Clustered index in InnoDB and query optimization
 Recently, networks often write about clustered index in InnoDB and MySQL tables, but, despite this, they are rarely used in practice.
Recently, networks often write about clustered index in InnoDB and MySQL tables, but, despite this, they are rarely used in practice. In this article, we will show two real-life examples of how we have optimized quite complex Badoo systems based on an understanding of how the clustered index works.
Clustered index - a form of organizing a table in a file. In InnoDB, the data is stored in a tree in the same tree as the usual B-TREE keys. The InnoDB table itself is already a big B-TREE. The key values are clustered index. According to the documentation , PRIMARY KEY is selected as the clustered index. If there is no PRIMARY KEY, the first UNIQUE KEY is selected. If this is not the case, then the internal 6-byte code is used.
What follows from such an organization of data on disk?
- Inserting in the middle of the table can be slow due to the need to rebuild the key.
- Updating the clustered index value of a row leads to the physical transfer of information on the disk or to its fragmentation.
- The need to use the ever-increasing value of clustered index for quick insertion into the table. The most optimal will be an auto-increment field.
- Each row has a unique identifier value, clustered index.
- Secondary keys simply reference these unique identifiers.
- In fact, a secondary key of the form KEY `key` (a, b, c) will have the structure KEY` key` (a, b, c, clustered_index).
- The data on the disk is sorted by clustered index (we do not consider the example with SSD).
We will talk about two types of optimization, which helped to significantly speed up the work of our scripts.
Test environment
To reduce the effect of caching on the results of the study, add SQL_NO_CACHE to the samples, and we will also flush the file system cache before each request. And, because we are interested in the worst case, when the data must actually be pulled from the disk, we will restart MySQL before each request.
Equipment:
- Intel® Pentium® Dual CPU E2180 @ 2.00GHz
- RAM DIMM 800 MHz 4Gb
- Ubuntu 11.04
- MySQL 5.5
- HDD Hitachi HDS72161
Optimization of deep offs
For example, take the abstract table messages, which contains user correspondence.
CREATE TABLE messages (
message_id int not null auto_increment,
user1 int not null,
user2 int not null,
ts timestamp not null default current_timestamp,
body longtext not null,
PRIMARY KEY (message_id),
KEY (user1, user2, ts)
) ENGINE = InnoDBConsider this table in light of the listed features of InnoDB.
The clustered index here matches the PRIMARY KEY and is an auto-increment field. Each line has a 4-byte identifier. Inserting new rows into the table is optimal. The secondary key is actually KEY (user1, user2, ts, message_id), and we will use this.
Add 100 million messages to our table. This is enough to identify the necessary features of InnoDB. There are only 10 users in our system, so each pair of people will have an average of a million messages.
Suppose these 10 test users exchanged a lot of messages and often reread old correspondence - the interface allows you to switch to a page with very old messages. And behind this interface is a simple request:
SELECT * FROM messages WHERE user1=1 and user2=2 order by ts limit 20 offset PageNumber*20 The most common, in fact, request. Let's look at the time of its execution, depending on the offset depth:
| offset | execution time (ms) |
|---|---|
| 100 | 311 |
| 1000 | 907 |
| 5000 | 3372 |
| 10,000 | 6176 |
| 20000 | 11901 |
| 30000 | 17057 |
| 40,000 | 21997 |
| 50,000 | 28268 |
| 60,000 | 32805 |
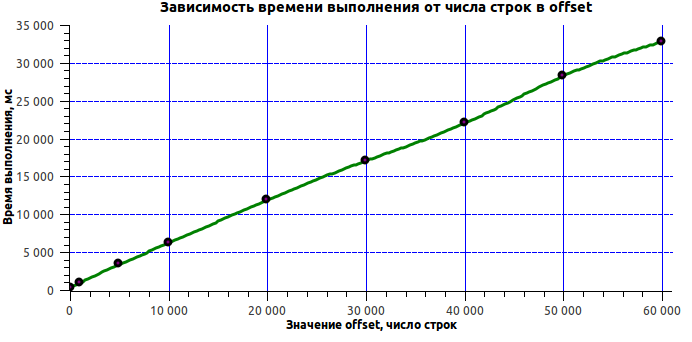
Surely many expected to see linear growth. But getting 33 seconds on 60 thousand records is too much! To explain what takes so much time is quite simple - you just have to mention one of the features of the MySQL implementation. The fact is that MySQL to read this query subtracts the offset + limit of the rows from the disk and returns limit from them. Now the situation is clear: all this time MySQL was engaged in reading from the disk 60 thousand of unnecessary lines to us. What to do in a similar situation? It begs a lot of different solutions. Here, by the way, is an interesting article about these options.
We found a very simple solution: the first query selected only the clustered index values, and then selected exclusively from them. We know that the clustered index value is present at the end of the secondary key, therefore, if we replace * in the request with message_id, we get a request that works only by the key, respectively, the speed of such a request is high.
It was:
mysql> explain select * from messages where user1 = 1 and user2 = 2 order by ts limit 20 offset 20000; + ---- + ------------- + ---------- + ------ + ------------ --- + ------- + --------- + ------------- + -------- + ----- -------- + | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | + ---- + ------------- + ---------- + ------ + ------------ --- + ------- + --------- + ------------- + -------- + ----- -------- + | 1 | SIMPLE | messages | ref | user1 | user1 | 8 | const, const | 210122 | Using where | + ---- + ------------- + ---------- + ------ + ------------ --- + ------- + --------- + ------------- + -------- + ----- -------- + 1 row in set (0.00 sec)
It became:
mysql> explain select message_id from messages where user1 = 1 and user2 = 2 order by ts limit 20 offset 20000; + ---- + ------------- + ---------- + ------ + ------------ --- + ------- + --------- + ------------- + -------- + ----- --------------------- + | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | + ---- + ------------- + ---------- + ------ + ------------ --- + ------- + --------- + ------------- + -------- + ----- --------------------- + | 1 | SIMPLE | messages | ref | user1 | user1 | 8 | const, const | 210122 | Using where; Using index | + ---- + ------------- + ---------- + ------ + ------------ --- + ------- + --------- + ------------- + -------- + ----- --------------------- + 1 row in set (0.00 sec)
Using index in this case means that MySQL will be able to get all the data from the secondary key, and will not access clustered index. Learn more about this here .
And now it remains only to extract the string values directly by the query.
SELECT * FROM messages WHERE message_id IN (....) Let's see how much more efficient this solution is:
| offset | execution time (ms) |
|---|---|
| 100 | 243 |
| 1000 | 164 |
| 5000 | 213 |
| 10,000 | 337 |
| 20000 | 618 |
| 30000 | 756 |
| 40,000 | 971 |
| 50,000 | 1225 |
| 60,000 | 1477 |
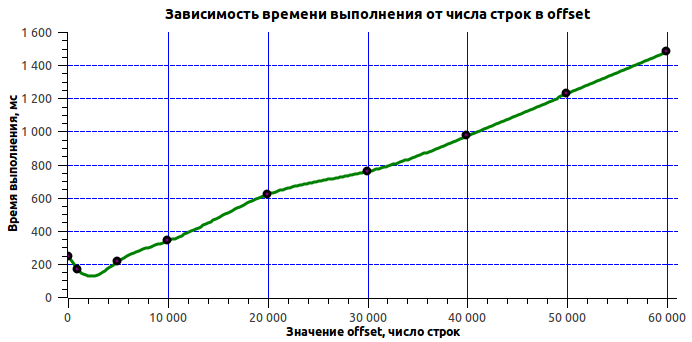
The achieved result suited everyone, so it was decided not to conduct further searches. In addition, it is not known whether it is possible to access these data in principle faster without changing the procedure for working with history itself. It should be noted again that the task was to optimize a specific query, and not the data structure itself.
Optimizing the procedure for updating a large table
The second need for optimization arose when we needed once a day to collect relevant data about our users in one large table. At that time, we had 130 million users. The script, bypassing all our databases and collecting new data, runs in half an hour and selects 30 million changed lines. The result of the script is tens of thousands of text files with serialized new values on the hard drive. Each file contains information about hundreds of users.
Transfer the information from these text files to the database. We read the files sequentially, group the lines into packs of several thousand and update. The execution time of the script ranges from 3 to 20 hours. Naturally, this script behavior is unacceptable. Moreover, it is obvious that the process needs to be optimized.
The first suspicion fell on the “spurious" load on the database server disk. But numerous observations have not revealed evidence of this hypothesis. We came to the conclusion that the problem lies in the bowels of the database and we need to think how to fix it. How does the data lie on disk? What do OS, MySQL and hardware have to do to update this data? While we were answering these questions, we noticed that the data is updated in the same order in which they were collected. This means that each request updates a completely random place in this large table, which entails a loss of time for positioning the disk heads, a loss of the file system cache and a loss of the database cache.
Note that the process of updating each row in MySQL consists of three stages: subtracting values, comparing the old and new values, writing the value. This can even be seen from the fact that, as a result of the query, MySQL answers how many rows matched and how many really were updated.
Then we looked at how many rows actually change in the table. Of the 30 million rows, only 3 million have changed (which is logical, because the table contains very truncated information about users). And this means that 90% of the time MySQL spends on proofreading, and not on updating. The solution came by itself: you should check how random access to the clustered index loses to the sequential one. The result can be generalized in the case of updating the table (before updating it, subtraction and comparison still occur).
The technique is extremely simple - measure the difference in the speed of query execution
SELECT * FROM messages where message_id in ($values)where, as values, transfer an array of 10K elements. Make element values completely random to check for random access. To test sequential access, 10K elements must be made sequentially, starting with some random offset.
function getValuesForRandomAccess () {
$ arr = array ();
foreach (range (1, 10000) as $ i) {
$ arr [] = rand (1,100000000);
}
return $ arr;
}
function getValuesForSequencialAccess () {
$ r = rand (1, 100000000-10000);
return range ($ r, $ r + 10000);
} Random and sequential request execution time:
| N | random | sequential |
|---|---|---|
| 1 | 38494 | 171 |
| 2 | 40409 | 141 |
| 3 | 40868 | 147 |
| 4 | 37161 | 138 |
| 5 | 38189 | 137 |
| 6 | 36930 | 134 |
| 7 | 37398 | 176 |
| 8 | 38035 | 144 |
| 9 | 39722 | 140 |
| 10 | 40720 | 146 |
As you can see, the difference in execution time is 200 times. Therefore, we must fight for this. To optimize execution, you need to sort the source data by primary key. Can we sort out 30 million values in files fast enough? The answer is unequivocal - we can!
After this optimization, the script run time was reduced to 2.5 hours. Pre-sorting 30 million lines takes 30 minutes (and gzip takes most of the time).
Same optimization, but on SSD
After writing the article, we found one extra SSD, on which we also tested.
Deep offset sampling:
| offset | execution time (ms) |
|---|---|
| 100 | 117 |
| 1000 | 406 |
| 5000 | 1681 |
| 10,000 | 3322 |
| 20000 | 6561 |
| 30000 | 9754 |
| 40,000 | 13039 |
| 50,000 | 16293 |
| 60,000 | 19472 |
Optimized deep offset sampling:
| offset | execution time (ms) |
|---|---|
| 100 | 101 |
| 1000 | 21 |
| 5000 | 24 |
| 10,000 | 32 |
| 20000 | 47 |
| 30000 | 94 |
| 40,000 | 84 |
| 50,000 | 95 |
| 60,000 | 120 |
Comparison of random and sequential access:
| N | random | sequential |
|---|---|---|
| 1 | 5321 | 118 |
| 2 | 5583 | 118 |
| 3 | 5881 | 117 |
| 4 | 6167 | 117 |
| 5 | 6349 | 120 |
| 6 | 6402 | 126 |
| 7 | 6516 | 125 |
| 8 | 6342 | 124 |
| 9 | 6092 | 118 |
| 10 | 5986 | 120 |
These figures show that the SSD, of course, has an advantage over a conventional drive, but its use does not eliminate the need for optimization.
And in conclusion of our article, we can say that we managed to increase the data sampling rate by 20 times. We have accelerated the actual updating of the table up to 10 times (surrogate test accelerated 200 times). Recall that the experiments were carried out on a system with caching disabled. The gain on the real system turned out to be less impressive (the cache still fixes the situation well).
The conclusion from the foregoing lies on the surface: it is not enough to know the strengths and weaknesses of the software with which you work, it is important to be able to put this knowledge into practice. Knowledge of the internal structure of MySQL sometimes allows you to speed up queries tens of times.
Alexey alexxz Yeremihin, developer of Badoo