Formation of high-level attributes using a large-scale experiment without teacher training
The article Face Detection human brain 19 facts that need to be aware of computer vision researchers mentioned experimental fact that primate brain are neurons selectively respond to the image of the muzzle face (human, monkeys, etc.), and the average delay is about 120 ms From which I made an amateurish conclusion in the commentary that the visual image is processed by direct signal propagation, and the number of layers of the neural network is about 12. I
offer a new experimental confirmation of this fact, published concretely by our beloved Andrew Ng.
The authors conducted a large-scale experiment to build a detector of human faces based on a huge number of images that are not marked in any way. A 9-layer neural network was constructed with the structure of a sparse auto-encoder with local receptive fields. A neural network is implemented on a cluster of 1000 computers, 16 cores in each, and contains 1 billion connections between neurons. To train the network, we used 10 million frames of 200x200 pixels randomly obtained from YouTube videos. Asynchronous gradient descent training took 3 days.
As a result of training on an unmarked sample, without a teacher, contrary to intuition, a neuron was selected in the output layer of the network, which selectively reacts to the presence of a face in the image. Control experiments showed that this classifier is resistant not only to face displacement on the image field, but also to scaling and even to 3D rotation outside the image plane! It turned out that this neural network is capable of learning to recognize a variety of high-level concepts, such as human figures or cats.
The full text of the article, see the link , here I give a brief retelling.
In neuroscience, it is believed that individual neurons can be distinguished in the brain that are selective for certain generalized categories, such as human faces. They are also called "grandmother's neurons."
In artificial neural networks, the standard approach is teaching with a teacher: for example, to construct a classifier of human faces, a set of faces is taken, as well as a set of images that do not contain faces, with each image labeled “face” - “not face”. The need for large, labeled collections of training data is a big technical problem.
In this paper, the authors tried to answer two questions: is it possible to train a neural network to recognize faces from unmarked data, and whether it is possible to experimentally confirm the possibility of self-training of "grandmother neurons" on unmarked data. This, in principle, will confirm the hypothesis that infants are independently trained to group similar images (for example, faces) without the intervention of a teacher.
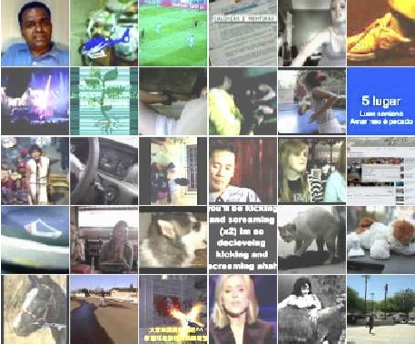
The training set was made by randomly sampling one frame of 10 million YouTube videos. Only one frame was taken from each video to avoid duplicates in the sample. Each frame was scaled to a size of 200x200 pixels (which distinguishes the described experiment from most recognition works that usually operate with 32x32 frames or the like) Here are typical images from the training set:
The basis for the experiment was a sparse auto-encoder ( described on the hub). Early experiments with shallow depth autoencoders made it possible to obtain classifiers of low-level features (segments, borders, etc.) similar to Gabor filters.
The described algorithm uses a multi-layer auto encoder, as well as some important distinguishing features:
Local receptive fields scale the neural network for large images. Pooling frames and localizing contrasts allows for invariance to movement and local deformations.
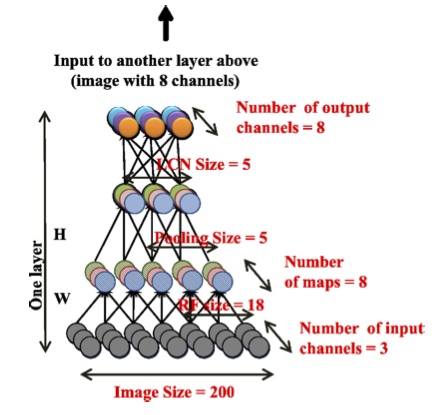
The auto encoder used consists of three repeating layers, in each of which the same sublevels are used: local filtering, local pooling, local normalization of contrasts.
The most important feature of this structure is the local connectivity between neurons. The first sublevel uses receptive fields of 18x18 pixels, and the second sublevel combines 5x5 frames of intersecting neighboring areas. Note that local receptive fields do not use convolution, i.e. the parameters of each recursive field are not repeated, they are unique. This approach is more close to the biological prototype, and also allows you to learn more invariants.
Local normalization of contrast also mimics the processes in the biological optic tract. From the activation of each neuron, the weighted average value of the activation of neighboring neurons (Gaussian weights) is subtracted. Then, normalization is performed according to the local rms value of the activation of neighboring neurons, also Gaussian-weighted.
The objective function when training the network minimizes the value of the error in reproducing the original image with a sparse auto-encoder. Optimization is performed globally for all managed network parameters (over 1 billion parameters) using asynchronous gradient descent (asynchronous SGD). To solve such a large-scale problem, model parallelism was implemented, consisting in the fact that the local weights of the neural network are distributed to various machines. One instance of the model is distributed on 169 computers, with 16 processor cores in each.
To further parallelize the learning process, asynchronous gradient descent using several instances of the model is implemented. In the described experiment, the training sample was divided into 5 portions, and each portion was trained on a separate copy of the model. Models transmit updated parameter values to centralized “parameter servers” (256 servers). In a simplified presentation, before processing a mini-series of 100 training images, the model requests parameters from the parameter servers, learns (updates the parameters) and transfers the parameter gradients to the parameter servers.
Such an asynchronous gradient descent is resistant to failures of individual network nodes.
To conduct this experiment, the DistBelief framework was developed, which solves all communication issues between parallel computers in a cluster, including dispatching requests to parameter servers. The learning process lasted 3 days.
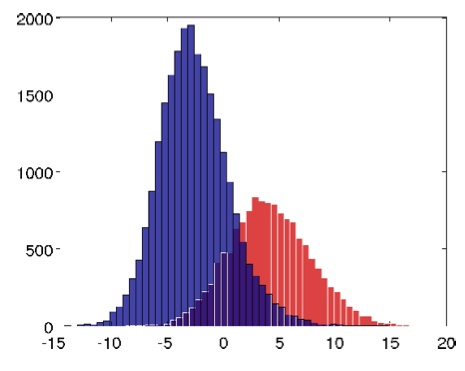
Surprisingly, in the learning process, neurons formed, the best of which showed 81.7% accuracy in facial recognition. The histogram of activation levels (relative to the threshold value of Zero) shows how many images in the test sample caused one or another activation of the “grandmother neuron”. Blue color shows images that do not contain faces (random images), red color shows faces.
In order to confirm that the classifier is trained specifically for face recognition, we visualized the trained network using two methods.
The first method is the selection of test images that caused the greatest activation of the classifier neuron:

The second approach is numerical optimization to obtain the optimal stimulus. Using the gradient descent method, an input pattern was obtained that maximizes the value of the output activation of the classifier for the given parameters of the neural network:

For more detailed quantitative estimates and conclusions about the experimental results, see the original article. On my own, I want to note that a large-scale computational experiment has proved the possibility of self-learning a neural network without a teacher, and the parameters of this network (in particular, the number of layers and interconnects) approximately correspond to biological values.
offer a new experimental confirmation of this fact, published concretely by our beloved Andrew Ng.
The authors conducted a large-scale experiment to build a detector of human faces based on a huge number of images that are not marked in any way. A 9-layer neural network was constructed with the structure of a sparse auto-encoder with local receptive fields. A neural network is implemented on a cluster of 1000 computers, 16 cores in each, and contains 1 billion connections between neurons. To train the network, we used 10 million frames of 200x200 pixels randomly obtained from YouTube videos. Asynchronous gradient descent training took 3 days.
As a result of training on an unmarked sample, without a teacher, contrary to intuition, a neuron was selected in the output layer of the network, which selectively reacts to the presence of a face in the image. Control experiments showed that this classifier is resistant not only to face displacement on the image field, but also to scaling and even to 3D rotation outside the image plane! It turned out that this neural network is capable of learning to recognize a variety of high-level concepts, such as human figures or cats.
The full text of the article, see the link , here I give a brief retelling.
Concept
In neuroscience, it is believed that individual neurons can be distinguished in the brain that are selective for certain generalized categories, such as human faces. They are also called "grandmother's neurons."
In artificial neural networks, the standard approach is teaching with a teacher: for example, to construct a classifier of human faces, a set of faces is taken, as well as a set of images that do not contain faces, with each image labeled “face” - “not face”. The need for large, labeled collections of training data is a big technical problem.
In this paper, the authors tried to answer two questions: is it possible to train a neural network to recognize faces from unmarked data, and whether it is possible to experimentally confirm the possibility of self-training of "grandmother neurons" on unmarked data. This, in principle, will confirm the hypothesis that infants are independently trained to group similar images (for example, faces) without the intervention of a teacher.
Training data
The training set was made by randomly sampling one frame of 10 million YouTube videos. Only one frame was taken from each video to avoid duplicates in the sample. Each frame was scaled to a size of 200x200 pixels (which distinguishes the described experiment from most recognition works that usually operate with 32x32 frames or the like) Here are typical images from the training set:
Algorithm
The basis for the experiment was a sparse auto-encoder ( described on the hub). Early experiments with shallow depth autoencoders made it possible to obtain classifiers of low-level features (segments, borders, etc.) similar to Gabor filters.
The described algorithm uses a multi-layer auto encoder, as well as some important distinguishing features:
- local receptive fields
- pooling frames
- local normalization of contrasts.
Local receptive fields scale the neural network for large images. Pooling frames and localizing contrasts allows for invariance to movement and local deformations.
The auto encoder used consists of three repeating layers, in each of which the same sublevels are used: local filtering, local pooling, local normalization of contrasts.
The most important feature of this structure is the local connectivity between neurons. The first sublevel uses receptive fields of 18x18 pixels, and the second sublevel combines 5x5 frames of intersecting neighboring areas. Note that local receptive fields do not use convolution, i.e. the parameters of each recursive field are not repeated, they are unique. This approach is more close to the biological prototype, and also allows you to learn more invariants.
Local normalization of contrast also mimics the processes in the biological optic tract. From the activation of each neuron, the weighted average value of the activation of neighboring neurons (Gaussian weights) is subtracted. Then, normalization is performed according to the local rms value of the activation of neighboring neurons, also Gaussian-weighted.
The objective function when training the network minimizes the value of the error in reproducing the original image with a sparse auto-encoder. Optimization is performed globally for all managed network parameters (over 1 billion parameters) using asynchronous gradient descent (asynchronous SGD). To solve such a large-scale problem, model parallelism was implemented, consisting in the fact that the local weights of the neural network are distributed to various machines. One instance of the model is distributed on 169 computers, with 16 processor cores in each.
To further parallelize the learning process, asynchronous gradient descent using several instances of the model is implemented. In the described experiment, the training sample was divided into 5 portions, and each portion was trained on a separate copy of the model. Models transmit updated parameter values to centralized “parameter servers” (256 servers). In a simplified presentation, before processing a mini-series of 100 training images, the model requests parameters from the parameter servers, learns (updates the parameters) and transfers the parameter gradients to the parameter servers.
Such an asynchronous gradient descent is resistant to failures of individual network nodes.
To conduct this experiment, the DistBelief framework was developed, which solves all communication issues between parallel computers in a cluster, including dispatching requests to parameter servers. The learning process lasted 3 days.
Experiment Results
Surprisingly, in the learning process, neurons formed, the best of which showed 81.7% accuracy in facial recognition. The histogram of activation levels (relative to the threshold value of Zero) shows how many images in the test sample caused one or another activation of the “grandmother neuron”. Blue color shows images that do not contain faces (random images), red color shows faces.
In order to confirm that the classifier is trained specifically for face recognition, we visualized the trained network using two methods.
The first method is the selection of test images that caused the greatest activation of the classifier neuron:
The second approach is numerical optimization to obtain the optimal stimulus. Using the gradient descent method, an input pattern was obtained that maximizes the value of the output activation of the classifier for the given parameters of the neural network:
For more detailed quantitative estimates and conclusions about the experimental results, see the original article. On my own, I want to note that a large-scale computational experiment has proved the possibility of self-learning a neural network without a teacher, and the parameters of this network (in particular, the number of layers and interconnects) approximately correspond to biological values.