Offline continuous handwriting recognition
Foreword
As you know, the task of recognizing continuous handwritten text in off-line mode is still considered unsolved.
I managed to solve this problem theoretically and practically. The practical part now looks like a demo version of the program. The solution is general, it is not limited to any field of application, language or dictionary size.
About the program
The program is fully trained. The learning process looks simple: you write characters on-line, the program generalizes them and highlights the writing algorithm. This is the first stage of training. The second stage occurs during operation. If a symbol is found whose general spelling algorithm matches one of the available ones, and the values of some properties go beyond the ranges calculated at the first stage, then the ranges expand. Of course, only after the user confirms the general recognition result. By the way, at the first stage, from three to seven presentations of the symbol are enough, and the algorithm is ready.
Theory
A bit about theory. There are several approaches to solving this problem. They are usually divided into two types: structural and reference. The first is based on the selection and analysis of various structural elements of the symbol and their signs, properties. The second involves comparing the recognized character with a set of specified patterns. These methods do not allow solving the problem in a general way.
The on-line handwriting task has been completely and successfully solved. This solution is based, in any case, on the creation of character writing algorithms that take into account the trajectory of the pen. That is, the sequence of changing its coordinates. There were suggestions to reduce the recognition problem in off-line mode to recognition in on-line mode. To do this, it is enough to correctly read the lines from the graphic copy of the text. But to do this is fundamentally impossible. Line segments between intersections can be considered, but interpretation is necessary to connect them correctly.
There is only one solution left - to restore the characters during the interpretation of the segments obtained at the stage of reading from a digital graphic copy of the text. For this, two components are needed: a special representation of the symbol spelling algorithm that allows this to be done, and a segment interpretation algorithm capable of analyzing all possible interpretations.
Practice
We managed to do this fully. As you know, the main task of the demo version is to demonstrate a fundamental solution to the task. What is the prototype that is now available in this sense? The program is able to recognize one word written in arbitrary continuous handwriting on white paper. For translation into a digital file, the word can be either scanned or photographed with a webcam or digital camera. In principle, text recognition has already been done, but this function needs refinement.
The following are examples of recognizable words. As you can see, here is not only the usual spelling, but also “complicated” options: crossed out words, characters written in segments, having extra parts and the like. This shows that in a fully finished form the program will be able to recognize quite noisy texts.
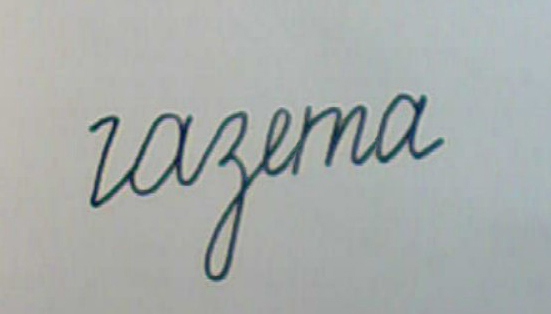
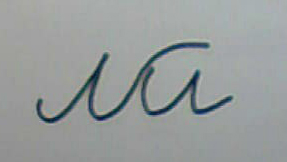
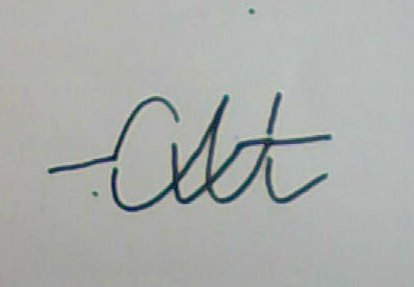

Obviously, only those symbols that have all the necessary parts in approximately their places can be confidently recognized. If there are missing or severely distorted parts, then interpretation at the level of words is necessary. The presence of a dictionary increases the recognition rate, but does not solve all problems. There are cases when, without understanding the meaning of the phrase, some words cannot be unambiguously interpreted. To do this, we need an artificial intelligence system that can understand the meaning of natural language phrases. Until recently, there was no information on the availability of such systems on the market. Now it’s already: ABBYY has announced the creation of the Compreno system , which uses semantic interpretation of phrases based on the “model of the world”, which is independent of a specific language, for translation.
I also have a prototype AI system that can understand the meaning of the text. Judging by the information about Compreno, which is now in the media, my system is functionally much wider. She is trained, capable of generalizing information and actively searching for knowledge in the case when they are not enough to complete the task. In other words, such a system is quite capable of working as a personal secretary. But it has one serious drawback compared to Compreno - in terms of general readiness, it still does not even reach the demo version.
Commerce
And in the end, a little about the commercial side of the project. On the Internet there is an interview with Vice President of ABBYY Lingvo Aram Pakhchanyan. Regarding the task of recognizing continuous handwritten text in off-line mode, it says, in fact, that this problem does not need to be solved. The costs of its solution (presumably very large) will not pay off. And, it seems, mainly because the continuous writing company ABBYY Lingvo has almost made irrelevant. She completely solved the problem of recognizing separate handwritten text, and for all occasions developed the corresponding forms.
Perhaps it was a joke. But still, it makes sense to say the following. Writing in the usual continuous handwriting is more convenient and easier than writing letters in the boxes. If a computer recognizes the former no worse than the latter, the latter will be a thing of the past, like punch cards, black-and-white televisions, and film for cameras.
In the next short video you can see the program in action. It might be interesting.
Conclusion
And another important point - performance indicators, namely, time and percentage recognition. Of course, the demo focused on the second criterion. A level of at least 70% has now been reached. In the finished version, this indicator can be formulated as follows: if a person can read the text, then the program too. So far, we can only say about the recognition time that it can be brought to acceptable values.
If all goes well, there will be more articles about some of the technical aspects of text recognition and about AI.
Thank you for attention.
____________
Update.
Dear habravchane! Thanks to everyone for the feedback, this is very important and useful to us. In general, the topic was met positively, which cannot but rejoice.
I would like to say to the indignant persons: dear, we are not fair magicians. We give a report in our words. If we wrote that in the finished product the recognition accuracy will tend to 100%, then we are sure of that.
You can consider this article an announcement, it did not have the goal of revealing all the technical details in detail. However, given the interest shown, after a while there will be another article in more detail describing the recognition process.
There will also be a demo version available for download.