Collaborative filtering
In the modern world, one often encounters the problem of recommending goods or services to users of an information system. In the old days, recommendations were made with a summary of the most popular products: this can be observed even now by opening the same Google Play . But over time, such recommendations began to be superseded by targeted (targeted) offers: users are recommended not just popular products, but those products that they surely will like. Not so long ago, Netflix held a contest with a prize pool of $ 1 million, whose task was to improve the algorithm for recommending films ( more ). How do similar algorithms work?
This article discusses the collaborative filtering algorithm for user similarity, determined using the cosine measure, as well as its implementation in python.

Suppose we have a matrix of ratings put up by users to products, for simplicity of presentation, numbers 1-9 are assigned to products:

You can set it using a csv file in which the first column is the user name, the second is the product identifier, and the third is the user’s rating. Thus, we need a csv file with the following contents:
To get started, we’ll develop a function that reads the above csv file. To store recommendations, we will use the standard dict data structure for python: each user is assigned a directory of his ratings of the form “product”: “rating”. The following code will turn out:
It is intuitively clear that to recommend a product to user # 1, you need to choose from products that some 2-3-4-etc. Users like, which are most similar in their ratings to user # 1. How to get a numerical expression of this "similarity" of users? Let's say we have M products. The ratings set by an individual user are a vector in the M-dimensional space of products, and we can compare vectors. Among the possible measures are the following:
In more detail, various measures and aspects of their application, I am going to consider in a separate article. In the meantime, suffice it to say that in recommender systems the cosine measure and Tanimoto's correlation coefficient are most often used. Let us consider in more detail the cosine measure, which we are going to implement. The cosine measure for two vectors is the cosine of the angle between them. From the school course of mathematics, we remember that the cosine of the angle between two vectors is their scalar product divided by the length of each of the two vectors: We
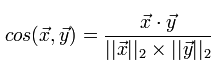
implement the calculation of this measure, not forgetting that we have a lot of user ratings presented in the form of a “product” dict : "Rating"
In the implementation, we used the fact that the scalar product of the vector itself gives the square of the length of the vector - this is not the best solution from the point of view of performance, but in our example, the speed is not fundamental.
So, we have a matrix of user preferences and we are able to determine how two users are similar to each other. Now it remains to implement the collaborative filtering algorithm, which consists in the following:
In the form of a formula, this algorithm can be represented as
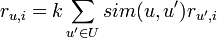
where the function sim is the measure of similarity of two users that we have chosen, U is the set of users, r is the assigned grade, k is the normalization coefficient:
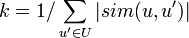
Now it remains only to write the corresponding code
To check its health, you can run the following command:
Which will result in the following result:
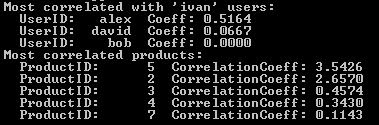
We looked at an example and implemented one of the simplest options for collaborative filtering using a cosine similarity measure. It is important to understand that there are other approaches to collaborative filtering, other formulas for calculating product ratings, other measures of similarity ( article , section “See also”). Further development of this idea can be carried out in the following areas:
This article discusses the collaborative filtering algorithm for user similarity, determined using the cosine measure, as well as its implementation in python.
Input data
Suppose we have a matrix of ratings put up by users to products, for simplicity of presentation, numbers 1-9 are assigned to products:
You can set it using a csv file in which the first column is the user name, the second is the product identifier, and the third is the user’s rating. Thus, we need a csv file with the following contents:
alex,1,5.0
alex,2,3.0
alex,5,4.0
ivan,1,4.0
ivan,6,1.0
ivan,8,2.0
ivan,9,3.0
bob,2,5.0
bob,3,5.0
david,3,4.0
david,4,3.0
david,6,2.0
david,7,1.0
To get started, we’ll develop a function that reads the above csv file. To store recommendations, we will use the standard dict data structure for python: each user is assigned a directory of his ratings of the form “product”: “rating”. The following code will turn out:
import csv
def ReadFile (filename = ""):
f = open (filename)
r = csv.reader (f)
mentions = dict()
for line in r:
user = line[0]
product = line[1]
rate = float(line[2])
if not user in mentions:
mentions[user] = dict()
mentions[user][product] = rate
f.close()
return mentions
Similarity measure
It is intuitively clear that to recommend a product to user # 1, you need to choose from products that some 2-3-4-etc. Users like, which are most similar in their ratings to user # 1. How to get a numerical expression of this "similarity" of users? Let's say we have M products. The ratings set by an individual user are a vector in the M-dimensional space of products, and we can compare vectors. Among the possible measures are the following:
- Cosine measure
- Pearson correlation coefficient
- Euclidean distance
- Tanimoto coefficient
- Manhattan distance, etc.
In more detail, various measures and aspects of their application, I am going to consider in a separate article. In the meantime, suffice it to say that in recommender systems the cosine measure and Tanimoto's correlation coefficient are most often used. Let us consider in more detail the cosine measure, which we are going to implement. The cosine measure for two vectors is the cosine of the angle between them. From the school course of mathematics, we remember that the cosine of the angle between two vectors is their scalar product divided by the length of each of the two vectors: We
implement the calculation of this measure, not forgetting that we have a lot of user ratings presented in the form of a “product” dict : "Rating"
def distCosine (vecA, vecB):
def dotProduct (vecA, vecB):
d = 0.0
for dim in vecA:
if dim in vecB:
d += vecA[dim]*vecB[dim]
return d
return dotProduct (vecA,vecB) / math.sqrt(dotProduct(vecA,vecA)) / math.sqrt(dotProduct(vecB,vecB))
In the implementation, we used the fact that the scalar product of the vector itself gives the square of the length of the vector - this is not the best solution from the point of view of performance, but in our example, the speed is not fundamental.
Collaborative Filtering Algorithm
So, we have a matrix of user preferences and we are able to determine how two users are similar to each other. Now it remains to implement the collaborative filtering algorithm, which consists in the following:
- Select L users whose tastes are most similar to the tastes of the one in question. To do this, for each of the users it is necessary to calculate the selected measure (in our case, cosine) in relation to the user in question, and select the L largest ones. For Ivan, from the table above, we get the following values:

- For each of the users, multiply his ratings by the calculated measure value, so the ratings of more “similar” users will have a stronger effect on the final position of the product, which can be seen in the table in the illustration below
- For each product, calculate the sum of the calibrated estimates of L of the closest users, divide the resulting amount by the sum of measures L of the selected users. The sum is shown in the illustration in the “sum” line, the final value in the “result” line.
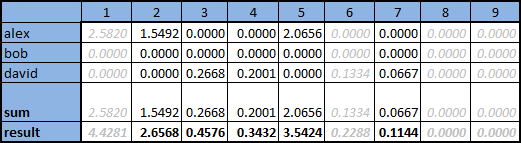
Gray indicates the columns of products that have already been evaluated by the user in question and re-offer them to him does not make sense
In the form of a formula, this algorithm can be represented as
where the function sim is the measure of similarity of two users that we have chosen, U is the set of users, r is the assigned grade, k is the normalization coefficient:
Now it remains only to write the corresponding code
import math
def makeRecommendation (userID, userRates, nBestUsers, nBestProducts):
matches = [(u, distCosine(userRates[userID], userRates[u])) for u in userRates if u <> userID]
bestMatches = sorted(matches, key=lambda(x,y):(y,x), reverse=True)[:nBestUsers]
print "Most correlated with '%s' users:" % userID
for line in bestMatches:
print " UserID: %6s Coeff: %6.4f" % (line[0], line[1])
sim = dict()
sim_all = sum([x[1] for x in bestMatches])
bestMatches = dict([x for x in bestMatches if x[1] > 0.0])
for relatedUser in bestMatches:
for product in userRates[relatedUser]:
if not product in userRates[userID]:
if not product in sim:
sim[product] = 0.0
sim[product] += userRates[relatedUser][product] * bestMatches[relatedUser]
for product in sim:
sim[product] /= sim_all
bestProducts = sorted(sim.iteritems(), key=lambda(x,y):(y,x), reverse=True)[:nBestProducts]
print "Most correlated products:"
for prodInfo in bestProducts:
print " ProductID: %6s CorrelationCoeff: %6.4f" % (prodInfo[0], prodInfo[1])
return [(x[0], x[1]) for x in bestProducts]
To check its health, you can run the following command:
rec = makeRecommendation ('ivan', ReadFile(), 5, 5)
Which will result in the following result:
Conclusion
We looked at an example and implemented one of the simplest options for collaborative filtering using a cosine similarity measure. It is important to understand that there are other approaches to collaborative filtering, other formulas for calculating product ratings, other measures of similarity ( article , section “See also”). Further development of this idea can be carried out in the following areas:
- Optimization of used data structures . When storing data in python as a dict, each time a particular value is accessed, a hash is calculated and the situation becomes worse the longer the name string. In practical tasks, sparse matrices can be used to store data , and instead of text user names and product names, use numerical identifiers (number all users and all products)
- Performance optimization . Obviously, calculating the recommendation for each user contact is extremely costly. There are several workarounds for this problem:
- Clustering users and calculating measures of similarity only between users belonging to the same cluster
- Calculation of product-product similarity factors. To do this, you need to transpose the use-product matrix (you get the product-user matrix), after which for each of the products calculate the set of the most similar products using the same cosine measure and remembering the k closest ones. This is a rather time-consuming process, so it can be done once every M hours / days. But now we have a list of products similar to this one, and multiplying user ratings by the value of the product similarity measure, we get a recommendation for O (N * k) , where N is the number of user ratings
- Selection of measures of similarity . The cosine measure is one of the most commonly used, but the choice of measure should be made only according to the results of analysis of the system data
- Modification of the filtering algorithm . Perhaps another filtering algorithm will give more accurate recommendations in a particular system. Again, a comparison of various algorithms can only be done when applied to a specific system