Database development in Dropbox. The path from one global MySQL database to thousands of servers
When Dropbox was launched, one user at Hacker News commented that you can implement it with several bash scripts using FTP and Git. Now this can not be said at all, it is a large cloud-based file storage with billions of new files every day, which are not just stored in a database, but so that any database can be restored to any point in the last six days.
Under the cut is the transcript of the report of Glory Bakhmutov ( m0sth8 ) on Highload ++ 2017, how the databases in Dropbox have evolved and how they are organized now.
About the speaker: Slava Bakhmutov, a site reliability engineer on the Dropbox team, loves Go very much and sometimes appears in the golangshow.com podcast.
Content
Dropbox appeared in 2008. In essence, this is a cloud file storage. When Dropbox was launched, the user at Hacker News commented that you can implement it with several bash scripts using FTP and Git. But, nevertheless, Dropbox is developing, and now it is a fairly large service with more than 1.5 billion users, 200 thousand businesses and a huge number (several billion!) Of new files every day.
What does Dropbox look like?
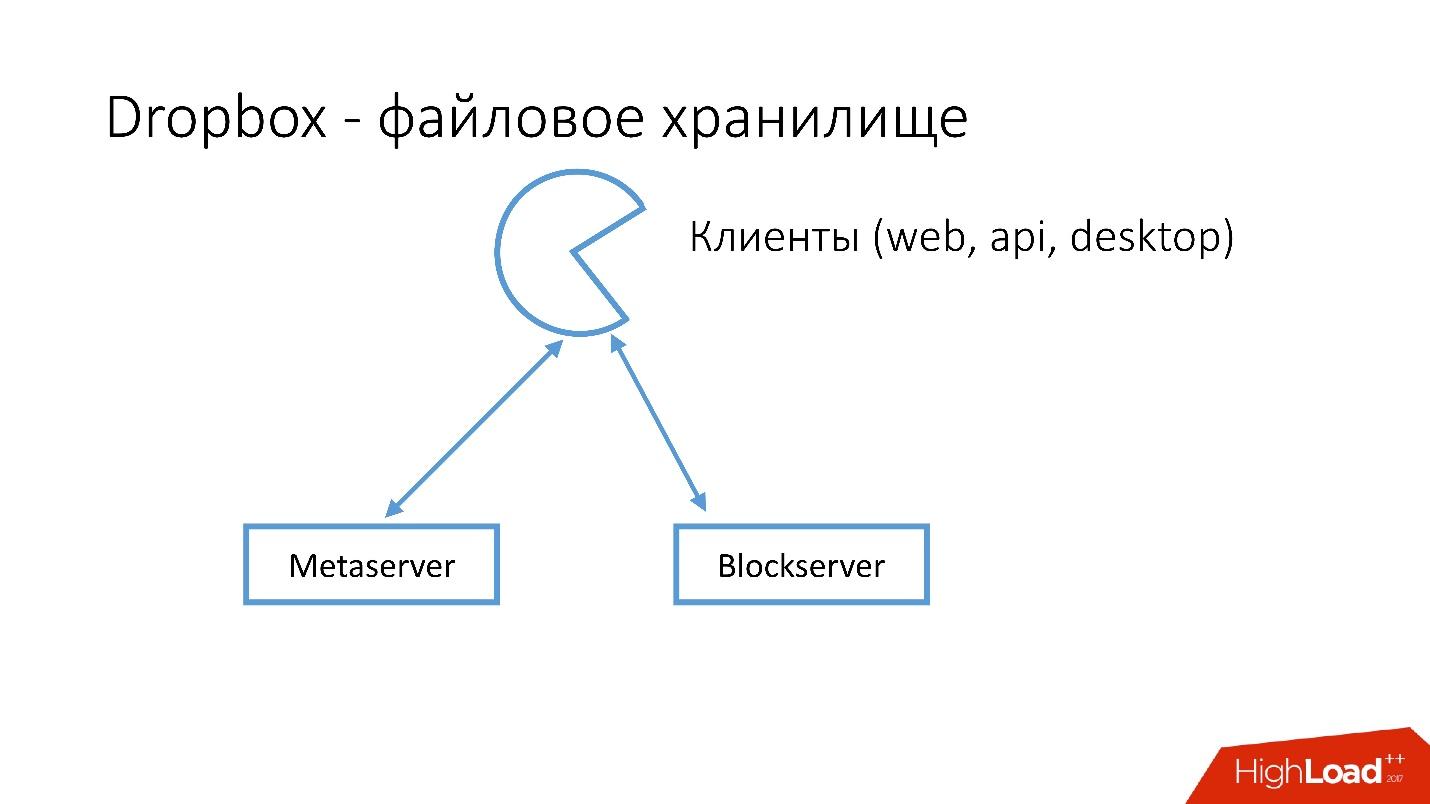
We have several clients (web interface, API for applications that use Dropbox, desktop applications). All these clients use the API and communicate with two large services, which can logically be divided into:
Metaserver stores meta information about a file: size, comments to it, links to this file in Dropbox, etc. The Blockserver stores information only about files: folders, paths, etc.
How it works?
For example, you have a video.avi file with some kind of video.
 Link from the slide
Link from the slide
 Link from the slide
Link from the slide
 Link from the slide
Link from the slide
Of course, this is a very simplified scheme, the protocol is much more complicated: there is synchronization between clients within the same network, there are kernel drivers, the ability to resolve conflicts, etc. This is a rather complicated protocol, but schematically it works something like this.

When a client saves something on Metaserver, all the information goes into MySQL. Blockserver information about files, how they are structured, what blocks they consist of, also stores in MySQL. Also, the Blockserver stores the blocks themselves in Block Storage, which, in turn, also stores information on where the block is, on which server, and how it is processed at the moment, in MYSQL.
How did the database evolve in Dropbox?

In 2008, it all started with one Metaserver and one global database. All the information that Dropbox needed to be saved somewhere, it saved to the only global MySQL. This did not last long, because the number of users grew, and individual bases and tablets inside the bases swelled faster than others.

Therefore, in 2011 several tables were placed on separate servers:
But after 2012, Dropbox began to grow very much, since then we have grown by about 100 million users per year .
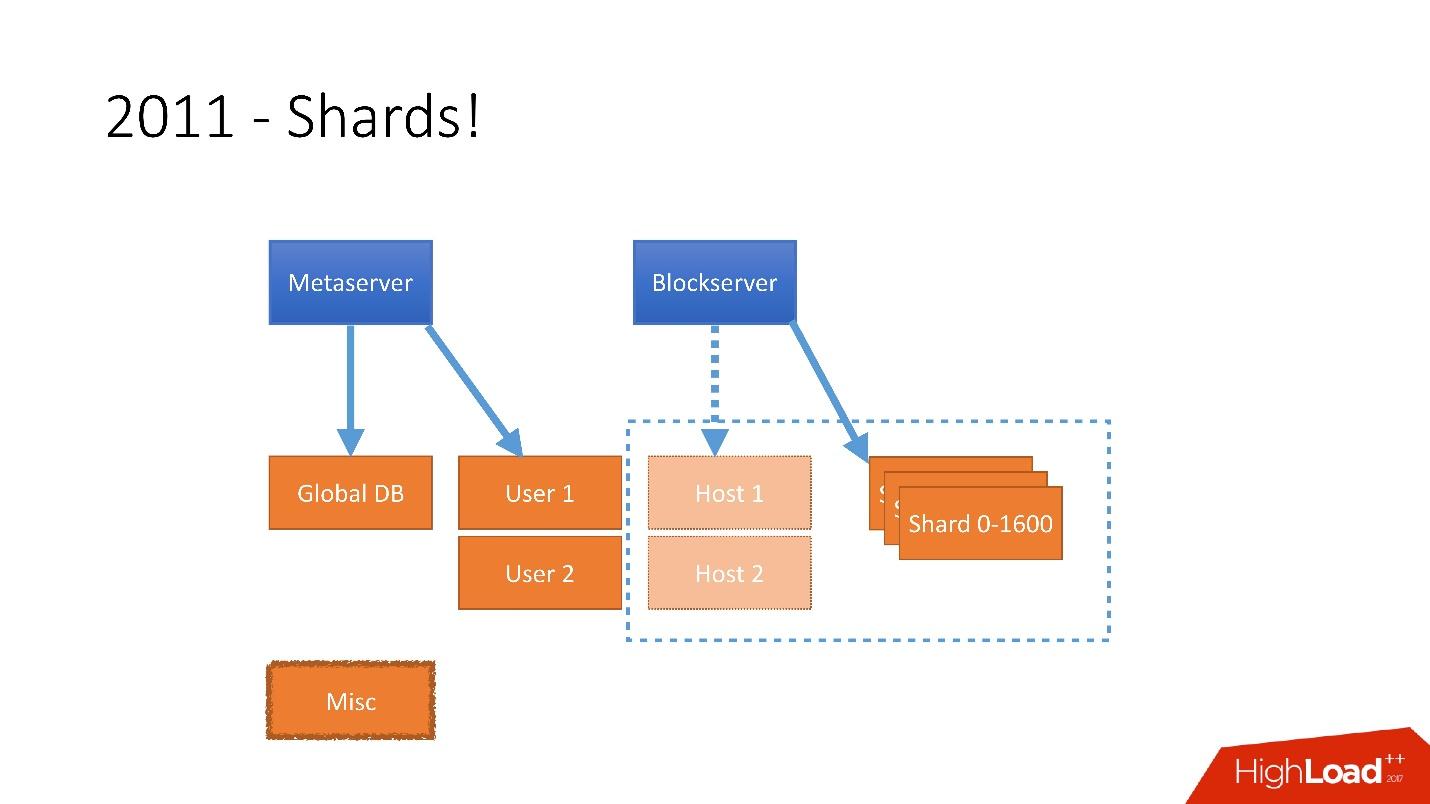
It was necessary to take into account such a huge growth, and therefore at the end of 2011 we had shards - the base consisting of 1,600 shards. Initially, only 8 servers with 200 shards each. Now it’s 400 master servers with 4 shards each.
 Link from the slide
Link from the slide
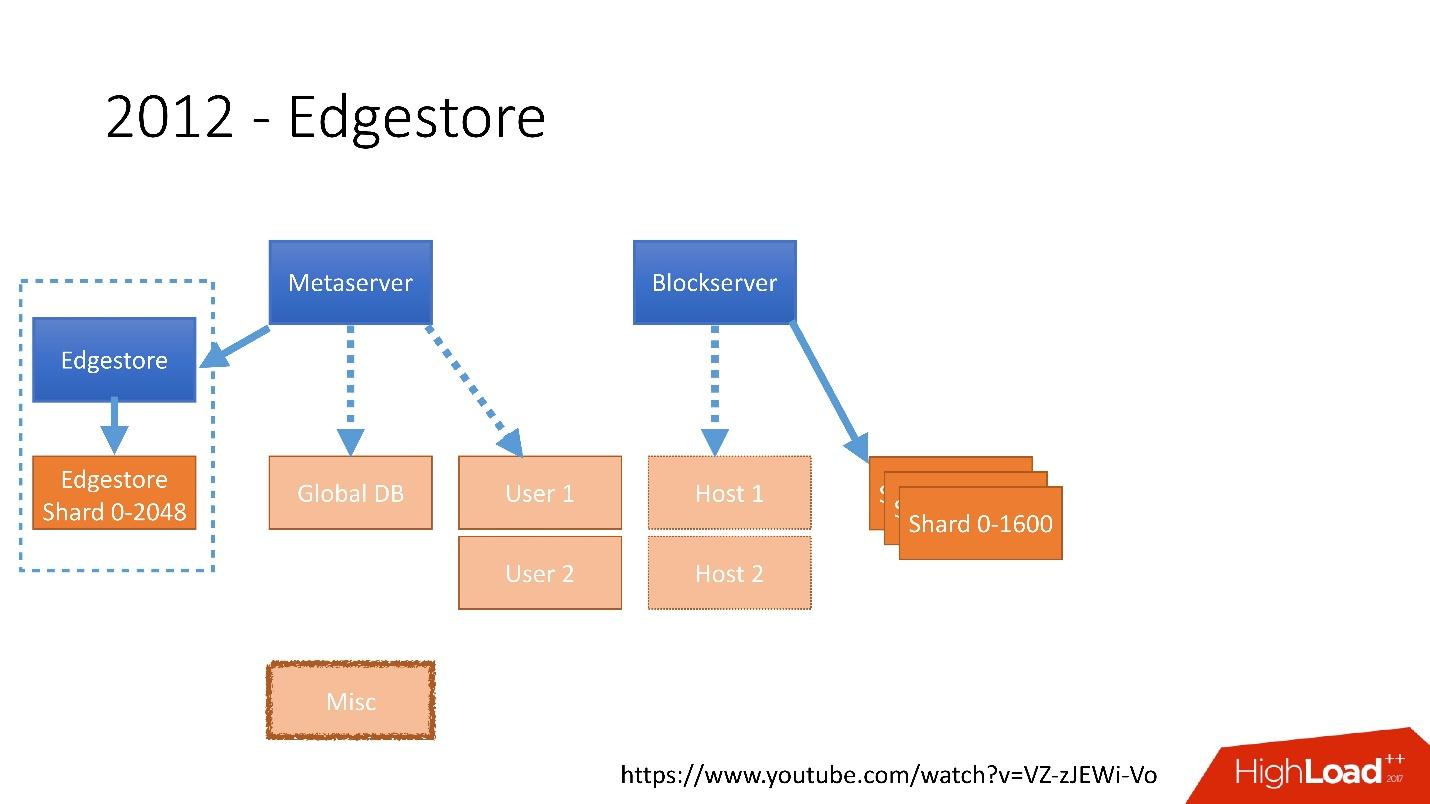
In 2012, we realized that creating tables and updating them in the database for each added business logic is very difficult, dreary and problematic. Therefore, in 2012 we invented our own graph storage, which we called Edgestore , and since then all the business logic and meta information that the application generates is stored in Edgestore.
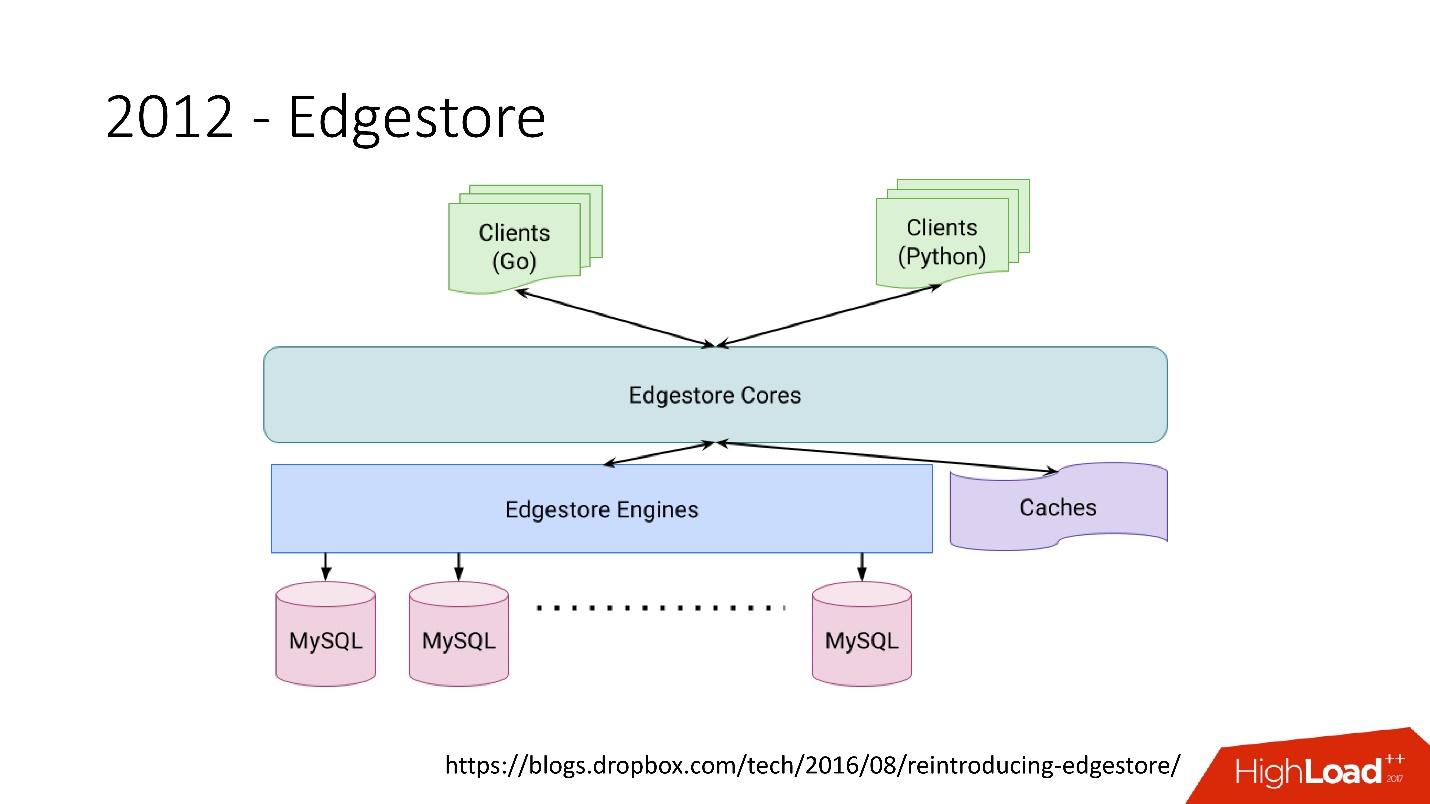
Edgestore essentially abstracts MySQL from clients. Clients have certain entities that are interconnected by links from the gRPC API to Edgestore Core, which converts this data to MySQL and somehow stores them there (basically it gives all this from the cache).
 Link from the slide
Link from the slide
In 2015, we left Amazon S3 , developed our own cloud storage called Magic Pocket. It contains information about where the block file is located, on which server, about the movement of these blocks between servers, is stored in MySQL.
 Link from the slide
Link from the slide
But MySQL is used in a very tricky way - in fact, as a large distributed hash table. This is a very different load, mainly on reading random entries. 90% recycling is I / O.
Firstly, we immediately identified some principles by which we build the architecture of our database:
All principles must be verifiable and measurable , that is, they must have metrics. If we are talking about the cost of ownership, then we need to calculate how many servers we have, for example, it goes under the database, how many servers it goes under backups, and how much it costs for Dropbox. When we choose a new solution, we count all the metrics and focus on them. When choosing any solution, we are fully guided by these principles.
The database is organized approximately as follows:
This topology is chosen because if we suddenly die the first data center, then in the second data center we already have almost complete topology . We simply change all addresses in Discovery, and customers can work.
We also have specialized topologies.
Topology Magic Pocket consists of one master-server and two slave-servers. This is done because Magic Pocket itself duplicates data among the zones. If it loses one cluster, it can recover all data from other zones via erasure code.

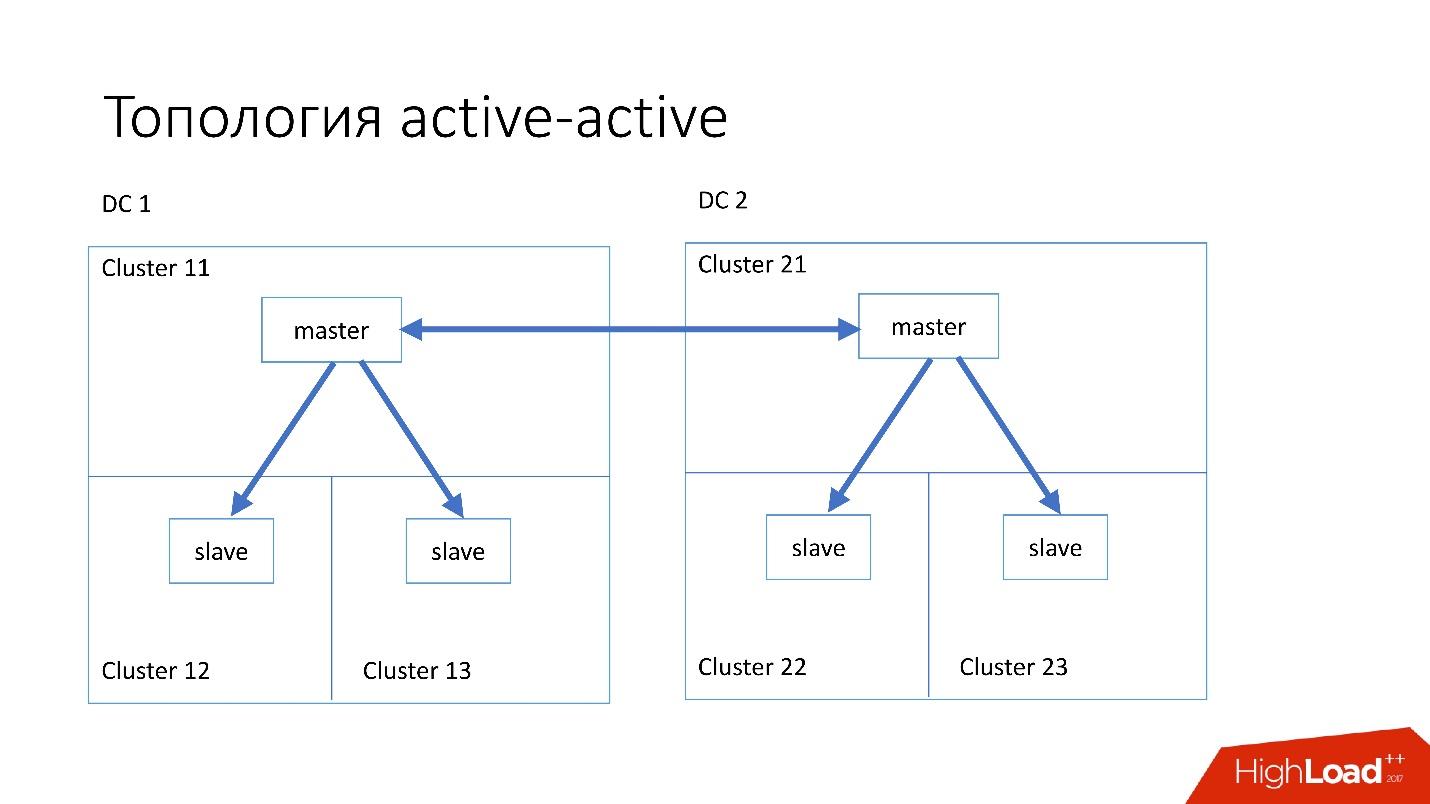
Topology active-active is a custom topology that is used in Edgestore. It has one master and two slaves in each of two data centers, and they are slaves for each other. This is a very dangerous scheme , but Edgestore at its level knows exactly what data it can write to which master for which range. Therefore, this topology does not break.
We have installed fairly simple servers with a configuration of 4-5 years old:
* Raid 0 - because it is easier and faster for us to replace the whole server than the disks.
On this server we have one big MySQL instance, on which there are several shards. This MySQL instance immediately allocates to itself almost all the memory. Other processes are running on the server: proxy, statistics collection, logs, etc.
This solution is good because:
+ It is easy to manage . If you need to replace MySQL instance, simply replace the server.
+ Just make files .
On the other hand:
- It is problematic that any operations occur on the whole MySQL instance and immediately on all shards. For example, if you need to make a backup, we make a backup of all shards at once. If you need to make a faylover, we make a faylover of all four shards at once. Accordingly, accessibility suffers 4 times more.
- Problems with replication of one shard affect other shards. MySQL replication is not parallel, and all shards work in one stream. If something happens to one shard, then the others also become victims.
Therefore, we are now switching to another topology.

In the new version, several MySQL instances are running on the server at once, each with one shard. What is better?
+ We can carry out operations only on one particular shard . That is, if you need a faylover, switch only one shard, if you need a backup, make a backup of only one shard. This means that operations are greatly accelerated - 4 times for a four-shard server.
+ Shards almost don't affect each other .
+ Improved replication.We can mix different categories and classes of databases. Edgestore takes up a lot of space, for example, all 4 TB, and Magic Pocket only takes 1 TB, but it has 90% utilization. That is, we can combine various categories that use I / O and machine resources in different ways, and run 4 replication threads.
Of course, this solution also has disadvantages:
- The biggest disadvantage is that it is much more difficult to manage all of this . We need some kind of smart planner who will understand where he can take this instance, where there will be an optimal load.
- Harder faylover .
Therefore, we are only now switching to this decision.
Customers need to somehow know how to connect to the right database, so we have Discovery, which should:
At first everything was simple: the address of the database in the source code in the config. When we needed to update the address, it was just that everything deployed very quickly.

Unfortunately, this does not work if there are a lot of servers.
Above is the very first Discovery, which we had. There were database scripts that changed the label in ConfigDB — it was a separate MySQL table, and clients already listened to this database and periodically took data from there.

The table is very simple; there is a database category, a shard key, a master / slave database class, a proxy, and a database address. In fact, the client requested a category, database class, shard key, and he was returned a MySQL address at which he could already establish a connection.
As soon as there were a lot of servers, Memcash was added and clients began to communicate with him.
But then we reworked it. MySQL scripts began to communicate through gRPC, through a thin client with a service that we called RegisterService. When some changes occurred, RegisterService had a queue, and he understood how to apply these changes. RegisterService saved data in AFS. AFS is our internal system, built on the basis of ZooKeeper.

The second solution, which is not shown here, directly used ZooKeeper, and this created problems, because with us every shard was a node in ZooKeeper. For example, 100 thousand clients connect to ZooKeeper, if they suddenly died because of some kind of bug all together, then 100 thousand requests to ZooKeeper will come at once, which will simply drop it and it will not be able to rise.
Therefore, the AFS system was developed , which is used by the entire Dropbox.. In fact, it abstracts the work with ZooKeeper for all clients. The AFS daemon locally rotates on each server and provides a very simple file API of the form: create a file, delete a file, request a file, receive notification of file changes, and compare and swap operations. That is, you can try to replace the file with some version, and if this version has changed during the shift, the operation is canceled.
Essentially, such an abstraction over ZooKeeper, in which there is a local backoff and jitter algorithms. ZooKeeper is no longer falling under load. With AFS, we remove backups in S3 and in GIT, then the local AFS itself notifies customers that the data has changed.

In AFS, data is stored as files, that is, it is a file system API. For example, the shard.slave_proxy file is the largest, it takes about 28 Kb, and when we change the shard category and the slave_proxy class, all clients who subscribe to this file receive a notification. They re-read this file, which has all the necessary information. By shard key get the category and reconfigure the connection pool to the database.
We use very simple operations: promotion, clone, backups / recovery.
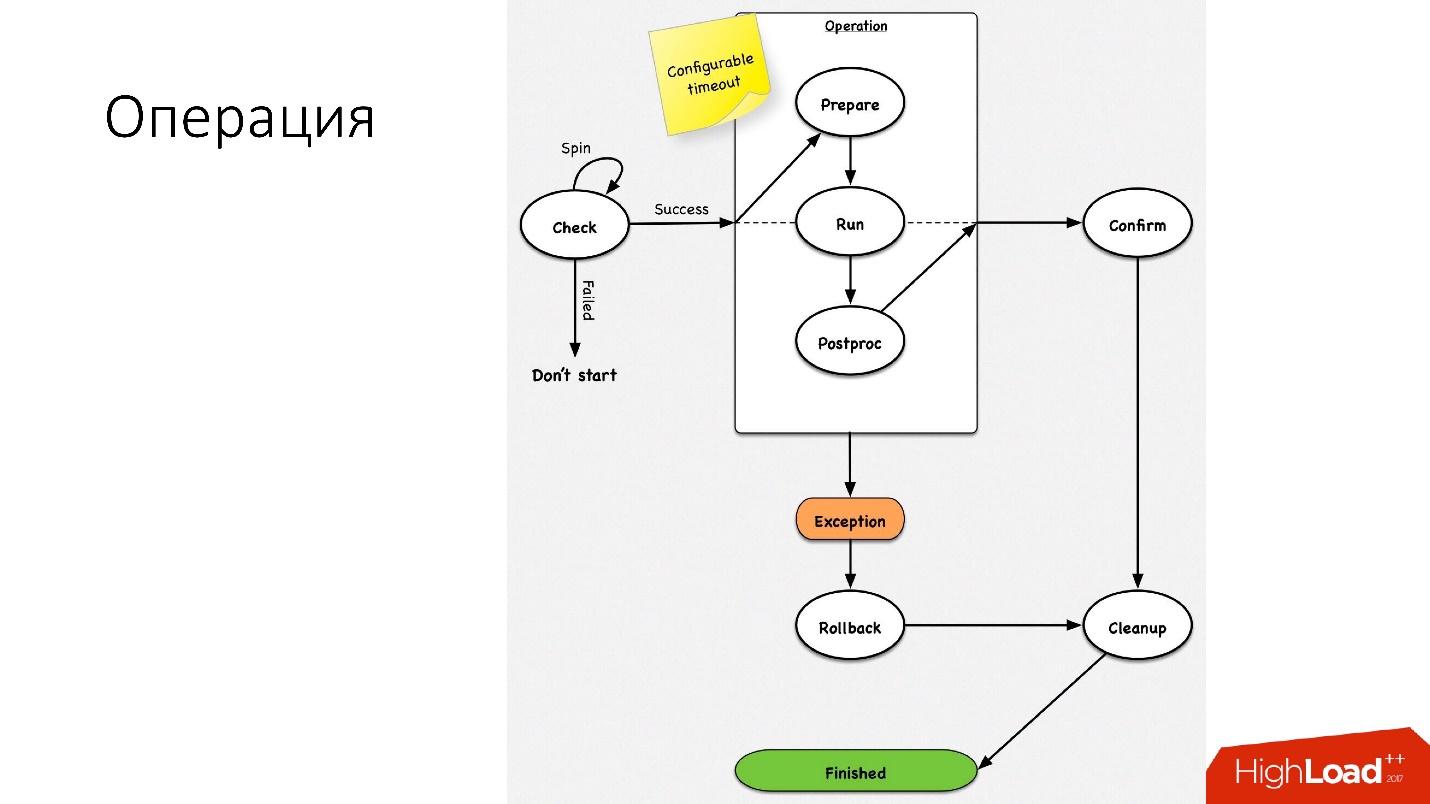
The operation is a simple state machine . When we go into an operation, we perform some checks, for example, a spin-check, which checks on timeouts several times if we can perform this operation. After that, we do some preparatory action that does not affect external systems. The actual operation itself.
All steps inside the operation have a rollback step (undo). If there is a problem with the operation, the operation tries to restore the system to its original position. If everything is normal, then a cleanup occurs, and the operation is completed.
We have such a simple state machine for any operation.
This is a very frequent operation in the database. There were questions about how to do alter on a hot master-server that works - he will get a stake. Simply, all these operations are performed on slave-servers, and then the slave changes with master places. Therefore, the promotion operation is very frequent .

We need to update the kernel - we are doing swap, we need to update the version of MySQL - we upgrade to the slave, we switch to master, we update there.

We have achieved a very fast promotion. For example, we have for four shards now a promotion of the order of 10-15 s. The graph above shows that when the promotion availability suffered by 0.0003%.
But normal promotion is not so interesting, because it is the usual operations that are performed every day. Faylover interesting.
Failover (replacement of a broken master)
Failover means that the database is dead.
We replace the deceased master servers about 2-3 times a day , this is a fully automated process, no human intervention is needed. The critical section takes about 30 seconds, and it has a bunch of additional checks on whether the server is actually alive, or maybe it has already died.
Below is an approximate diagram of how the filer works.

In the selected section, we reboot the master server . This is necessary because we have MySQL 5.6, and in it semisync replication is not lossless. Therefore phantom reads are possible, and we need this master, even if it is not dead, to kill it as soon as possible so that the clients disconnect from it. Therefore, we do a hard reset via Ipmi - this is the first most important operation we need to do. In MySQL version 5.7, this is not so critical.
Cluster sync. Why do we need cluster synchronization?
If we recall the previous picture with our topology, one master server has three slave servers: two in one data center, one in the other. During the promotion, we need the master to be in the same main data center. But sometimes, when the slave is loaded, with semisync it happens that the semisync-slave becomes a slave in another data center, because it is not loaded. Therefore, we need to synchronize the entire cluster first, and then make a promotion on the slave in the data center we need. This is done very simply:
The second important operation is cluster synchronization . Then begins the promotion , which happens as follows:
At any step, in case of an error, we are trying to rollback to the point we can. That is, we cannot rollback to reboot. But for operations for which this is possible, for example, reassignment - change master - we can return master to the previous step.
Backups are a very important topic in databases. I do not know if you are making backups, but it seems to me that everyone should do them, this is already a beaten joke.
Patterns of use
● Add a new slave
The most important pattern that we use when adding a new slave server, we simply restore it from the backup. It happens all the time.
● Restoring data to a point in the past
Quite often, users delete data, and then ask them to restore it, including from the database. This rather frequent data recovery operation on a point in the past is automated.
● Recover the entire cluster from scratch
Everyone thinks that backups are needed to restore all data from scratch. In fact, this operation almost never required us. Last time we used it 3 years ago.
These are our main guarantees that we give to our customers. The speed of 1 TB in 40 minutes, because there are restrictions on the network, we are not alone on these racks; traffic is still produced on them.
We have introduced such an abstraction as a cycle. In one cycle, we try to backup almost all of our databases. We simultaneously spin 4 different cycles.

All this is stored for several cycles. Suppose if we store 3 cycles, then in HDFS we have the last 3 days, and the last 6 days in S3. So we support our guarantee.
This is an example of how they work.

In this case, we have two long loops running, which make backups of shardded databases, and one short one. At the end of each cycle, we necessarily verify that the backups work, that is, we do recovery on a certain percentage of the database. Unfortunately, we cannot recover all the data, but we definitely check some percentage of the data for the cycle. As a result, we will have 100 percent of the backups that we restored.
We have certain shards that we always restore to watch the recovery rate, to monitor possible regressions, and there are shards that we restore simply randomly to check that they have recovered and are working. Plus, when cloning, we also recover from backups.

Now we have a hot backup, for which we use the Percona tool xtrabackup. We run it in the —stream = xbstream mode, and it returns us on the working database, the stream of binary data. Next we have a script-splitter, which this binary stream divides into four parts, and then we compress this stream.
MySQL stores data on a disk in a very strange way and we have more than 2x compression. If the database occupies 3 TB, then, as a result of compression, the backup takes approximately 1 500 GB. Next, we encrypt this data so that no one can read it, and send it to HDFS and S3.
In the opposite direction it works exactly the same.

We prepare the server, where we will install the backup, get the backup from HDFS or from S3, decode and decompress it, the splitter compresses it all and sends it to xtrabackup, which restores all data to the server. Then crash-recovery occurs.
Some time, the most important problem of hot backups was that crash-recovery takes quite a long time. In general, you need to lose all transactions during the time you make a backup. After that we lose binlog so that our server will catch up with the current master.
How do we save binlogs?
We used to save binlog files. We collected the master files, alternated them every 4 minutes, or 100 MB each, and saved to HDFS.
Now we use a new scheme: there is a certain Binlog Backuper, which is connected to replications and to all databases. He, in fact, constantly merges binlog to himself and saves them to HDFS.
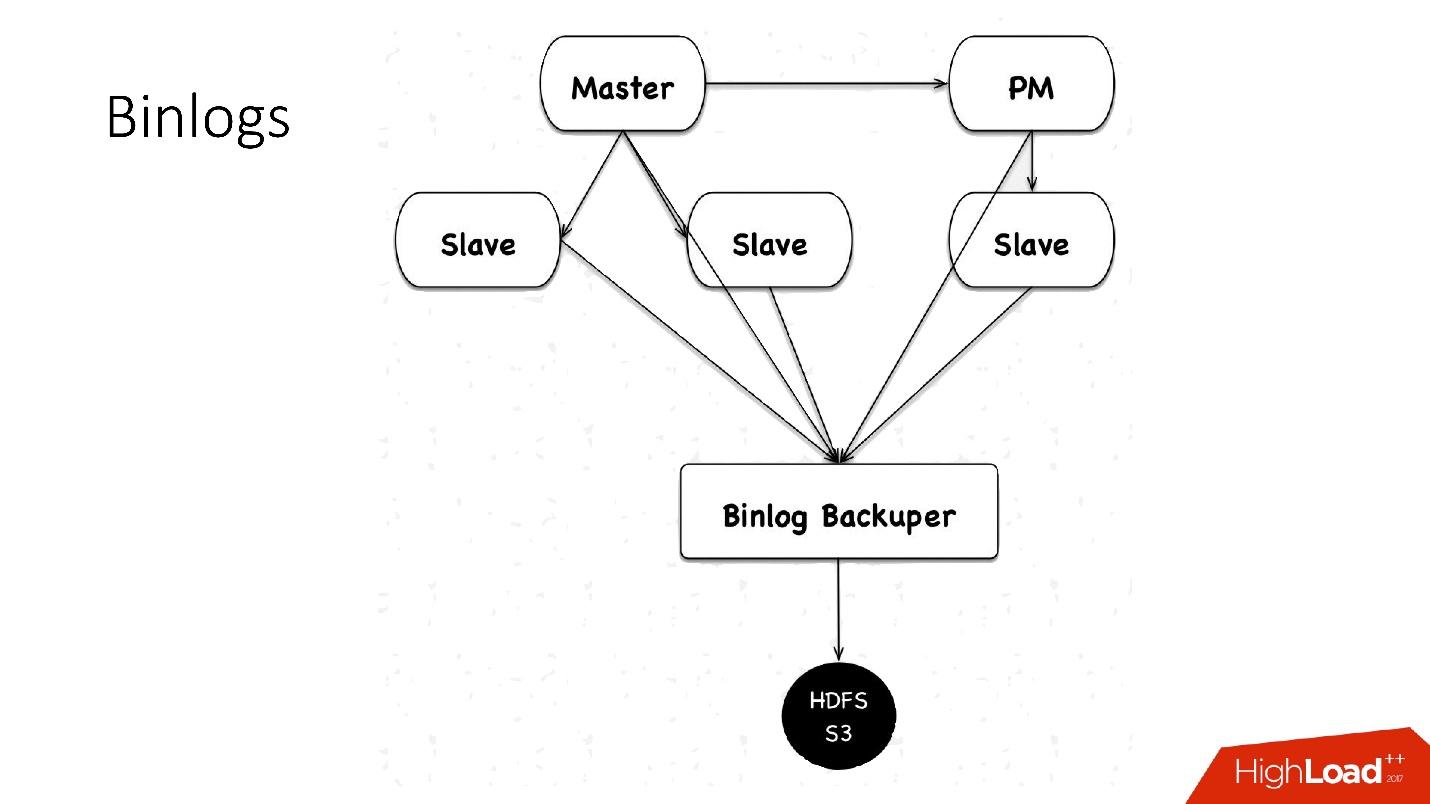
Accordingly, in the previous implementation, we could lose 4 minutes of binary logs, if we lost all 5 servers, in the same implementation, depending on the load, we lose literally seconds. Everything stored in HDFS and in S3 is stored for a month.
We are thinking of switching to cold backups.
Prerequisites for this:
Warranties that were obtained with cold backups in our experiments:

In our topology, there is a slave in another data center that does almost nothing. We periodically stop it, make a cold backup and run it back. Everything is very simple.
These are plans for the distant future. When we update our Hardware Park, we want to add an additional spindle disk (HDD) of about 10 TB to each server, and make hot backups + crash recovery xtrabackup on it, and then download backups. Accordingly, we will have backups on all five servers simultaneously, at different points in time. This, of course, will complicate all the processing and operation, but will reduce the cost, because the HDD costs a penny, and a huge cluster of HDFS is expensive.
As I said, cloning is a simple operation:
In the diagram where we copy to HDFS, the data is also simply copied to another server, where there is a receiver that receives all the data and restores it.
Of course, on 6,000 servers, no one does anything manually. Therefore, we have various scripts and automation services, there are a lot of them, but the main ones are:
This script is needed when the server is dead, and you need to understand whether it is true, and what the problem is - maybe the network is broken or something else. It needs to be resolved as quickly as possible.
Availability is a function of the time between the occurrence of errors and the time over which you can detect and fix this error. We can fix it very quickly - our recovery is very fast, so we need to determine the existence of a problem as soon as possible.

On each MySQL server, the service that heartbeat writes is running. Heartbeat is the current timestamp.
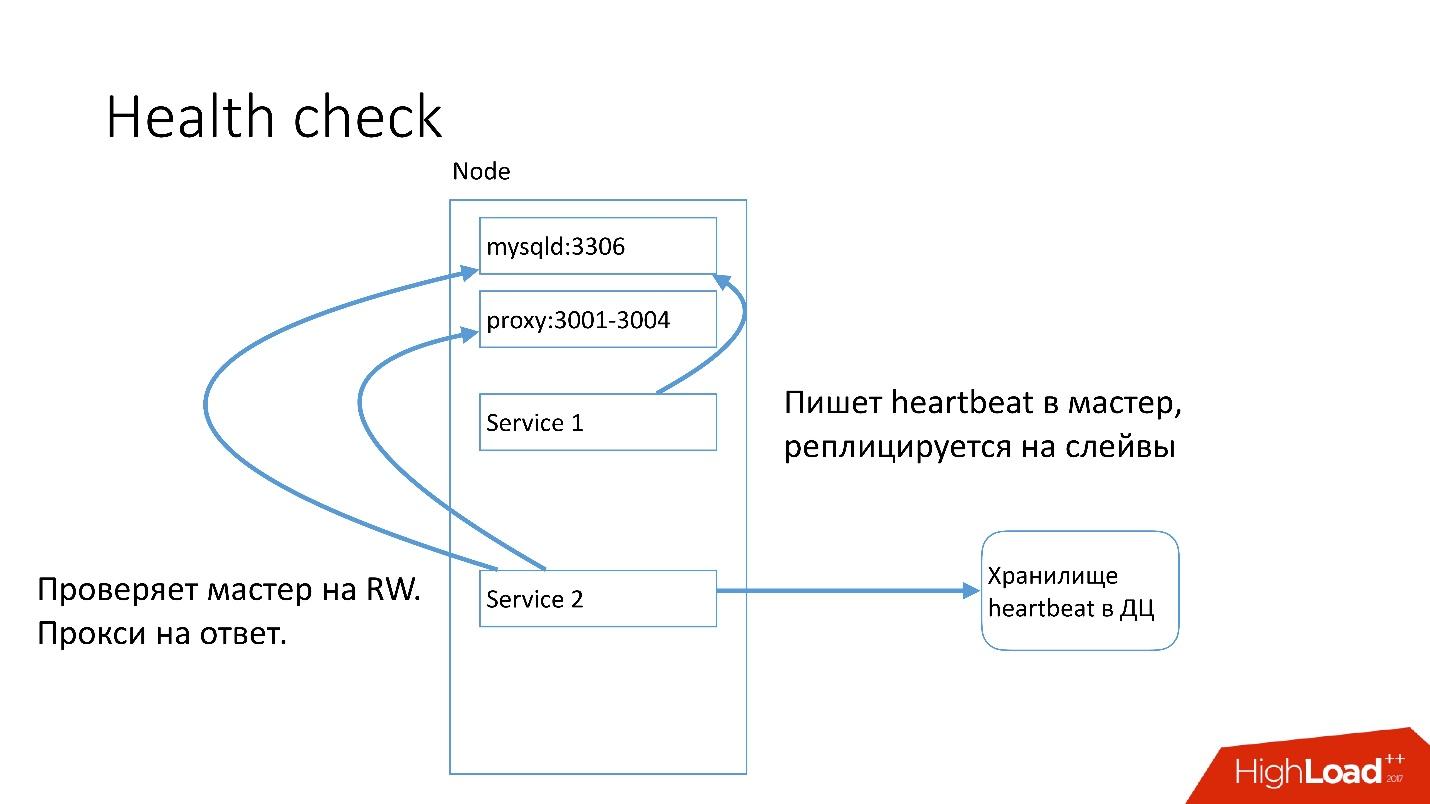
There is also another service that writes the value of some predicates, for example, that master is in read-write mode. After that, the second service sends this heartbeat to the central repository.
We have an auto-replace script that works like this.
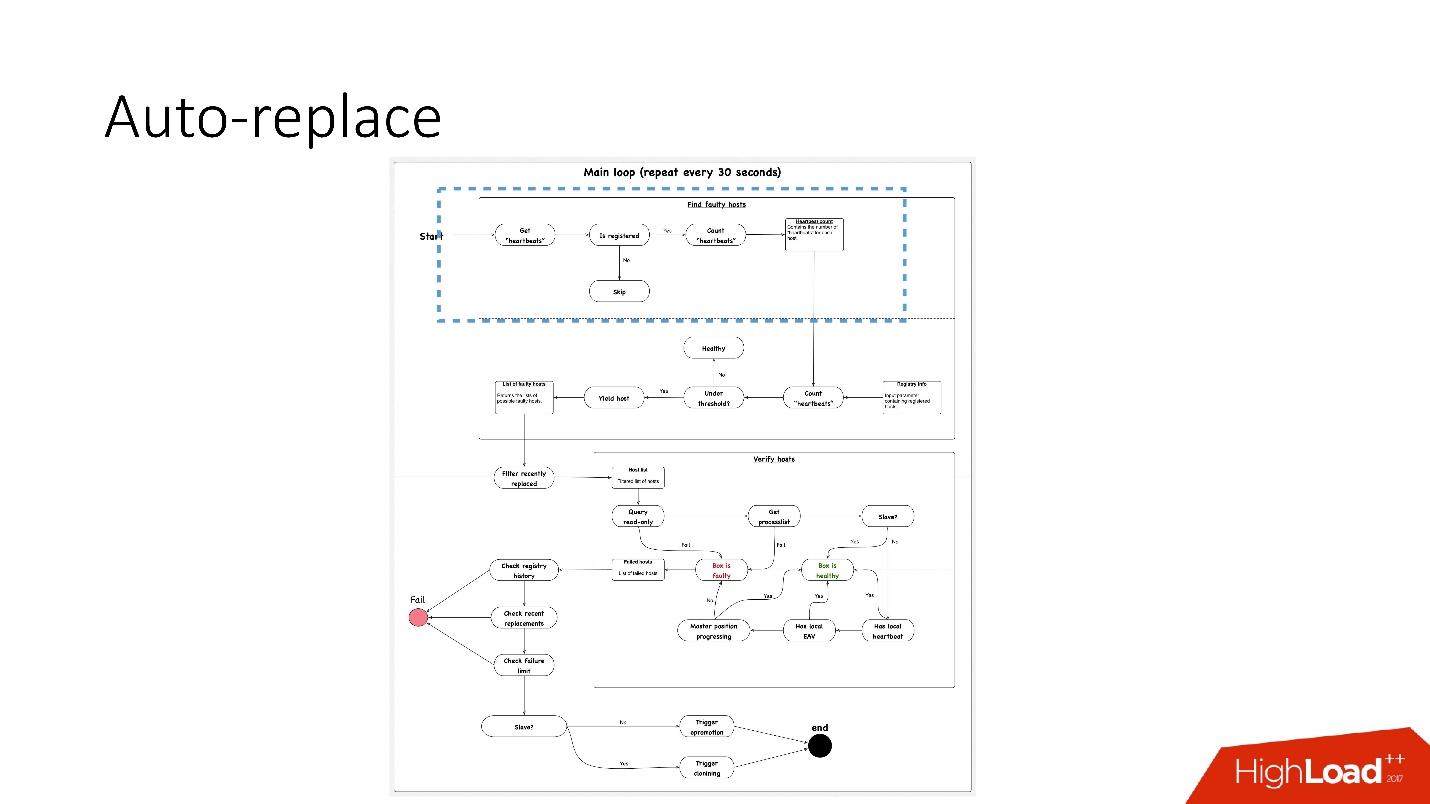 The scheme in the best quality and separately its enlarged fragments are in the presentation of the report, starting with 91 slides.
The scheme in the best quality and separately its enlarged fragments are in the presentation of the report, starting with 91 slides.
What's going on here?
Auto-replace is very conservative. He never wants to do a lot of automatic operations.
Therefore, we solve only one problem at a time .
Accordingly, for the slave server, we start cloning and simply remove it from the topology, and if it is master, then we launch the file shareer, the so-called emergency promotion.
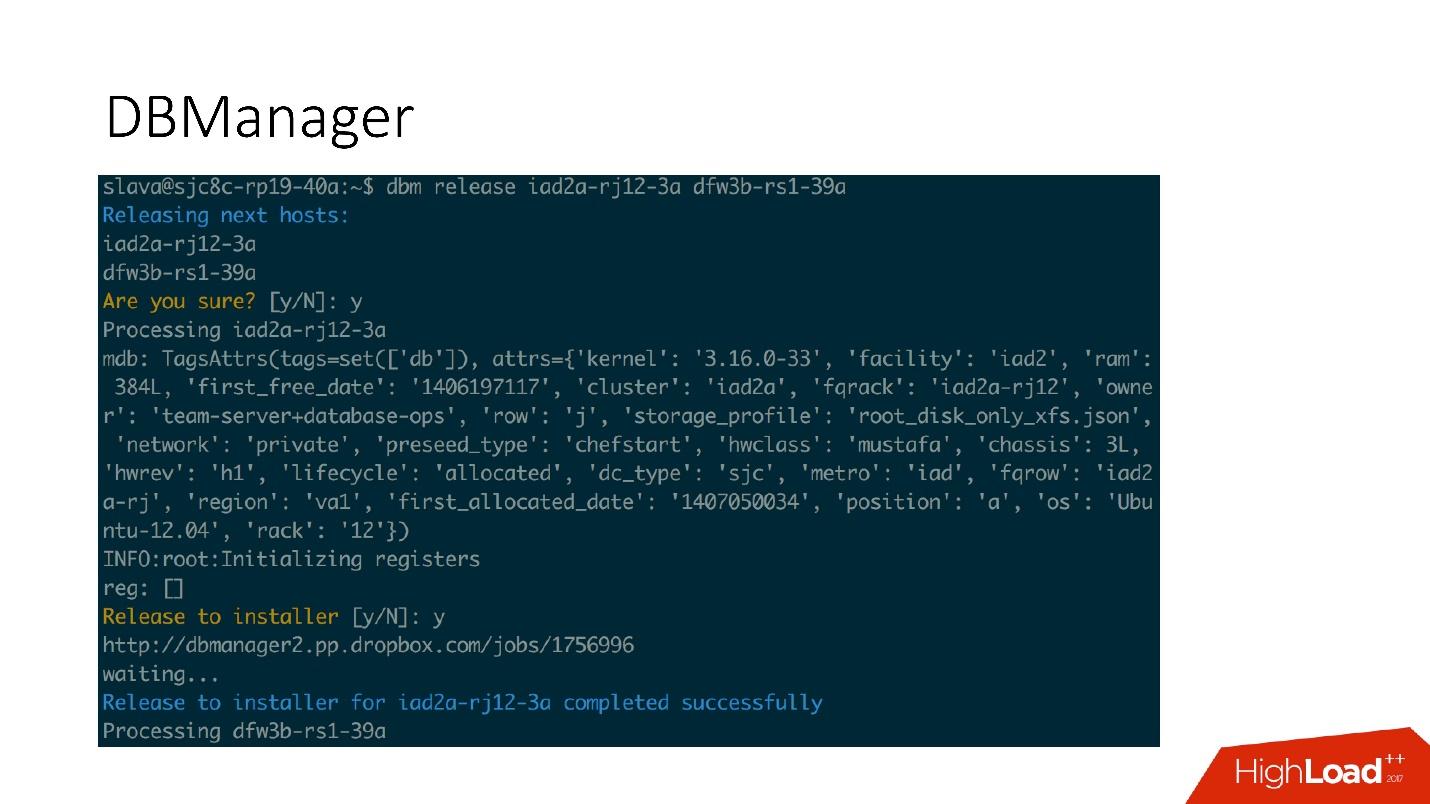
DBManager is a service for managing our databases. He has:
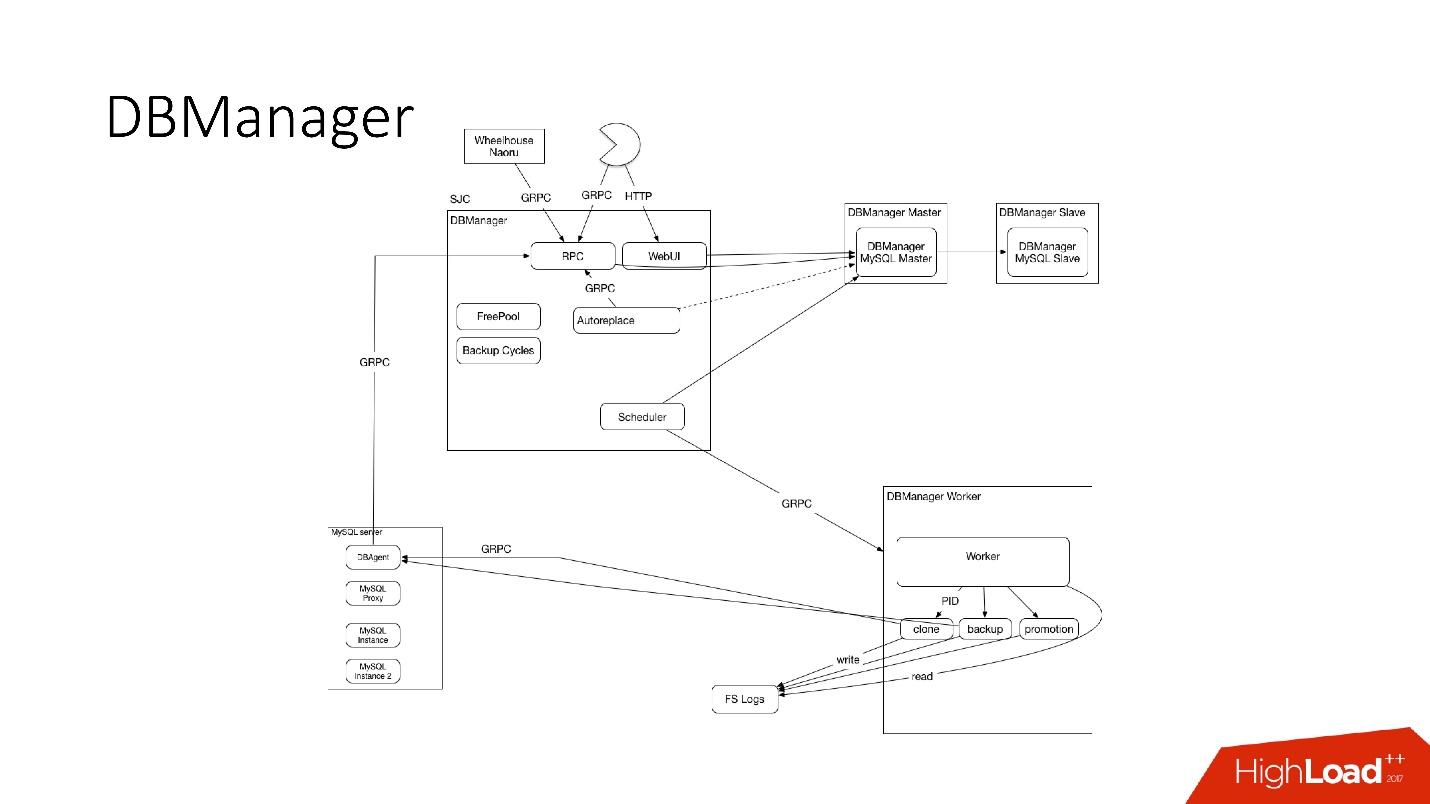
DBManager is quite simple architecturally.
We have a web interface for DBManager, where you can see the current running tasks, logs to these tasks, who started what and when, what operations were performed for a specific database server, etc.
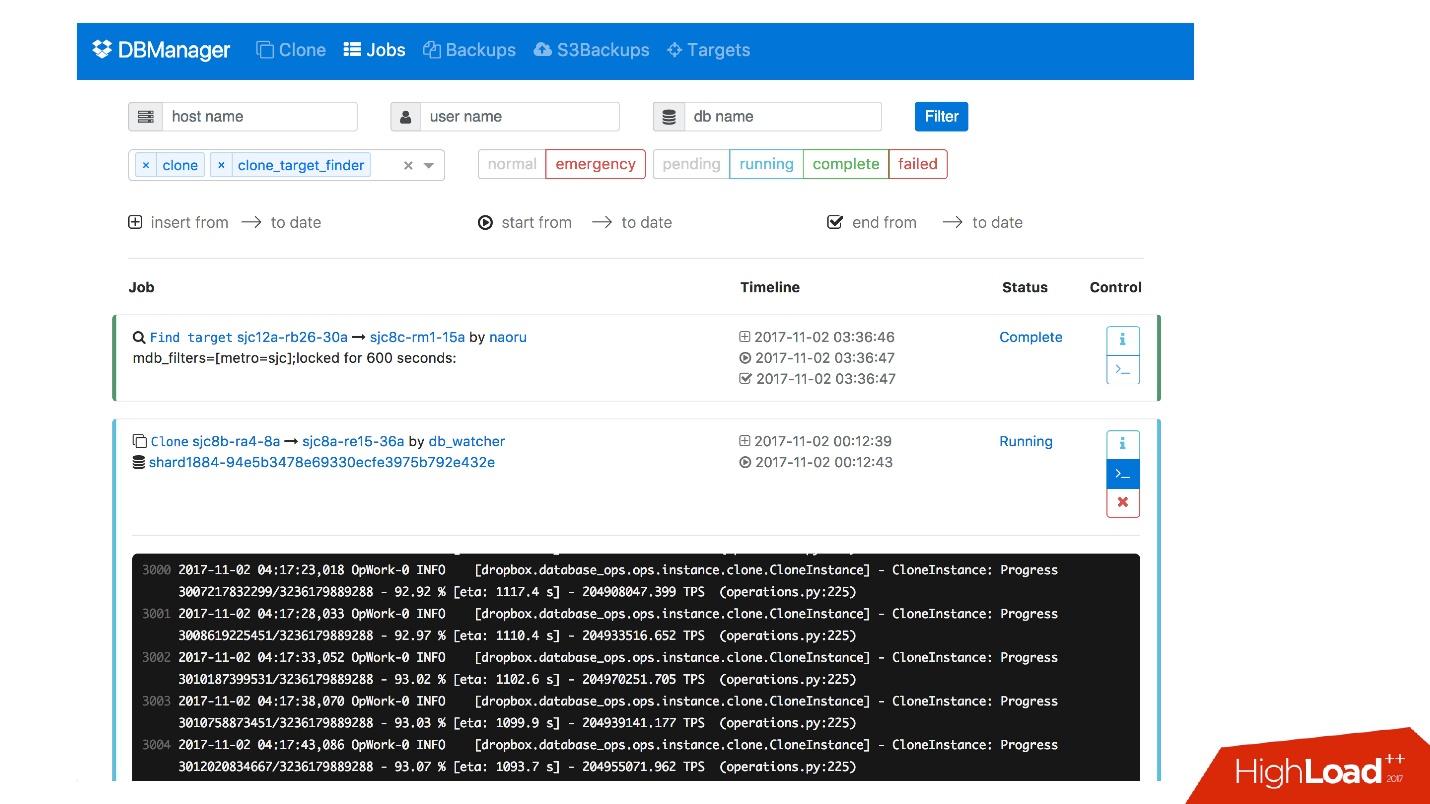
There is a fairly simple CLI interface where you can run tasks and also view them in convenient views.
We also have a problem response system. When something breaks in us, for example, the disk failed or some service does not work, Naoru works . This is a system that works throughout Dropbox, everyone uses it, and it was built for just such small tasks. I talked about Naoru in my 2016 report .
The wheelhouse system is based on the state machine and is designed for long processes. For example, we need to update the kernel on all MySQL on our entire cluster of 6000 machines. Wheelhouse clearly does this - it updates on the slave server, launches the promotion, the slave becomes master, it updates on the master server. This operation can take a month or even two.

It is very important.
We monitor everything in MySQL - all the information we can get from MySQL, we have somewhere saved, we can access it in time. We store information on InnoDb, statistics on requests, on transactions, on the length of transactions, on the length of the transaction, on replication, on the network - all, all - a huge number of metrics.
We have configured 992 alerts. In fact, nobody looks at the metrics, it seems to me that there are no people who come to work and start looking at the metrics chart, there are more interesting tasks.

Therefore, there are alerts that are triggered when certain threshold values are reached. We have 992 alerts, no matter what happens, we will find out about it .

We have PagerDuty - this is a service through which alerts are sent to those in charge who are starting to take action.

In this case, an error occurred in the emergency promotion and immediately after that an alert was registered that the master had fallen. After that, the duty officer checked what prevented the emergency promotion, and did the necessary manual operations.
We will definitely analyze every incident that has occurred, for each incident we have a task in the task tracker. Even if this incident is a problem in our alerts, we also create a task, because if the problem is in the logic of the alert and the thresholds, they need to be changed. Alerts should not just ruin people's lives. Alert is always painful, especially at 4 am.
As with monitoring, I am sure that everyone is involved in testing. In addition to the unit tests with which we cover our code, we have integration tests in which we test:
If we have promotion operations, we test in the integration test of promotion operations. If we have cloning, we do cloning for all the topologies we have.
Example of topology

We have topologies for all occasions: 2 data centers with multi instance, with shards, without shards, with clusters, one data center - in general, almost any topology - even those that we do not use, just to view .

In this file we just have the settings, which servers and with what we need to raise. For example, we need to raise the master, and we say that we need to do this with such data of the instances, with such databases at such ports. We have almost everything going with the help of Bazel, which creates a topology on the basis of these files, starts the MySQL server, then the test is started.

The test looks very simple: we indicate which topology is used. In this test, we test auto_replace.
Stage environments are the same databases as in production, but they do not have user traffic, but there is some kind of synthetic traffic that is similar to production through Percona Playback, sysbench, and similar systems.
In Percona Playback, we record traffic, then we lose it on the stage-environment with different intensity, we can lose 2-3 times faster. That is, it is an artificial, but very close to the real load.
This is necessary because in integration tests we cannot test our production. We cannot test the alert or that the metrics work. At testing, we test alerts, metrics, operations, periodically we kill servers and see that they are normally assembled.
Plus, we test all the automations together, because in the integration tests, most likely, one part of the system is tested, and in the staging all the automated systems work simultaneously. Sometimes you think that the system will behave this way and not otherwise, but it may behave differently.
We also conduct tests in production - right on real databases. This is called Disaster recovery testing. Why do we need it?
● We want to test our warranties.
This is done by many large companies. For example, Google has one service that worked so stably - 100% of the time - that all the services that used it, decided that this service is really 100% stable and never drops. Therefore, Google had to drop this service specifically for users to take into account such an opportunity.
So we - we have a guarantee that MySQL works - and sometimes it does not work! And we have a guarantee that it may not work for a certain period of time, customers should take this into account. Periodically we kill the production master, or if we want to make a file share, we kill all the slave servers to see how semisync replication behaves.
● Customers are ready for these errors (replacement and death of the master)
Why is this good? We had a case when with the promotion of 4 shards out of 1600, the availability dropped to 20%. It seems that something is wrong, for 4 shards out of 1600 there must be some other numbers. Faylovera for this system occurred quite rarely, about once a month, and everyone decided: “Well, this is faylover, it happens.”
At some point, when we switched to a new system, one person decided to optimize those two heartbeat recording services and merged them into one. This service did something else and, eventually, was dying and heartbeats stopped recording. It so happened that for this client we had 8 faylover per day. All lay - 20% availability.
It turned out that in this client keep-alive 6 hours. Accordingly, as soon as the master was dying, all of our connections were kept for another 6 hours. The pool could not continue to work - it keeps connections, it is limited and does not work. It repaired.
Doing a faylover again - no longer 20%, but still a lot. Something's all wrong anyway. It turned out that the bug in the implementation of the pool. The pool, when requested, addressed many shards, and then put it all together. If any shards were fake, some race condition occurred in the Go code, and the whole pool was clogged. All these shards could not work anymore.
Disaster recovery testing is very useful, because clients must be prepared for these errors, they must check their code.
● Plus Disaster recovery testing is good because it goes into business hours and everything is in place, less stress, people know what is going to happen now. This is not happening at night, and it is great.
1. Everything needs to be automated, never clap hands.
Each time when someone climbs into the system with our hands, everything dies and breaks in us - every single time! - even on simple operations. For example, one slave died, the person had to add a second one, but decided to remove the dead slave with his hands from the topology. However, instead of the deceased, he copied the live command into the command - the master was left without a slave at all. Such operations should not be done manually.
2. Tests should be permanent and automated (and in production).
Your system is changing, your infrastructure is changing. If you checked it once and it seemed to work, it does not mean that it will work tomorrow. Therefore, it is necessary to do automated testing every day, including in production.
3. It is imperative to own clients (libraries).
Users may not know how databases work. They may not understand why they need timeouts, keep-alive. Therefore, it is better to own these customers - you will be calmer.
4. You need to define your principles of building a system and your guarantees, and always comply with them.
Thus it is possible to support 6 thousand database servers.
Under the cut is the transcript of the report of Glory Bakhmutov ( m0sth8 ) on Highload ++ 2017, how the databases in Dropbox have evolved and how they are organized now.
About the speaker: Slava Bakhmutov, a site reliability engineer on the Dropbox team, loves Go very much and sometimes appears in the golangshow.com podcast.
Content
- Briefly about Dropbox architecture
- The history of database development and how the current Dropbox architecture is arranged
- Simplest database operations (file managers, backups, clones, promotions)
- Automation - which manages all databases and starts operations
- Monitoring
- Testing, staging and DRT
Simple Dropbox Architecture
Dropbox appeared in 2008. In essence, this is a cloud file storage. When Dropbox was launched, the user at Hacker News commented that you can implement it with several bash scripts using FTP and Git. But, nevertheless, Dropbox is developing, and now it is a fairly large service with more than 1.5 billion users, 200 thousand businesses and a huge number (several billion!) Of new files every day.
What does Dropbox look like?
We have several clients (web interface, API for applications that use Dropbox, desktop applications). All these clients use the API and communicate with two large services, which can logically be divided into:
- Metaserver .
- Blockserver .
Metaserver stores meta information about a file: size, comments to it, links to this file in Dropbox, etc. The Blockserver stores information only about files: folders, paths, etc.
How it works?
For example, you have a video.avi file with some kind of video.
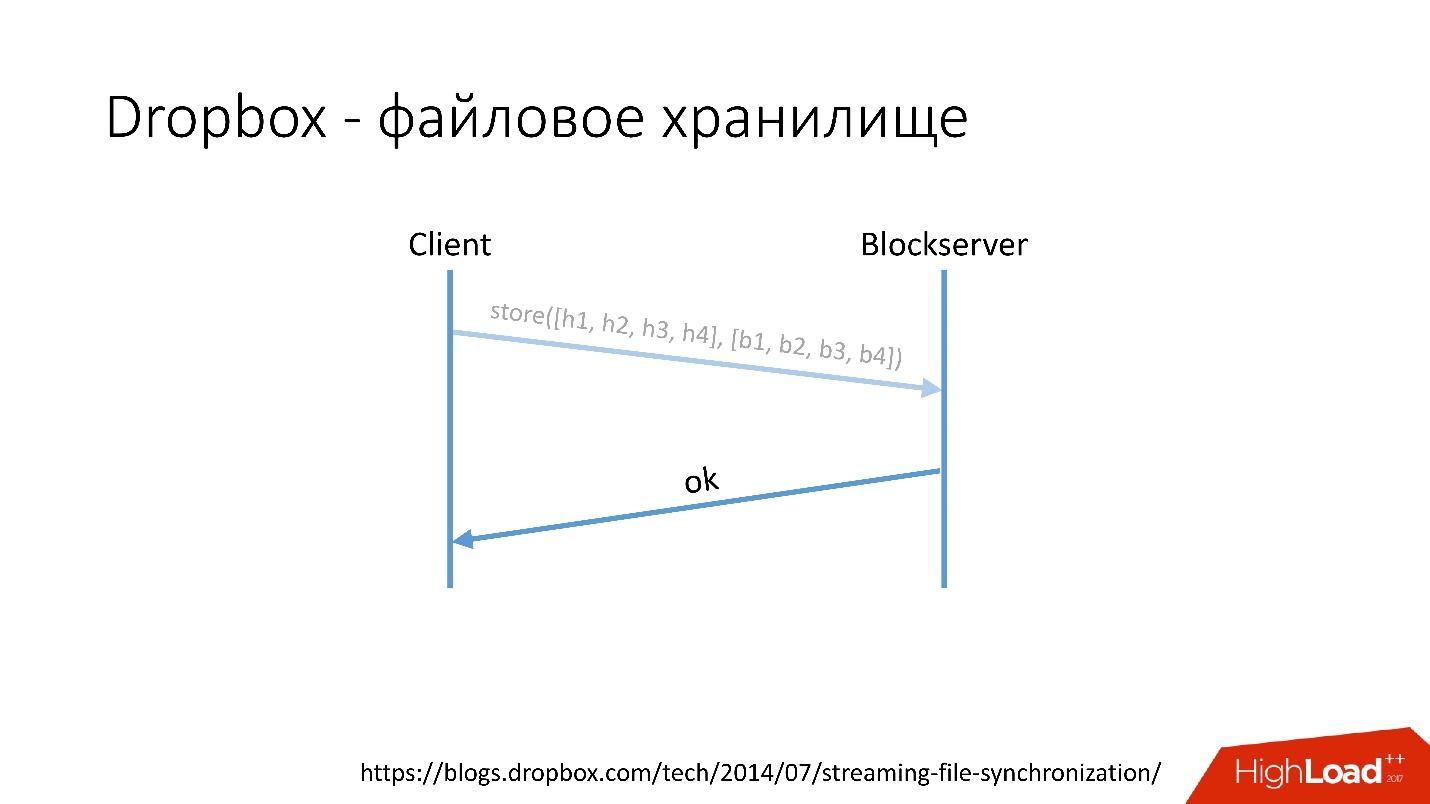
Link from the slide- The client splits this file into several chunks (in this case 4 MB), calculates the checksum and sends a request to Metaserver: “I have an * .avi file, I want to download it, such hash sums”.
- Metaserver returns the answer: “I do not have these blocks, let's download!” Or he can answer that he has all or some blocks, and you need to download only the remaining ones.
Link from the slide- After that, the client goes to the Blockserver, sends the hash sum and the data block itself, which is stored on the Blockserver.
- Blockserver confirms operation.
Link from the slideOf course, this is a very simplified scheme, the protocol is much more complicated: there is synchronization between clients within the same network, there are kernel drivers, the ability to resolve conflicts, etc. This is a rather complicated protocol, but schematically it works something like this.
When a client saves something on Metaserver, all the information goes into MySQL. Blockserver information about files, how they are structured, what blocks they consist of, also stores in MySQL. Also, the Blockserver stores the blocks themselves in Block Storage, which, in turn, also stores information on where the block is, on which server, and how it is processed at the moment, in MYSQL.
To store exabytes of user files, we simultaneously save additional information into a database of several dozen petabytes scattered across 6 thousand servers.
The history of database development
How did the database evolve in Dropbox?
In 2008, it all started with one Metaserver and one global database. All the information that Dropbox needed to be saved somewhere, it saved to the only global MySQL. This did not last long, because the number of users grew, and individual bases and tablets inside the bases swelled faster than others.
Therefore, in 2011 several tables were placed on separate servers:
- User , with information about users, for example, logins and oAuth tokens;
- Host , with information about files from Blockserver;
- Misc , which did not participate in processing requests from production, but was used for service functions, like batch jobs.
But after 2012, Dropbox began to grow very much, since then we have grown by about 100 million users per year .
It was necessary to take into account such a huge growth, and therefore at the end of 2011 we had shards - the base consisting of 1,600 shards. Initially, only 8 servers with 200 shards each. Now it’s 400 master servers with 4 shards each.
Link from the slideIn 2012, we realized that creating tables and updating them in the database for each added business logic is very difficult, dreary and problematic. Therefore, in 2012 we invented our own graph storage, which we called Edgestore , and since then all the business logic and meta information that the application generates is stored in Edgestore.
Edgestore essentially abstracts MySQL from clients. Clients have certain entities that are interconnected by links from the gRPC API to Edgestore Core, which converts this data to MySQL and somehow stores them there (basically it gives all this from the cache).
Link from the slideIn 2015, we left Amazon S3 , developed our own cloud storage called Magic Pocket. It contains information about where the block file is located, on which server, about the movement of these blocks between servers, is stored in MySQL.
Link from the slideBut MySQL is used in a very tricky way - in fact, as a large distributed hash table. This is a very different load, mainly on reading random entries. 90% recycling is I / O.
Database architecture
Firstly, we immediately identified some principles by which we build the architecture of our database:
- Reliability and durability . This is the most important principle and what customers expect from us - the data should not be lost.
- The optimal solution is an equally important principle. For example, backups should be made quickly and recovered too quickly.
- Simplicity of the solution - both architecturally and from the point of view of maintenance and further development support.
- Cost of ownership . If something optimizes the solution, but is very expensive, it does not suit us. For example, a slave that is one day behind master is very convenient for backups, but then you need to add another 1,000 to 6,000 servers - the cost of owning such a slave is very high.
All principles must be verifiable and measurable , that is, they must have metrics. If we are talking about the cost of ownership, then we need to calculate how many servers we have, for example, it goes under the database, how many servers it goes under backups, and how much it costs for Dropbox. When we choose a new solution, we count all the metrics and focus on them. When choosing any solution, we are fully guided by these principles.
Basic topology
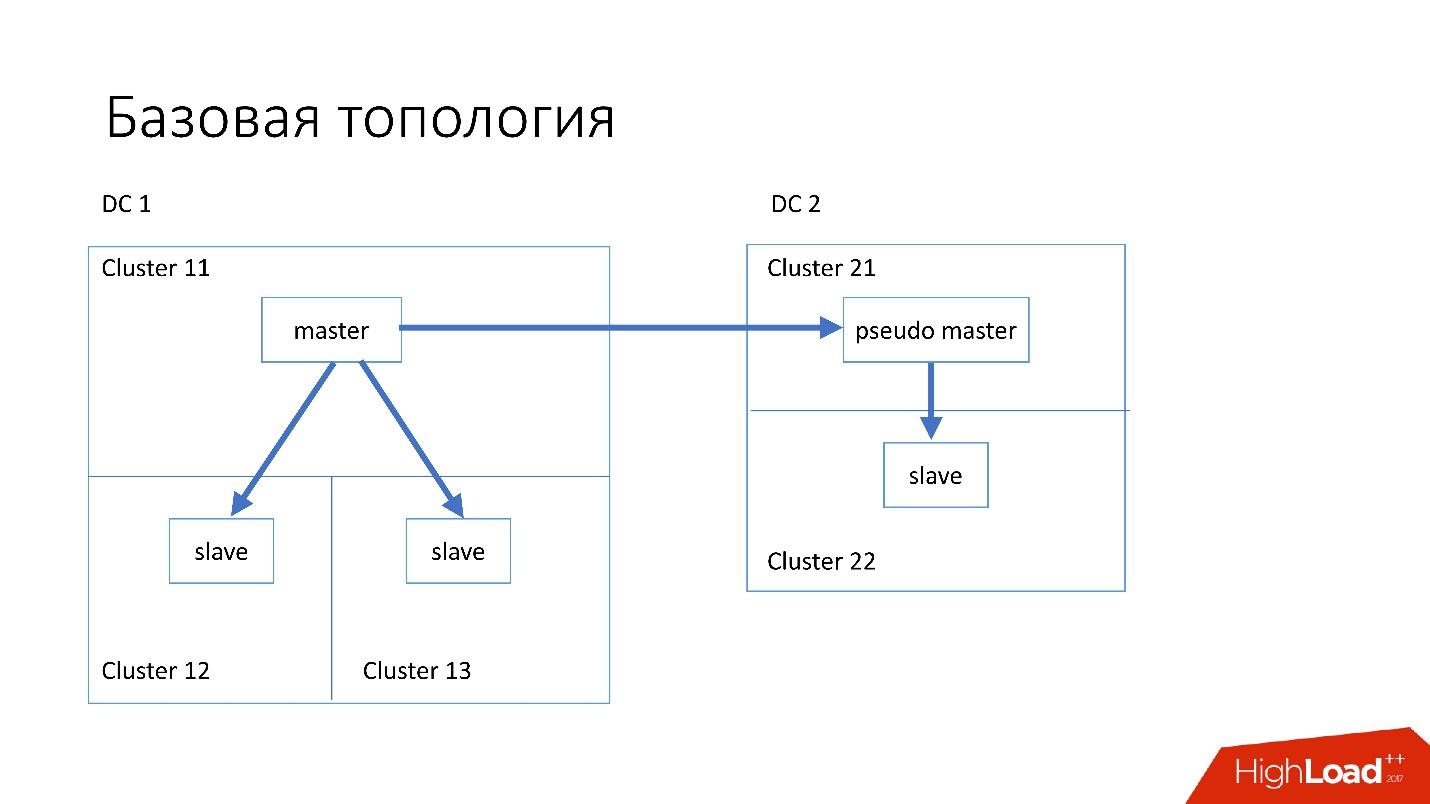
The database is organized approximately as follows:
- In the main data center, we have a master, in which all the records occur.
- The master server has two slave servers to which semisync replication occurs. Servers often die (about 10 per week), so we need two slave servers.
- Slave servers are in separate clusters. Clusters are completely separate rooms in the data center that are not connected to each other. If one room burns down, the second remains quite a working one.
- Also in another data center we have a so-called pseudo master (intermediate master), which is actually just a slave, which has another slave.
This topology is chosen because if we suddenly die the first data center, then in the second data center we already have almost complete topology . We simply change all addresses in Discovery, and customers can work.
Specialized topologies
We also have specialized topologies.
Topology Magic Pocket consists of one master-server and two slave-servers. This is done because Magic Pocket itself duplicates data among the zones. If it loses one cluster, it can recover all data from other zones via erasure code.
Topology active-active is a custom topology that is used in Edgestore. It has one master and two slaves in each of two data centers, and they are slaves for each other. This is a very dangerous scheme , but Edgestore at its level knows exactly what data it can write to which master for which range. Therefore, this topology does not break.
Instance
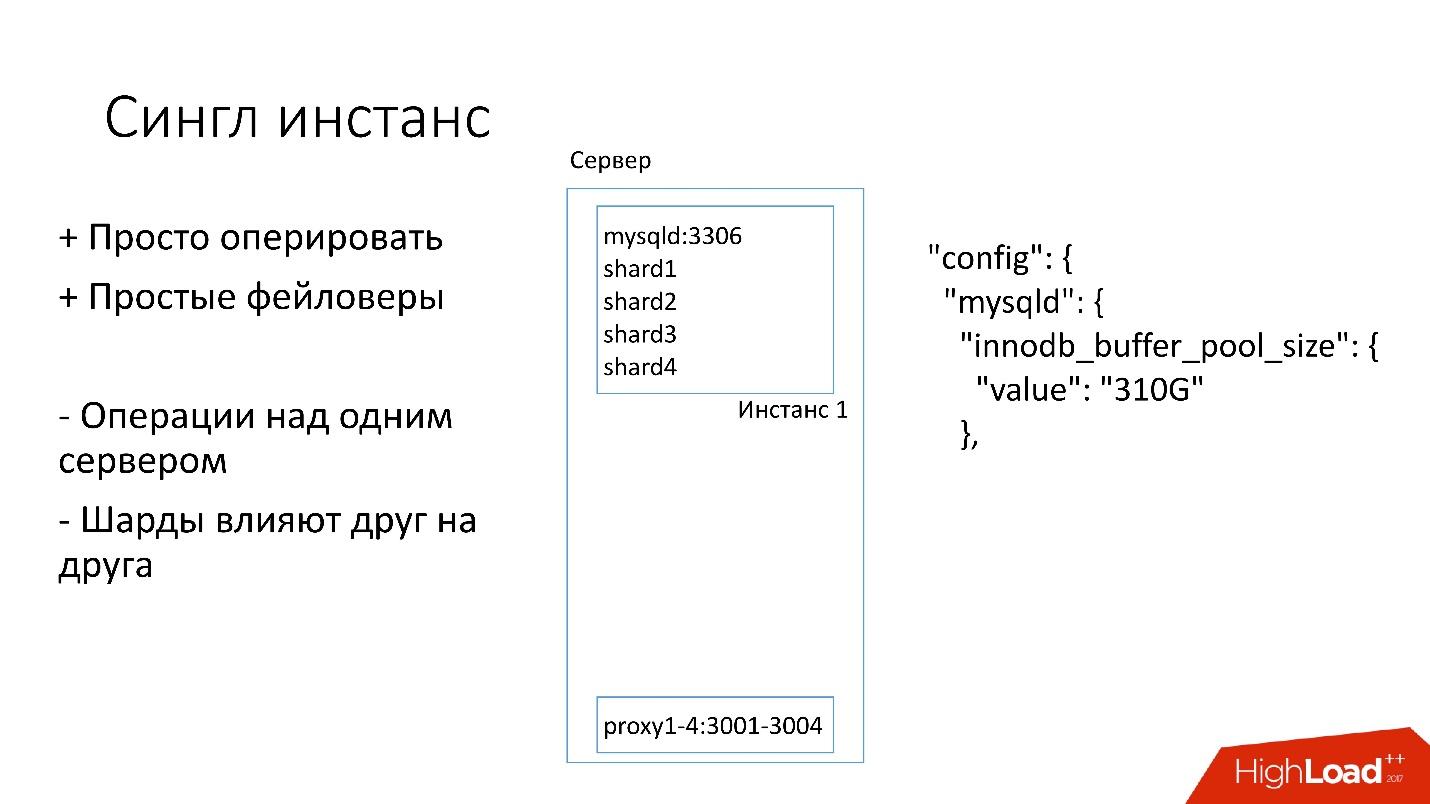
We have installed fairly simple servers with a configuration of 4-5 years old:
- 2x Xeon 10 cores;
- 5TB (8 SSD Raid 0 *);
- 384 GB memory.
* Raid 0 - because it is easier and faster for us to replace the whole server than the disks.
Single instance
On this server we have one big MySQL instance, on which there are several shards. This MySQL instance immediately allocates to itself almost all the memory. Other processes are running on the server: proxy, statistics collection, logs, etc.
This solution is good because:
+ It is easy to manage . If you need to replace MySQL instance, simply replace the server.
+ Just make files .
On the other hand:
- It is problematic that any operations occur on the whole MySQL instance and immediately on all shards. For example, if you need to make a backup, we make a backup of all shards at once. If you need to make a faylover, we make a faylover of all four shards at once. Accordingly, accessibility suffers 4 times more.
- Problems with replication of one shard affect other shards. MySQL replication is not parallel, and all shards work in one stream. If something happens to one shard, then the others also become victims.
Therefore, we are now switching to another topology.
Multi instance
In the new version, several MySQL instances are running on the server at once, each with one shard. What is better?
+ We can carry out operations only on one particular shard . That is, if you need a faylover, switch only one shard, if you need a backup, make a backup of only one shard. This means that operations are greatly accelerated - 4 times for a four-shard server.
+ Shards almost don't affect each other .
+ Improved replication.We can mix different categories and classes of databases. Edgestore takes up a lot of space, for example, all 4 TB, and Magic Pocket only takes 1 TB, but it has 90% utilization. That is, we can combine various categories that use I / O and machine resources in different ways, and run 4 replication threads.
Of course, this solution also has disadvantages:
- The biggest disadvantage is that it is much more difficult to manage all of this . We need some kind of smart planner who will understand where he can take this instance, where there will be an optimal load.
- Harder faylover .
Therefore, we are only now switching to this decision.
Discovery
Customers need to somehow know how to connect to the right database, so we have Discovery, which should:
- Very quickly notify the client about topology changes. If we changed the master and slave, customers should know about it almost instantly.
- The topology should not depend on the MySQL replication topology, because for some operations we change the MySQL topology. For example, when we do split, at the preparatory step to the target master, where we will take some shards, some of the slave servers migrate to this target master. Customers do not need to know about it.
- It is important that there is atomicity of operations and state verification. It is impossible for two different servers of the same database to become master at the same time.
How Discovery Developed
At first everything was simple: the address of the database in the source code in the config. When we needed to update the address, it was just that everything deployed very quickly.
Unfortunately, this does not work if there are a lot of servers.
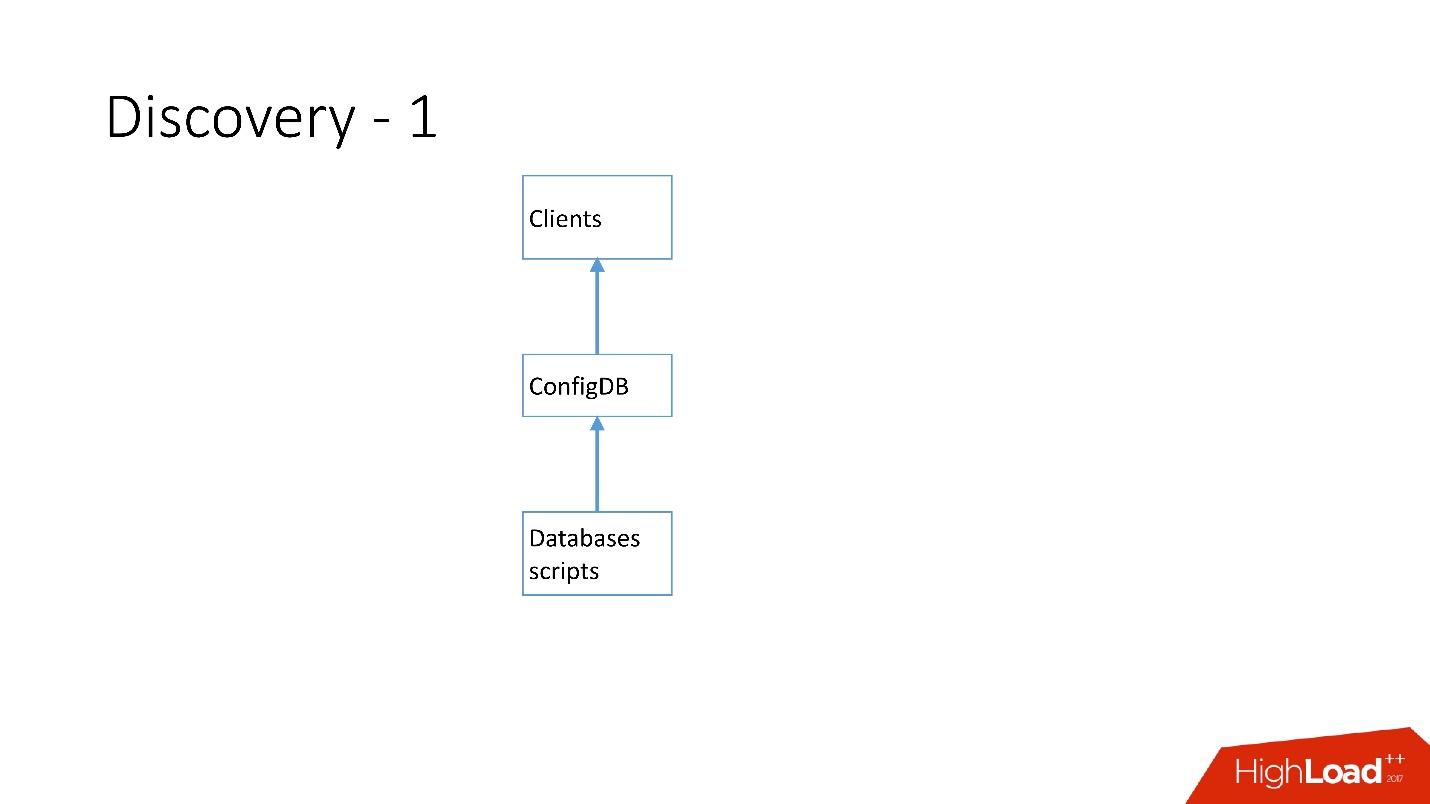
Above is the very first Discovery, which we had. There were database scripts that changed the label in ConfigDB — it was a separate MySQL table, and clients already listened to this database and periodically took data from there.
The table is very simple; there is a database category, a shard key, a master / slave database class, a proxy, and a database address. In fact, the client requested a category, database class, shard key, and he was returned a MySQL address at which he could already establish a connection.
As soon as there were a lot of servers, Memcash was added and clients began to communicate with him.
But then we reworked it. MySQL scripts began to communicate through gRPC, through a thin client with a service that we called RegisterService. When some changes occurred, RegisterService had a queue, and he understood how to apply these changes. RegisterService saved data in AFS. AFS is our internal system, built on the basis of ZooKeeper.
The second solution, which is not shown here, directly used ZooKeeper, and this created problems, because with us every shard was a node in ZooKeeper. For example, 100 thousand clients connect to ZooKeeper, if they suddenly died because of some kind of bug all together, then 100 thousand requests to ZooKeeper will come at once, which will simply drop it and it will not be able to rise.
Therefore, the AFS system was developed , which is used by the entire Dropbox.. In fact, it abstracts the work with ZooKeeper for all clients. The AFS daemon locally rotates on each server and provides a very simple file API of the form: create a file, delete a file, request a file, receive notification of file changes, and compare and swap operations. That is, you can try to replace the file with some version, and if this version has changed during the shift, the operation is canceled.
Essentially, such an abstraction over ZooKeeper, in which there is a local backoff and jitter algorithms. ZooKeeper is no longer falling under load. With AFS, we remove backups in S3 and in GIT, then the local AFS itself notifies customers that the data has changed.
In AFS, data is stored as files, that is, it is a file system API. For example, the shard.slave_proxy file is the largest, it takes about 28 Kb, and when we change the shard category and the slave_proxy class, all clients who subscribe to this file receive a notification. They re-read this file, which has all the necessary information. By shard key get the category and reconfigure the connection pool to the database.
Operations
We use very simple operations: promotion, clone, backups / recovery.
The operation is a simple state machine . When we go into an operation, we perform some checks, for example, a spin-check, which checks on timeouts several times if we can perform this operation. After that, we do some preparatory action that does not affect external systems. The actual operation itself.
All steps inside the operation have a rollback step (undo). If there is a problem with the operation, the operation tries to restore the system to its original position. If everything is normal, then a cleanup occurs, and the operation is completed.
We have such a simple state machine for any operation.
Promotion (change of master)
This is a very frequent operation in the database. There were questions about how to do alter on a hot master-server that works - he will get a stake. Simply, all these operations are performed on slave-servers, and then the slave changes with master places. Therefore, the promotion operation is very frequent .
We need to update the kernel - we are doing swap, we need to update the version of MySQL - we upgrade to the slave, we switch to master, we update there.
We have achieved a very fast promotion. For example, we have for four shards now a promotion of the order of 10-15 s. The graph above shows that when the promotion availability suffered by 0.0003%.
But normal promotion is not so interesting, because it is the usual operations that are performed every day. Faylover interesting.
Failover (replacement of a broken master)
Failover means that the database is dead.
- If the server is really dead, this is just the perfect case.
- In fact, it happens that the servers are partially alive.
- Sometimes the server dies very slowly. He refuses to raid-controllers, disk system, some requests return answers, but some threads are blocked and do not return answers.
- It happens that the master is just overloaded and does not respond to our health check. But if we make a promotion, then the new master will also be overloaded, and it will only get worse.
We replace the deceased master servers about 2-3 times a day , this is a fully automated process, no human intervention is needed. The critical section takes about 30 seconds, and it has a bunch of additional checks on whether the server is actually alive, or maybe it has already died.
Below is an approximate diagram of how the filer works.
In the selected section, we reboot the master server . This is necessary because we have MySQL 5.6, and in it semisync replication is not lossless. Therefore phantom reads are possible, and we need this master, even if it is not dead, to kill it as soon as possible so that the clients disconnect from it. Therefore, we do a hard reset via Ipmi - this is the first most important operation we need to do. In MySQL version 5.7, this is not so critical.
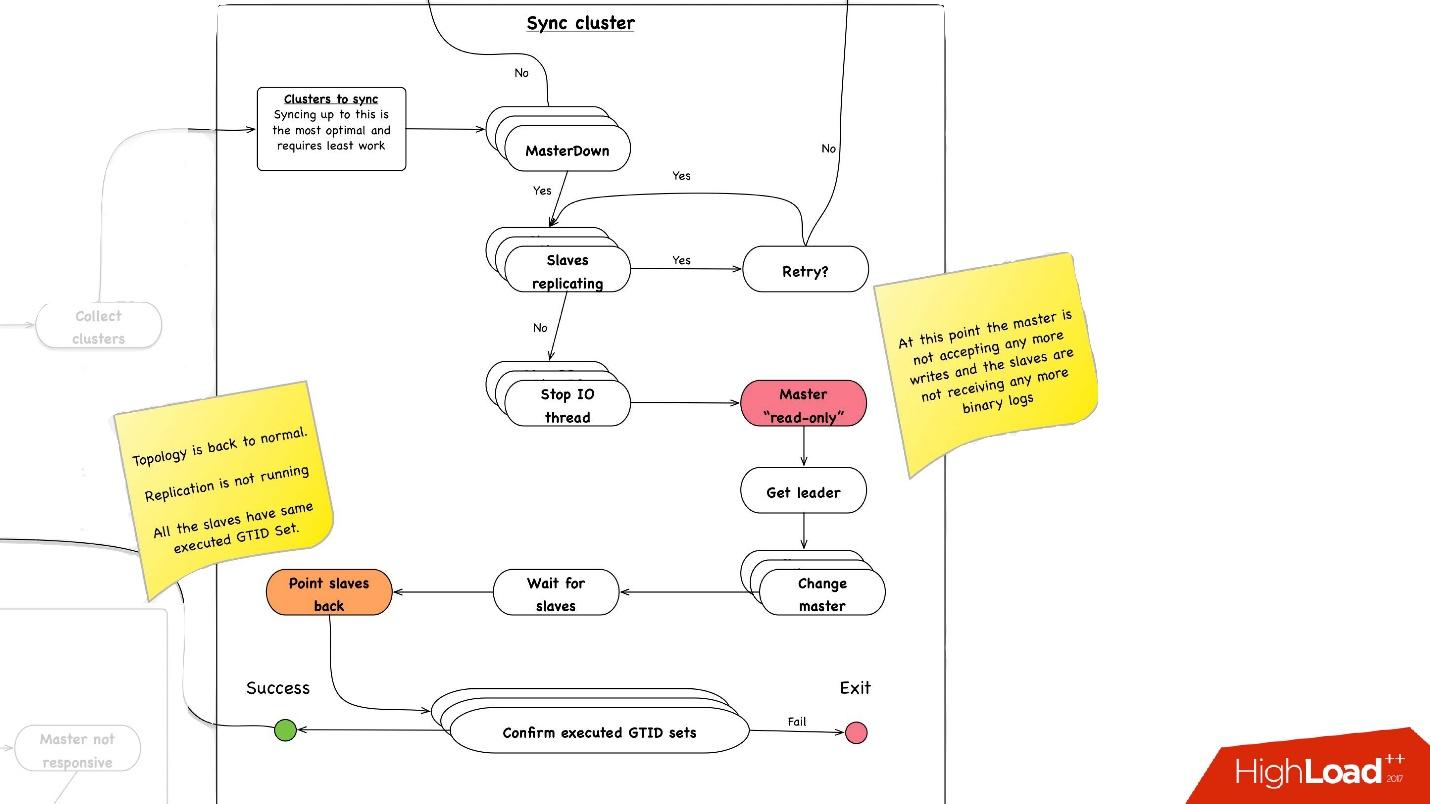
Cluster sync. Why do we need cluster synchronization?
If we recall the previous picture with our topology, one master server has three slave servers: two in one data center, one in the other. During the promotion, we need the master to be in the same main data center. But sometimes, when the slave is loaded, with semisync it happens that the semisync-slave becomes a slave in another data center, because it is not loaded. Therefore, we need to synchronize the entire cluster first, and then make a promotion on the slave in the data center we need. This is done very simply:
- We stop all I / O thread on all slave servers.
- After that, we already know for sure that the master is “read-only”, as semisync has disconnected and no one else can write anything there.
- Then we select the slave with the largest retrieved / executed GTID Set, that is, with the largest transaction that it has either downloaded or already applied.
- We migrate all the slave servers to this selected slave, start the I / O thread, and they are synchronized.
- We are waiting for them to synchronize, after which we have the entire cluster becomes synchronized. At the end, we check that all of us are executed GTID set set to the same position.
The second important operation is cluster synchronization . Then begins the promotion , which happens as follows:
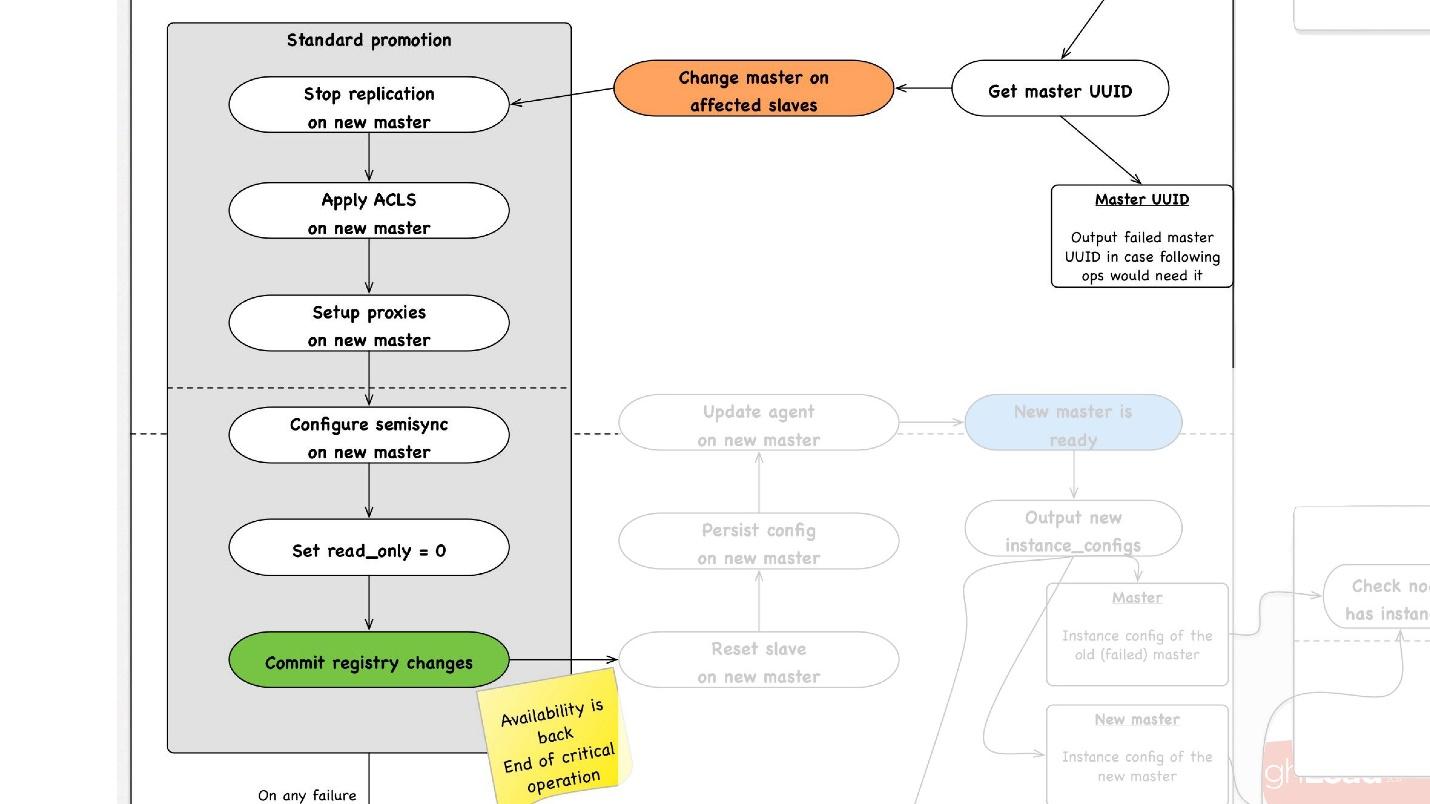
- We select any slave in the data center we need, tell it that it is a master, and start the operation of the standard promotion.
- We reconfigure all the slave servers to this master, stop replication there, apply ACLs, drive users in, stop some proxy servers, perhaps reload something.
- In the end, we do read_only = 0, that is, we say that you can now write to master and update the topology. From this point on, clients go to this master and everything works for them.
- Next we have non-critical post-processing steps. In them we restart some services on this host, redraw the configuration, do additional checks that everything works fine, for example, that the proxy allows traffic to pass.
- After that, the whole operation is completed.
At any step, in case of an error, we are trying to rollback to the point we can. That is, we cannot rollback to reboot. But for operations for which this is possible, for example, reassignment - change master - we can return master to the previous step.
Backups
Backups are a very important topic in databases. I do not know if you are making backups, but it seems to me that everyone should do them, this is already a beaten joke.
Patterns of use
● Add a new slave
The most important pattern that we use when adding a new slave server, we simply restore it from the backup. It happens all the time.
● Restoring data to a point in the past
Quite often, users delete data, and then ask them to restore it, including from the database. This rather frequent data recovery operation on a point in the past is automated.
● Recover the entire cluster from scratch
Everyone thinks that backups are needed to restore all data from scratch. In fact, this operation almost never required us. Last time we used it 3 years ago.
We look at backups as a product, so we tell customers that we have guarantees:
- We can restore any database. Under normal conditions, the expected recovery rate of 1Tb in 40 minutes.
- Any base can be restored to any location in the past six days.
These are our main guarantees that we give to our customers. The speed of 1 TB in 40 minutes, because there are restrictions on the network, we are not alone on these racks; traffic is still produced on them.
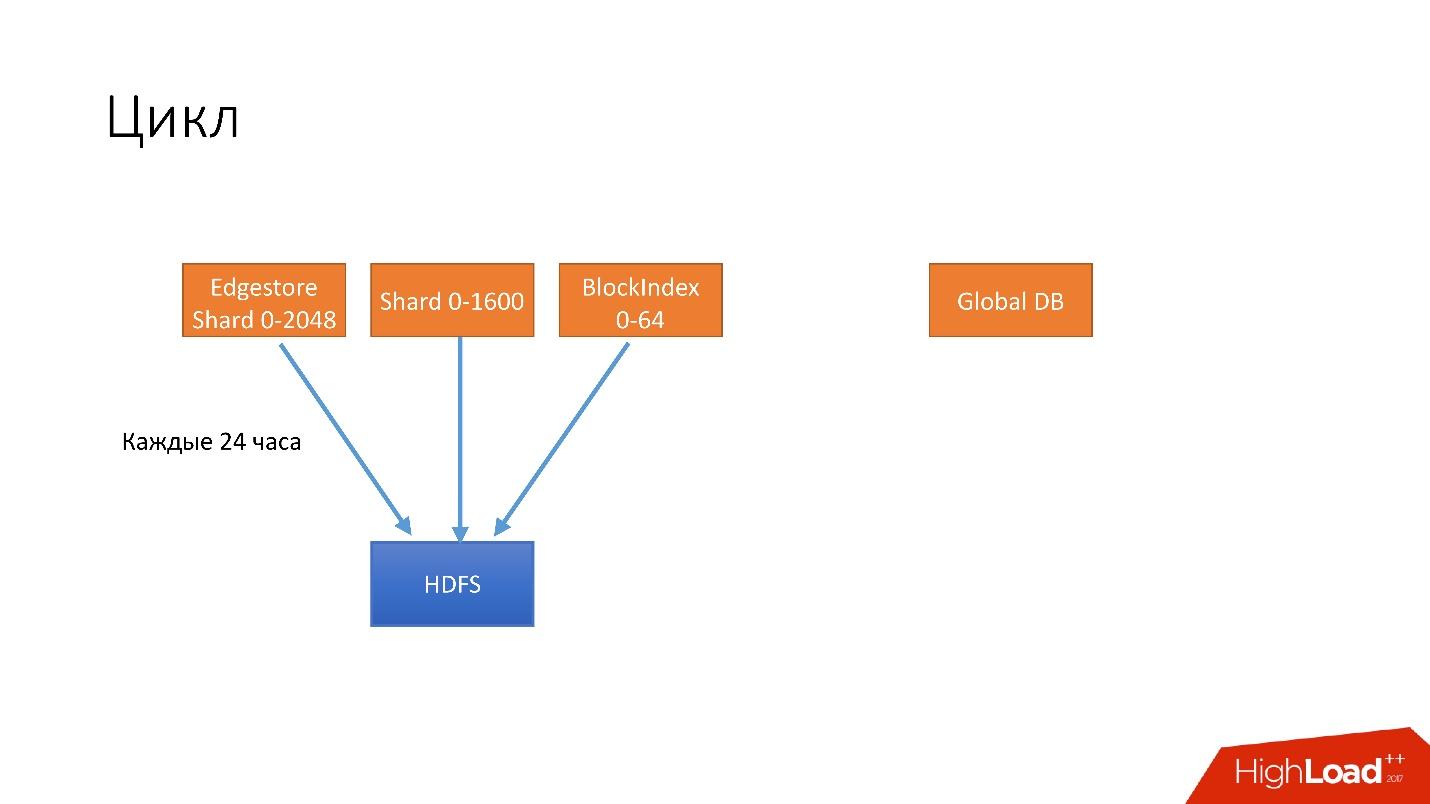
Cycle
We have introduced such an abstraction as a cycle. In one cycle, we try to backup almost all of our databases. We simultaneously spin 4 different cycles.
- The first cycle runs every 24 hours . We back up all our hijacked databases on HDFS, that's about a thousand or more hosts.
- Every 6 hours we make backups for unsharded databases, we still have some data on the Global DB. We really want to get rid of them, but, unfortunately, they still exist.
- Every 3 days we save all the information from the S3 shard database.
- Every 3 days we completely save all information of non-chard database to S3.
All this is stored for several cycles. Suppose if we store 3 cycles, then in HDFS we have the last 3 days, and the last 6 days in S3. So we support our guarantee.
This is an example of how they work.
In this case, we have two long loops running, which make backups of shardded databases, and one short one. At the end of each cycle, we necessarily verify that the backups work, that is, we do recovery on a certain percentage of the database. Unfortunately, we cannot recover all the data, but we definitely check some percentage of the data for the cycle. As a result, we will have 100 percent of the backups that we restored.
We have certain shards that we always restore to watch the recovery rate, to monitor possible regressions, and there are shards that we restore simply randomly to check that they have recovered and are working. Plus, when cloning, we also recover from backups.
Hot backups
Now we have a hot backup, for which we use the Percona tool xtrabackup. We run it in the —stream = xbstream mode, and it returns us on the working database, the stream of binary data. Next we have a script-splitter, which this binary stream divides into four parts, and then we compress this stream.
MySQL stores data on a disk in a very strange way and we have more than 2x compression. If the database occupies 3 TB, then, as a result of compression, the backup takes approximately 1 500 GB. Next, we encrypt this data so that no one can read it, and send it to HDFS and S3.
In the opposite direction it works exactly the same.
We prepare the server, where we will install the backup, get the backup from HDFS or from S3, decode and decompress it, the splitter compresses it all and sends it to xtrabackup, which restores all data to the server. Then crash-recovery occurs.
Some time, the most important problem of hot backups was that crash-recovery takes quite a long time. In general, you need to lose all transactions during the time you make a backup. After that we lose binlog so that our server will catch up with the current master.
How do we save binlogs?
We used to save binlog files. We collected the master files, alternated them every 4 minutes, or 100 MB each, and saved to HDFS.
Now we use a new scheme: there is a certain Binlog Backuper, which is connected to replications and to all databases. He, in fact, constantly merges binlog to himself and saves them to HDFS.
Accordingly, in the previous implementation, we could lose 4 minutes of binary logs, if we lost all 5 servers, in the same implementation, depending on the load, we lose literally seconds. Everything stored in HDFS and in S3 is stored for a month.
Cold backups
We are thinking of switching to cold backups.
Prerequisites for this:
- The speed of the channels on our servers has increased - it was 10 GB, it became 45 GB - you can recycle more.
- I want to restore and create clones faster, because we need a smarter scheduler for multi instances and want very often to transfer the slave and master from the server to the server.
- The most important point - with a cold backup, we can guarantee that the backup works. Because when we make a cold backup, we simply copy the file, then we start the database, and as soon as it starts up, we know that this backup works. After pt-table-checksum we know for sure that the data on the file system is consistent.
Warranties that were obtained with cold backups in our experiments:
- Under normal conditions, the expected recovery rate is 1TB in 10 minutes, because it is just copying files. No need to do a crash-recovery, but this is the most problematic place.
- Any base can be restored for any period of time for the last six days.
In our topology, there is a slave in another data center that does almost nothing. We periodically stop it, make a cold backup and run it back. Everything is very simple.
Plans ++
These are plans for the distant future. When we update our Hardware Park, we want to add an additional spindle disk (HDD) of about 10 TB to each server, and make hot backups + crash recovery xtrabackup on it, and then download backups. Accordingly, we will have backups on all five servers simultaneously, at different points in time. This, of course, will complicate all the processing and operation, but will reduce the cost, because the HDD costs a penny, and a huge cluster of HDFS is expensive.
Clone
As I said, cloning is a simple operation:
- this is either recovery from backup and playing binary logs;
- or the backup process immediately to the target server.
In the diagram where we copy to HDFS, the data is also simply copied to another server, where there is a receiver that receives all the data and restores it.
Automation
Of course, on 6,000 servers, no one does anything manually. Therefore, we have various scripts and automation services, there are a lot of them, but the main ones are:
- Auto-replace;
- DBManager;
- Naoru, Wheelhouse
Auto-replace
This script is needed when the server is dead, and you need to understand whether it is true, and what the problem is - maybe the network is broken or something else. It needs to be resolved as quickly as possible.
Availability is a function of the time between the occurrence of errors and the time over which you can detect and fix this error. We can fix it very quickly - our recovery is very fast, so we need to determine the existence of a problem as soon as possible.
On each MySQL server, the service that heartbeat writes is running. Heartbeat is the current timestamp.
There is also another service that writes the value of some predicates, for example, that master is in read-write mode. After that, the second service sends this heartbeat to the central repository.
We have an auto-replace script that works like this.
The scheme in the best quality and separately its enlarged fragments are in the presentation of the report, starting with 91 slides. What's going on here?
- There is a main loop in which we check heartbeat in the global database. We look, this service is registered or not. Count the heartbeats, for example, are there two heartbeats in 30 seconds?
- Further, we look, whether their quantity satisfies the threshold value. If not, then something is wrong with the server - since it did not send heartbeat.
- After that, we do a reverse check just in case - suddenly these two services have died, something is connected to the network, or the global database cannot for some reason record heartbeat. In reverse check, we connect to the broken database and check its status.
- If nothing has already helped, we look to see if the master position is progressing or not, whether recordings occur on it. If nothing happens, then this server is definitely not working.
- The last stage is auto-replace itself.
Auto-replace is very conservative. He never wants to do a lot of automatic operations.
- First, we check if there have been any recent topology operations? Maybe this server has just been added and something is not running on it yet.
- We check if there were any replacements in the same cluster at some time interval.
- We check what our failure limit is. If we have many problems at once - 10, 20 - then we will not automatically solve them all, because we may inadvertently disrupt the operation of all databases.
Therefore, we solve only one problem at a time .
Accordingly, for the slave server, we start cloning and simply remove it from the topology, and if it is master, then we launch the file shareer, the so-called emergency promotion.
DBManager
DBManager is a service for managing our databases. He has:
- a smart task scheduler that knows exactly when to start which job;
- logs and all information: who, when and what launched - this is the source of truth;
- synchronization point.
DBManager is quite simple architecturally.
- There are clients that are either DBAs that do something through the web interface, or scripts / services that have written DBAs that access gRPC.
- There are external systems like Wheelhouse and Naoru, which through gRPC goes to DBManager.
- There is a scheduler who understands what operation, when and where he can run.
- There is a very stupid worker who, when an operation comes to him, starts it, checks it by PID. Worker can reboot, processes are not interrupted. All workers are located as close as possible to the servers on which operations take place, so that, for example, when updating ACLS, we don’t have to do a lot of round-trips.
- On each SQL host we have a DBAgent - this is an RPC server. When you need to perform some operation on the server, we send an RPC request.
We have a web interface for DBManager, where you can see the current running tasks, logs to these tasks, who started what and when, what operations were performed for a specific database server, etc.
There is a fairly simple CLI interface where you can run tasks and also view them in convenient views.
Remediations
We also have a problem response system. When something breaks in us, for example, the disk failed or some service does not work, Naoru works . This is a system that works throughout Dropbox, everyone uses it, and it was built for just such small tasks. I talked about Naoru in my 2016 report .
The wheelhouse system is based on the state machine and is designed for long processes. For example, we need to update the kernel on all MySQL on our entire cluster of 6000 machines. Wheelhouse clearly does this - it updates on the slave server, launches the promotion, the slave becomes master, it updates on the master server. This operation can take a month or even two.
Monitoring
It is very important.
If you do not monitor the system, then most likely it does not work.
We monitor everything in MySQL - all the information we can get from MySQL, we have somewhere saved, we can access it in time. We store information on InnoDb, statistics on requests, on transactions, on the length of transactions, on the length of the transaction, on replication, on the network - all, all - a huge number of metrics.
Alert
We have configured 992 alerts. In fact, nobody looks at the metrics, it seems to me that there are no people who come to work and start looking at the metrics chart, there are more interesting tasks.
Therefore, there are alerts that are triggered when certain threshold values are reached. We have 992 alerts, no matter what happens, we will find out about it .
Incidents
We have PagerDuty - this is a service through which alerts are sent to those in charge who are starting to take action.
In this case, an error occurred in the emergency promotion and immediately after that an alert was registered that the master had fallen. After that, the duty officer checked what prevented the emergency promotion, and did the necessary manual operations.
We will definitely analyze every incident that has occurred, for each incident we have a task in the task tracker. Even if this incident is a problem in our alerts, we also create a task, because if the problem is in the logic of the alert and the thresholds, they need to be changed. Alerts should not just ruin people's lives. Alert is always painful, especially at 4 am.
Testing
As with monitoring, I am sure that everyone is involved in testing. In addition to the unit tests with which we cover our code, we have integration tests in which we test:
- all the topologies that we have;
- all operations on these topologies.
If we have promotion operations, we test in the integration test of promotion operations. If we have cloning, we do cloning for all the topologies we have.
Example of topology
We have topologies for all occasions: 2 data centers with multi instance, with shards, without shards, with clusters, one data center - in general, almost any topology - even those that we do not use, just to view .
In this file we just have the settings, which servers and with what we need to raise. For example, we need to raise the master, and we say that we need to do this with such data of the instances, with such databases at such ports. We have almost everything going with the help of Bazel, which creates a topology on the basis of these files, starts the MySQL server, then the test is started.
The test looks very simple: we indicate which topology is used. In this test, we test auto_replace.
- We create auto_replace service, we start it.
- We kill the master in our topology, wait for some time and see that the target-slave has become the master. If not, the test fails.
Stages
Stage environments are the same databases as in production, but they do not have user traffic, but there is some kind of synthetic traffic that is similar to production through Percona Playback, sysbench, and similar systems.
In Percona Playback, we record traffic, then we lose it on the stage-environment with different intensity, we can lose 2-3 times faster. That is, it is an artificial, but very close to the real load.
This is necessary because in integration tests we cannot test our production. We cannot test the alert or that the metrics work. At testing, we test alerts, metrics, operations, periodically we kill servers and see that they are normally assembled.
Plus, we test all the automations together, because in the integration tests, most likely, one part of the system is tested, and in the staging all the automated systems work simultaneously. Sometimes you think that the system will behave this way and not otherwise, but it may behave differently.
DRT (Disaster recovery testing)
We also conduct tests in production - right on real databases. This is called Disaster recovery testing. Why do we need it?
● We want to test our warranties.
This is done by many large companies. For example, Google has one service that worked so stably - 100% of the time - that all the services that used it, decided that this service is really 100% stable and never drops. Therefore, Google had to drop this service specifically for users to take into account such an opportunity.
So we - we have a guarantee that MySQL works - and sometimes it does not work! And we have a guarantee that it may not work for a certain period of time, customers should take this into account. Periodically we kill the production master, or if we want to make a file share, we kill all the slave servers to see how semisync replication behaves.
● Customers are ready for these errors (replacement and death of the master)
Why is this good? We had a case when with the promotion of 4 shards out of 1600, the availability dropped to 20%. It seems that something is wrong, for 4 shards out of 1600 there must be some other numbers. Faylovera for this system occurred quite rarely, about once a month, and everyone decided: “Well, this is faylover, it happens.”
At some point, when we switched to a new system, one person decided to optimize those two heartbeat recording services and merged them into one. This service did something else and, eventually, was dying and heartbeats stopped recording. It so happened that for this client we had 8 faylover per day. All lay - 20% availability.
It turned out that in this client keep-alive 6 hours. Accordingly, as soon as the master was dying, all of our connections were kept for another 6 hours. The pool could not continue to work - it keeps connections, it is limited and does not work. It repaired.
Doing a faylover again - no longer 20%, but still a lot. Something's all wrong anyway. It turned out that the bug in the implementation of the pool. The pool, when requested, addressed many shards, and then put it all together. If any shards were fake, some race condition occurred in the Go code, and the whole pool was clogged. All these shards could not work anymore.
Disaster recovery testing is very useful, because clients must be prepared for these errors, they must check their code.
● Plus Disaster recovery testing is good because it goes into business hours and everything is in place, less stress, people know what is going to happen now. This is not happening at night, and it is great.
Conclusion
1. Everything needs to be automated, never clap hands.
Each time when someone climbs into the system with our hands, everything dies and breaks in us - every single time! - even on simple operations. For example, one slave died, the person had to add a second one, but decided to remove the dead slave with his hands from the topology. However, instead of the deceased, he copied the live command into the command - the master was left without a slave at all. Such operations should not be done manually.
2. Tests should be permanent and automated (and in production).
Your system is changing, your infrastructure is changing. If you checked it once and it seemed to work, it does not mean that it will work tomorrow. Therefore, it is necessary to do automated testing every day, including in production.
3. It is imperative to own clients (libraries).
Users may not know how databases work. They may not understand why they need timeouts, keep-alive. Therefore, it is better to own these customers - you will be calmer.
4. You need to define your principles of building a system and your guarantees, and always comply with them.
Thus it is possible to support 6 thousand database servers.
In questions after the report, and especially the answers to them, there is also a lot of useful information.Questions and answers
Она не отличается на порядки. Она практически нормально распределена. У нас есть троттлинг, то есть мы не можем перегрузить шард по сути, мы троттлим на уровне клиента. Вообще бывает такое, что какая-нибудь звезда выкладывает фотографию, и шард практически взрывается. Тогда мы баним эту ссылку
Это все создается вручную. У нас есть собственная внутренняя система, называется Vortex, где хранятся метрики, в ней поддерживаются алерты. Есть yaml-файл, в котором написано, что есть условие, например, что бэкапы должны выполняться каждый день, и если это условие выполняется, то алерт не срабатывает. Если не выполняется, тогда приходит алерт.
Это наша внутренняя разработка, потому что мало кто умеет хранить столько метрик, сколько нам нужно.
Вообще работать в базах данных — это реально боль. Если база данных упала, сервис не работает, весь Dropbox не работает. Это реальная боль. DRT полезно тем, что это бизнес-часы. То есть я готов, я сижу за рабочим столом, я выпил кофе, я свеж, я готов сделать все, что угодно.
Хуже, когда это происходит в 4 часа ночи, и это не DRT. Например, последний сильный сбой у нас был недавно. При вливании новой системы мы забыли выставить OOM Score для нашего MySQL. Там еще был другой сервис, который читал binlog. В какой-то момент наш оператор вручную — опять же вручную! — запускает команду по удалению в Percona checksum-table какой-то информации. Просто обычное удаление, простая операция, но эта операция породила огромный binlog. Сервис прочитал этот binlog в память, OOM Killer пришел и думает, кого бы убить? А мы забыли OOM Score выставить, и он убивает MySQL!
У нас в 4 часа ночи умирают 40 мастеров. Когда умирает 40 мастеров, это реально очень страшно и опасно. DRT — это не страшно и не опасно. Мы лежали где-то час.
Кстати, DRT — это хороший способ отрепетировать такие моменты, чтобы мы точно знали, какая последовательность действий нужна, если что-то массово поломается.
Вы имеете в виду что-нибудь вроде group replication, galera cluster и т.п.? Мне кажется, group application еще не готов к жизни. Galera мы, к сожалению, еще не пробовали. Это здорово, когда фейловер есть внутри вашего протокола, но, к сожалению, у них есть очень многих дргуих проблем, и не так просто перейти на это решение.
У нас до сих пор еще 5.6 стоит. Я не знаю, когда мы перейдем на 8. Может, попробуем.
Нагрузка на master регулируется semisync’ом. Semisync ограничивает запись на мастер производительностью slave-серверов. Конечно, может быть такое, что транзакция пришла, semisync отработал, но slave’ы очень долго проигрывают эту транзакцию. Нужно тогда подождать, пока slave проиграет эту транзакцию до конца.
Когда мы запускаем процесс promotion, мы отключаем I/O. После этого master не может ничего записать, потому что semisync репликация. Может прийти фантомное чтение, к сожалению, но это другая проблема уже.
Все скрипты написаны на Python, все сервисы написаны на Go. Это наша политика. Логику поменять несложно — просто в Python-коде, по которому генерируется стейт-диаграмма.
Да. Тестирование у нас собирается с помощью Bazel. Есть некие настроечные файлы (json) и Bazel поднимает скрипт, который по этому настроечному файлу создает топологию для нашего теста. Там описаны разные топологии.
У нас это все работает в docker-контейнерах: либо это работает в CI, либо на Devbox. У нас есть система Devbox. Мы все разрабатываем на некоем удаленном сервере, и это может на нем работать, например. Там это тоже запускается внутри Bazel, внутри docker-контейнера или в Bazel Sandbox. Bazel очень сложный, но прикольный.
Каждый инстанс стал меньше. Соответственно, чем с меньшей памятью MySQL оперирует, тем ему проще жить. Любой системе проще оперировать небольшим количеством памяти. В этом месте мы ничего не потеряли. У нас есть простейшие С-группы, которые ограничивают по памяти эти инстансы.
Это десятки экзабайт, мы переливали данные с Амазона в течение года.
Да, изначально было 1600. Это было сделано чуть меньше 10 лет назад, и до сих пор живем. Но у нас еще есть 4 шарда — в 4 раза мы можем еще увеличить место.
Самое главное — это диски вылетают. У нас RAID 0 — диск вылетел, мастер умер. Это самая главная проблема, но нам проще заменить этот сервер. Google проще заменить дата-центр, нам сервер пока еще. Corruption checksum у нас практически не бывало. Если честно, я не помню, когда последний раз такое было. Просто мы достаточно часто обновляем мастера. У нас время жизни одного мастера ограничено 60 днями. Он не может жить дольше, после этого мы его заменяем на новый сервер, потому что почему-то в MySQL постоянно что-то накапливается, и через 60 дней мы видим, что начинают проблемы происходить. Может быть, не в MySQL, может быть, в Linux.
Мы не знаем, что это за проблема и не хотим с этим разбираться. Мы просто ограничили время 60 днями, и обновляем весь стек. Не нужно прикипать к одному мастеру.
Мы храним информацию о файле, о блоках. Мы можем — в Dropbox есть возможность восстанавливать файлы.
Вообще в Dropbox есть какие-то гарантии, за какой промежуток времени сколько версий хранится. Это немножко другое. Есть система, которая умеет восстанавливать файлы, и там файлы просто не удаляются сразу, они в какую-то корзину кладутся.
Есть проблема, когда совершенно все удалено. Файлы есть, есть блоки, но в базе данных нет информации, как из этих блоков файл собрать. В такой момент мы можем проиграть до какого-то момента, то есть восстановились за 6 дней, проиграли до момента, когда этот файл был удален, не стали его удалять, восстановили и отдали пользователю.
Questions and answers
- What will happen if there is an imbalance in the load on shards - some kind of meta-information about some file has turned out to be more popular? Is it possible to dissolve this shard, or is the load on shards different nowhere by orders of magnitude?
Она не отличается на порядки. Она практически нормально распределена. У нас есть троттлинг, то есть мы не можем перегрузить шард по сути, мы троттлим на уровне клиента. Вообще бывает такое, что какая-нибудь звезда выкладывает фотографию, и шард практически взрывается. Тогда мы баним эту ссылку
— Вы говорили у вас 992 алерта. Можно поподробнее, что это такое — это из коробки или это создается? Если создается, то это ручной труд или что-то вроде машинного обучения?
Это все создается вручную. У нас есть собственная внутренняя система, называется Vortex, где хранятся метрики, в ней поддерживаются алерты. Есть yaml-файл, в котором написано, что есть условие, например, что бэкапы должны выполняться каждый день, и если это условие выполняется, то алерт не срабатывает. Если не выполняется, тогда приходит алерт.
Это наша внутренняя разработка, потому что мало кто умеет хранить столько метрик, сколько нам нужно.
— Насколько крепкие должны быть нервы, чтобы делать DRT? Ты уронил, CODERED, не поднимается, с каждой минутой паники все больше.
Вообще работать в базах данных — это реально боль. Если база данных упала, сервис не работает, весь Dropbox не работает. Это реальная боль. DRT полезно тем, что это бизнес-часы. То есть я готов, я сижу за рабочим столом, я выпил кофе, я свеж, я готов сделать все, что угодно.
Хуже, когда это происходит в 4 часа ночи, и это не DRT. Например, последний сильный сбой у нас был недавно. При вливании новой системы мы забыли выставить OOM Score для нашего MySQL. Там еще был другой сервис, который читал binlog. В какой-то момент наш оператор вручную — опять же вручную! — запускает команду по удалению в Percona checksum-table какой-то информации. Просто обычное удаление, простая операция, но эта операция породила огромный binlog. Сервис прочитал этот binlog в память, OOM Killer пришел и думает, кого бы убить? А мы забыли OOM Score выставить, и он убивает MySQL!
У нас в 4 часа ночи умирают 40 мастеров. Когда умирает 40 мастеров, это реально очень страшно и опасно. DRT — это не страшно и не опасно. Мы лежали где-то час.
Кстати, DRT — это хороший способ отрепетировать такие моменты, чтобы мы точно знали, какая последовательность действий нужна, если что-то массово поломается.
— Хотел бы подробнее узнать про переключение master-master. Во-первых, почему не используется кластер, к примеру? Кластер баз данных, то есть не master-slave с переключением, а master-master аппликация, чтобы если один упал, то и не страшно.
Вы имеете в виду что-нибудь вроде group replication, galera cluster и т.п.? Мне кажется, group application еще не готов к жизни. Galera мы, к сожалению, еще не пробовали. Это здорово, когда фейловер есть внутри вашего протокола, но, к сожалению, у них есть очень многих дргуих проблем, и не так просто перейти на это решение.
— Кажется, в MySQL 8 есть что-то типа InnoDb кластера. Не пробовали?
У нас до сих пор еще 5.6 стоит. Я не знаю, когда мы перейдем на 8. Может, попробуем.
— В таком случае, если у вас есть один большой master, при переключении с одного на другой, получается на slave-серверах высокой нагрузкой скапливается очередь. Если master погасить, надо, чтобы очередь добежала, чтобы slave переключить в режим master — или как-то по-другому это делается?
Нагрузка на master регулируется semisync’ом. Semisync ограничивает запись на мастер производительностью slave-серверов. Конечно, может быть такое, что транзакция пришла, semisync отработал, но slave’ы очень долго проигрывают эту транзакцию. Нужно тогда подождать, пока slave проиграет эту транзакцию до конца.
— Но тогда на master будут поступать новые данные, и надо будет...
Когда мы запускаем процесс promotion, мы отключаем I/O. После этого master не может ничего записать, потому что semisync репликация. Может прийти фантомное чтение, к сожалению, но это другая проблема уже.
— Эти все красивые стейт—машины — на чем написаны скрипты и как сложно добавить новый шаг? Что нужно сделать тому, кто пишет эту систему?
Все скрипты написаны на Python, все сервисы написаны на Go. Это наша политика. Логику поменять несложно — просто в Python-коде, по которому генерируется стейт-диаграмма.
— А можно подробнее про тестирование. Как написаны тесты, как они разворачивают ноды в виртуалке — это контейнеры?
Да. Тестирование у нас собирается с помощью Bazel. Есть некие настроечные файлы (json) и Bazel поднимает скрипт, который по этому настроечному файлу создает топологию для нашего теста. Там описаны разные топологии.
У нас это все работает в docker-контейнерах: либо это работает в CI, либо на Devbox. У нас есть система Devbox. Мы все разрабатываем на некоем удаленном сервере, и это может на нем работать, например. Там это тоже запускается внутри Bazel, внутри docker-контейнера или в Bazel Sandbox. Bazel очень сложный, но прикольный.
— Когда вы сделали на одном сервере 4 инстанса, не потеряли ли вы в эффективности использования памяти?
Каждый инстанс стал меньше. Соответственно, чем с меньшей памятью MySQL оперирует, тем ему проще жить. Любой системе проще оперировать небольшим количеством памяти. В этом месте мы ничего не потеряли. У нас есть простейшие С-группы, которые ограничивают по памяти эти инстансы.
— Если у вас 6 000 серверов хранят базы данных, можете назвать, сколько миллиардов петабайт хранится в ваших файлах?
Это десятки экзабайт, мы переливали данные с Амазона в течение года.
— Получается, у вас вначале было 8 серверов, на них по 200 шардов, потом 400 серверов по 4 шарда. У вас 1600 шардов — это какое-то жестко заданное значение? Вы больше не сможете никогда сделать? Это будет больно, если вам понадобится, например, 3 200 шардов?
Да, изначально было 1600. Это было сделано чуть меньше 10 лет назад, и до сих пор живем. Но у нас еще есть 4 шарда — в 4 раза мы можем еще увеличить место.
— Как умирают сервера, в основном по каким причинам? Что происходит чаще, что реже, и особенно интересно, происходят ли спонтанные карапты блоков?
Самое главное — это диски вылетают. У нас RAID 0 — диск вылетел, мастер умер. Это самая главная проблема, но нам проще заменить этот сервер. Google проще заменить дата-центр, нам сервер пока еще. Corruption checksum у нас практически не бывало. Если честно, я не помню, когда последний раз такое было. Просто мы достаточно часто обновляем мастера. У нас время жизни одного мастера ограничено 60 днями. Он не может жить дольше, после этого мы его заменяем на новый сервер, потому что почему-то в MySQL постоянно что-то накапливается, и через 60 дней мы видим, что начинают проблемы происходить. Может быть, не в MySQL, может быть, в Linux.
Мы не знаем, что это за проблема и не хотим с этим разбираться. Мы просто ограничили время 60 днями, и обновляем весь стек. Не нужно прикипать к одному мастеру.
— Вы сказали, что за последние 6 дней можете восстановиться из бэкапа на любое состояние. Например, человек залил JPEG с одним названием, потом залил такой же JPEG, но измененный, то вы можете достать первую версию? То есть, получается, вы храните версионность файлов и какие-то метаданные с версиями? Если человек попросит — я хочу достать первую версию файла, вы можете ему это отдать или нет?
Мы храним информацию о файле, о блоках. Мы можем — в Dropbox есть возможность восстанавливать файлы.
— Как вы потом вычищаете это все? Нет проблем с фрагментацией на дисках и так далее? Много данных стирается с диска, получается, через какое-то время, когда версия становится ненужной, протухшей? Допустим, человек залил 10 версий файлов поочередно. Очевидно, через 7 дней в бэкапе вы поймете, что вам первые 6 версий уже не нужны, и их нужно удалить. Или они вечно хранятся?
Вообще в Dropbox есть какие-то гарантии, за какой промежуток времени сколько версий хранится. Это немножко другое. Есть система, которая умеет восстанавливать файлы, и там файлы просто не удаляются сразу, они в какую-то корзину кладутся.
Есть проблема, когда совершенно все удалено. Файлы есть, есть блоки, но в базе данных нет информации, как из этих блоков файл собрать. В такой момент мы можем проиграть до какого-то момента, то есть восстановились за 6 дней, проиграли до момента, когда этот файл был удален, не стали его удалять, восстановили и отдали пользователю.
Follow the blog or subscribe to the newsletter , facebook or youtube channel - we regularly publish fresh materials and updates in the preparation of Highload ++ 2018 . In the latter, you can take an active part by sending an application for a report before September 1 .