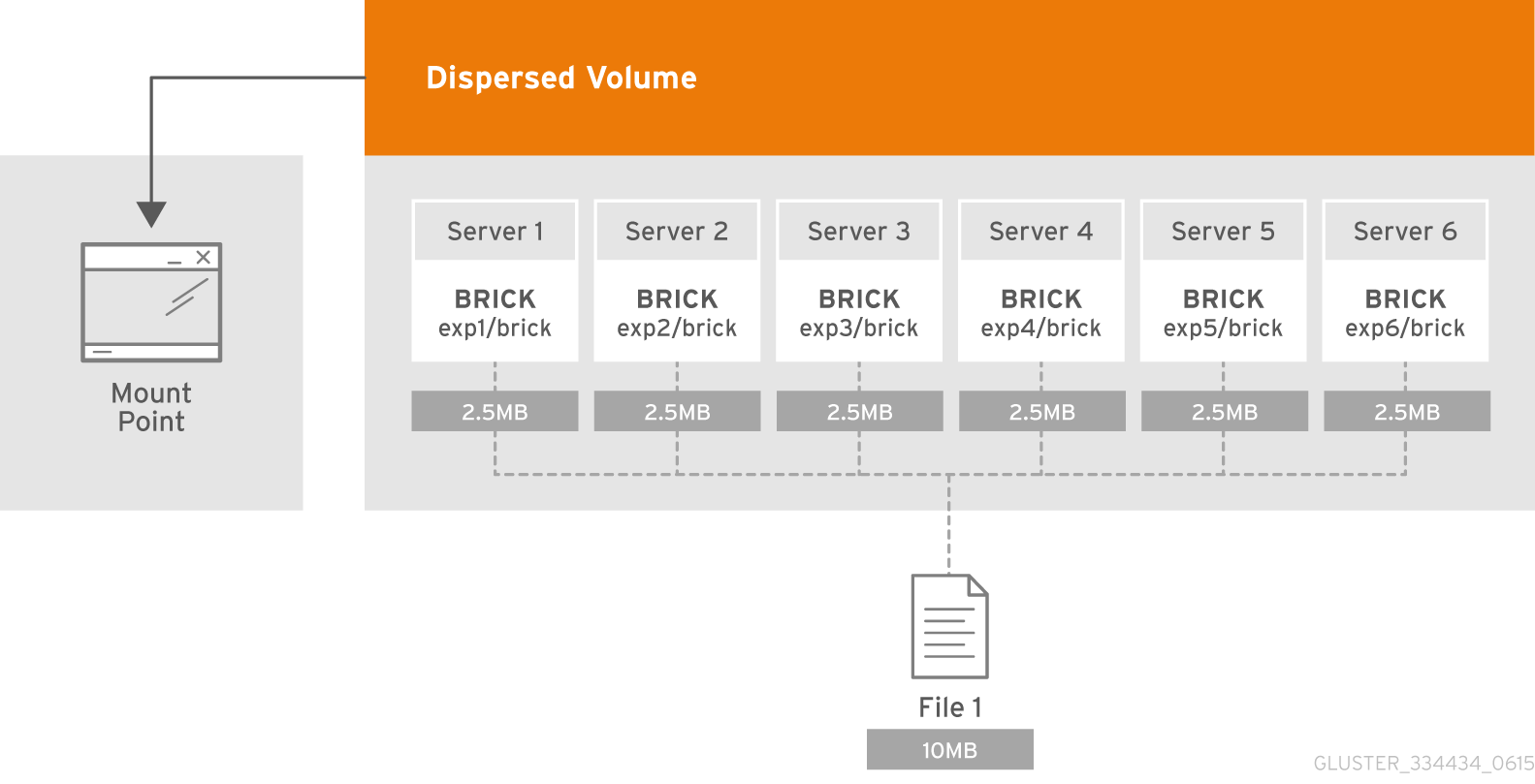
The essence of a subvolume in GlusterFS terminology appears along with distributed volums. In distributed-disperced erasure, coding will work just within the framework of a subevolume. And in the case of, for example, with distributed-replicated data will be replicated within the framework of the subevolume.
Each of them is spread to different servers, which allows them to be freely lost or output to sync. In the figure, servers (physical) are marked in green, dashed lines are sub-volums. Each of them is presented as a disk (volume) to an application server:

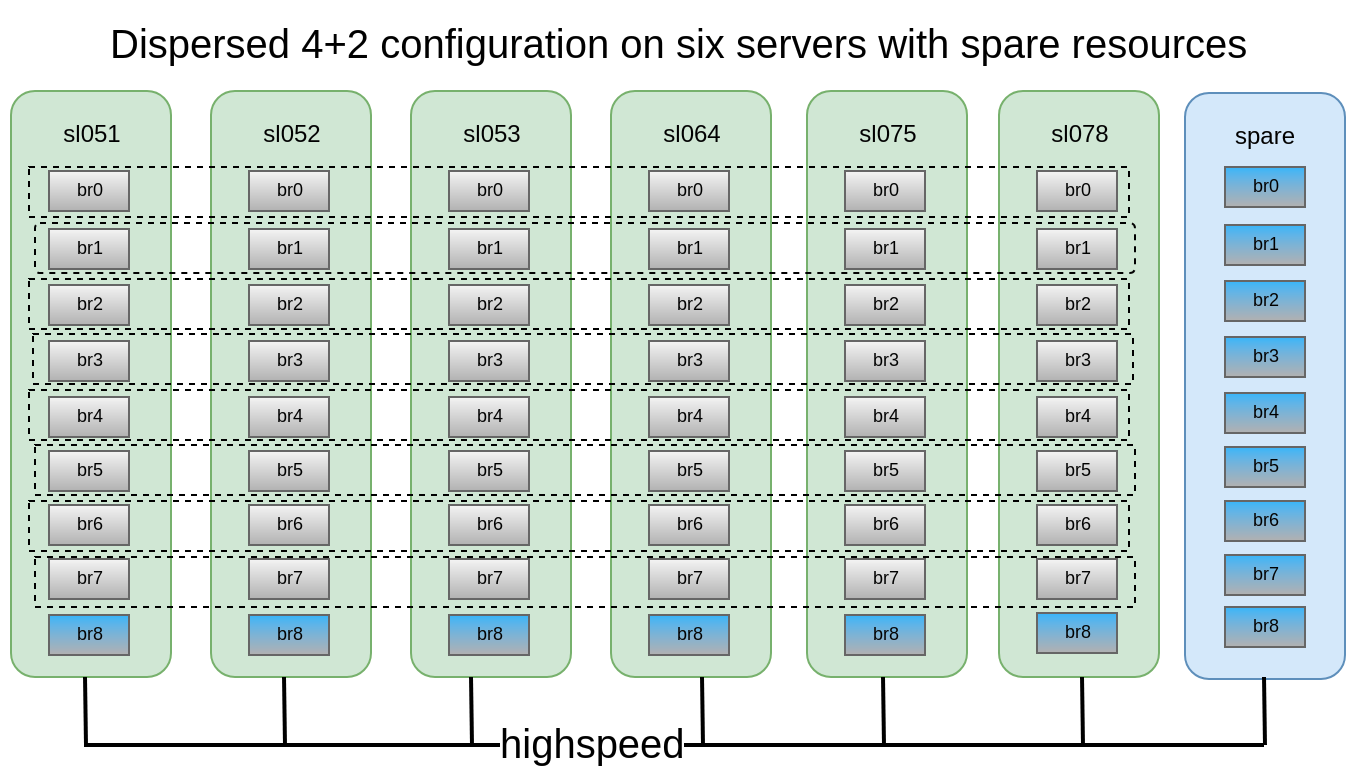
It was decided that the distributed-dispersed 4 + 2 configuration on 6 nodes looks quite reliable, we can lose 2 any servers or 2 disks within each subevolution while continuing to have access to data .
We had 6 old DELL PowerEdge R510 with 12 disk slots and 48x2TB 3.5 SATA disks. In principle, if there are servers with 12 disk slots, and having disks on the market up to 12TB, we can collect a storage of up to 576TB of usable space. But do not forget that even though the maximum HDD sizes continue to grow from year to year, their performance stays in place and a 10-12TB rebuild disk can take you a week.

Creating the volume: A
detailed description of how to prepare bricks, you can read in my previous post
We create, but do not rush to run and mount, as we still have to apply several important parameters.
What we got:
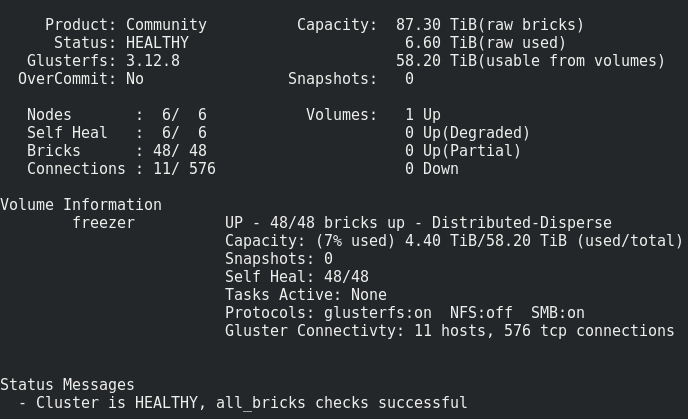
Everything looks quite normal, but there is one nuance.
It consists in writing to the bricks of such a volum:
Files are put alternately into subvolumes, rather than being spread evenly over them, therefore, sooner or later we will abut in its size, and not in the size of the whole volume. The maximum size of the file that we can put in this storage is = the useful size of the subspace minus the space already occupied on it. In my case it is <8 TB.
What to do? How to be?
This problem is solved by sharding or stripe wolume, but, as practice has shown, the stripe works very badly.
Therefore, we will try sharding.
What is sharding, in detail here .
What is sharding, briefly :
Each file that you put in the volume will be divided into parts (shards), which are relatively evenly decomposed into sub-volums. The shard size is specified by the administrator, the default value is 4 MB.
Turn on sharding after creating a volume, but before it started :
We set the size of the shard (which one is optimal? Guys from oVirt recommend 512MB) :
Empirically, it turns out that the actual size of the shard in a briquette using dispersed voluum 4 + 2 is equal to shard-block-size / 4, in our case 512M / 4 = 128M.
Each shard according to the logic of erasure coding is decomposed into bricks within a sub-volum: 4 * 128M + 2 * 128M
Draw failure cases that the gluster of this configuration goes through:
In this configuration, we can survive a fall of 2 nodes or 2 any disks within one subevolum .
For the tests, we decided to slip the resulting storage under our cloud and run fio from the virtual machines.
We turn on sequential recording with 15 VMs and do the following.
Rebut of the 1st node:
17:09
It looks uncritical (~ 5 seconds of inaccessibility using the ping.timeout parameter).
17:19
Launched heal full.
The number of heal entries is only growing, probably due to the large level of writing to the cluster.
17:32
It was decided to turn off recording from VM.
The number of heal entries has begun to decrease.
17:50
heal done.
Rebut 2 nodes:
The same results are observed as with the 1st node.
Rebut 3 nodes:
The mount point was issued by the Transport endpoint is not connected, the VMs received an ioerror.
After switching on the nodes, Glaster recovered himself, without intervention from our side, and the process of treatment began.
But 4 out of 15 VMs could not get up. I saw errors on the hypervisor:
Hardly repay 3 nodes with sharding turned off
Also losing data, can not be restored.
Gently extinguish 3 nodes with sharding, will there be data corruption?
Yes, but significantly less (coincidence?), Lost 3 disks out of 30.
Conclusions:
It is also very important to test disc replacement cases.
Departures of bricks (disks):
17:20
We knock out the brik:
17:22
One can see such a drawdown at the moment of replacing the brik (recording from 1 source):

The replacement process is quite long, with a small recording level per cluster and default settings of 1 TB, it is treated for about a day.
Adjustable treatment options:
Option: disperse.background-heals
Default Value: 8
Description:
Option: disperse.heal-wait-qlength
Default Value: 128
Description: can wait
Option: disperse.shd-max-threads
Default Value: 1
Description: Maximum number of parallel heals. If you don’t have any storage space, you can’t keep it.
Option: disperse.shd-wait-qlength
Default Value: 1024
Description:
Option: disperse.cpu-extensions
Default Value: auto
Description: force the accelerate the galois field computations.
Option: disperse. Self-heal-window-size
Default Value: 1
Description: Maximum number of blocks (128KB).
Stand out:
With the new parameters of 1 TB of data, it took 8 hours to complete (3 times faster!) The
unpleasant moment is that the result is a breeze larger than it
was:
became:
Need to understand. Probably, it's about inflating thin discs. With the subsequent replacement of the increased brika size remained the same.
Rebalancing:
After expanding or shrinking (using the add-brick and remove-brick commands respectively), you need to rebalance. In all non-replicated volume, all bricks should be changed. In a replicated volume, it should not be up.
Shaping rebalancing:
Option: cluster.rebal-throttle
Default Value: normal
Description: Sets the maximum number of parallel file migrations during the rebalance operation. The default value is normal and it allows a max of [($ (processing units) - 4) / 2), 2] files to b
migrated at a time. Lazy will allow only one file to be migrated at a time and aggressive will allow max of [($ (processing units) - 4) / 2) 4]
Option: cluster.lock-migration
Default Value: off
Description: If enabled this the will of the migrate feature posix locks the associated with a file DURING rebalance
the Option: cluster.weighted-rebalance
the Default the Value: on
the Description: for When the enabled, files is will of the BE to the Allocated bricks with a Probability proportional to Their size bed. Otherwise, all bricks will have the same probability.
Comparing the record, and then reading the same parameters fio (for more detailed results of performance tests - in a personal):



If interested, compare the speed of rsync to traffic to Gluster nodes:
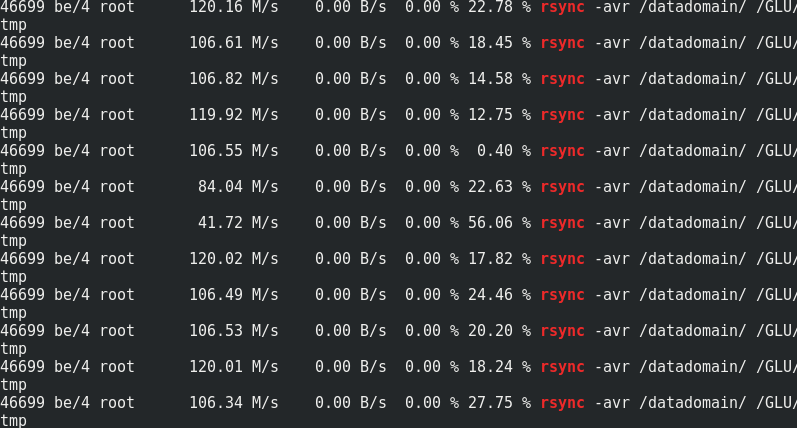

It can be seen that approximately 170 MB / s / traffic to 110 MB / s / payload. It turns out that this is 33% of additional traffic, as well as 1/3 of Erasure Coding redundancy.
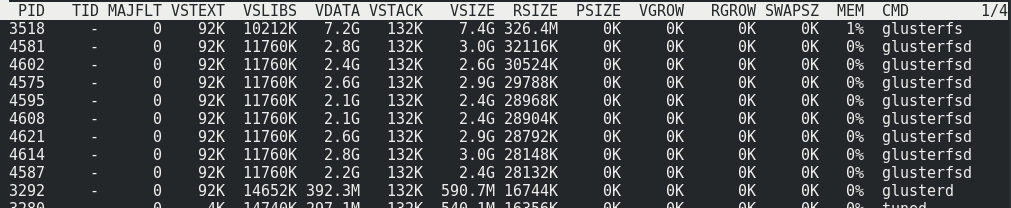
The memory consumption on the server side with the load and almost without it does not change:
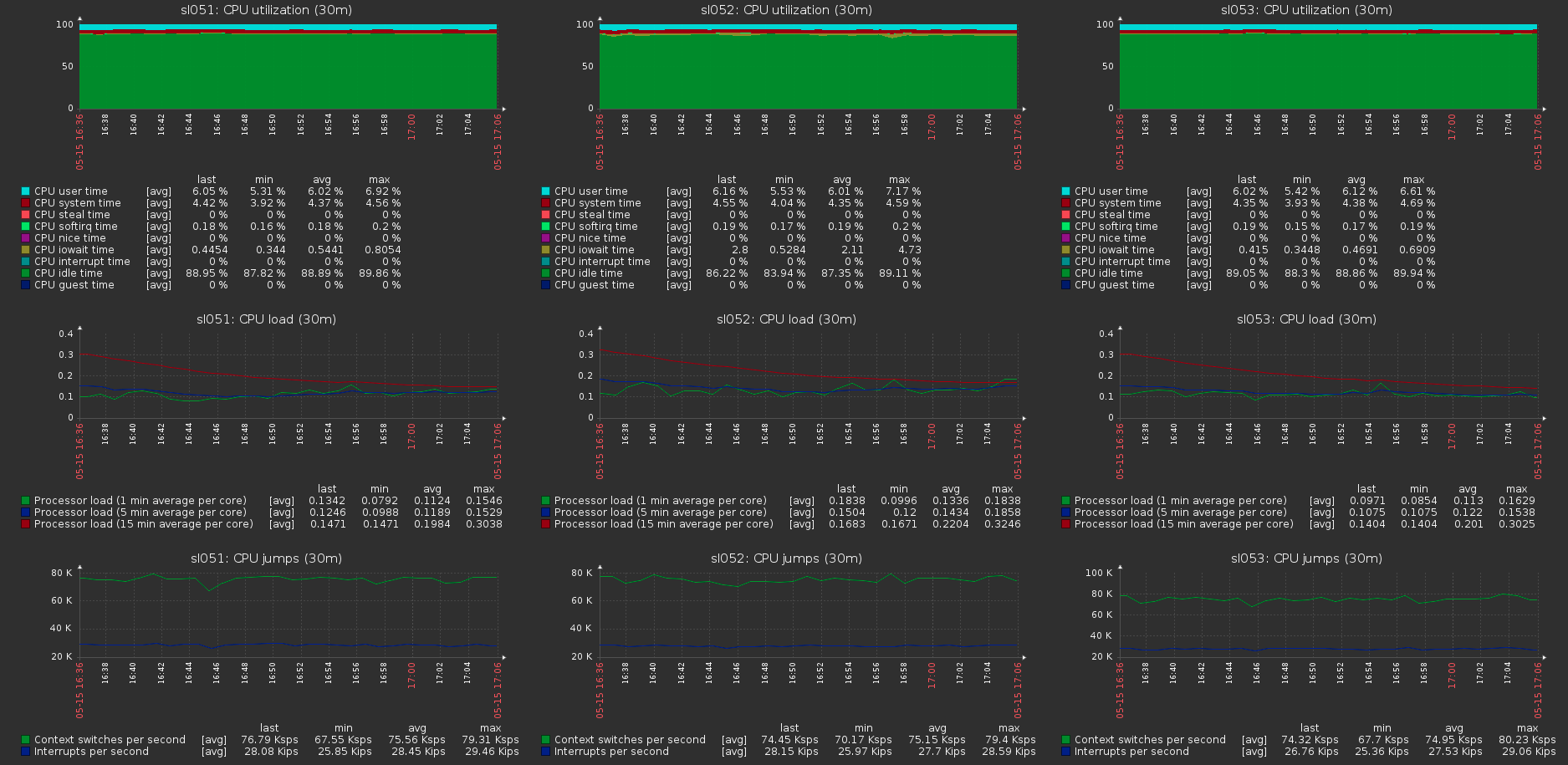
The load on the cluster hosts at the maximum load on the Volyum:
This is not hardcore enough. We did not stop and decided to collect something more serious. Therefore, we will discuss such things as erasure coding, sharding, rebalancing and throttling, load testing, and so on.
- More theory of volumas / subevolumes
- hot spare
- heal / heal full / rebalance
- Conclusions after reboot 3 nodes (never do this)
- How does the recording affect the subwoofer load at different speeds from different VMs and shard on / off
- rebalance after discing
- fast rebalance
What they wanted
The task is simple: to collect a cheap but reliable stack. As cheap as possible, reliable — so that it is not scary to keep our own files on sale. Until. Then, after long tests and backups to another storage system, it is also client-side.
Application (sequential IO) :
- Backups
- Test infrastructures
- Test repository for heavy media files.
We are here.
- Combat file dumping and serious test infrastructures
- Storage for important data.
Like last time, the main requirement is the network speed between instances of Glaster. 10G at first is normal.
Theory: what is dispersed volume?
Dispersed volume is based on erasure coding (EC) technology, which provides quite effective protection against disk or server failures. It's like RAID 5 or 6, but not quite. It stores the encoded file fragment for each brik in such a way that only a subset of the fragments stored on the remaining bricks is required to restore the file. The number of bricks that may be unavailable without losing access to the data is configured by the administrator during volume creation.
What is a subvolume?
The essence of a subvolume in GlusterFS terminology appears along with distributed volums. In distributed-disperced erasure, coding will work just within the framework of a subevolume. And in the case of, for example, with distributed-replicated data will be replicated within the framework of the subevolume.
Each of them is spread to different servers, which allows them to be freely lost or output to sync. In the figure, servers (physical) are marked in green, dashed lines are sub-volums. Each of them is presented as a disk (volume) to an application server:
It was decided that the distributed-dispersed 4 + 2 configuration on 6 nodes looks quite reliable, we can lose 2 any servers or 2 disks within each subevolution while continuing to have access to data .
We had 6 old DELL PowerEdge R510 with 12 disk slots and 48x2TB 3.5 SATA disks. In principle, if there are servers with 12 disk slots, and having disks on the market up to 12TB, we can collect a storage of up to 576TB of usable space. But do not forget that even though the maximum HDD sizes continue to grow from year to year, their performance stays in place and a 10-12TB rebuild disk can take you a week.
Creating the volume: A
detailed description of how to prepare bricks, you can read in my previous post
gluster volume create freezer disperse-data 4 redundancy 2 transport tcp \
$(for i in {0..7} ; doecho {sl051s,sl052s,sl053s,sl064s,sl075s,sl078s}:/export/brick$i/freezer ; done)We create, but do not rush to run and mount, as we still have to apply several important parameters.
What we got:
Everything looks quite normal, but there is one nuance.
It consists in writing to the bricks of such a volum:
Files are put alternately into subvolumes, rather than being spread evenly over them, therefore, sooner or later we will abut in its size, and not in the size of the whole volume. The maximum size of the file that we can put in this storage is = the useful size of the subspace minus the space already occupied on it. In my case it is <8 TB.
What to do? How to be?
This problem is solved by sharding or stripe wolume, but, as practice has shown, the stripe works very badly.
Therefore, we will try sharding.
What is sharding, in detail here .
What is sharding, briefly :
Each file that you put in the volume will be divided into parts (shards), which are relatively evenly decomposed into sub-volums. The shard size is specified by the administrator, the default value is 4 MB.
Turn on sharding after creating a volume, but before it started :
gluster volume set freezer features.shard onWe set the size of the shard (which one is optimal? Guys from oVirt recommend 512MB) :
gluster volume set freezer features.shard-block-size 512MBEmpirically, it turns out that the actual size of the shard in a briquette using dispersed voluum 4 + 2 is equal to shard-block-size / 4, in our case 512M / 4 = 128M.
Each shard according to the logic of erasure coding is decomposed into bricks within a sub-volum: 4 * 128M + 2 * 128M
Draw failure cases that the gluster of this configuration goes through:
In this configuration, we can survive a fall of 2 nodes or 2 any disks within one subevolum .
For the tests, we decided to slip the resulting storage under our cloud and run fio from the virtual machines.
We turn on sequential recording with 15 VMs and do the following.
Rebut of the 1st node:
17:09
It looks uncritical (~ 5 seconds of inaccessibility using the ping.timeout parameter).
17:19
Launched heal full.
The number of heal entries is only growing, probably due to the large level of writing to the cluster.
17:32
It was decided to turn off recording from VM.
The number of heal entries has begun to decrease.
17:50
heal done.
Rebut 2 nodes:
The same results are observed as with the 1st node.
Rebut 3 nodes:
The mount point was issued by the Transport endpoint is not connected, the VMs received an ioerror.
After switching on the nodes, Glaster recovered himself, without intervention from our side, and the process of treatment began.
But 4 out of 15 VMs could not get up. I saw errors on the hypervisor:
2018.04.27 13:21:32.719 ( volumes.py:0029): I: Attaching volume vol-BA3A1BE1 (/GLU/volumes/33/33e3bc8c-b53e-4230-b9be-b120079c0ce1) with attach type generic...
2018.04.27 13:21:32.721 ( qmp.py:0166): D: Querying QEMU: __com.redhat_drive_add({'file': u'/GLU/volumes/33/33e3bc8c-b53e-4230-b9be-b120079c0ce1', 'iops_rd': 400, 'media': 'disk', 'format': 'qcow2', 'cache': 'none', 'detect-zeroes': 'unmap', 'id': 'qdev_1k7EzY85TIWm6-gTBorE3Q', 'iops_wr': 400, 'discard': 'unmap'})...
2018.04.27 13:21:32.784 ( instance.py:0298): E: Failed to attach volume vol-BA3A1BE1 to the instance: Device 'qdev_1k7EzY85TIWm6-gTBorE3Q' could not be initialized
Traceback (most recent call last):
File "/usr/lib64/python2.7/site-packages/ic/instance.py", line 292, in emulation_started
c2.qemu.volumes.attach(controller.qemu(), device)
File "/usr/lib64/python2.7/site-packages/c2/qemu/volumes.py", line 36, in attach
c2.qemu.query(qemu, drive_meth, drive_args)
File "/usr/lib64/python2.7/site-packages/c2/qemu/_init_.py", line 247, in query
return c2.qemu.qmp.query(qemu.pending_messages, qemu.qmp_socket, command, args, suppress_logging)
File "/usr/lib64/python2.7/site-packages/c2/qemu/qmp.py", line 194, in query
message["error"].get("desc", "Unknown error")
QmpError: Device 'qdev_1k7EzY85TIWm6-gTBorE3Q' could not be initialized
qemu-img: Could not open '/GLU/volumes/33/33e3bc8c-b53e-4230-b9be-b120079c0ce1': Could not read image for determining its format: Input/output error
Hardly repay 3 nodes with sharding turned off
Transport endpoint is not connected (107)
/GLU/volumes/e0/e0bf9a42-8915-48f7-b509-2f6dd3f17549: ERROR: cannot read (Input/output error)Also losing data, can not be restored.
Gently extinguish 3 nodes with sharding, will there be data corruption?
Yes, but significantly less (coincidence?), Lost 3 disks out of 30.
Conclusions:
- Heal of these files hangs endlessly, rebalance does not help. We come to the conclusion that the files that were actively recording when the 3rd node was turned off were irretrievably lost.
- Never reboot more than 2 nodes in a 4 + 2 configuration in production!
- How not to lose data if you really want to reboot 3 + nodes? P stop writing to the mount point and / or stop volume.
- Replacing a node or brika should be done as soon as possible. For this, it is highly desirable to have, for example, 1-2 a la hot-spare bricks in each node for quick replacement. And one more spare node with bricks in case of a node's drop.
It is also very important to test disc replacement cases.
Departures of bricks (disks):
17:20
We knock out the brik:
/dev/sdh 1.9T 598G 1.3T 33% /export/brick617:22
gluster volume replace-brick freezer sl051s:/export/brick_spare_1/freezer sl051s:/export/brick2/freezer commit forceOne can see such a drawdown at the moment of replacing the brik (recording from 1 source):
The replacement process is quite long, with a small recording level per cluster and default settings of 1 TB, it is treated for about a day.
Adjustable treatment options:
gluster volume set cluster.background-self-heal-count 20
# Default Value: 8# Description: This specifies the number of per client self-heal jobs that can perform parallel heals in the background.
gluster volume set cluster.heal-timeout 500
# Default Value: 600# Description: time interval for checking the need to self-heal in self-heal-daemon
gluster volume set cluster.self-heal-window-size 2
# Default Value: 1# Description: Maximum number blocks per file for which self-heal process would be applied simultaneously.
gluster volume set cluster.data-self-heal-algorithm diff
# Default Value: (null)# Description: Select between "full", "diff". The "full" algorithm copies the entire file from source to # sink. The "diff" algorithm copies to sink only those blocks whose checksums don't match with those of # source. If no option is configured the option is chosen dynamically as follows: If the file does not exist # on one of the sinks or empty file exists or if the source file size is about the same as page size the # entire file will be read and written i.e "full" algo, otherwise "diff" algo is chosen.
gluster volume set cluster.self-heal-readdir-size 2KB
# Default Value: 1KB# Description: readdirp size for performing entry self-healOption: disperse.background-heals
Default Value: 8
Description:
Option: disperse.heal-wait-qlength
Default Value: 128
Description: can wait
Option: disperse.shd-max-threads
Default Value: 1
Description: Maximum number of parallel heals. If you don’t have any storage space, you can’t keep it.
Option: disperse.shd-wait-qlength
Default Value: 1024
Description:
Option: disperse.cpu-extensions
Default Value: auto
Description: force the accelerate the galois field computations.
Option: disperse. Self-heal-window-size
Default Value: 1
Description: Maximum number of blocks (128KB).
Stand out:
disperse.shd-max-threads: 6
disperse.self-heal-window-size: 4
cluster.self-heal-readdir-size: 2KB
cluster.data-self-heal-algorithm: diff
cluster.self-heal-window-size: 2
cluster.heal-timeout: 500
cluster.background-self-heal-count: 20
cluster.disperse-self-heal-daemon: enable
disperse.background-heals: 18With the new parameters of 1 TB of data, it took 8 hours to complete (3 times faster!) The
unpleasant moment is that the result is a breeze larger than it
was:
Filesystem Size Used Avail Use% Mounted on
/dev/sdd 1.9T 645G 1.2T 35% /export/brick2became:
Filesystem Size Used Avail Use% Mounted on
/dev/sdj 1.9T 1019G 843G 55% /export/hot_spare_brick_0Need to understand. Probably, it's about inflating thin discs. With the subsequent replacement of the increased brika size remained the same.
Rebalancing:
After expanding or shrinking (using the add-brick and remove-brick commands respectively), you need to rebalance. In all non-replicated volume, all bricks should be changed. In a replicated volume, it should not be up.
Shaping rebalancing:
Option: cluster.rebal-throttle
Default Value: normal
Description: Sets the maximum number of parallel file migrations during the rebalance operation. The default value is normal and it allows a max of [($ (processing units) - 4) / 2), 2] files to b
migrated at a time. Lazy will allow only one file to be migrated at a time and aggressive will allow max of [($ (processing units) - 4) / 2) 4]
Option: cluster.lock-migration
Default Value: off
Description: If enabled this the will of the migrate feature posix locks the associated with a file DURING rebalance
the Option: cluster.weighted-rebalance
the Default the Value: on
the Description: for When the enabled, files is will of the BE to the Allocated bricks with a Probability proportional to Their size bed. Otherwise, all bricks will have the same probability.
Comparing the record, and then reading the same parameters fio (for more detailed results of performance tests - in a personal):
fio --fallocate=keep --ioengine=libaio --direct=1 --buffered=0 --iodepth=1 --bs=64k --name=test --rw=write/read --filename=/dev/vdb --runtime=6000
If interested, compare the speed of rsync to traffic to Gluster nodes:
It can be seen that approximately 170 MB / s / traffic to 110 MB / s / payload. It turns out that this is 33% of additional traffic, as well as 1/3 of Erasure Coding redundancy.
The memory consumption on the server side with the load and almost without it does not change:
The load on the cluster hosts at the maximum load on the Volyum: