QUIC, TLS 1.3, DNS-over-HTTPS, then everywhere
Habr, hello! This is a transcription of the report of Artem ximaera Gavrichenkov, read by him at BackendConf 2018 as part of the last RIT ++ festival.

- Hello!
The title of the report contains a long list of protocols, we will go over it gradually, but let's start with what is not in the title.
This is (under the cut) the title of one of the blogs, on the Internet you could see such titles very much. In that post it is written that HTTP / 2 is not some distant future, it is our present; This is a modern protocol developed by Google and hundreds of professionals from many advanced companies, released by the IETF as an RFC back in 2015, that is, 3 years ago.
IETF standards are perceived by the industry as concrete documents such as gravestones, in fact.

It is planned that they determine the development of the Internet and take into account all possible usage scenarios. That is, if we had an old version of the protocol, and then a new one appeared, then it definitely maintains compatibility with all previous versions and additionally solves a lot of problems, optimizes work, and so on.
HTTP / 2 had to be adapted for an advanced web, ready for use in modern services and applications, in fact to be a drop-in replacement for older versions of the HTTP protocol. It was supposed to improve the performance of the site, while simultaneously reducing the load on the backend.

Even SEO-Schnick said they need HTTP / 2.

And, it seemed, it was very easy to support him. In particular, Neil Craig from the BBC wrote on his blog that it’s enough to “just turn it on” on the server. You can also find a lot of presentations, where it is written that HTTP / 2 is included as follows: if you have Nginx, you can correct the configuration in one place; if there is no HTTPS, you need to additionally put a certificate; but, in principle, this is a question of one token in the configuration file.
And, naturally, after you register this token, you immediately begin to receive bonuses from improved performance, new available features, capabilities - in general, everything becomes wonderful.

Links from the slide:
1. medium.com/@DarkDrag0nite/how-http-2-reduces-server-cpu-and-bandwidth-10dbb8458feb
2.www.cloudflare.com/website-optimization/http2
Further history is based on real events. The company has some online service that processes about 500-1000 HTTP requests per second. This service is under Cloudflare DDoS protection.
There are many benchmarks that confirm that switching to HTTP / 2 reduces the load on the server due to the fact that when switching to HTTP / 2, the browser establishes not seven connections, but the plan is one. It was expected that when switching to HTTP / 2 and the memory used will be less, and the processor will be less loaded.
Plus, on the Cloudflare blog and on the Cloudflare site, it’s proposed to enable HTTP / 2 with just one click. Question: Why not do this?

On February 1, 2018, the company includes HTTP / 2 with this same button in Cloudflare, and on the local Nginx also includes it. Month data is collected. On March 1, the consumed resources are measured, and then sysops look at the number of requests in the logs that come in via HTTP / 2 to the server behind Cloudflare. The next slide will be the percentage of requests that came to the server via HTTP / 2. Raise your hands, who knows what this percentage will be?
[From the audience: “1-2%!”]

- Zero. For what reason?
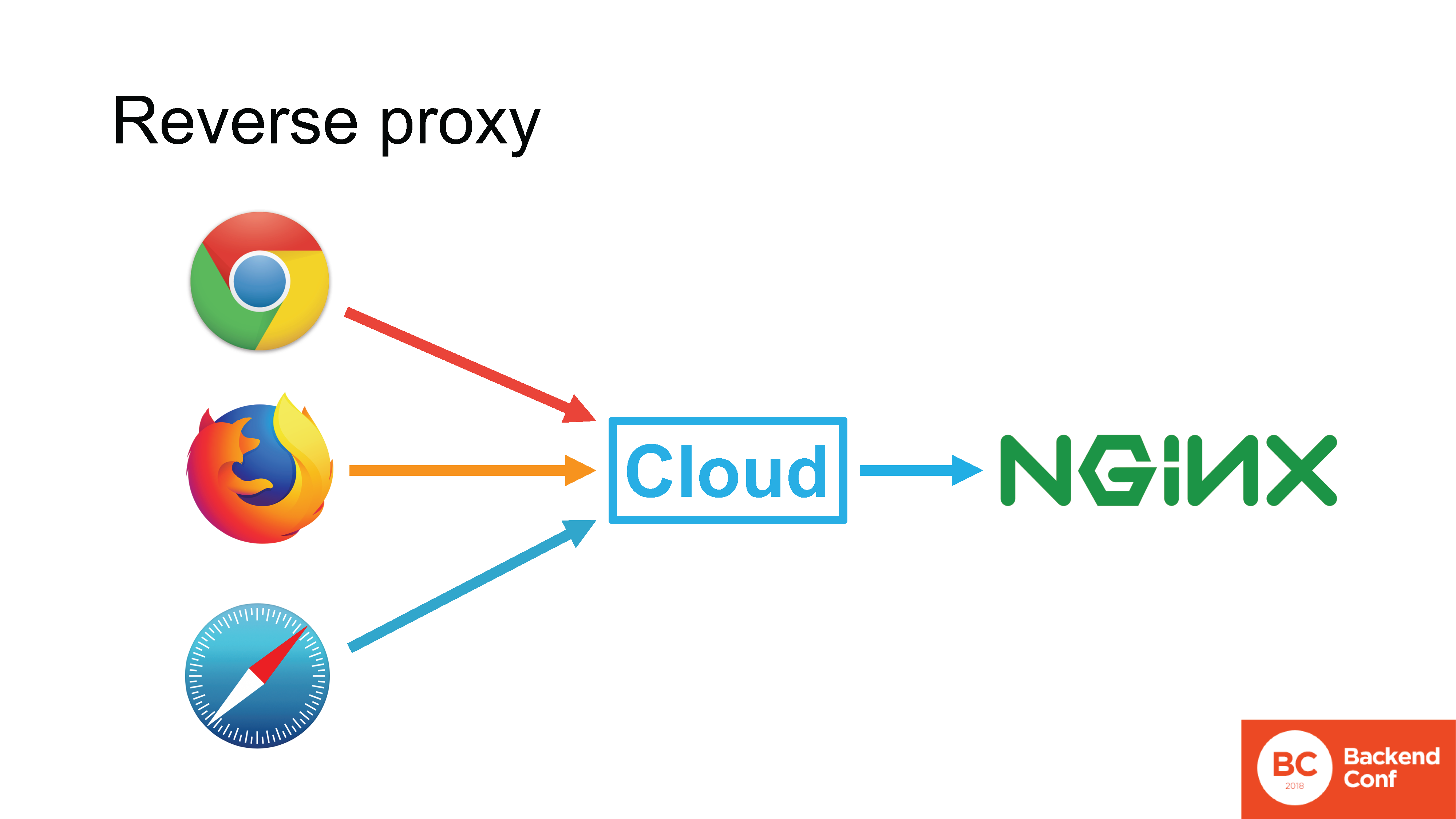
Cloudflare, as well as other attack protection services, MSSP and cloud services, work in reverse proxy mode.. If in a normal situation the browser directly connects to your Nginx, that is, the connection goes directly from the browser to your HTTP server, then you can use the protocol that the browser supports.
If there is a cloud between the browser and your server, the incoming TCP connection is terminated in the cloud, TLS is also terminated there, and the HTTP request first hits the cloud, then the cloud actually processes this request.
The cloud has its own HTTP server, in most cases the same Nginx, in rare cases it is a “self-written” server. This server parses the request, somehow processes it, consults with the caches and, ultimately, forms a new request and sends it to your server using the protocol it supports.
All existing clouds claiming HTTP / 2 support support HTTP / 2 on the side facing the browser. But do not support him on the side looking to you.
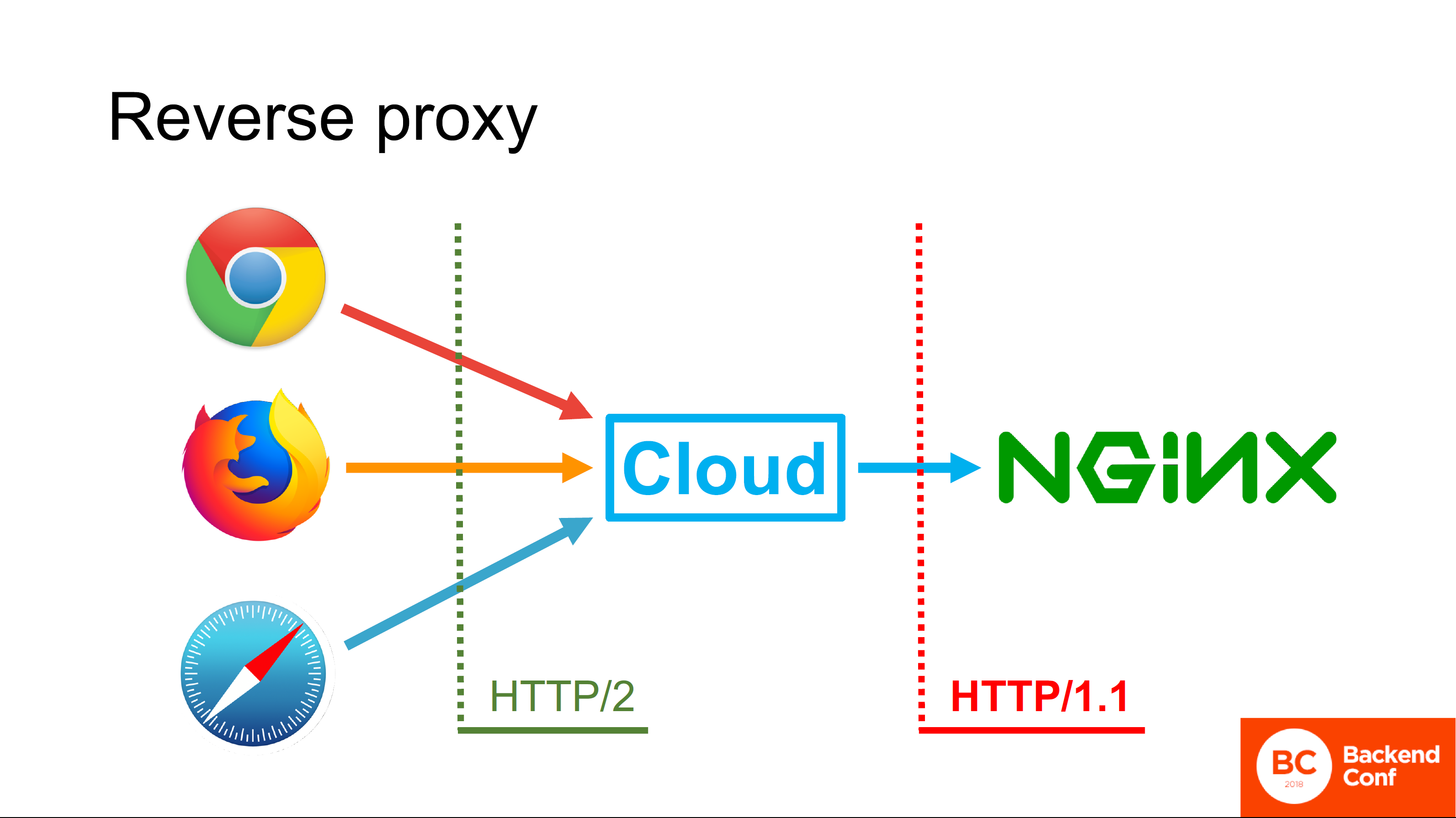
Why?
A simple and not entirely correct answer: "Because in most cases they have Nginx deployed, and Nginx does not know how to go over HTTP / 2 to upstream." Okay, well, this answer is correct , but not complete .

Engineers of Cloudflare give us the full answer. The fact is that the focus of the HTTP / 2 specification, written and released in 2015, was to increase browser performance on specific usage scenarios, for example, for Google.
Google uses its own technologies, does not use reverse proxy in front of its production servers, so no one thought about reverse proxy, which is why HTTP / 2 from the cloud to the upstream is not used. There, in fact, there is little profit, because in reverse proxy mode, from what is described in the HTTP / 2 protocol, for example, Server Push is not supported, because it is not clear how it should work if we have pipelining.
The fact that HTTP / 2 saves connections is cool, but reverse proxy saves them by itself, because it does not open one connection per user. It makes no sense to support HTTP / 2 here, and the overhead and problems associated with this are large.

What is important: reverse proxy is a technology that began to be actively used about 13 years ago. That is, this is the technology of the mid-2000s: I went to school, and it was already used. In the standard, released in 2015, it is not mentioned, is not supported and work on its support, at the moment, in the working group httpbis in the IETF is not conducted.
This is one example of the issues that arise when people begin to implement HTTP / 2. In fact, when you talk to people who have developed and have already had some experience with him, you constantly hear about the same words.

Best of all they were formulated by Maxim Matyukhin from Badoo in a post.on Habré, where he talked about how HTTP / 2 Server Push works. He wrote that he was very surprised by how different the interaction with this particular functionality was with browsers, because he thought that this was a fully developed feature, ready for use in production . I have already heard this phrase regarding HTTP / 2 many times: they thought it was a protocol that “drop-in replacement” —that is, turn it on, and everything is fine — why is it so difficult in practice, where all these problems come from and flaws?
Let's see.
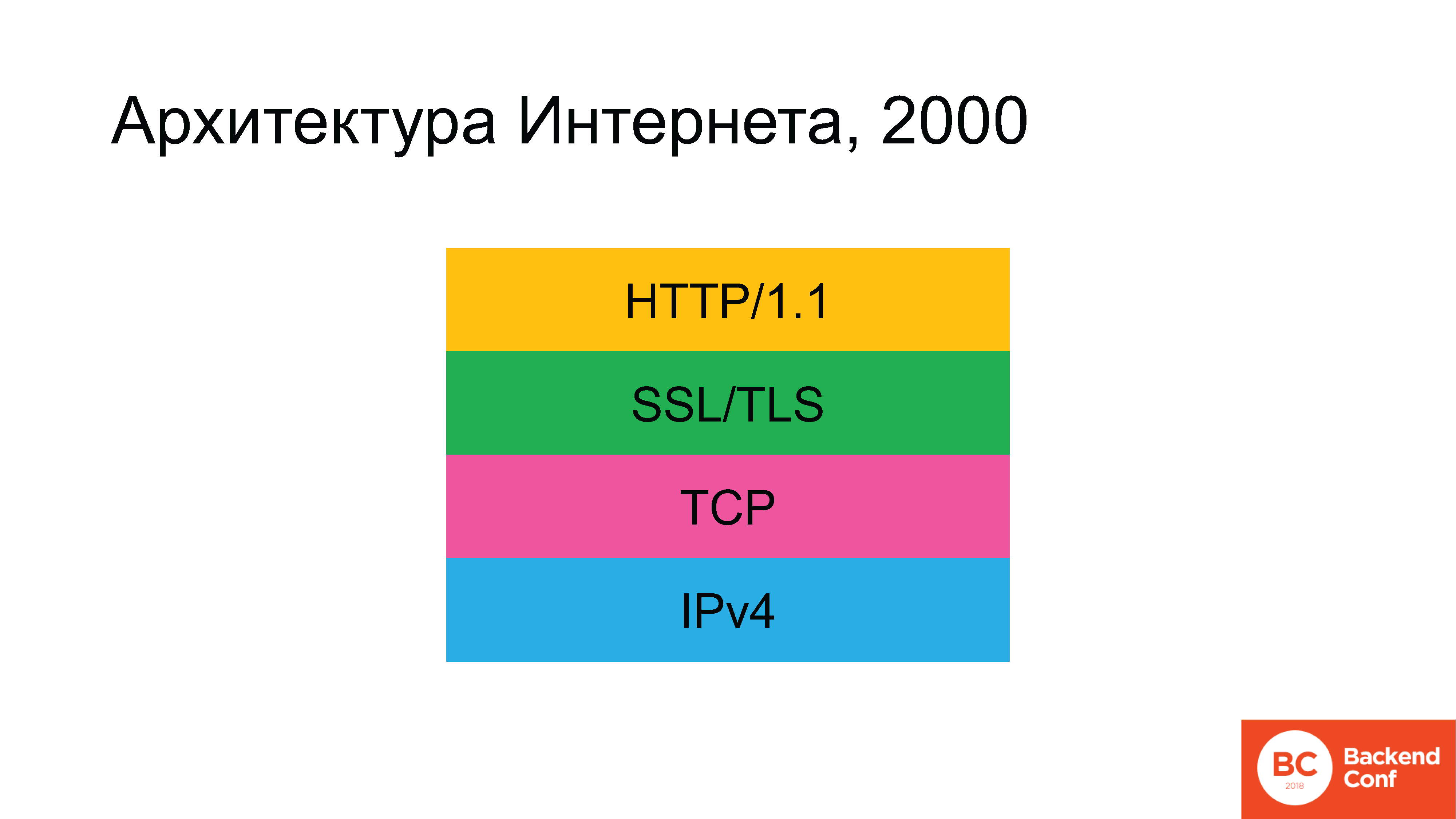
Historically, in ancient times, the architecture of the Internet looked something like this. At some point there was no green rectangle, but then it appeared.
The following protocols were used: since we are talking about the Internet, and not about the local network, then at the lower level we start with the IPv4 protocol. Above it, TCP - or UDP was used, but for 90% of cases (since 80-90% of traffic on the Internet is Web), then TCP was then - then SSL (which was later replaced with TLS), and the hypertext protocol HTTP was already above . Gradually, the situation developed that, according to the plan, by 2020, the architecture of the Internet was to change radically.

IPv6 protocol with us for a long time. TLS recently updated, we will discuss how it happened. And the HTTP / 2 protocol has also been updated.
The wonderful Russian science fiction writer Vadim Panov had such a beautiful phrase in the “Enclave” cycle: “You were waiting for the future. Did you want a future? It has come. You did not want him? It still came. ” The only thing that remained virtually untouched - as of a couple of years ago - is the TCP protocol.
People who are engaged in the design of the Internet, could not pass by such a blatant injustice and decided to throw out the TCP protocol, too.
Well, this is of course a joke. The problem is not just that the protocol is too old. There are flaws in the TCP protocol. Especially many were worried that the HTTP / 2 protocol was already written, the 2015 standard is already being implemented, but specifically with TCP it does not always work well, and it would be nice to put some other transport under it that is more suitable for something that once called SPDY, when those conversations went, and then for HTTP / 2.

The protocol decided to call QUIC. QUIC is the current transport protocol under development. It is based on UDP, that is, it is a datagram protocol. The first draft of the standard was released in July 2016, and the current version of the draft ...
[The speaker checks mail on the phone]
- ... yes, still the 12th.
At the moment, QUIC is not yet a standard - it is being actively written. If I’m not mistaken - I didn’t write on the slide because I was afraid to make a mistake - but IETF 101 in London said that it was planned to be released as a final document sometime by November 2018. It is the QUIC standard itself, because there are eight more documents in the working group .

That is, there is no standard yet, but an active hyip is already underway. I listed only those conferences where I was in the last six months, where there was at least one presentation about QUIC. About “how cool it is”, “how we need to switch to it”, “what operators should do”, “stop filtering UDP - now QUIC will work through it”. All this HYIP has been going on for quite some time - I have already seen many articles that called on the gaming industry to switch to QUIC instead of regular UDP.

Links from the slide:
1. conferences.sigcomm.org/imc/2017/papers/imc17-final39.pdf
2. blog.apnic.net/2018/01/29/measuring-quic-vs-tcp-mobile-desktop
In November 2017, the following link appears on the QUIC working group mailing list: the top one is on whitepaper, and the bottom one is for those who are hard to read whitepaper - this is a link to the APNIC blog with brief content.
The researchers decided to compare the performance of TCP and QUIC in its current form. For comparison, in order not to figure out who is to blame and where Windows might be blamed, from the client’s side took Chrome under Ubuntu, and also took 2 mobile devices: some kind of Nexus and some kind of Samsung . Nexus 6 and MotoG) with Android 4 and 6 versions, and they also launched Chrome.
From the server side, they installed Apache in order to see how the TCP server works, and in order to track QUIC, they tore out a piece of the open source code that is in the Chromium project. The benchmark results showed that, although QUIC does outperform TCP in all greenhouse conditions, there are some corner cases in which it loses.

For example, Google's QUIC implementation works much worse than TCP if packet reordering occurs on the network, that is, the packets arrive in the wrong order in which they were sent by the server. In 2017-2018, in the age of mobile and wireless networks, there is no guarantee whatsoever that the package will fly in principle, let alone in what order. QUIC works fine on a wired network, but who uses the wired network now?

In general, the developers of this code in Google, apparently, do not like mobile phones.
QUIC is a protocol that is implemented on top of UDP in the user space. And on mobile devices as well in user space. According to the measurement results, in a normal situation, that is, when working through a wireless network, the implementation of the QUIC protocol spends 58% of the time in Android in the “Application Limited” state. What is this condition? This is the state when we have sent some data and are waiting for confirmation. For comparison, the desktop was a figure of about 7%.
Only 2 use cases: the first is a wireless network, the second is a mobile device; and QUIC works either as TCP, or significantly worse. Naturally, this turned out to be on the QUIC IETF working group and, of course, Google responded to this. The Google response was as follows:

mailarchive.ietf.org/arch/msg/quic/QktVML_qNDfqjIGirj4t5D0JRGE
Well, we laughed, but in fact this is absolutely logical.
Why? Because the QUIC design - although we are already talking about implementation in production, but - in fact, the wildest experiment.
Here, for example, the seven-tier ISO / OSI model. Who remembers her here? Remember levels: physical, channel, network, transport, some kind of nonsense, some kind of nonsense and applied, right?
Yes, it was developed a very long time ago, and somehow we lived with this level model. QUIC is an experiment to eliminate the level system of the network itself. It combines encryption, transport, reliable data delivery. All this is not in a layered structure, but in a combine, where each component has access to the API of other components.

Quoting one of the designersChristian Guitema's QUIC protocol: "One of the main advantages of QUIC from an architectural point of view is the absence of a layered structure." We have both acknowledgment, and flow control, and encryption, and all cryptography - all this is completely in one transport, and our transport innovations imply access to all of this directly to the network API, so we do not want a layered architecture in QUIC.

The discussion in the working group about this was due to the fact that at the beginning of March another QUIC protocol designer, namely Eric Reskorla, decided to propose for discussion an option in which all encryption is removed from QUIC, in general. Only the transport function that runs on top of the DTLS remains. DTLS, in turn, is TLS over UDP, in total it turns out: QUIC over TLS over UDP.
Where did this proposal come from? By the way, Reskorla wrote a large document, but not at all to make it a standard - it was a subject for discussion, because in the process of designing the QUIC architecture, in the process of testing interoperability and implementation, many problems arose. Mainly related to "stream 0".
What is stream 0 in QUIC? This is the same idea as in HTTP / 2: we have one connection, inside it we have several multiplexed streams. By QUIC design, I recall that encryption is provided by the same protocol. This was done in the following way: the “magic” stream number 0 is opened, which is responsible for setting up the connection, handshake and encryption, after which this stream 0 is encrypted and all others are encrypted too. There were a lot of problems with this, they are listed on the mailing list, there are 10 points, I will not dwell on each one. I will highlight only one that I really like.

www.ietf.org/mail-archive/web/quic/current/msg03498.html
The problem with flow 0, one of them, is that if we lose packets, we need to resend them. And at the same time, for example, on the server side the connection may already be marked as encrypted, and the lost packet belongs to the time when it was unencrypted. In this case, when re-sending, the implementation may accidentally encrypt the packets.
Once again:

Randomly encrypt packets.
It is quite difficult to comment, in addition, to tell how all this is actually designed. In the development of QUIC, an ersatz-agile approach is actually used. That is, it’s not that someone writes a reinforced concrete standard, which can be officially released after a couple of iterations. Not.

The work is as follows:
1. A draft standard is launched, for example, number 5;
2. On the mailing lists, as well as at IETF-meetings - three pieces a year - there is a discussion, then implementation, interop testing takes place on the hackathons, feedback is collected;
3. Google introduces some of the changes in Chrome, in its own infrastructure, analyzes the consequences and then the counter is incremented and the standard appears 6.
Now, I remind you, version 12.
Note Ed .: as of July 10, 2018 is already the 13th.
What is important here?
Firstly, the minuses we have just seen, but there are also pluses. In this process, in fact, you can participate. Feedback is collected from all parties involved: if you are involved in gaming, if you think that you in the gaming industry can simply take and change UDP, put QUIC in its place, and everything will work - no, it won't. But at the moment you can influence this, you can somehow work with it.

And this is, in fact, a common story. Feedback from you is expected, everyone wants to see it.
Google is developing a protocol, putting some ideas into it - for its own purposes. Companies that do other things (if they are not quite typical Web, gaming or mobile applications, SEO is the same), they cannot by default expect that the protocol will take into account their interests: not only because nobody cares, but because no one simply knows about these interests.
This is, by the way, a surrender. Of course, the question to me is why we, like Qrator Labs , in particular, did not participate in the development of the HTTP / 2 protocol and did not tell anyone about reverse proxy. But the same Cloudflare and Nginx did not participate there either.
While the industry is not involved in this, Google, Facebook, some other companies and academics are engaged in the development.. So that you know, in the near-IETF'noy crowd, the word “academician” is, so to speak, not commendable. It sounds like the epithets "schizophrenic" and "hypochondriac". People often come without any practical goals, without understanding real-world problems, but they fit in there because it’s easier to work out a doctoral thesis.
In this all, of course, you need to participate and there are no other options.

Returning to QUIC: so, the protocol is implemented in the user space, on mobile devices there is ... Blah blah. "Implemented in user space". Let's talk about it.
How did we arrange transportation at all before we started to invent QUIC? How does it work now in production? There is a TCP protocol, if we are talking about the Web.
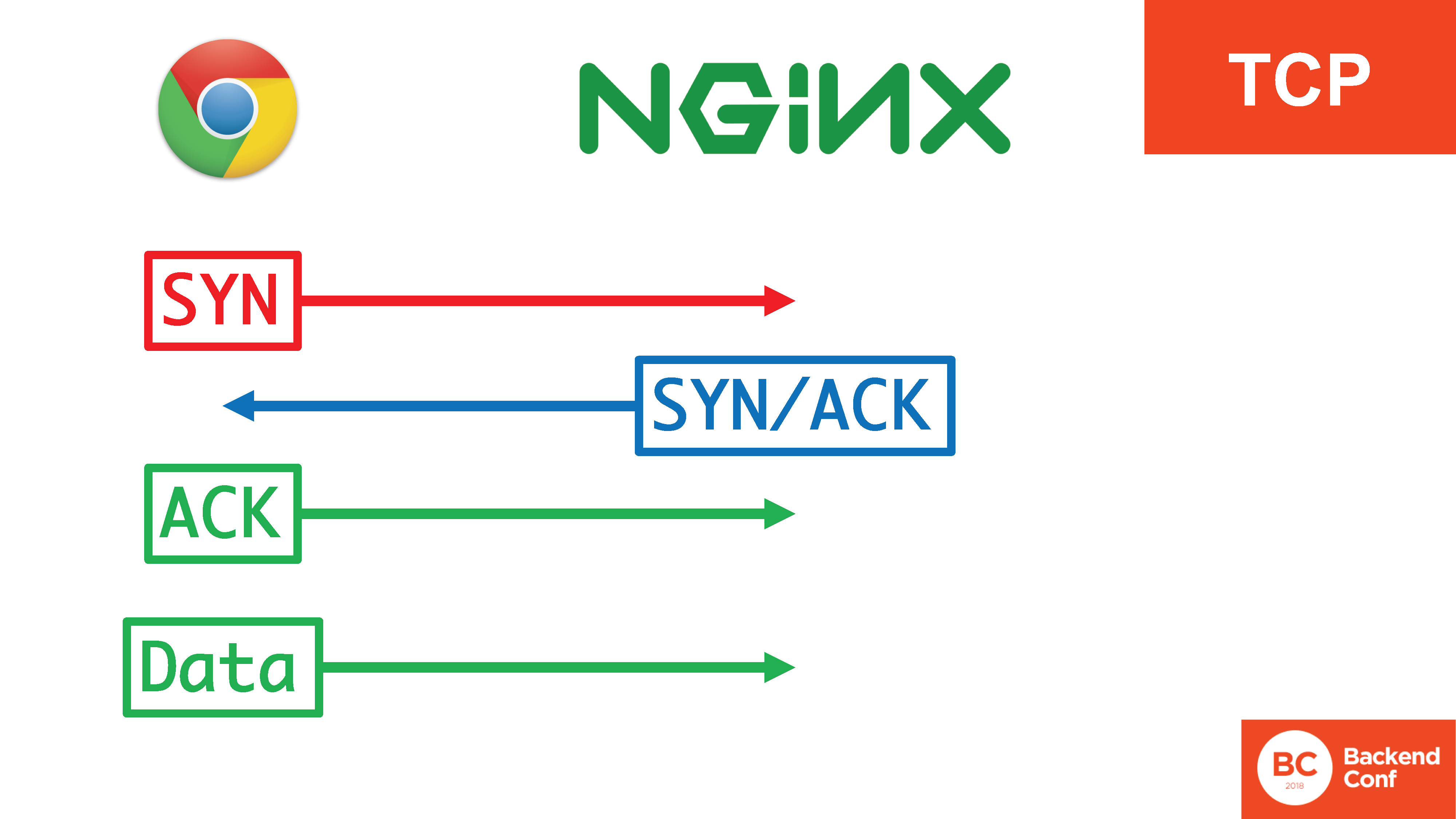
There is a triple handshake in TCP protocol.: SYN, SYN / ACK, ACK. It is necessary for a number of things: in order to prevent the server from being used to attack others, to more successfully filter certain attacks on the TCP protocol, such as a SYN flood . Only after the 3 segments of the triple handshake have passed, we begin sending data.
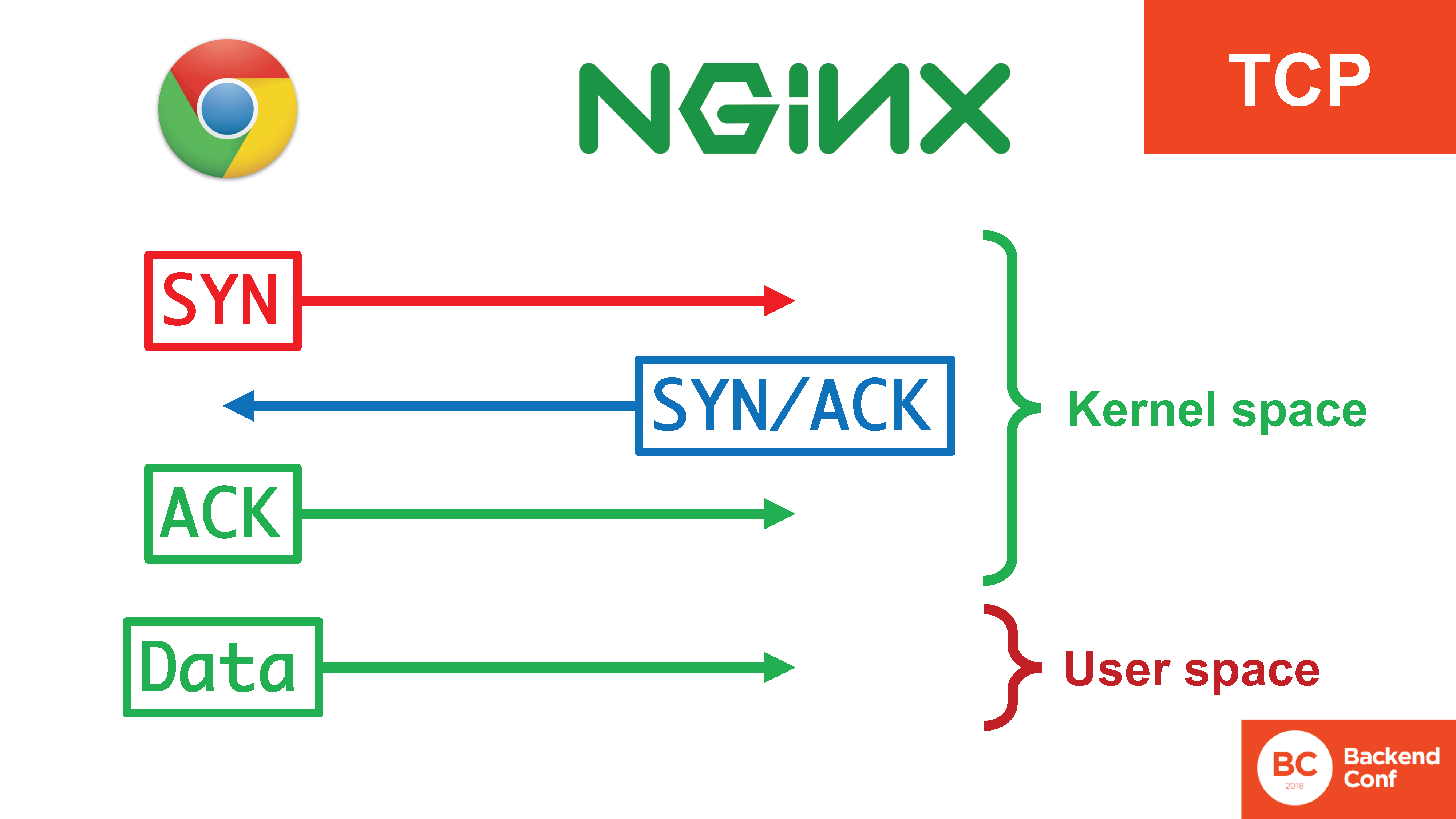
In this case, there are 4 actions, 3 of which occur in the kernel, they occur quite effectively, and the data already gets into the user space when the connection is established.
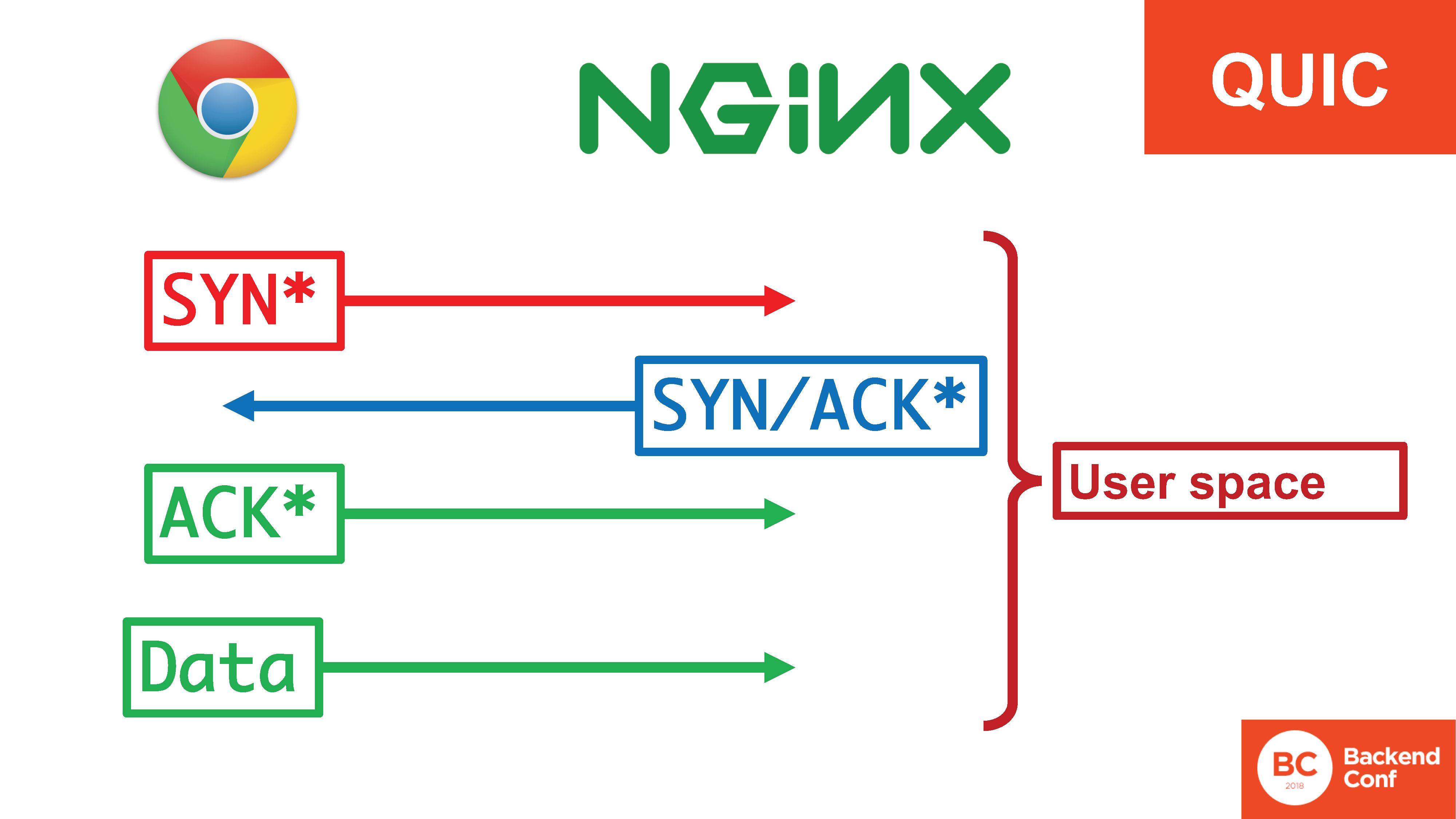
In the situation with QUIC, all this happiness is in userspace. There is an asterisk here, because the terminology is not quite “SYN, SYN / ACK”, but, in fact, this is the same handheld, just moved completely into user space. If flies 20 Gbit / s flooding and earlier in TCP they could be processed in the SYN-cores kernel, now they need to be processed in the user space, as they fly through the entire core and through all context switches. And there they need to somehow support.
Why is it done like this? Why is QUIC a user space protocol? Although the transport seems to be the place for him somewhere at the system level.

Because, again, this is the interest of Google and other members of the working group. They want to see the new protocol implemented, they do not want to wait until all the operating systems in the district are updated. If it is implemented in the user space, it can be used (in particular, in the browser, but not only) now.
The fact that you need to spend a lot of resources on the server side is not a problem for Google. Somewhere there was a good saying that to solve most of the performance problems on the backend of the modern Internet, you just need to confiscate half of the servers from Google (and preferably three quarters). What is not without some common sense, because Google, in fact, is not exchanged for such trifles.

www.ietf.org/mail-archive/web/quic/current/msg03736.html
On the screen, there is a literal quote from the QUIC mailing, where the discussion was just about the fact that the protocol is planned to be implemented in user space. This is a literal quote: “We want to deploy QUIC on any machine without the support of the operating system. If anyone has a performance problem, they will take it all to the core. ” QUIC is already so spreading that it’s already scary to carry it into the kernel with encryption and everything else, but the working group on this topic is also not particularly worn out.

And why this approach is used on the client side - I can understand. But the same approach is used on the server side. Theoretically, in this case, QUIC would really be worth taking to the core, but, again, work is not being done on it, and when it is finished, we will be gray at best, and I do not plan to live forever. And when this happens is not very clear.
Speaking of the Linux kernel, one can not fail to mention that one of the main meanings of QUIC was that it was implemented on top of the lightweight UDP protocol, and because of this, it works more efficiently, more quickly ... and why do we need TCP, so big and cumbersome.

vger.kernel.org/netconf2017_files/rx_hardening_and_udp_gso.pdf
Here is another reference to the benchmark. It turns out that sending a UDP datagram in Linux is more expensive than sending a TCP stream, and much more expensive, much more expensive. There are 2 main points (that is, many moments, but only two):
1. Searching the routing table takes longer in the case of a UDP datagram;
2. A piece called “large segment offload”. In TCP, we can simply download a large data stream into transmission, we don’t have to split it into segments on the CPU, while in UDP we need to prepare each datagram, we don’t have a stream. At the moment, kernel developers are thinking about what to do with it, but, by and large, at the moment, TCP is working on sending big data that does not fit in one packet, more efficiently than UDP, on which QUIC is based.

www.ietf.org/mail-archive/web/quic/current/msg03720.html
This is again a quote from an employee of Google, in particular, I also asked him this question. After all, we can just try to blame Linux, say that under Windows, maybe not so bad, but no. It is argued that on any platform on which Google deploys QUIC, there is a problem with the increased cost (from the point of view of the central processor) of sending a UDP packet against the TCP stream. That is, this is not just a Linux one, but this is a general approach.

Which leads us to one simple thought.
Stop talking about QUIC. Enough. A simple idea to get out of here is that before introducing any new protocol instead of the old one: HTTP / 2 against HTTP / 1.1, QUIC instead of TCP, DNS encryption, IPv6 instead of IPv4 ... the first thing to do before making a decision and displaying on production is naturally benchmarking.
Do not trust anyone who says that the protocol “you can simply change / enable / press a button” - no ! There will never be such a thing - and there has never been, and never will be in the future, and no one guarantees such
Therefore, only a benchmark, and, of course, that if you do not do it, but simply deploy something, then, of course, no one will provide you with a guarantee of quality work.

By the way, about IPv6. The fact is that in the days of IPv6, when it was developed, protocols were developed in a more straightforward way, that is, without agile technology. But their adaptation on the Internet still took a very large substantial time. And, at the moment, it is still ongoing, and still hangs at 10-20% in the case of IPv6. And depending on the country, because in Russia it is even lower.
On the path to implementing IPv6, many problems have been solved. Who knows what “Happy Eyeballs” is? In general, there were a lot of problems related to IPv6, and such when live users complained. Let's say you close the laptop, go out of the house where you have IPv6, come to a cafe where there is no IPv6, open a laptop - nothing works because the browser and operating system caches continue to look into IPv6, but there is no local connectivity .
An approach called “Happy Eyeballs” (also a standard issued by the IETF) was invented : if within 0.3 seconds we did not find IPv6 connectivity, we could not connect, we roll back to IPv4.
Crutch, but almost always works, it seems, but! Constantly having mystical problems with implementation. In particular, for some reason, one of the most popular problems for some reason was with the iPad, which switched from IPv6 to IPv4 and back significantly slower than 0.3 seconds: about 1 second - or even 1 minute.
Even at some point, an insane offer appeared on the IETF 99 in Prague: “let us have a Happy Eyeballs syslog on a centralized server on every network, if there are problems, send something”. Collect syslog from all connected devices - no one, of course, did not agree. But this is an indication that a lot of problems.
Other problems are the fight against all sorts of malicious activities, because the local network in IPv6 is / 64 and there are a lot of addresses that an attacker can begin to sort through, the defense needs to be aggregated in time, and so on. This needs to be dealt with somehow, all this must be realized.
As a result, we still got implementation problems, which are not only expressed in the fact that someone is slowly introducing IPv6. No, it began to turn off back. Go back to IPv4. Because even without problems it was difficult for the management to justify the benefits of the transition, but if, after switching on, users began to complain, everything was right away. This is such an example, when even the protocol that was developed with a view to the implementation still causes the wildest problems with the implementation, which are expressed in the head of the technical department.
Imagine what will happen when implementing protocols that were not designed for large-scale implementation in appropriate use cases.
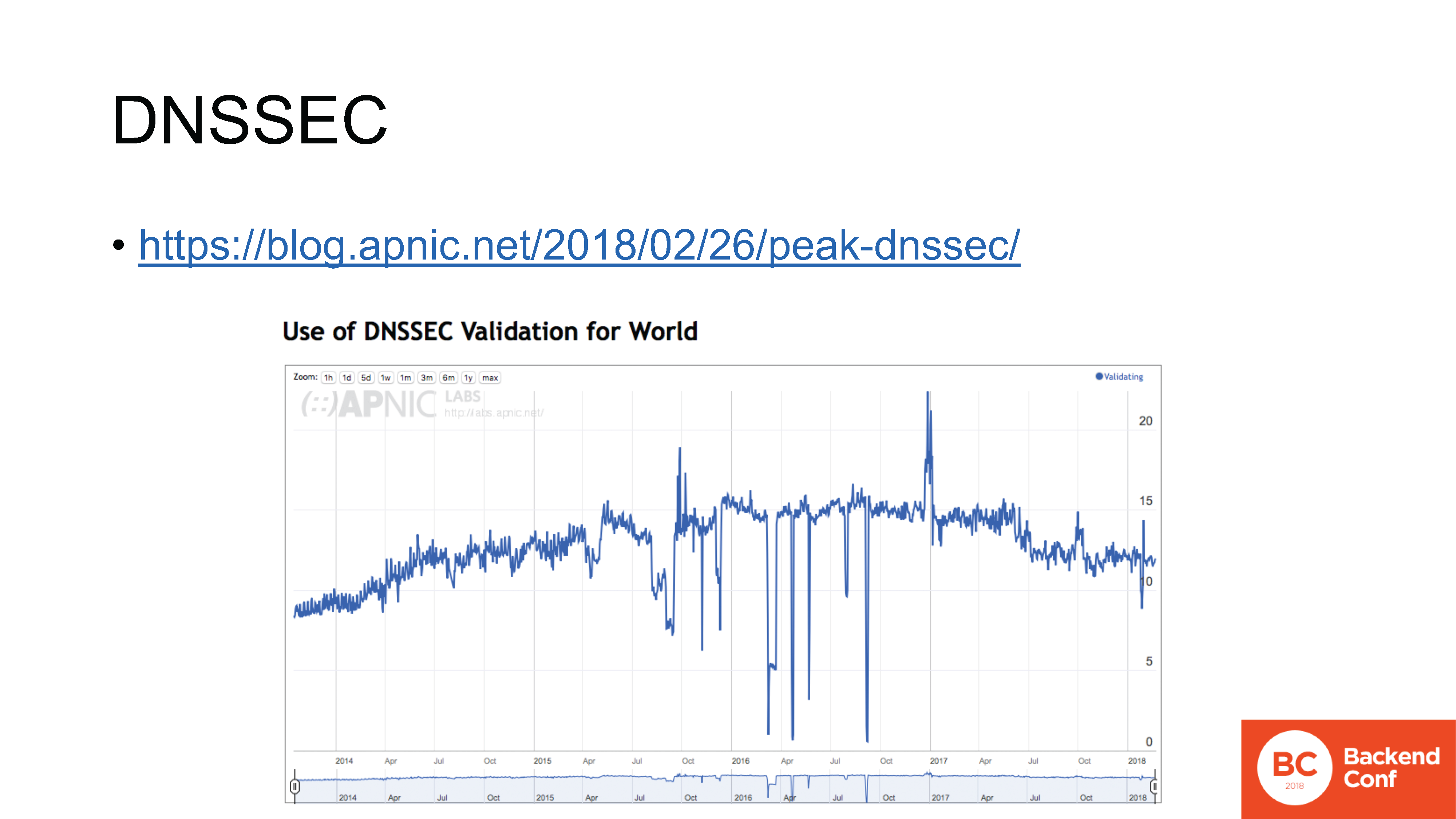
blog.apnic.net/2018/02/26/peak-dnssec
Another example on this topic is DNSSEC. I will not ask you to raise your hands to find out who has it, because I know that nobody has it.
Deployment of IPv6, on the one hand, is developing, on the other hand, there are problems with it, but at least it is coming. Since the end of last year, the introduction of DNSSEC in the world has slowed and gone in the opposite direction.
In this graph, we see the daily number of Internet users (as measured by APNIC Labs) using resolvers that validate DNSSEC. The bearish trend is very clearly visible here: here it starts after the last peak, and this peak is October 2016.
DNSSEC has a goal, there are correct tasks, but its deployment actually stopped and some reverse process started, and there is still to be investigated. where did this process come from.

datatracker.ietf.org/meeting/101/materials/slides-101-dnsop-sessa-the-dns-camel-01
There are a lot of problems with DNS. In the IETF dnsop working group, there are now 3 chairmen, 15 drafts, as they say, “in flight” : they are preparing for the release as RFC.
DNS, in particular, have learned to transmit on top of everything. Over TCP it worked for a long time (but people still need to show how to do it correctly ). Now they have started it on top of TLS , on top of HTTPS , on top of QUIC .
It all looked absolutely wonderful, until people started to realize it, and they didn’t get sick at the fifth point. In March 2017, OpenDNS developers brought a “DNS Camel” to the IETF presentation.or "camel DNS". The presentation boils down to the following thought: how much more can we load this camel (aka DNS protocol) before another twig breaks its back?
This is a general approach to how we see design now. Features are added, there are a lot of features, they interfere with each other in different ways. And not always in a predictable way, and not always the authors of the implementation understand all possible points of interference. The introduction of each such new feature, implementation, implementation in production adds a set of potential points of failure in each place where such interference occurs. Without benchmark, without monitoring - nowhere.
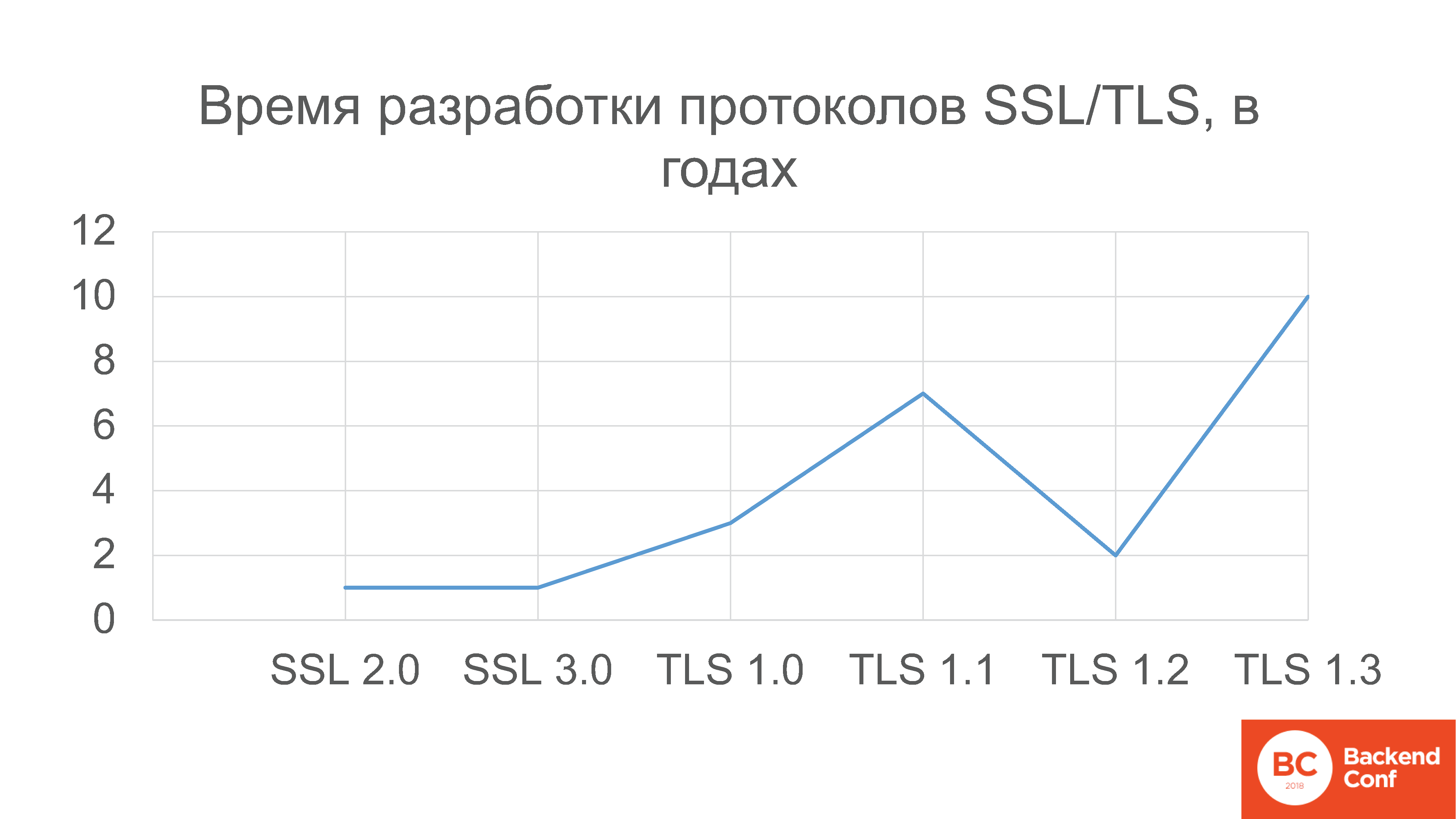
Why is it important to be involved in this whole process? Because the IETF standard - “RFC” - is still a standard. There is such a good statistic: the timing of the development of various versions of SSL and TLS encryption protocols.
Please note that SSL versioning starts with number 2, because versions 0.9 and 1.0 were never released in production, they were more full of holes than Netscape could afford to release. Therefore, the story began with the protocol SSL 2.0, which was developed year. Then SSL 3.0 was developed for another year.
Then TLS 1.0 was developed for 3 years; version 1.1 - 7 years; 1.2 was developed only 2 years, because there were not such big changes; but the latest version, which was released in March of this year - the 27th draft, by the way - was developed 10 years .
In the relevant working group, at a certain point there was a big panic on this topic, because it turned out that TLS 1.3 breaks a lot of use cases, in particular, in financial organizations, with their monitoring and firewalls. But to change this, having come to the realization already at the stage of the eighteenth draft, even such large companies as US Bank could not. They didn’t have anything to do with it, because when you come to the party at the moment when everyone is already giving away the bill, you cannot expect that your offer to continue the fun will be treated with understanding .
Therefore, if in some protocol it is again a question for feedback, there are / will / appear features that do not suit you, the only option is to track it in time and intervene in time, because otherwise it will be released and have to build crutches around it.

Here on the slide, in fact, the three main conclusions from the whole process.
First, as I said, the introduction of a new protocol is not just in the “tweak something” configuration. This is a planned implementation plan, an assessment of expediency with mandatory benchmarks, as in reality it will all behave.
Point number two: protocols are not developed by aliens, they are not given to us from above, you can and should participate in this process, because no one will be able to promote your use cases.
And third, really: feedback is needed . The most important thing is that Google is not evil, it just pursues its own goals, it has no task to develop a protocol for you and for you, only you can do it.
Therefore, in the general case, the introduction of something new in return for something old, despite the number of laudatory articles on blogs, begins with the fact that it is necessary to invest not just in deployment, but in the protocol design process, see how it works, and only after that make an informed decision.
Thank!