Type-safe SQL on Kotlin
- Tutorial
Expressiveness is an interesting feature of programming languages. With a simple combination of expressions, you can achieve impressive results. Some languages sensibly reject the ideas of expressiveness, but Kotlin is definitely not such a language.
Using basic language constructs and a small amount of sugar, we will try to recreate the SQL in Kotlin syntax as closely as possible.

Link to GitHub for the impatient
Our goal will be to help the programmer catch a certain subset of errors at the compilation stage. Kotlin, being a strictly typed language, will help us to avoid non-valid expressions in the SQL query structure. As a bonus, we will get more protection from typos and help from the IDE in writing requests. Fix the shortcomings of SQL completely fail, but to eliminate some problem areas is quite possible.
This article will tell you about the library at Kotlin, which allows you to write SQL queries in the syntax of Kotlin. Also, we'll take a quick look at the insides of the library to see how this works.
Some theory
SQL stands for Structured Query Language, i.e. the structure of the queries is present, although the syntax leaves much to be desired - the language was created so that any user, even without programming skills, could use it.
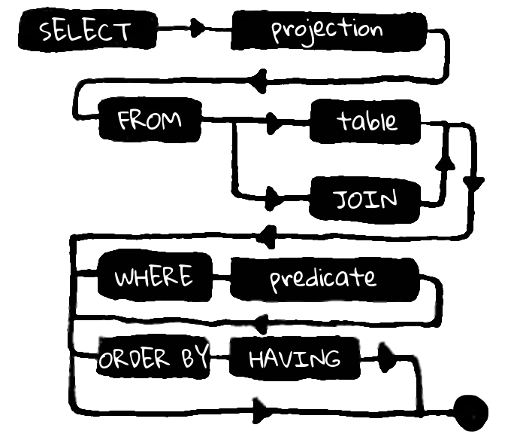
However, under SQL hides a fairly powerful foundation in the form of the theory of relational databases - everything is very logical there. To understand the structure of requests, we turn to a simple sample:
SELECTid, name-- проекция (projection), π(id, name)FROM employees -- источник (table)WHERE organization_id = 1-- выборка с предикатом (predicate), σ(organization_id = 1)What is important to understand: the request consists of three consecutive parts. Each of these parts is, firstly, dependent on the previous one, and secondly, implies a limited set of expressions to continue the query. In fact, even not quite like this: the FROM clause here is clearly primary to the SELECT, since which set of fields we can choose directly depends on the table from which the sample is taken, but not vice versa.
Transfer to Kotlin
So, FROM is primary in relation to any other query language constructs. It is from this expression that all possible options for the continuation of the query arise. In Kotlin, we will reflect this through the function from (T), which will take as input an object representing a table that has a set of columns.
object Employees : Table("employees") {
val id = Column("id")
val name = Column("name")
val organizationId = Column("organization_id")
}
The function returns an object that contains methods that reflect the possible continuation of the query. The from construct always comes first, before any other expressions, so it assumes a large number of extensions, including the final SELECT (as opposed to SQL, where SELECT always comes before FROM). The code equivalent to the SQL query above will be as follows:
from(Employees)
.where { e -> e.organizationId eq 1 }
.select { e -> e.id .. e.name }
Interestingly, in this way we can prevent invalid SQL even at compile time. Each expression, each method call in a chain implies a limited number of continuations. We can control the validity of the request using the Kotlin language. As an example, the where expression does not imply a continuation in the form of another where and, especially, from, but the groupBy, having, orderBy, limit, offset and final select constructs are all valid.
The lambdas passed as arguments to the where and select operators are designed to construct a predicate and a projection, respectively (we already mentioned them earlier). A table is transmitted to the lambda input so that columns can be accessed. It is important that type safety is preserved at this level - with the help of operator overloading, we can achieve that the predicate will ultimately be a pseudo-Boolean expression that does not compile if there is a syntax error or type error. The same applies to the projection.
funwhere(predicate: (T) -> Predicate): WhereClause<T>
funselect(projection: (T) -> Iterable<Projection>): SelectStatement<T>
JOIN
Relational databases allow you to work with a variety of tables and the relationships between them. It would be good to give the opportunity to the developer to work with JOIN and in our library. Fortunately, the relational model fits well with everything that was described earlier - you just need to add the join method, which will add the second table to our expression.
fun<T2: Table>join(table2: T2): JoinClause<T, T2>
JOIN, in this case, will have methods similar to those provided by the FROM clause, with the only difference that the lambda projections and predicates will take two parameters each to refer to the columns of both tables.
from(Employees)
.join(Organizations).on { e, o -> o.id eq e.organizationId }
.where { e, o -> e.organizationId eq 1 }
.select { e, o -> e.id .. e.name .. o.name }
Data management
Data manipulation language is a SQL language tool that allows, in addition to queries to tables, to insert, modify, and delete data. These designs fit well into our model. To support update and delete, we only need to supplement the from and where expressions with an option with calling the appropriate methods. To support insert, we introduce an additional function into.
from(Employees)
.where { e -> e.id eq 1 }
.update { e -> e.name("John Doe") }
from(Employees)
.where { e -> e.id eq 0 }
.delete()
into(Employees)
.insert { e -> e.name("John Doe") .. e.organizationId(1) }
Data description
SQL works with structured data in the form of tables. Tables require a description before working with them. This part of the language is called Data definition language.
The CREATE TABLE and DROP TABLE statements are implemented similarly - the over function will serve as the starting point.
over(Employees)
.create {
integer(it.id).primaryKey(autoIncrement = true)..
text(it.name).unique().notNull()..
integer(it.organizationId).foreignKey(references = Organizations.id)
}
over(Employees).drop()