Uppercase and lowercase letters
I have gathered here some not very obvious facts about upper and lower case letters that a programmer may encounter in his work. Many of you translated strings into “all uppercase”, “all lowercase” (lowercase), “first uppercase, and the rest lowercase” (titlecase). Case-insensitive comparison operation is even more popular. On a global scale, such operations can be quite nontrivial. The post was built in the form of a "collection of misconceptions" with counterexamples.
Not. In the text, lowercase ligatures may appear that do not correspond to one character in upper case. For example, when transferring to uppercase: fi (U + FB00) -> FI (U + 0046, U + 0049)
Not. Some letters with diacritics do not have an exact match in another case, so you have to use a combined character. Let's say in Afrikaans there is a letter ʼn (U + 0149). In upper case, it corresponds to a combination of two characters: (U + 02BC, U + 004E). If you will fall transliteration of the Arabic text, you can be faced with
(U + 02BC, U + 004E). If you will fall transliteration of the Arabic text, you can be faced with  (U + 1E96), which is in upper case and no single-character matching, so you have to replace
(U + 1E96), which is in upper case and no single-character matching, so you have to replace  (U + 0048, U + 0331). The Wakhi Language is a letter
(U + 0048, U + 0331). The Wakhi Language is a letter  (U + 01F0) with a similar problem. You may argue that this is exotic, but there are 23,000 articles on Afrikaans on Wikipedia.
(U + 01F0) with a similar problem. You may argue that this is exotic, but there are 23,000 articles on Afrikaans on Wikipedia.
Not. There is, for example, in German the letter “escet” ß (U + 00DF). When converted to uppercase, it turns into two characters SS (U + 0053, U + 0053).
Not. There are specific Greek letters, for example,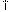 (U + 0390), which turn into three Unicode characters
(U + 0390), which turn into three Unicode characters  (U + 0399, U + 0308, U + 0301)
(U + 0399, U + 0308, U + 0301)
Not. Recall the same ligatures. If the word in lowercase starts with fl (U + FB02), then in uppercase the ligature will turn into FL (U + 0046, U + 004C), but in titlecase - into Fl (U + 0046, U + 006C). The same with ß, but theoretically words cannot begin with it.
Will not work. There is, for example, the digraph dz (U + 01F3), which can be used in the text in Polish, Slovak, Macedonian or Hungarian. In uppercase, it corresponds to the digraph DZ (U + 01F1), and in titlecase to the digraph Dz (U + 01F2). There are also different digraphs . Greek, on the other hand , will delight you with jokes from hypogrammen and programmen (fortunately, this is rarely found in modern texts). In general, the uppercase and titlecase options for a character can be different; for them, there are separate entries in the Unicode standard.
Not. For example, the Greek capital sigma Σ (U + 03A3) at the end of a word turns into lowercase ς (U + 03C2), and in the middle - σ (U + 03C3).
Not. For example, in most Latin languages, the lowercase version for I (U + 0049) is i (U + 0069), but not in Turkish and Azerbaijani. There, the lowercase version for I is ı (U + 0131), and the uppercase version for i is ı (U + 0130). In Turkey, because of this, enchanting bugs are sometimes observed in various software. And if you come across Lithuanian text with accents, then, for example, the capital letter Ì (U + 00CC), which will turn not into ì (U + 00EC), but into (U + 0069, U + 0307, U + 0300) . In general, the result of the conversion also depends on the language. Most complex cases are described here .
(U + 0069, U + 0307, U + 0300) . In general, the result of the conversion also depends on the language. Most complex cases are described here .
There are also many pitfalls that arise from the above. For example, it will not work with German straße and STRASSE (the first will not change, the second will turn into strasse). There will be problems with many other letters described above.
And this will not always work (albeit much more often). But, say, if you come across the STRA E record (yes, there is a large escet in German and Unicode too ), it will not coincide with straße. For comparisons, letters are converted according to a special Unicode table - CaseFolding , so both ß and SS will turn into ss.
E record (yes, there is a large escet in German and Unicode too ), it will not coincide with straße. For comparisons, letters are converted according to a special Unicode table - CaseFolding , so both ß and SS will turn into ss.
Here I agree.
If someone does not display any characters, write me a personal message, I will replace it with a picture.
1. If I translate the string to uppercase or lowercase, the number of Unicode characters will not change.
Not. In the text, lowercase ligatures may appear that do not correspond to one character in upper case. For example, when transferring to uppercase: fi (U + FB00) -> FI (U + 0046, U + 0049)
2. Ligatures - perversion, nobody uses them. If they are not taken into account, then I am right.
Not. Some letters with diacritics do not have an exact match in another case, so you have to use a combined character. Let's say in Afrikaans there is a letter ʼn (U + 0149). In upper case, it corresponds to a combination of two characters:
(U + 02BC, U + 004E). If you will fall transliteration of the Arabic text, you can be faced with (U + 1E96), which is in upper case and no single-character matching, so you have to replace (U + 0048, U + 0331). The Wakhi Language is a letter (U + 01F0) with a similar problem. You may argue that this is exotic, but there are 23,000 articles on Afrikaans on Wikipedia.3. Well, ok, but let's consider a combined symbol (with modifying or combining code points) as one symbol. Then the length will still be preserved.
Not. There is, for example, in German the letter “escet” ß (U + 00DF). When converted to uppercase, it turns into two characters SS (U + 0053, U + 0053).
4. Okay, okay, I get it. We assume that the number of Unicode characters can increase, but no more than double.
Not. There are specific Greek letters, for example,
(U + 0390), which turn into three Unicode characters (U + 0399, U + 0308, U + 0301)5. Let's talk about titlecase. Everything is simple here: I took the first character from the word, transferred it to uppercase, took all the subsequent ones, transferred it to lowercase.
Not. Recall the same ligatures. If the word in lowercase starts with fl (U + FB02), then in uppercase the ligature will turn into FL (U + 0046, U + 004C), but in titlecase - into Fl (U + 0046, U + 006C). The same with ß, but theoretically words cannot begin with it.
6. Again these ligatures! Well, we take the first character from the word, translate it to uppercase, if it turns out more than one character, then we leave the first one, and the rest back to lowercase. Then it will definitely work.
Will not work. There is, for example, the digraph dz (U + 01F3), which can be used in the text in Polish, Slovak, Macedonian or Hungarian. In uppercase, it corresponds to the digraph DZ (U + 01F1), and in titlecase to the digraph Dz (U + 01F2). There are also different digraphs . Greek, on the other hand , will delight you with jokes from hypogrammen and programmen (fortunately, this is rarely found in modern texts). In general, the uppercase and titlecase options for a character can be different; for them, there are separate entries in the Unicode standard.
7. Good, but at least the result of converting the case of a character to uppercase or lowercase does not depend on its position in the word.
Not. For example, the Greek capital sigma Σ (U + 03A3) at the end of a word turns into lowercase ς (U + 03C2), and in the middle - σ (U + 03C3).
8. Oh, well, we’ll process the Greek sigma separately. But in any case, the same character in the same position in the text is converted equally.
Not. For example, in most Latin languages, the lowercase version for I (U + 0049) is i (U + 0069), but not in Turkish and Azerbaijani. There, the lowercase version for I is ı (U + 0131), and the uppercase version for i is ı (U + 0130). In Turkey, because of this, enchanting bugs are sometimes observed in various software. And if you come across Lithuanian text with accents, then, for example, the capital letter Ì (U + 00CC), which will turn not into ì (U + 00EC), but into
(U + 0069, U + 0307, U + 0300) . In general, the result of the conversion also depends on the language. Most complex cases are described here .9. What a horror! Well, let us now properly convert to uppercase and lowercase. Comparing two words is not case sensitive: translate both into lowercase and compare.
There are also many pitfalls that arise from the above. For example, it will not work with German straße and STRASSE (the first will not change, the second will turn into strasse). There will be problems with many other letters described above.
10. M-yes ... Maybe then everything is in uppercase?
And this will not always work (albeit much more often). But, say, if you come across the STRA
E record (yes, there is a large escet in German and Unicode too ), it will not coincide with straße. For comparisons, letters are converted according to a special Unicode table - CaseFolding , so both ß and SS will turn into ss.11. Ahhh, this is some kind of kapets!
Here I agree.
If someone does not display any characters, write me a personal message, I will replace it with a picture.