How JS works: abstract syntax trees, parsing and its optimization
- Transfer
[We advise you to read] Other 19 parts of the cycle
Часть 1: Обзор движка, механизмов времени выполнения, стека вызовов
Часть 2: О внутреннем устройстве V8 и оптимизации кода
Часть 3: Управление памятью, четыре вида утечек памяти и борьба с ними
Часть 4: Цикл событий, асинхронность и пять способов улучшения кода с помощью async / await
Часть 5: WebSocket и HTTP/2+SSE. Что выбрать?
Часть 6: Особенности и сфера применения WebAssembly
Часть 7: Веб-воркеры и пять сценариев их использования
Часть 8: Сервис-воркеры
Часть 9: Веб push-уведомления
Часть 10: Отслеживание изменений в DOM с помощью MutationObserver
Часть 11: Движки рендеринга веб-страниц и советы по оптимизации их производительности
Часть 12: Сетевая подсистема браузеров, оптимизация её производительности и безопасности
Часть 12: Сетевая подсистема браузеров, оптимизация её производительности и безопасности
Часть 13: Анимация средствами CSS и JavaScript
Часть 14: Как работает JS: абстрактные синтаксические деревья, парсинг и его оптимизация
Часть 15: Как работает JS: классы и наследование, транспиляция в Babel и TypeScript
Часть 16: Как работает JS: системы хранения данных
Часть 17: Как работает JS: технология Shadow DOM и веб-компоненты
Часть 18: Как работает JS: WebRTC и механизмы P2P-коммуникаций
Часть 19: Как работает JS: пользовательские элементы
Часть 2: О внутреннем устройстве V8 и оптимизации кода
Часть 3: Управление памятью, четыре вида утечек памяти и борьба с ними
Часть 4: Цикл событий, асинхронность и пять способов улучшения кода с помощью async / await
Часть 5: WebSocket и HTTP/2+SSE. Что выбрать?
Часть 6: Особенности и сфера применения WebAssembly
Часть 7: Веб-воркеры и пять сценариев их использования
Часть 8: Сервис-воркеры
Часть 9: Веб push-уведомления
Часть 10: Отслеживание изменений в DOM с помощью MutationObserver
Часть 11: Движки рендеринга веб-страниц и советы по оптимизации их производительности
Часть 12: Сетевая подсистема браузеров, оптимизация её производительности и безопасности
Часть 12: Сетевая подсистема браузеров, оптимизация её производительности и безопасности
Часть 13: Анимация средствами CSS и JavaScript
Часть 14: Как работает JS: абстрактные синтаксические деревья, парсинг и его оптимизация
Часть 15: Как работает JS: классы и наследование, транспиляция в Babel и TypeScript
Часть 16: Как работает JS: системы хранения данных
Часть 17: Как работает JS: технология Shadow DOM и веб-компоненты
Часть 18: Как работает JS: WebRTC и механизмы P2P-коммуникаций
Часть 19: Как работает JS: пользовательские элементы
We all know that the javascript-code of web projects can grow to a huge size. And the larger the code size, the longer the browser will load it. But the problem here is not only the time of data transmission over the network. After the program is loaded, it still needs to be parsed, compiled into bytecode, and finally executed. Today we bring to your attention a translation of the 14th part of a series of materials about the JavaScript ecosystem. Namely, the discussion will focus on parsing JS-code, how abstract syntax trees are built, and how a programmer can influence these processes by increasing the speed of their applications.

How are programming languages
Before we talk about abstract syntax trees, let us dwell on how programming languages are organized. Regardless of which language you use, you always have to use certain programs that take the source code and convert it into something that contains specific commands for the machines. In the role of such programs are either interpreters or compilers. It doesn't matter if you are writing in an interpreted language (JavaScript, Python, Ruby), or compiled (C #, Java, Rust), your code, which is plain text, will always go through the parsing stage, that is, turning plain text into a data structure , which is called an abstract syntax tree (Abstract Syntax Tree, AST).
Abstract syntax trees not only provide a structured representation of the source code, they also play a crucial role in semantic analysis, during which the compiler checks the correctness of the software constructs and the correctness of using their elements. After forming an AST and performing checks, this structure is used to generate bytecode or machine code.
Using abstract syntax trees
Abstract syntax trees are used not only in interpreters and compilers. They are, in the world of computers, useful in many other areas. One of the most common options for their use is static code analysis. Static analyzers do not execute the code passed to them. However, despite this, they need to understand the structure of the programs.
Suppose you want to develop a tool that finds common structures in your code. Reports of this tool will help in refactoring, will reduce duplication of code. This can be done using the usual string comparison, but this approach will be very primitive, its possibilities will be limited. In fact, if you want to create such a tool, you do not need to write your own JavaScript parser. There are many open source implementations of such programs that are fully compatible with the ECMAScript specification. For example - Esprima and Acorn. There are also tools that can help in working with what parsers generate, namely, in working with abstract syntax trees.
Abstract syntax trees, in addition, are widely used in the development of transpilers. Suppose you decide to develop a transpiler that translates Python code into JavaScript code. Such a project can be based on an idea, in accordance with which a transpiler is used to create an abstract syntax tree based on Python code, which, in turn, is converted to JavaScript code. You will probably wonder how this is possible. The thing is that abstract syntax trees are just an alternative way of representing code in a certain programming language. Before the code is converted to AST, it looks like plain text, which when written, follow certain rules that form the language. After parsing, this code turns into a tree structure, which contains the same information as the source code of the program. As a result, it is possible to make not only a transition from source code to AST, but also an inverse transformation, turning the abstract syntax tree into a textual representation of the program code.
Parsing javascript code
Let's talk about how abstract syntax trees are built. As an example, consider a simple JavaScript function:
functionfoo(x){
if (x > 10) {
var a = 2;
return a * x;
}
return x + 10;
}The parser will create an abstract syntax tree, which is shown schematically in the following figure.
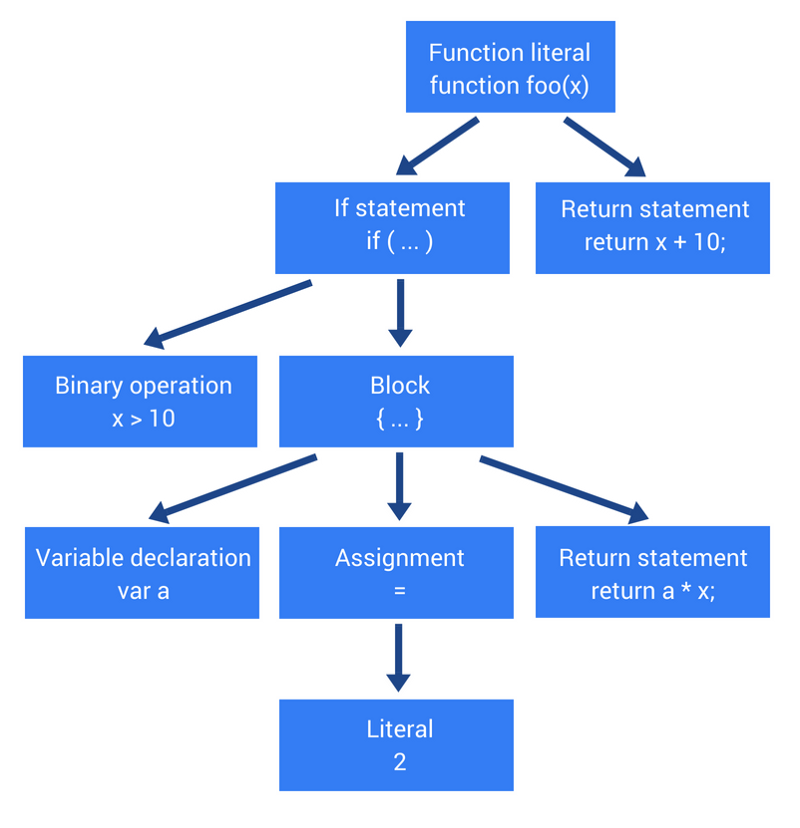
Abstract syntax tree
Please note that this is a simplified representation of the results of the parser. This abstract syntax tree looks much more complicated. In this case, our main goal is to get an idea of what, in the first place, the source code turns into before it is executed. If you are interested in taking a look at how a real abstract syntax tree looks like - use the AST Explorer website. In order to generate an AST for a certain fragment of JS code, it is enough to place it in the corresponding field on the page.
Perhaps, here you have a question about why a programmer needs to know how the JS parser works. After all, parsing and executing code is the task of the browser. In a sense, you are right. The figure below shows the time required for some well-known web projects to perform various steps in the JS code execution process.
Look at this picture, perhaps you will see something interesting there.
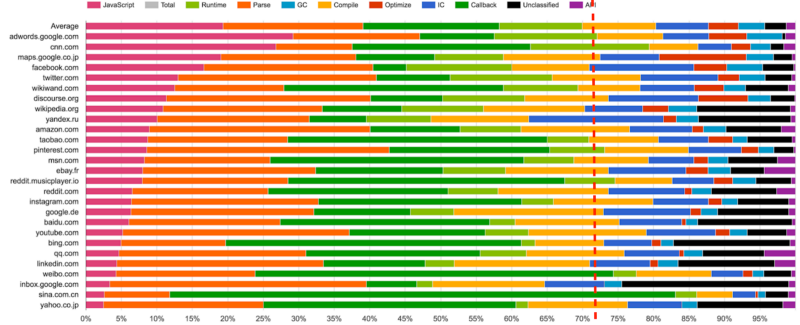
Time spent on JS code execution
Do you see? If not, look again. As a matter of fact, we are talking about the fact that, on average, browsers spend 15-20% of their time on parsing JS code. And this is not some conditional data. Before you - statistical information about the work of real web projects that somehow use JavaScript. Perhaps the figure of 15% may not seem so big to you, but believe me, this is a lot. A typical one-page application loads approximately 0.4 MB of JavaScript code, and in order to parse this code, the browser needs approximately 370 ms. Again, you can say that there is nothing to worry about. And yes, in itself it is a bit. However, one should not forget that this is only the time it takes to disassemble the code and turn it into an AST. This does not include the time required to execute the code, or the time it takes to solve other problems,rendering page . Moreover, we are talking only about desktop browsers. In the case of mobile systems, it is still worse. In particular, the time of parsing the same code on mobile devices can be 2-5 times longer than on desktop ones. Take a look at the following drawing.

Time parsing 1 MB JS-code on various devices
Here is the time required to parse the 1 MB JS-code on various mobile and desktop devices.
In addition, web applications are constantly becoming more complex, the solution of more and more tasks is transferred to the client side. All this is aimed at improving the user experience of working with websites, in order to bring these feelings closer to those that users experience by interacting with traditional applications. It is easy to find out how much all this affects web projects. To do this, simply open the developer’s tools in the browser, go to some modern website and see how much time is spent on parsing the code, on the compilation, and on everything else that happens in the browser when preparing the page for work.

Analyzing a site using developer tools in a browser
Unfortunately, mobile browsers do not have such tools. However, this does not mean that mobile versions of sites cannot be analyzed. This is where tools like DeviceTiming come to our rescue . Using DeviceTiming, you can measure the time it takes to parse and execute scripts in managed environments. This works by placing local scripts in the environment generated by the auxiliary code, which means that every time the page is loaded from various devices, we have the opportunity to locally measure the time of parsing and code execution.
Optimization of parsing and JS engines
JS engines do a lot of useful things in order to avoid unnecessary work and optimize code processing. Here are some examples.
The V8 engine supports streaming scripts and code caching. In this case, streaming refers to the fact that the system is engaged in parsing scripts that are loaded asynchronously, and scripts that are suspended, in a separate thread, starting to do this from the moment code is started. This leads to the fact that the parsing ends almost simultaneously with the completion of the script loading, which gives about a 10% reduction in the time required to prepare the pages for work.
JavaScript code is usually compiled to bytecode each time a page is visited. This bytecode, however, is lost after the user moves to another page. This happens because the compiled code is highly dependent on the state and context of the system at compile time. In order to improve the situation in Chrome 42 added support for bytecode caching. Thanks to this innovation, the compiled code is stored locally, as a result, when the user returns to the already visited page, to prepare it for work, you do not need to perform loading, parsing and compiling scripts. This allows Chrome to save approximately 40% of the time on parsing and compiling tasks. In addition, in the case of mobile devices, this leads to saving battery power. Carakan
enginewhich was used in the Opera browser and was replaced by V8 for quite a long time, could reuse the compilation results of already processed scripts. It did not require that these scripts be connected to the same page or even be loaded from the same domain. This caching technique is, in fact, very efficient and allows you to completely abandon the compile step. It relies on typical user behavior scenarios, on how people work with web resources. Namely, when a user follows a certain sequence of actions, while working with a web application, the same code is loaded. SpiderMonkey
interpreterused in FireFox is not caching everything. It supports a monitoring system that counts the number of calls to a specific script. On the basis of these indicators, sections of code that need to be optimized, that is, those that account for the maximum load, are determined.
Of course, some browser developers may decide that they do not need caching at all. So, Macey Stachowiak , lead developer of the Safari browser, says that Safari is not caching the compiled bytecode. The possibility of caching has been considered, but it has not yet been implemented, since code generation takes less than 2% of the total program execution time.
These optimizations do not directly affect the source code parsing of JS. In the course of their application, everything possible is done to, in certain cases, completely skip this step. No matter how fast the parsing is, it still takes some time, and the complete absence of parsing is perhaps an example of perfect optimization.
Reduced time to prepare web applications for work
As we found out above, it would be good to reduce the need for parsing scripts to a minimum, but it is impossible to get rid of it completely, so let's talk about how to reduce the time required to prepare web applications for work. In fact, for this you can do a lot of things. For example, you can minimize the amount of JS-code included in the application. The code of a small volume that prepares a page for work can be disassembled more quickly, and its implementation will most likely take less time than a more voluminous code.
In order to reduce the amount of code, you can organize loading on the page only what it really needs, and not some kind of huge piece of code, which includes everything that is necessary for the web project as a whole. For example, the pattern PRPLIt promotes this approach to loading code. As an alternative, you can check the dependencies and see if there is something redundant in them, one that only leads to an unjustified proliferation of the code base. In fact, here we touched on a big topic worthy of a separate material. Let's return to parsing.
So, the purpose of this material is to discuss techniques that allow a web developer to help the parser to do its work faster. Such techniques exist. Modern JS parsers use heuristic algorithms to determine whether to execute a certain piece of code as soon as possible, or it will need to be executed later. Based on these predictions, the parser either completely analyzes the code fragment using the greedy parsing algorithm (eager parsing), or uses the lazy parsing algorithm (lazy parsing). With full analysis, the functions that need to be compiled as soon as possible are analyzed. During this process, the solution of three main tasks is carried out: building an AST, creating a hierarchy of scopes, and searching for syntax errors. Lazy analysis, on the other hand, used only for functions that do not need to be compiled yet. No AST is created here and no error search is performed. With this approach, a hierarchy of scopes is only created, which saves about half the time compared to processing the functions that need to be performed as soon as possible.
In fact, the concept is not new. Even older browsers like IE9 support similar approaches to optimization, although, of course, modern systems have gone far ahead.
Let us analyze an example illustrating the operation of these mechanisms. Suppose we have the following JS code:
functionfoo() {
functionbar(x) {
return x + 10;
}
functionbaz(x, y) {
return x + y;
}
console.log(baz(100, 200));
}As in the previous example, the code gets into the parser, which parses it and generates an AST. As a result, the parser represents the code consisting of the following main parts (
foowe will not pay attention to the function ):- The declaration of a function
barthat takes one argument (x). This function has one return command, it returns the result of additionxand 10. - Declaring a function
bazthat takes two arguments (xandy). She also has one return command, she returns the result of the additionxandy. - Making a function call
bazwith two arguments - 100 and 200. - Make a function call
console.logwith one argument, which is the value returned by a previously called function.
Here's what it looks like.

The result of the sample code analysis without applying optimization
Let's talk about what is happening here. The parser sees the function declaration, the function
bardeclaration, the functionbazcall,bazand the function callconsole.log. Obviously, parsing this code snippet, the parser will face a task whose execution will not affect the results of the execution of this program. This is an analysis of the functionbar. Why the analysis of this function is not of practical use? The thing is that the functionbar, at least in the presented code fragment, is never called. This simple example may seem far-fetched, but in many real-world applications there are a large number of functions that are never invoked. In a situation like this, instead of parsing the function
bar, we can simply make a record that it is declared, but is not used anywhere. At the same time, the actual parsing of this function is performed when it becomes necessary, immediately before its execution. Naturally, when performing lazy parsing, you need to detect the body of the function and record its declaration, but this ends the work. For such a function, it is not necessary to form an abstract syntax tree, since the system does not have information that this function is planned to be performed. In addition, no memory is allocated from the heap, which usually requires considerable system resources. If in a nutshell, the refusal to parse unnecessary functions leads to a significant increase in code performance.As a result, in the previous example, the real parser will form a structure resembling the following scheme.

The result of the analysis of the example code with optimization
Please note that the parser made a record about the declaration of the function
bar, but did not analyze it further. The system made no effort to analyze the function code. In this case, the function body was a command to return the result of simple calculations. However, in most real-world applications, function code can be much longer and more complex, containing many return commands, conditions, loops, variable declaration commands, and nested functions. An analysis of all this, provided that such functions are never called, is a waste of time.There is nothing complicated in the above concept, but its practical implementation is not an easy task. Here we looked at a very simple example, and, in fact, when deciding whether a certain code fragment will be required in a program, you need to analyze both functions, and cycles, and conditional operators, and objects. In general, we can say that the parser needs to process and analyze absolutely everything that is in the program.
Here, for example, is a very common pattern of implementation of modules in JavaScript:
var myModule = (function(){
// Вся логика модуля
// Возврат объекта модуля
})();Most modern JS parsers recognize this pattern, it is for them a signal that the code inside the module needs to be fully analyzed.
And what if the parsers always used lazy parsing? This, unfortunately, is not a good idea. The fact is that with this approach, if some code needs to be executed as soon as possible, we will face slowing down the system. The parser will perform one pass of lazy parsing, after which it will immediately start on a complete analysis of what needs to be done as soon as possible. This will lead to about 50% slowdown compared to the approach, when the parser immediately starts a full analysis of the most important code.
Code optimization taking into account the features of its analysis
Now that we have understood a little about what is happening in the depths of the parsers, it's time to think about what can be done to help them. We can write code so that the functions are parsed at the right time. There is one pattern that most parsers understand. It is expressed in the fact that functions are enclosed in brackets. Such a construction almost always tells the parser that the function must be immediately parsed. If the parser detects an opening parenthesis immediately after which the function declaration follows, it will immediately begin to parse the function. We can help the parser by applying this technique when describing the functions that need to be performed as soon as possible.
Suppose we have a function
foo:functionfoo(x) {
return x * 10;
}Since there is no explicit indication in this code fragment that this function is planned to be executed immediately, the browser will only perform its lazy syntax analysis. However, we are confident that we will need this function very soon, so we can resort to the following trick.
First, let's save the function in a variable:
var foo = functionfoo(x){
return x * 10;
};Notice
functionthat we left the original function name between the keyword and the opening bracket. This is not to say that it is absolutely necessary, but it is recommended to do just that, since if an exception is thrown during the function, you can see the name of the function in the stack trace data, not <anonymous>. After the above change, the parser will continue to use lazy parsing. In order to change this, one small detail is enough. The function must be enclosed in brackets:
var foo = (functionfoo(x){
return x * 10;
});Now, when the parser detects the opening parenthesis before the keyword
function, it will immediately proceed to parse this function. Such optimizations can be difficult to perform manually, since for this you need to know in which cases the parser will perform lazy syntax analysis, and in which cases it will complete. In addition, it takes time to decide whether a particular function needs to be prepared as quickly as possible for work or not.
Programmers, for sure, do not want to charge themselves with all this extra work. In addition, what is no less important than everything that has already been said, the code processed in this way will be more difficult to read and understand. In this situation, special software packages like Optimize.js are ready to help us. Their main goal is to optimize the time of the initial download of the source code to JS. They perform static code analysis and modify it so that the functions that need to be performed as soon as possible would be enclosed in brackets, which causes the browser to immediately analyze them and prepare them for execution.
So, suppose that we are programming without particularly thinking about anything, and we have the following code fragment:
(function() {
console.log('Hello, World!');
})();It looks quite normal, it works as it is expected, it is executed quickly, because the parser finds the opening bracket in front of the keyword
function. So far, so good. Of course, before all this gets into production, the code must be minified in order to reduce its size:!function(){console.log('Hello, World!')}();It seems that everything is fine here, the code works the same way it used to be. However, if you look closely, it turns out that something in this minified fragment of the source program is not enough.
The minifikator removed the parentheses in which the function declaration was enclosed by placing an exclamation mark at the beginning of the line. This means that the parser will skip this line, that it will be processed using lazy parsing. Moreover, in order to perform this function, the system will have to perform a full analysis immediately after the lazy one. All this will lead to the fact that such a minified code will work slower than its original version. Now it's time to think about tools like the aforementioned Optimize.js. If you process the minified code using Optimize.js, the output will be as follows:
!(function(){console.log('Hello, World!')})();This is more like what we need. We get both minification and code optimization. The program text takes up less disk space, and the parser understands which fragments need to be completely disassembled and as soon as possible, and which fragments using the lazy parsing technique.
Precompilation
As you can see, preparing JS-code for work is a matter that requires considerable system resources. Why not do all this on the server? In the end, it is much better to once prepare the program for execution and pass on what happened to customers, rather than forcing each client system to process the source code each time. In fact, this possibility is now being discussed, in particular, the question is whether browser JS engines should offer mechanisms for executing precompiled scripts in order to free browsers from the tasks of preparing code for execution. In general, the idea is that we have some server tool that can generate bytecode that is enough to transfer to the client over the network and execute. This will significantly reduce the time to prepare web pages for work. And although this mechanism looks quite seductive, in fact, not everything is so simple. Preparing the code to work on the server can have the opposite effect, since the amount of data transferred is likely to increase, it may be necessary to sign the code and check it for security purposes. In addition, JS-engines are developing in the already formed mainstream, in particular, the V8 development team is working on the internal mechanisms of the engine, aimed at getting rid of re-parsing. Similar approaches to client-side optimization can make precompilation on the server not so attractive anymore. it may be necessary to sign the code and check it for security purposes. In addition, JS-engines are developing in the already formed mainstream, in particular, the V8 development team is working on the internal mechanisms of the engine, aimed at getting rid of re-parsing. Similar approaches to client-side optimization can make precompilation on the server not so attractive anymore. it may be necessary to sign the code and check it for security purposes. In addition, JS-engines are developing in the already formed mainstream, in particular, the V8 development team is working on the internal mechanisms of the engine, aimed at getting rid of re-parsing. Similar approaches to client-side optimization can make precompilation on the server not so attractive anymore.
Optimization Tips
Here are a few recommendations that you can use to optimize web applications:
- Check project dependencies. Get rid of all unnecessary.
- Split the code into small pieces instead of storing it into one large file.
- Postpone, in those situations where it is possible, loading JS-scripts. When processing the current route, the user can be issued only the code that is necessary for normal operation, and nothing superfluous.
- Use developer tools and tools like DeviceTiming to find the bottlenecks of your projects.
- Use tools like Optimize.js to help parsers decide which parts of the code they need to process as soon as possible.
Results
The author of this material says that in his company, which develops the SessionStack system , designed to monitor and record what is happening on web pages, the optimization techniques described above began to be used relatively recently. This allows them to make the application code load faster and get ready for work. The faster this happens, the more pleasant the users will be working with the system. Perhaps ensuring the user experience is one of the tasks that the developers of any web project are trying to solve, and what was discussed in this material is fully capable of helping to solve this problem.
Dear readers! Do you optimize your web projects taking into account the speed of loading and parsing their JavaScript code?
