Ivan Tulup: asynchronism in JS under the hood
Are you familiar with Ivan Tulup? Most likely, yes, you just don’t know what kind of person it is, and that you need to take great care of the state of its cardiovascular system.
About this and how asynchrony works in JS under the hood, how the Event Loop works in browsers and in Node.js, are there any differences and maybe similar things were told by Mikhail Bashurov ( SaitoNakamura ) in his report on RIT ++ We are pleased to share with you the decoding of this informative presentation.

About Speaker: Mikhail Bashurov - fullstack web developer at JS and .NET from Luxoft. He likes beautiful UI, green tests, transpilation, compilation, compiler allowing technique and improved dev experience.
From the editor:Mikhail's report was accompanied not just by slides, but by a demo project in which you can click on the buttons and see for yourself how to do the task. The best option would be to open the presentation in the adjacent tab and periodically refer to it, but the text will be given links to specific pages. And now we pass the word to the speaker, enjoy reading.
I had a candidacy for Ivan Tulup.

But I decided to go a more conformist way, so meet - grandfather Ivan Tulup!

Actually, you only need to know about two things:
You may have heard that cases of heart disease and mortality from them have recently become more frequent. Probably the most common heart disease is a heart attack, that is, a heart attack.
What is interesting about heart attack?
We have a coronary artery that supplies blood to the muscle (myocardium). If the blood starts to get sick of it, the muscle gradually dies off. Naturally, this has a very negative effect on the heart and on its work.
Grandfather Ivan Tulup also has a heart, and it beats. But our heart pumps blood, and the heart of Ivan Tulup pumps our code and our tasks.
Task: a large circle of blood circulation
What is task? What could be the browser in general? Why are they even needed?
For example, we execute code from a script. This is one heartbeat, and now we have blood flow. We clicked on the button and subscribed to the event — the event handler was spat out — the Callback that we sent. Put setTimeout, Callback worked - one more task. And so in parts, one heartbeat is one task.

There are many different sources of taskes, according to the specification of a huge number. Our heart continues to beat, and while it beats, we are fine.
Event Loop in the browser: a simplified version
This can be represented in a very simple diagram.
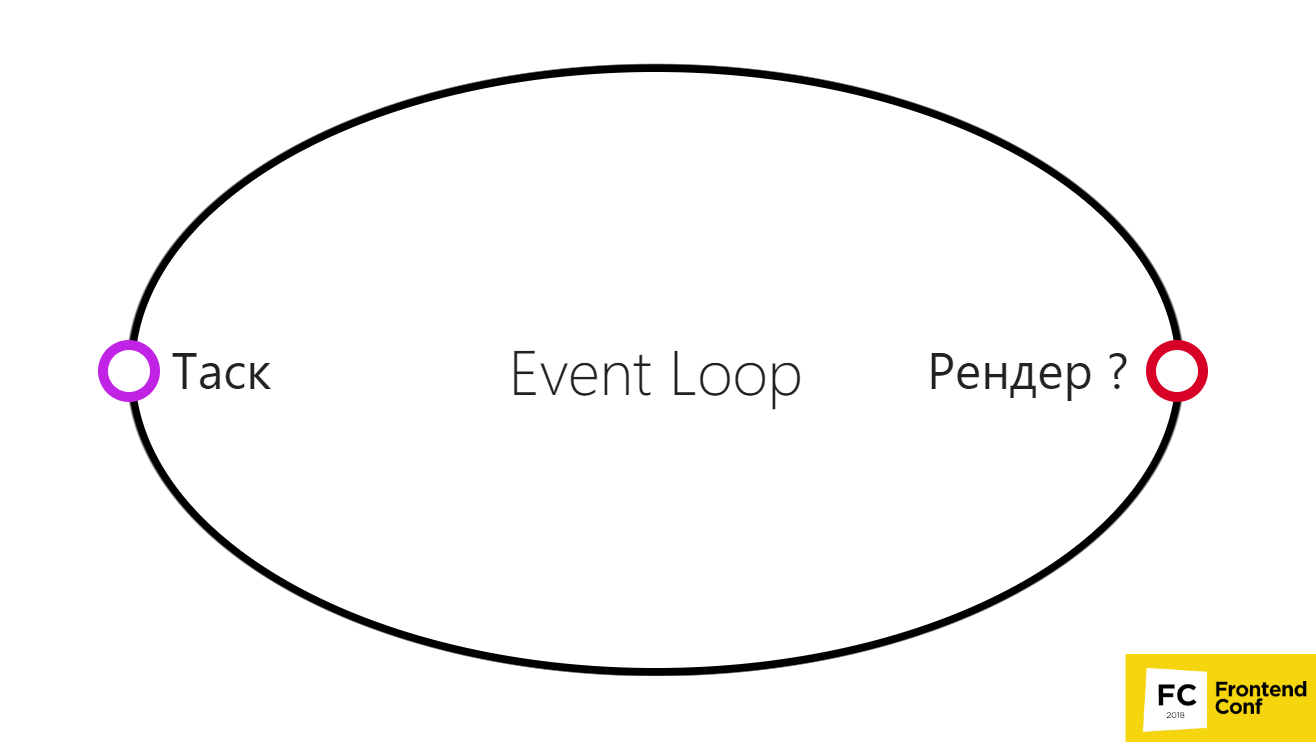
But in fact, this is not necessary, because in some cases the browser may not render the render between two tasks.
This can happen, for example, if the browser can decide to group several timeouts or multiple scrolling events. Or at some point something goes wrong, and the browser decides instead of 60 fps (the usual frame rate so that everything goes cool and smooth) to show 30 fps. Thus, he will have much more time to execute your code and other useful work, he will be able to perform several tasks.
Therefore, the render is actually not necessarily performed after each task.
Taski: classification
There are two types of potential operations:
CPU bound is our useful work, which we do (we consider, display, etc.)
I / O bound - these are the points at which we can divide our tasks. It may be:
Then CPUbound is:
Of course, the crypt can be mine on the GPU, but I think - the GPU, the CPU - you understand this analogy.
In the end, it turns out that our heart beats: it performs one TASK, the second, the third, until we do something wrong. For example, we go through an array of 1 million elements and count the sum. It would seem that it is not so difficult, but it can take considerable time. If we constantly occupy tangible time without releasing the task, our render cannot be performed. He hangs in this task, and that's it - the arrhythmia begins.
I think everyone understands that arrhythmia is a rather unpleasant heart disease. But you can still live with him. What happens if you put a task that just hangs the entire event loop in an endless loop? You put a thrombus in the coronary or some other artery, and everything will be very sad. Unfortunately, our grandfather Ivan Tulup will die.
That grandfather Ivan died ...

For us, this means that the entire tab will freeze at all - you will not be able to click on anything, and then Chrome will say: “Aw, Snap!”
This is even worse than the bugs on the website when something went wrong. But if everything is hanging at all, moreover, probably, the CPU has loaded and everything has hung up for the user, then he will most likely never go to your site.
Therefore, the idea is this: we have a task, and we do not need to hang out for a very long time in this task. We need to quickly release it so that the browser, if anything, can render (if it wants). If you do not want - fine, dance!
Philip Roberts Demo: Loupe by Philip Roberts
Consider an example :
The point is this: we have a button, we subscribe to it (addEventListener), we call Timeout for 5 s and write “Hello, world!” To console.log, write Timeout to setTimeout, we write Click on onClick.
What will happen if we run it and repeatedly click on the button - when will Timeout actually be executed? Let's see the demo:
The code starts to execute, gets on the stack, Timeout goes. Meanwhile, we clicked on the button. At the bottom of the queue added a few events. While the Click is running, Timeout is waiting, although 5 seconds has passed.
Here onClick runs quickly, but if you put a longer task, then in general everything will hang, as has been clarified earlier. This is a very simplified example. There is one line here, but in browsers this is actually not the case.
In what order are the events executed - what does the HTML specification say about this?
She says the following: we have 2 concepts:
Task source is a kind of task. This can be a user interaction, that is, onClick, onChange is something the user interacts with; or timers, that is, setTimeout and setInterval, or PostMessages; or generally completely wild Canvas Blob Serialization types task source is also a separate type.
The specification says that for the same task source, tasks will be guaranteed to be executed in the order of addition. For everything else, nothing is guaranteed, because the task queue can be an unlimited number. The browser itself decides how many they will be. Using the task queue and creating them, the browser can prioritize certain tasks.
Browser Priorities and Task Queues
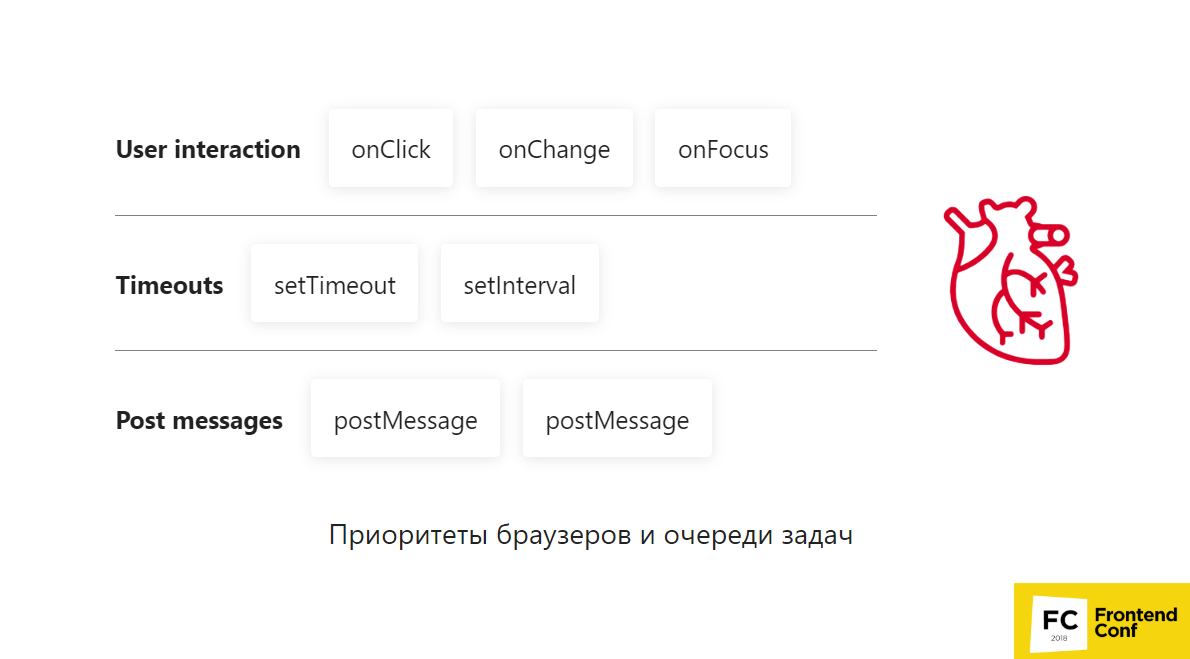
Imagine that we have 3 queues:
The browser starts to get hacks from these queues:
This again is also a very simplified example, and, unfortunately, no one can guarantee how it will work in browsers , because they themselves decide it all. You need to test it yourself if you want to find out what it is.
For example, postMessages are more priority than setTimeout. You may have heard about such a thing as setImmediate, which, for example, in IE browsers was only native. But there are polyfiles that are mostly not based on setTimeout, but on creating a postMessages channel and subscribing to it. This works generally faster because browsers prioritize this.
Well, these tasks are done here. At what point do we finish performing our task and understand that we can take the next one, or what can we render?
A stack is a simple data structure that works on the principle of "last in - first out", i.e. “I put the last one - you get it first” . The closest, probably the real equivalent is a deck of cards. Therefore, our grandfather Ivan Tulup loves to play cards.
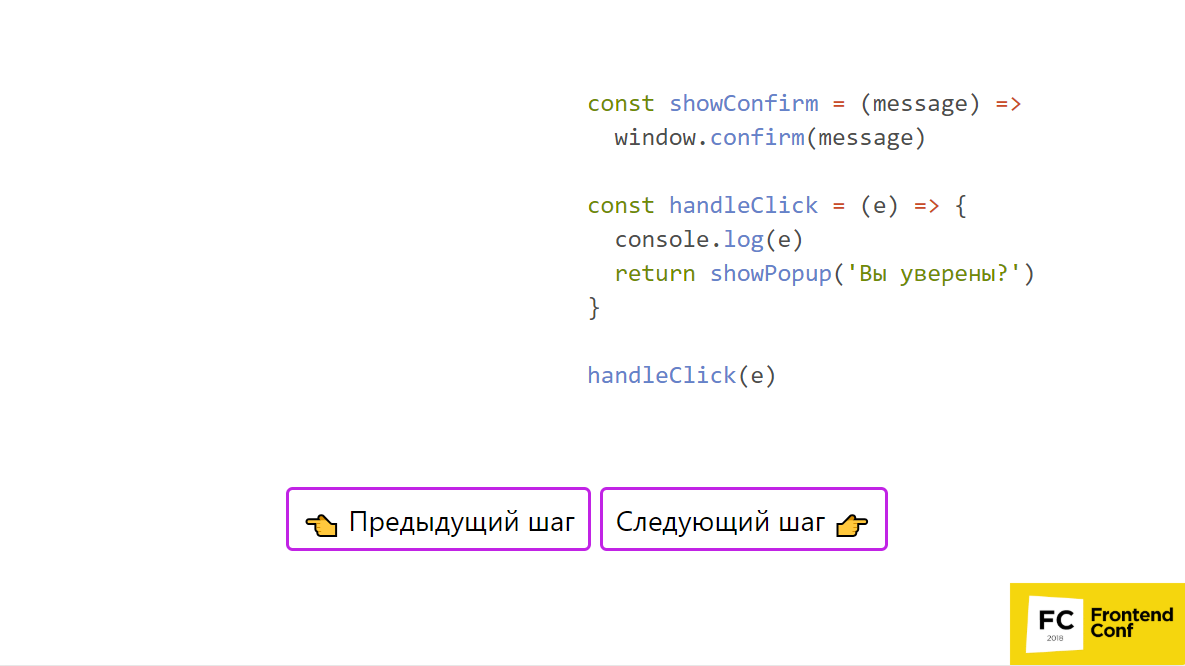
Above is an example in which there is some code, the same example can be poked into the presentation . In some place we call handleClick, enter console.log, call showPopup and window. confirm. Let's form a stack.
We have nothing more - we do it. A window will pop up: “Are you sure?”, Click on “Yes”, and everything will leave the stack. Now we have finished the showConfirm body and the handleClick body. Our stack is cleared and you can proceed to the next task. Question: well, I now know that it is necessary to break it all into small pieces. How can I, for example, do this in the most elementary case?
Let's look at the most "in the forehead" example. Immediately I warn you: please do not try to repeat this at home - it will not compile.

We have a large, large array, and we want to calculate something on it, for example, parse some binary data. We can just break it into chunks: process this piece, this and this. We choose the size of the chunk, say, 10 thousand elements, we consider how many chunks we will have. We have the parseData function, which is included in the CPU bound and can really do something heavy. Then we divide the array into chunks, setTimeout (() => parseData (slice), 0).
In this case, the browser will again be able to prioritize User interaction and render the render in between. So at least you let go of your Event Loop, and it continues to work. Your heart keeps beating, and that's good.
But this is really a very "in the forehead" example. Now browsers have many APIs that will help to do this in a more specialized way.
In addition to setTimeout and setInterval, there are APIs that go beyond the limits of tasks, such as, for example, requestAnimationFrame and requestIdleCallback.
Probably many people are familiar with requestAnimationFrame , and even use it already. It is performed before the render. Its charm is that, firstly, it tries to run every 60 fps (or 30 fps), secondly, this is all done immediately before creating the CSS Object Model, etc.

Therefore, even if you have multiple requestAnimationFrame, they will actually group all the changes, and the frame will be complete. In the case of setTimeout, of course, you cannot receive such a guarantee and guarantee it One setTimeout will change one thing, another another, and between this a render may slip through - you will have jerking of the screen or something else. RequestAnimationFrame for this fits perfectly.
In addition, there is a requestIdleCallback.Maybe you heard that it is used in React v16.0 (Fiber). RequestIdleCallback works in such a way that if the browser understands that it has time between frames (60 fps) to do something useful, and at the same time they did everything - did the task, did requestAnimationFrame - everything seems to be cool, then can give out small quanta, say, 50 ms for you to do something (IDLE mode).
It is not on the diagram above, because it is not in a particular place. The browser can decide to place it before the frame, after the frame, between the requestAnimationFrame and the render, after the task, before the task. No one can guarantee this.
It’s guaranteed that if you have work that is not related to changing the DOM (because then requestAnimationFrame is animation and so on), while it’s not super priority, but tangible, requestIdleCallback is your way out.
So, if we have a long CPU bound operation, then we can try to break it apart.
Browser Tasking Results:
The problem is that our Ivan Tulup is an old grandfather, because the implementations of the Event Loop in browsers are also very old. They were created before the specification was written, so the specification, unfortunately, is respected as long as. Even if you read that the specification should be so, no one guarantees that all browsers have supported it. So be sure to check in browsers how it actually works.
Grandfather Ivan Tulup in browsers is a man of little predictable, with some interesting features, we must remember this.
Terminator Santa: Loop Mascot in Node.js
Node.js is more like someone like that.

Because on the one hand it is the same grandfather with a beard, but at the same time everything is distributed in phases and clearly spelled out where what is being done.
Phases of the Event Loop in Node.js:
Everything except the last is not very clear what it means. The phases have such strange names, because under the hood, as we already know, we have Libuv in order to rule everyone:
Thousands of them all!
In addition, Libuv also provides the same Event Loop. There are no specifics of Node.js in it, but there are phases, and Node.js simply uses them. But for some reason she took the names from there.
Let's see what each phase actually means.
Phase Timers performs:
Phase pending callbacks
Prior to this, the documentation phase was called I / O callbacks. Most recently, this documentation has been corrected, and it has ceased to contradict itself. Prior to this, in one place it was written that I / O callbacks are executed in this phase, in another - that in the poll phase. But now everything is written there clearly and well, so read the documentation - something will become much more understandable.
In the pending callback phase, callbacks from some system operations (TCP error) are executed. That is, if in Unix there is an error in the TCP-socket, in this case, he wants not to throw it out right away, but in a callback that will just be executed during this phase. That's all we need to know about her. It is practically not interesting to us.
Phase Idle, prepare
In this phase, we cannot do anything at all, so we forget about it in principle.

Phase poll
This is the most interesting phase in Node.js, because it does the main useful work:
Looking ahead, setImmediate will be executed at the next check phase, that is, guaranteed before the timers.
Also, the poll phase controls the Event Loop flow. For example, if we have no timers, no setImmediate, that is, no one did the timer, setImmediate did not call, we just block in this phase and wait for an event from the I / O if something comes to us, if there are any callbacks , if we subscribed to something.
How is a non-blocking model implemented? For example, with the same Epoll, we can subscribe to an event — we open the socket and wait for something written in it. In addition, the second argument is timeout, i.e. we will wait for Epoll, but if the timeout ends, and the event from the I / O does not come, then it will exit the timeout. If we receive an event from the network (someone writes in the socket), it will come.
Therefore, the poll phase gets from the heap (a heap is a data structure that allows for a well-sorted retrieval and delivery) of the earliest callback, takes its timeout, writes down at this timeout and releases everything. Thus, even if no one in our socket writes, timeout will work, return to the poll phase and work will continue.
Sadly, in other phases it is not. If you add 10 billion timeout, you add 10 billion timeout. Therefore, the next phase is the check phase.
Here setImmediate is executed. The phase is beautiful because the setImmediate, called in the poll phase, is guaranteed to execute earlier than the timer. Because the timer will only be on the next tick at the very beginning, and from the poll phase earlier. Therefore, we can not be afraid of competition with other timers and use this phase for those things that we don’t want for some reason to perform in a callback.
This phase does not perform all of our callback socket closures and other types:
She executes them only if this event took off unexpectedly, for example, someone at the other end sent: “Everything — close the socket — go here, Vasya!” Then this phase will work, because the event is unexpected. But we are not particularly affected.
What will happen if we have the same pattern that we took in browsers with setTimeout, put it on Node.js - that is, we divide the array into chunks; for each chunk we will make setTimeout - 0.
Do you think there are any problems with this?
I already ran a little ahead when I said that if we add 10 thousand timeout (or 10 billion!), There will be 10 thousand timers in the queue, and he will get them and execute - there is no protection against this: get - execute, get - perform and so on to infinity.
Only the poll phase, if we constantly receive an event from I / O, all the time in the socket, someone writes something, so that we at least can set the timers and setImmediate, have protection for the limit, and system-dependent. That is, it will be different on different operating systems.
Unfortunately, other phases, including timers and setImmediate, do not have such protection. Therefore, if you do the same as in the example, everything will hang on you and it won't take very long to reach the poll phase.
How do you think something will change if we replace setTimeout (() => parseData (slice), 0) with setImmediate (() => parseData (slice))? - Naturally, no, there is also no protection in the check phase.
To solve this problem, you can call recursive processing .
The bottom line is that we took the function parseData and wrote its recursive call, but not just ourselves, but through setImmediate. When you call it in the setImmediate phase, then it hits the next tick, and not the current one. Therefore, it will release the Event Loop, it will go further in a circle. That is, we have recursiveAsyncParseData, where we pass a certain index, fetch a chunk on this index, parse it - and then put the setImmediate in the queue with the next index. He will get us to the next tick, and we can thus recursively handle the whole thing.
True, the problem is that it is still some kind of CPU bound task. Perhaps she will still somehow weigh and take time in the Event Loop. Most likely, you want your Node.js to have a pure I / O bound.
Therefore, it is better to use some other things for this, for example, process fork / thread pool.
Now we know about Node.js that:
You should also be careful with thread pool, because Node.js and so many things run there, in particular, DNS resolving, because for some reason, the DNS function DNS is not asynchronous. Therefore, it is necessary to execute it in ThreadPool. On Windows, fortunately, not the case. But there and files can be read asynchronously. In Linux, unfortunately, is impossible.
In my opinion, the standard limit is 4 processes in a ThreadPool. Therefore, if you actively do something there, it will compete with everyone else - with fs and others. You can consider increasing the ThreadPool, but also very carefully. Therefore, read something on this topic.
We have Tasks in Node.js and Tasks in browsers. You may have already heard about microtasks. Let's see what it is and how they work, and start with browsers.
Microtasks in browsers
To understand how microtasks work, let's turn to the whatWg standard Event Loop algorithm, that is, let's go into the specification and see how it all looks.

Translating into human language, it looks like this:

They are performed in the place indicated in the diagram, and in several other places that we will soon find out. That is, the task is over, microtasks are executed.
The important thing is not Promise itself, but Promise.then. That callback that was placed in the then is a microtask. If you called 10 then - you have 10 micro-strokes, 10 thousand then - 10 thousand micro-strokes.
How many people use the mutation observer?
I think that few use the Mutation observer. Most likely, Promise.then is used more, therefore we will consider it in the example.
Features of microtask checkpoint:
This is an interesting point. It turns out that you can generate new microtasks and we will execute them all to the end. What can it lead us to?

We have two hearts. The first heart I animated JS animation, and the second - CSS-animation. There is another great feature called starveMicrotasks. We call Promise.resolve, and then we put the same function in then.
Look in the presentation for what happens if you call this function.
Yes, the heart of JS will stop, because we add a micro-drag, and then we add a micro-drag in it, and then we add a micro-drag in it ... And so endlessly.
That is, a recursive call microtasks hang everything. But, it would seem, I have everything asynchronous! Should be let go, I called setTimeout there. Not! Unfortunately, you need to be careful with microtasks, so if you somehow use a recursive call, be careful - you can block everything.
In addition, as we remember, microtasks are executed at the end of stack cleaning. We remember what a stack is. It turns out that as soon as we got out of our code, the setTimeout callback was executed — that's all — the microtasks went right away. This can lead to interesting side effects.
Consider an example .

There is a button and a gray container in which it lies. We subscribe to click and buttons, and container. Events, as we know, float, that is, they will appear here and there.
In handlers, we do 2 things:
In the handler itself, we then enter "FUS", and in the handler on the container - "DAH!" (When we have an event pops up).
Do you think that we will appear in the console? In these messages there is a small hint, and oddly enough, it will be displayed “FUS RO DAH!” Excellent! Everything works as we expected.

Now let's consider exactly the same example, but earlier we clicked on the button and the browser called the handler for us, but now we will programmatically call this click. It would seem - what's the difference. Do you think something will change or not?

Of course change! Because otherwise I would not ask this question.

Let's see why this happens.
So, we have our first code, which has a queue of microtasks, and we have a stack. You can see how this is all done in the first case..
It would seem that everything is cool and everything is logical. Why is the next example wrong with us? Let's follow the execution flow in the second case :
But our synchronous method (click) did not end, because there are still other handlers there, and the stack is not cleared. Therefore, we go to divHandleClick and, of course, execute console.log ('DAH!') Executed. And only after that we have cleared the stack, and we can execute our microduck.
This is very unpleasant, for example, when we call button.click in all sorts of tests.
With this, it is easy to shoot yourself in the foot. Event popup is used, for example, in modal windows. It often happens that a modal window is closed if you click it outside.
This is usually implemented as follows: we subscribe to the document (click) and the modal window container itself (also to click). If we clicked somewhere and it reached the modal window, we stopPropagation. If not, then it comes to the document, a click pops up, we understand that we have clicked somewhere outside, close the window.
And what if some evil genius (or junior programmer) tries to build an interesting logic - like we click on the “Confirm” button, we have a promise that resolves, and then in then we decide whether to close something or not . In this case, it turns out that there will be one behavior in the interface, and another in the tests: either the test will fall, and the interface will not fall, or vice versa. It will be very unpleasant. Therefore, it is better not to be tied to this behavior at all, not to try to invent something on top of this and make it as simple as possible.
Now most browsers (I tested 4) work well with microtasks, and this is all done correctly in the right order. But before that it was not, and no one, unfortunately, can guarantee that there will be no bugs or any additional tricky cases. So it is better to do simply and not be tied to this implementation.
On microtasks in browsers, we learned that:
That is, in fact, in the middle of the task, they can also be executed, because the stack has cleared. A click is one task, but the stack is cleared in the middle of it, the microtasks come out.
Microtasks in Node.js
The microtasks in Node.js are Promise.then and process.nextTick. And they are also executed every time the stack is empty - not at the end of the phase. Just every time the phase ends, strangely enough, the stack is empty.
process.nextTick
Good, but why do we need process.nextTick if there is setImmediate? Why do we need microtasks in Node.js in general?
Let's look at an example. We have a createServer function, it creates an EventEmitter, then returns us an object that has a listen method (subscribe to the port), and this method emit our event.
Then we call the function, create the server, listen to port 8080, subscribe to the listening event, and write something elementary in console.log.
Let's think about how this code is actually executed, and if there is any problem with it.
We execute the createServer function, and it returns an object. At this object we call the listen method, in which we already emit an event, but we have not yet had time to subscribe to it. We still have the last line is not even fulfilled.
Thus, we subscribed to the event, but did not receive it. What can be done? You can use process.nextTick: replace evEmitter.emit ('listening', port) with process.nextTick (() => evEmitter.emit ('listening', port)).
The bottom line is that process.nextTick should be used to call the callbacks that were passed to you. From the point of view of EventEmitter, this is also essentially a callback. So, they passed you a callback, but they expect an asynchronous API from you, because this callback will not be executed synchronously. Therefore, we use process.nextTick, and this emit will occur immediately after the userland code has run out. That is, we declared the createServer function, executed it, listened, subscribed to the listening event. Our stack has cleared - at this point in the process. NextTick - boom! Emit event, we have already subscribed to it, everything is cool.
This polling case process.nextTick basically. That is, everything for callback, including errors, is the same story.
But it should be understood that process.nextTick has the same behavior as Promise.then in browsers. If you call process.nextTick recursively, no one will help you - everything will hang on you, both the Event Loop and Node.js will hang. Therefore, please do not do so.
Use process.nextTick only in exceptional cases , otherwise it is better to use ghbvtybnm setImmediate with recursive patterns, or give it to a module in C ++, etc. at all. And process.nextTick can be used just to call callbacks.
We also have such an API - async / await, some kind of generators. They work very simply. As we all know, async / await is based on Promise, so from the point of view of the Event Loop, it works exactly the same. There are some differences in implementation, but from our point of view it is all the same.
Please do not let Ivan Tulup die!
About this and how asynchrony works in JS under the hood, how the Event Loop works in browsers and in Node.js, are there any differences and maybe similar things were told by Mikhail Bashurov ( SaitoNakamura ) in his report on RIT ++ We are pleased to share with you the decoding of this informative presentation.
About Speaker: Mikhail Bashurov - fullstack web developer at JS and .NET from Luxoft. He likes beautiful UI, green tests, transpilation, compilation, compiler allowing technique and improved dev experience.
From the editor:Mikhail's report was accompanied not just by slides, but by a demo project in which you can click on the buttons and see for yourself how to do the task. The best option would be to open the presentation in the adjacent tab and periodically refer to it, but the text will be given links to specific pages. And now we pass the word to the speaker, enjoy reading.
Grandpa Ivan Tulup
I had a candidacy for Ivan Tulup.
But I decided to go a more conformist way, so meet - grandfather Ivan Tulup!
Actually, you only need to know about two things:
- He likes to play cards.
- He, like all people, has a heart, and it beats.
Facts About Heart Attack
You may have heard that cases of heart disease and mortality from them have recently become more frequent. Probably the most common heart disease is a heart attack, that is, a heart attack.
What is interesting about heart attack?
- Most often it occurs on Monday morning.
- Lonely people have a higher risk of having a heart attack. Here, perhaps, the matter is solely in correlation, and not in causation. Unfortunately (or fortunately), however, it is.
- Ten conductors died of a heart attack while conducting (apparently very nervous work!).
- A heart attack is a necrosis of the heart muscle caused by a lack of blood flow.
We have a coronary artery that supplies blood to the muscle (myocardium). If the blood starts to get sick of it, the muscle gradually dies off. Naturally, this has a very negative effect on the heart and on its work.
Grandfather Ivan Tulup also has a heart, and it beats. But our heart pumps blood, and the heart of Ivan Tulup pumps our code and our tasks.
Task: a large circle of blood circulation
What is task? What could be the browser in general? Why are they even needed?
For example, we execute code from a script. This is one heartbeat, and now we have blood flow. We clicked on the button and subscribed to the event — the event handler was spat out — the Callback that we sent. Put setTimeout, Callback worked - one more task. And so in parts, one heartbeat is one task.
There are many different sources of taskes, according to the specification of a huge number. Our heart continues to beat, and while it beats, we are fine.
Event Loop in the browser: a simplified version
This can be represented in a very simple diagram.
- There is a task, we performed it.
- Then we perform the browser render.
But in fact, this is not necessary, because in some cases the browser may not render the render between two tasks.
This can happen, for example, if the browser can decide to group several timeouts or multiple scrolling events. Or at some point something goes wrong, and the browser decides instead of 60 fps (the usual frame rate so that everything goes cool and smooth) to show 30 fps. Thus, he will have much more time to execute your code and other useful work, he will be able to perform several tasks.
Therefore, the render is actually not necessarily performed after each task.
Taski: classification
There are two types of potential operations:
- I / O bound;
- CPU bound.
CPU bound is our useful work, which we do (we consider, display, etc.)
I / O bound - these are the points at which we can divide our tasks. It may be:
- Time-out.
- xhr / fetch.
- Network (Bd).
- File.
Then CPUbound is:
- For example, when we do a for of / for loop (;;) or through an array with some additional methods, we go through: filter, map, etc.
- JSON.parse or JSON.stringify, that is, serialization / deserialization of messages. This is all done on the CPU, we can’t just wait until all of this is done magically somewhere.
- Counting hashes, that is, for example, mining crypts.
Of course, the crypt can be mine on the GPU, but I think - the GPU, the CPU - you understand this analogy.
Task: arrhythmia and thrombus
In the end, it turns out that our heart beats: it performs one TASK, the second, the third, until we do something wrong. For example, we go through an array of 1 million elements and count the sum. It would seem that it is not so difficult, but it can take considerable time. If we constantly occupy tangible time without releasing the task, our render cannot be performed. He hangs in this task, and that's it - the arrhythmia begins.
I think everyone understands that arrhythmia is a rather unpleasant heart disease. But you can still live with him. What happens if you put a task that just hangs the entire event loop in an endless loop? You put a thrombus in the coronary or some other artery, and everything will be very sad. Unfortunately, our grandfather Ivan Tulup will die.
That grandfather Ivan died ...
For us, this means that the entire tab will freeze at all - you will not be able to click on anything, and then Chrome will say: “Aw, Snap!”
This is even worse than the bugs on the website when something went wrong. But if everything is hanging at all, moreover, probably, the CPU has loaded and everything has hung up for the user, then he will most likely never go to your site.
Therefore, the idea is this: we have a task, and we do not need to hang out for a very long time in this task. We need to quickly release it so that the browser, if anything, can render (if it wants). If you do not want - fine, dance!
Philip Roberts Demo: Loupe by Philip Roberts
Consider an example :
$.on(’button', ‘click', functiononClick(){
console.log('click');
});
setTimeout(functiontimeout() {
console log("timeout");
}. 5000);
console.log(“Hello world");
The point is this: we have a button, we subscribe to it (addEventListener), we call Timeout for 5 s and write “Hello, world!” To console.log, write Timeout to setTimeout, we write Click on onClick.
What will happen if we run it and repeatedly click on the button - when will Timeout actually be executed? Let's see the demo:
The code starts to execute, gets on the stack, Timeout goes. Meanwhile, we clicked on the button. At the bottom of the queue added a few events. While the Click is running, Timeout is waiting, although 5 seconds has passed.
Here onClick runs quickly, but if you put a longer task, then in general everything will hang, as has been clarified earlier. This is a very simplified example. There is one line here, but in browsers this is actually not the case.
In what order are the events executed - what does the HTML specification say about this?
She says the following: we have 2 concepts:
- task source;
- task queue.
Task source is a kind of task. This can be a user interaction, that is, onClick, onChange is something the user interacts with; or timers, that is, setTimeout and setInterval, or PostMessages; or generally completely wild Canvas Blob Serialization types task source is also a separate type.
The specification says that for the same task source, tasks will be guaranteed to be executed in the order of addition. For everything else, nothing is guaranteed, because the task queue can be an unlimited number. The browser itself decides how many they will be. Using the task queue and creating them, the browser can prioritize certain tasks.
Browser Priorities and Task Queues
Imagine that we have 3 queues:
- user interaction;
- timeouts;
- post messages.
The browser starts to get hacks from these queues:
- First, he takes onFocus user interaction - this is very important - one heartbeat from us has gone.
- Then he takes postMessages - well, postMessages is pretty high priority, great!
- The next, onChange, is also a priority from user interaction.
- Further onClick goes . The user interaction queue is over, we brought the user all that is needed.
- Then we take setInterval , we add postMessages.
- setTimeout will be executed only the most recent . He was somewhere at the end of the lineup.
This again is also a very simplified example, and, unfortunately, no one can guarantee how it will work in browsers , because they themselves decide it all. You need to test it yourself if you want to find out what it is.
For example, postMessages are more priority than setTimeout. You may have heard about such a thing as setImmediate, which, for example, in IE browsers was only native. But there are polyfiles that are mostly not based on setTimeout, but on creating a postMessages channel and subscribing to it. This works generally faster because browsers prioritize this.
Well, these tasks are done here. At what point do we finish performing our task and understand that we can take the next one, or what can we render?
Stack
A stack is a simple data structure that works on the principle of "last in - first out", i.e. “I put the last one - you get it first” . The closest, probably the real equivalent is a deck of cards. Therefore, our grandfather Ivan Tulup loves to play cards.
Above is an example in which there is some code, the same example can be poked into the presentation . In some place we call handleClick, enter console.log, call showPopup and window. confirm. Let's form a stack.
- So, first we take handleClick and put the call to this function on the stack - great!
- Then we go into his body and execute it.
- We put console.log on the stack, and execute it right there, because there is everything to execute it.
- Next, we put showConfirm - this is a function call - great.
- Put the functions in the stack - put her body, that is, window.confirm.
We have nothing more - we do it. A window will pop up: “Are you sure?”, Click on “Yes”, and everything will leave the stack. Now we have finished the showConfirm body and the handleClick body. Our stack is cleared and you can proceed to the next task. Question: well, I now know that it is necessary to break it all into small pieces. How can I, for example, do this in the most elementary case?
Splitting an array into chunks and their asynchronous processing
Let's look at the most "in the forehead" example. Immediately I warn you: please do not try to repeat this at home - it will not compile.
We have a large, large array, and we want to calculate something on it, for example, parse some binary data. We can just break it into chunks: process this piece, this and this. We choose the size of the chunk, say, 10 thousand elements, we consider how many chunks we will have. We have the parseData function, which is included in the CPU bound and can really do something heavy. Then we divide the array into chunks, setTimeout (() => parseData (slice), 0).
In this case, the browser will again be able to prioritize User interaction and render the render in between. So at least you let go of your Event Loop, and it continues to work. Your heart keeps beating, and that's good.
But this is really a very "in the forehead" example. Now browsers have many APIs that will help to do this in a more specialized way.
In addition to setTimeout and setInterval, there are APIs that go beyond the limits of tasks, such as, for example, requestAnimationFrame and requestIdleCallback.
Probably many people are familiar with requestAnimationFrame , and even use it already. It is performed before the render. Its charm is that, firstly, it tries to run every 60 fps (or 30 fps), secondly, this is all done immediately before creating the CSS Object Model, etc.
Therefore, even if you have multiple requestAnimationFrame, they will actually group all the changes, and the frame will be complete. In the case of setTimeout, of course, you cannot receive such a guarantee and guarantee it One setTimeout will change one thing, another another, and between this a render may slip through - you will have jerking of the screen or something else. RequestAnimationFrame for this fits perfectly.
In addition, there is a requestIdleCallback.Maybe you heard that it is used in React v16.0 (Fiber). RequestIdleCallback works in such a way that if the browser understands that it has time between frames (60 fps) to do something useful, and at the same time they did everything - did the task, did requestAnimationFrame - everything seems to be cool, then can give out small quanta, say, 50 ms for you to do something (IDLE mode).
It is not on the diagram above, because it is not in a particular place. The browser can decide to place it before the frame, after the frame, between the requestAnimationFrame and the render, after the task, before the task. No one can guarantee this.
It’s guaranteed that if you have work that is not related to changing the DOM (because then requestAnimationFrame is animation and so on), while it’s not super priority, but tangible, requestIdleCallback is your way out.
So, if we have a long CPU bound operation, then we can try to break it apart.
- If this is a DOM change, then use requestAnimationFrame.
- If this is a non-priority, short-lived and not hard task that will not burden the CPU too much, then requestIdleCallback.
- If we have a big powerful task that needs to be performed constantly, then we go beyond the Event Loop and use WebWorkers. There is no other way out.
Browser Tasking Results:
- Split everything up into small tasks.
- There are many types of tasks.
- Tasks are prioritized for these types through specification queues.
- Much is solved by browsers, and the only way to understand how it works is just to check, run this or that code.
- But the specification is not always respected!
The problem is that our Ivan Tulup is an old grandfather, because the implementations of the Event Loop in browsers are also very old. They were created before the specification was written, so the specification, unfortunately, is respected as long as. Even if you read that the specification should be so, no one guarantees that all browsers have supported it. So be sure to check in browsers how it actually works.
Grandfather Ivan Tulup in browsers is a man of little predictable, with some interesting features, we must remember this.
Terminator Santa: Loop Mascot in Node.js
Node.js is more like someone like that.
Because on the one hand it is the same grandfather with a beard, but at the same time everything is distributed in phases and clearly spelled out where what is being done.
Phases of the Event Loop in Node.js:
- timers;
- pending callback;
- idle, prepare;
- poll;
- check;
- close callbacks.
Everything except the last is not very clear what it means. The phases have such strange names, because under the hood, as we already know, we have Libuv in order to rule everyone:
- Linux - epoll / POSIX AIO;
- BSD - kqueue;
- Windows - IOCP;
- Solaris - event ports.
Thousands of them all!
In addition, Libuv also provides the same Event Loop. There are no specifics of Node.js in it, but there are phases, and Node.js simply uses them. But for some reason she took the names from there.
Let's see what each phase actually means.
Phase Timers performs:
- Callback ready timers;
- setTimeout and setInterval;
- But NOT setImmediate is another phase.
Phase pending callbacks
Prior to this, the documentation phase was called I / O callbacks. Most recently, this documentation has been corrected, and it has ceased to contradict itself. Prior to this, in one place it was written that I / O callbacks are executed in this phase, in another - that in the poll phase. But now everything is written there clearly and well, so read the documentation - something will become much more understandable.
In the pending callback phase, callbacks from some system operations (TCP error) are executed. That is, if in Unix there is an error in the TCP-socket, in this case, he wants not to throw it out right away, but in a callback that will just be executed during this phase. That's all we need to know about her. It is practically not interesting to us.
Phase Idle, prepare
In this phase, we cannot do anything at all, so we forget about it in principle.
Phase poll
This is the most interesting phase in Node.js, because it does the main useful work:
- Performs I / O callbacks (not pending callback phase!).
- Waiting for events from I / O;
- It's cool to do setImmediate;
- No timers;
Looking ahead, setImmediate will be executed at the next check phase, that is, guaranteed before the timers.
Also, the poll phase controls the Event Loop flow. For example, if we have no timers, no setImmediate, that is, no one did the timer, setImmediate did not call, we just block in this phase and wait for an event from the I / O if something comes to us, if there are any callbacks , if we subscribed to something.
How is a non-blocking model implemented? For example, with the same Epoll, we can subscribe to an event — we open the socket and wait for something written in it. In addition, the second argument is timeout, i.e. we will wait for Epoll, but if the timeout ends, and the event from the I / O does not come, then it will exit the timeout. If we receive an event from the network (someone writes in the socket), it will come.
Therefore, the poll phase gets from the heap (a heap is a data structure that allows for a well-sorted retrieval and delivery) of the earliest callback, takes its timeout, writes down at this timeout and releases everything. Thus, even if no one in our socket writes, timeout will work, return to the poll phase and work will continue.
It is important to note that in the poll phase there is a limit on the number of callbacks at a time.
Sadly, in other phases it is not. If you add 10 billion timeout, you add 10 billion timeout. Therefore, the next phase is the check phase.
Phase check
Here setImmediate is executed. The phase is beautiful because the setImmediate, called in the poll phase, is guaranteed to execute earlier than the timer. Because the timer will only be on the next tick at the very beginning, and from the poll phase earlier. Therefore, we can not be afraid of competition with other timers and use this phase for those things that we don’t want for some reason to perform in a callback.
Phase close callbacks
This phase does not perform all of our callback socket closures and other types:
socket.on('close', …).
She executes them only if this event took off unexpectedly, for example, someone at the other end sent: “Everything — close the socket — go here, Vasya!” Then this phase will work, because the event is unexpected. But we are not particularly affected.
Invalid asynchronous processing of chunks in Node.js
What will happen if we have the same pattern that we took in browsers with setTimeout, put it on Node.js - that is, we divide the array into chunks; for each chunk we will make setTimeout - 0.
const bigArray = [1..1_000_000]
const chunks = getChunks(bigArray)
const parseData = (slice) =>// parse binary datafor (chunk of chunks) {
setTimeout(() => parseData(slice), 0)
}
Do you think there are any problems with this?
I already ran a little ahead when I said that if we add 10 thousand timeout (or 10 billion!), There will be 10 thousand timers in the queue, and he will get them and execute - there is no protection against this: get - execute, get - perform and so on to infinity.
Only the poll phase, if we constantly receive an event from I / O, all the time in the socket, someone writes something, so that we at least can set the timers and setImmediate, have protection for the limit, and system-dependent. That is, it will be different on different operating systems.
Unfortunately, other phases, including timers and setImmediate, do not have such protection. Therefore, if you do the same as in the example, everything will hang on you and it won't take very long to reach the poll phase.
How do you think something will change if we replace setTimeout (() => parseData (slice), 0) with setImmediate (() => parseData (slice))? - Naturally, no, there is also no protection in the check phase.
To solve this problem, you can call recursive processing .
const parseData = (slice) =>// parse binary dataconst recursiveAsyncParseData = (i) => {
parseData(getChunk(i))
setImmediate(() => recursiveAsyncParseData(i + 1))
}
recursiveAsyncParseData(0)
The bottom line is that we took the function parseData and wrote its recursive call, but not just ourselves, but through setImmediate. When you call it in the setImmediate phase, then it hits the next tick, and not the current one. Therefore, it will release the Event Loop, it will go further in a circle. That is, we have recursiveAsyncParseData, where we pass a certain index, fetch a chunk on this index, parse it - and then put the setImmediate in the queue with the next index. He will get us to the next tick, and we can thus recursively handle the whole thing.
True, the problem is that it is still some kind of CPU bound task. Perhaps she will still somehow weigh and take time in the Event Loop. Most likely, you want your Node.js to have a pure I / O bound.
Therefore, it is better to use some other things for this, for example, process fork / thread pool.
Now we know about Node.js that:
- everything is distributed in phases - well, we clearly know it;
- there is protection from too long poll-phase, but not the rest;
- recursive processing patterns can be applied in order not to block the Event Loop;
- But it is better to use process fork, thread pool, child process
You should also be careful with thread pool, because Node.js and so many things run there, in particular, DNS resolving, because for some reason, the DNS function DNS is not asynchronous. Therefore, it is necessary to execute it in ThreadPool. On Windows, fortunately, not the case. But there and files can be read asynchronously. In Linux, unfortunately, is impossible.
In my opinion, the standard limit is 4 processes in a ThreadPool. Therefore, if you actively do something there, it will compete with everyone else - with fs and others. You can consider increasing the ThreadPool, but also very carefully. Therefore, read something on this topic.
Microtasks: a small circle of blood circulation
We have Tasks in Node.js and Tasks in browsers. You may have already heard about microtasks. Let's see what it is and how they work, and start with browsers.
Microtasks in browsers
To understand how microtasks work, let's turn to the whatWg standard Event Loop algorithm, that is, let's go into the specification and see how it all looks.
Translating into human language, it looks like this:
- We take free tuska from our turn,
- We carry it out
- We execute microtask checkpoint - OK, we still do not know what it is, but remember.
- Update the rendering (if necessary), and go back to square one.
They are performed in the place indicated in the diagram, and in several other places that we will soon find out. That is, the task is over, microtasks are executed.
Sources microtasks
- Promise.then.
The important thing is not Promise itself, but Promise.then. That callback that was placed in the then is a microtask. If you called 10 then - you have 10 micro-strokes, 10 thousand then - 10 thousand micro-strokes.
- Mutation observer.
- Object.observe , which is deprecated and not needed by anyone.
How many people use the mutation observer?
I think that few use the Mutation observer. Most likely, Promise.then is used more, therefore we will consider it in the example.
Features of microtask checkpoint:
- We carry out everything - this means that we carry out all the microtasks that we have in line to the end. We do not let go - just everything that we have, we take and we do - they must be micro, right?
- You can still generate new microtasks in the process, and they will be executed at the same microtask checkpoint.
- What else is important - they are executed not only after the execution of the task, but also after clearing the stack.
This is an interesting point. It turns out that you can generate new microtasks and we will execute them all to the end. What can it lead us to?
We have two hearts. The first heart I animated JS animation, and the second - CSS-animation. There is another great feature called starveMicrotasks. We call Promise.resolve, and then we put the same function in then.
Look in the presentation for what happens if you call this function.
Yes, the heart of JS will stop, because we add a micro-drag, and then we add a micro-drag in it, and then we add a micro-drag in it ... And so endlessly.
That is, a recursive call microtasks hang everything. But, it would seem, I have everything asynchronous! Should be let go, I called setTimeout there. Not! Unfortunately, you need to be careful with microtasks, so if you somehow use a recursive call, be careful - you can block everything.
In addition, as we remember, microtasks are executed at the end of stack cleaning. We remember what a stack is. It turns out that as soon as we got out of our code, the setTimeout callback was executed — that's all — the microtasks went right away. This can lead to interesting side effects.
Consider an example .
There is a button and a gray container in which it lies. We subscribe to click and buttons, and container. Events, as we know, float, that is, they will appear here and there.
In handlers, we do 2 things:
- Promise.resolve;
- .then in which we enter console.log ('RO')
In the handler itself, we then enter "FUS", and in the handler on the container - "DAH!" (When we have an event pops up).
Do you think that we will appear in the console? In these messages there is a small hint, and oddly enough, it will be displayed “FUS RO DAH!” Excellent! Everything works as we expected.
Now let's consider exactly the same example, but earlier we clicked on the button and the browser called the handler for us, but now we will programmatically call this click. It would seem - what's the difference. Do you think something will change or not?
Of course change! Because otherwise I would not ask this question.
Let's see why this happens.
So, we have our first code, which has a queue of microtasks, and we have a stack. You can see how this is all done in the first case..
- The first time we first go into our handler - buttonHandleClick, put it on the stack.
- Then we add Promise.resolve. He, too, falls on the stack. We executed it, and he added the microretk console.log ('RO') to the queue. We did it.
- Then we enter and process console.log ('FUS').
- After that, the buttonHandleClick almost ended and the stack was cleared. We can get our microdog and execute it.
- Now the event pops up, we go to the second handler (divHandleClick) and execute its code, display “DAH!”.
- HandleClick is over.
It would seem that everything is cool and everything is logical. Why is the next example wrong with us? Let's follow the execution flow in the second case :
- Running button.click (). We put it on the stack.
- Go to button HandleClick.
- Run Promise.resolve with then. He adds a microtask to the queue, Promise.resolve is executed.
- Next, go to console.log and enter "FUS".
- We have finished the buttonHandleClick body and exit it, remove it from the stack.
But our synchronous method (click) did not end, because there are still other handlers there, and the stack is not cleared. Therefore, we go to divHandleClick and, of course, execute console.log ('DAH!') Executed. And only after that we have cleared the stack, and we can execute our microduck.
This is very unpleasant, for example, when we call button.click in all sorts of tests.
With this, it is easy to shoot yourself in the foot. Event popup is used, for example, in modal windows. It often happens that a modal window is closed if you click it outside.
This is usually implemented as follows: we subscribe to the document (click) and the modal window container itself (also to click). If we clicked somewhere and it reached the modal window, we stopPropagation. If not, then it comes to the document, a click pops up, we understand that we have clicked somewhere outside, close the window.
And what if some evil genius (or junior programmer) tries to build an interesting logic - like we click on the “Confirm” button, we have a promise that resolves, and then in then we decide whether to close something or not . In this case, it turns out that there will be one behavior in the interface, and another in the tests: either the test will fall, and the interface will not fall, or vice versa. It will be very unpleasant. Therefore, it is better not to be tied to this behavior at all, not to try to invent something on top of this and make it as simple as possible.
Now most browsers (I tested 4) work well with microtasks, and this is all done correctly in the right order. But before that it was not, and no one, unfortunately, can guarantee that there will be no bugs or any additional tricky cases. So it is better to do simply and not be tied to this implementation.
On microtasks in browsers, we learned that:
- With their help, you can block the Event Loop. It is unpleasant.
- They are executed every time after the task and every time the stack is empty.
That is, in fact, in the middle of the task, they can also be executed, because the stack has cleared. A click is one task, but the stack is cleared in the middle of it, the microtasks come out.
Microtasks in Node.js
The microtasks in Node.js are Promise.then and process.nextTick. And they are also executed every time the stack is empty - not at the end of the phase. Just every time the phase ends, strangely enough, the stack is empty.
process.nextTick
Good, but why do we need process.nextTick if there is setImmediate? Why do we need microtasks in Node.js in general?
Let's look at an example. We have a createServer function, it creates an EventEmitter, then returns us an object that has a listen method (subscribe to the port), and this method emit our event.
const createServer = () => {
const evEmitter = new EventEmitter()
return {
listen: port => {
evEmitter.emit('listening', port)
return evEmitter
}
}
}
const server = createServer().listen(8080)
server.on('listening', () => console.log('listening'))
Then we call the function, create the server, listen to port 8080, subscribe to the listening event, and write something elementary in console.log.
Let's think about how this code is actually executed, and if there is any problem with it.
We execute the createServer function, and it returns an object. At this object we call the listen method, in which we already emit an event, but we have not yet had time to subscribe to it. We still have the last line is not even fulfilled.
Thus, we subscribed to the event, but did not receive it. What can be done? You can use process.nextTick: replace evEmitter.emit ('listening', port) with process.nextTick (() => evEmitter.emit ('listening', port)).
The bottom line is that process.nextTick should be used to call the callbacks that were passed to you. From the point of view of EventEmitter, this is also essentially a callback. So, they passed you a callback, but they expect an asynchronous API from you, because this callback will not be executed synchronously. Therefore, we use process.nextTick, and this emit will occur immediately after the userland code has run out. That is, we declared the createServer function, executed it, listened, subscribed to the listening event. Our stack has cleared - at this point in the process. NextTick - boom! Emit event, we have already subscribed to it, everything is cool.
This polling case process.nextTick basically. That is, everything for callback, including errors, is the same story.
But it should be understood that process.nextTick has the same behavior as Promise.then in browsers. If you call process.nextTick recursively, no one will help you - everything will hang on you, both the Event Loop and Node.js will hang. Therefore, please do not do so.
Use process.nextTick only in exceptional cases , otherwise it is better to use ghbvtybnm setImmediate with recursive patterns, or give it to a module in C ++, etc. at all. And process.nextTick can be used just to call callbacks.
Async / await
We also have such an API - async / await, some kind of generators. They work very simply. As we all know, async / await is based on Promise, so from the point of view of the Event Loop, it works exactly the same. There are some differences in implementation, but from our point of view it is all the same.
useful links
- Once again, the link to the slides and the source .
- Philip Roberts. What the heck is the event loop anyway?
- Bert Belder. Everything you need to know about the Node.js event loop.
- Jake Archibald. In the Loop .
- The Node.js Event Loop, Timers, and process.nextTick ()
- WHATWG Specification event loop processing model
Please do not let Ivan Tulup die!
Separate original Frontend Conf is just around the corner - on October 4 and 5 in Moscow, in Infospace. The reception of reports has already ended, and we can share the themes of some class applications:
- Grid Layout as the basis of the modern layout / Sergey Popov (Liga A.)
- Building decentralized apps with JS / Mikhail Kuznetsov (ING)
- Zakeshiruy it / Vsevolod Shmyrov (Yandex)
- StoreWars (ngxs, redux, vuex) / Kirill Yusupov, Maxim Ivanov (Cinimex)
Come, it will be interesting!