Comprehending git
- Transfer
From a translator: this article does not describe git commands, it implies that you are already familiar with it. It describes a completely sound, in my opinion, approach to keeping public history clean and tidy.
If you do not understand what prompted git to do just that, then suffering awaits you. Using a lot of flags (--flag), you can get git to work the way you think it should work, instead of working the way git wants it to. It's like hammering nails with a screwdriver. The work is done, but worse, slower, and the screwdriver spoils.
Let's see how the usual approach to development with git falls apart.
We buddle the branch from master, work, merge back when finished.
Most of the time this works, as expected, because master changes after you have made the branch (I mean that your colleagues commit in master - approx. Translator.) . Once you merge the feature branch into master, but master hasn't changed. Instead of a merge commit, git simply moves the master pointer to the last commit, fast forward occurs.
To explain the fast forward mechanism, I borrowed a picture from one well-known article. Note translator.
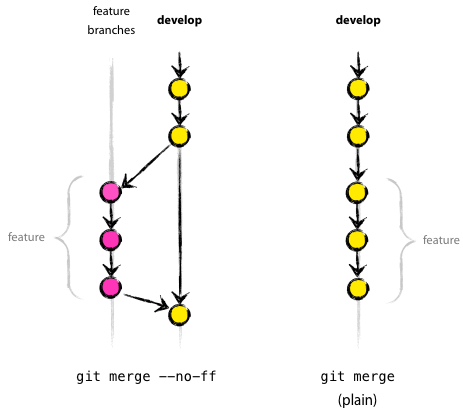
Unfortunately, your feature branch contained intermediate commits - frequent commits that backup work, but capture code inoperative. Now these commits are indistinguishable from stable commits in master. You can easily roll back into such a disaster.
So, you are adding a new rule: "Use --no-ff when merging feature branches." This solves the problem and you move on.
Then one day you find a critical bug in production and you need to track the moment when it appeared. You run bisect , but constantly fall into intermediate commits. You give up and look for it with your hands.
You localize the bug down to the file. Run blame to see changes in the last 48 hours. You know that this is not possible, but blame reports that the file has not changed for several weeks. It turns out that blame gives the time of the initial commit instead of the merge time of the branch (it’s logical, because merge commit is empty - translator comment) . Your first interim commit changed this file a few weeks ago, but the change was introduced only today.
A no-ff crutch, a broken bisect and a slurred blame are symptoms of hammering nails with a screwdriver.
Version control is needed for two things.
The first is to help write code. There is a need to synchronize edits with your team and regularly backup your work.
The second reason is configuration management . Includes concurrent development management. For example, work on the next release version and parallel bug fixes of the existing production version. Configuration management implies the ability to find out when something has been changed. An invaluable tool for diagnosing errors.
Traditionally, these two reasons come into conflict.
When developing some functionality, you will need regular intermediate commits. However, these commits usually break the build.
In a perfect world, every change in version history is concise and stable. There are no intermediate commits that interfere. There are no giant commits per 10,000 lines. A neat story lets you roll back edits or toss them between branches using cherry-pick . A neat story is easier to learn and analyze. However, maintaining the purity of history implies bringing all edits to perfect condition.
So what approach do you choose? Frequent commits or a neat story?
If you are working together on a pre-release startup, a neat story does not bribe much. You can commit everything in master and release releases whenever you like.
As soon as the significance of the changes increases, be it the growth of the development team or the size of the user base, you will need tools to maintain order. This includes automated testing, code review, and a neat history.
Feature branches look like a good compromise. They solve simple problems of parallel development. You are thinking about integrating at the least important point in time when writing code, but that will help you for a while.
When your project grows big enough, the simple branch / commit / merge approach will fall apart. The time for applying the adhesive tape is over. You need a neat change history.
Git is revolutionary because it gives you the best of both worlds. You can make frequent commits during the development process and clear history at the end. If this is your approach, then git defaults seem more meaningful (meaning fast-forward by default when merging branches - approx. Translator) .
Think of branches in the context of two categories: public branches and private.
Public branches are the official history of the project. A commit to a public branch should be concise, atomic and have a good description. It must be linear. It must be unchanged. Public branches are master and release.
Private branch for yourself. This is your draft at the time of solving the problem.
It is most secure to store private branches locally. If you need to make a push to synchronize your desktop and home computers, for example, tell your colleagues that the branch is yours and that you should not rely on it.
Do not inject a private branch into a public simple merge. First clean your branch with tools like reset, rebase, merge --squash and commit --amend.
Imagine yourself a writer, and commits as chapters of a book. Writers do not publish drafts. Michael Crichton said: "Great books are not written - they are rewritten."
If you came from other VCSs, changing the history will seem taboo to you. You proceed from the fact that any commit is carved in stone. Following this logic, you need to remove "undo" from text editors.
Pragmatists only care about edits until these edits become annoying. For configuration management, only global changes are important to us. Intermediate commits are just a lightweight buffer with the ability to cancel.
If we consider history as something unsullied, then fast-forward merging is not only safe but also preferable. It supports the linearity of history, it is easier to track.
The only remaining argument for --no-ff is documentation. You can use merge commits to associate with the latest production code. This is an antipattern. Use tags.
I use 3 simple approaches depending on the size of the change, the time it worked on it, and how far the branch went to the side.
Most of the time cleaning is just a squash commit.
Suppose I created a feature branch and made several intermediate commits within an hour.
As soon as I finish, instead of a simple merge, I do the following:
Then I spend a minute writing a more detailed comment on the commit.
At times, the implementation of a feature grows into a multi-day project with many small commits.
I decide that my edit should be split into smaller parts, so squash is too coarse a tool. (As a daily rule, I ask myself: “Will it be easy to make a code review?”)
If my interim commits were a logical move forward, then you can use rebase interactively.
Interactive mode is powerful. You can use it to edit old commits, split or organize them, and, in this case, to combine several.
In the feature branch:
An editor opens with a list of commits. Each line is: a command to be executed, a SHA1 hash, and a comment for the commit. Below is a list of possible commands.
By default, each commit has “pick”, which means “do not change the commit”.
I change the command to squash, which combines the current commit with the previous one.
I save, now another editor requests a comment on the merged commit. All is ready.
Perhaps the feature branch lasted a long time and other branches merged into it to maintain its relevance. The story is complicated and confused. The simplest solution is to take a rough diff and create a new branch.
Now the working directory is full of my edits and no legacy of the previous branch. Now we take and pens add and commit edits.
If you're struggling with defaults in git, ask yourself why.
Consider a public story immutable, atomic, and easily traceable.
Consider a private story mutable and flexible.
The procedure is as follows:
If you do not understand what prompted git to do just that, then suffering awaits you. Using a lot of flags (--flag), you can get git to work the way you think it should work, instead of working the way git wants it to. It's like hammering nails with a screwdriver. The work is done, but worse, slower, and the screwdriver spoils.
Let's see how the usual approach to development with git falls apart.
We buddle the branch from master, work, merge back when finished.
Most of the time this works, as expected, because master changes after you have made the branch (I mean that your colleagues commit in master - approx. Translator.) . Once you merge the feature branch into master, but master hasn't changed. Instead of a merge commit, git simply moves the master pointer to the last commit, fast forward occurs.
To explain the fast forward mechanism, I borrowed a picture from one well-known article. Note translator.
Unfortunately, your feature branch contained intermediate commits - frequent commits that backup work, but capture code inoperative. Now these commits are indistinguishable from stable commits in master. You can easily roll back into such a disaster.
So, you are adding a new rule: "Use --no-ff when merging feature branches." This solves the problem and you move on.
Then one day you find a critical bug in production and you need to track the moment when it appeared. You run bisect , but constantly fall into intermediate commits. You give up and look for it with your hands.
You localize the bug down to the file. Run blame to see changes in the last 48 hours. You know that this is not possible, but blame reports that the file has not changed for several weeks. It turns out that blame gives the time of the initial commit instead of the merge time of the branch (it’s logical, because merge commit is empty - translator comment) . Your first interim commit changed this file a few weeks ago, but the change was introduced only today.
A no-ff crutch, a broken bisect and a slurred blame are symptoms of hammering nails with a screwdriver.
Rethinking Version Control
Version control is needed for two things.
The first is to help write code. There is a need to synchronize edits with your team and regularly backup your work.
The second reason is configuration management . Includes concurrent development management. For example, work on the next release version and parallel bug fixes of the existing production version. Configuration management implies the ability to find out when something has been changed. An invaluable tool for diagnosing errors.
Traditionally, these two reasons come into conflict.
When developing some functionality, you will need regular intermediate commits. However, these commits usually break the build.
In a perfect world, every change in version history is concise and stable. There are no intermediate commits that interfere. There are no giant commits per 10,000 lines. A neat story lets you roll back edits or toss them between branches using cherry-pick . A neat story is easier to learn and analyze. However, maintaining the purity of history implies bringing all edits to perfect condition.
So what approach do you choose? Frequent commits or a neat story?
If you are working together on a pre-release startup, a neat story does not bribe much. You can commit everything in master and release releases whenever you like.
As soon as the significance of the changes increases, be it the growth of the development team or the size of the user base, you will need tools to maintain order. This includes automated testing, code review, and a neat history.
Feature branches look like a good compromise. They solve simple problems of parallel development. You are thinking about integrating at the least important point in time when writing code, but that will help you for a while.
When your project grows big enough, the simple branch / commit / merge approach will fall apart. The time for applying the adhesive tape is over. You need a neat change history.
Git is revolutionary because it gives you the best of both worlds. You can make frequent commits during the development process and clear history at the end. If this is your approach, then git defaults seem more meaningful (meaning fast-forward by default when merging branches - approx. Translator) .
Sequencing
Think of branches in the context of two categories: public branches and private.
Public branches are the official history of the project. A commit to a public branch should be concise, atomic and have a good description. It must be linear. It must be unchanged. Public branches are master and release.
Private branch for yourself. This is your draft at the time of solving the problem.
It is most secure to store private branches locally. If you need to make a push to synchronize your desktop and home computers, for example, tell your colleagues that the branch is yours and that you should not rely on it.
Do not inject a private branch into a public simple merge. First clean your branch with tools like reset, rebase, merge --squash and commit --amend.
Imagine yourself a writer, and commits as chapters of a book. Writers do not publish drafts. Michael Crichton said: "Great books are not written - they are rewritten."
If you came from other VCSs, changing the history will seem taboo to you. You proceed from the fact that any commit is carved in stone. Following this logic, you need to remove "undo" from text editors.
Pragmatists only care about edits until these edits become annoying. For configuration management, only global changes are important to us. Intermediate commits are just a lightweight buffer with the ability to cancel.
If we consider history as something unsullied, then fast-forward merging is not only safe but also preferable. It supports the linearity of history, it is easier to track.
The only remaining argument for --no-ff is documentation. You can use merge commits to associate with the latest production code. This is an antipattern. Use tags.
Recommendations and examples
I use 3 simple approaches depending on the size of the change, the time it worked on it, and how far the branch went to the side.
Quick edit
Most of the time cleaning is just a squash commit.
Suppose I created a feature branch and made several intermediate commits within an hour.
git checkout -b private_feature_branch
touch file1.txt
git add file1.txt
git commit -am "WIP"As soon as I finish, instead of a simple merge, I do the following:
git checkout master
git merge --squash private_feature_branch
git commit -vThen I spend a minute writing a more detailed comment on the commit.
Edit more
At times, the implementation of a feature grows into a multi-day project with many small commits.
I decide that my edit should be split into smaller parts, so squash is too coarse a tool. (As a daily rule, I ask myself: “Will it be easy to make a code review?”)
If my interim commits were a logical move forward, then you can use rebase interactively.
Interactive mode is powerful. You can use it to edit old commits, split or organize them, and, in this case, to combine several.
In the feature branch:
git rebase --interactive masterAn editor opens with a list of commits. Each line is: a command to be executed, a SHA1 hash, and a comment for the commit. Below is a list of possible commands.
By default, each commit has “pick”, which means “do not change the commit”.
pick ccd6e62 Work on back button
pick 1c83feb Bug fixes
pick f9d0c33 Start work on toolbarI change the command to squash, which combines the current commit with the previous one.
pick ccd6e62 Work on back button
squash 1c83feb Bug fixes
pick f9d0c33 Start work on toolbarI save, now another editor requests a comment on the merged commit. All is ready.
Failed branches
Perhaps the feature branch lasted a long time and other branches merged into it to maintain its relevance. The story is complicated and confused. The simplest solution is to take a rough diff and create a new branch.
git checkout master
git checkout -b cleaned_up_branch
git merge --squash private_feature_branch
git resetNow the working directory is full of my edits and no legacy of the previous branch. Now we take and pens add and commit edits.
Summarize
If you're struggling with defaults in git, ask yourself why.
Consider a public story immutable, atomic, and easily traceable.
Consider a private story mutable and flexible.
The procedure is as follows:
- Create a private branch from the public branch.
- We methodically commit work to this private branch.
- Once the code is perfect, we tidy up the story.
- Merge the ordered branch back into the public one.