Open webinar "Order of execution of a SELECT query and query plan in MS SQL Server"
Hello again!
Colleagues, on the last day of January we launch the course “MS SQL Server Developer” , in connection with which we had a thematic open lesson. On it, we talked about how MS SQL Server performs a SELECT query, discussed the order in which and what is being analyzed, and also slightly dived into reading the query plan.
The instructor is Kristina Kucherova , data model architect at Sberbank of Russia.
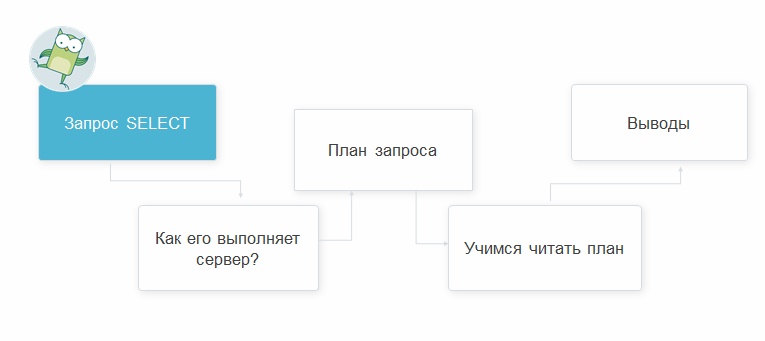
Objectives and route of the webinar
At the beginning of the webinar were set the following goals:
To achieve them, the teacher has prepared a simple but effective route:
Why do we need a query plan?
The query plan is a very useful tool that, unfortunately, many developers do not use. At first glance, it may seem that it is not necessary to know the mechanics of the query. However, if you understand what is happening inside SQL Server, you can write a more efficient query. And it will greatly help, for example, with optimization.
How do we see the SELECT query?
Let's see what a SELECT query looks like:
How to understand where to go for the data?
The first thing the server tries to understand when a request comes in is where to go for the data. The FROM command answers this question, since it is here that we will have a list of tables (or the name of a single table).
For clarity, let's imagine that our server is a kind of butler, whom we order to collect us on vacation. Accordingly, the butler begins to think, and in what closet are the necessary things (in which table do you need to take data)? And so that our butler can easily complete his task, we use FROM.
How to understand what data to take?
Suppose the butler found the closet he needed and opened it. But what things to take? Maybe we are going to a ski resort? Or maybe on a hot sunny beach? In order for our things to match the weather, we need the WHERE command, which defines the conditions, that is, allows us to filter the data. If it's hot, we take slates, T-shirts and swimsuits, if it's cold - mittens, knitted socks, sweaters)).
The next stage is to put this data into groups, which is done with the help of GROUP BY (shirts separately, socks separately). According to the results of grouping, you can impose one more condition using HAVING (for example, weed out unpaired things). In the end, we add everything with the help of ORDER BY, resulting in a ready-made bag of things, or rather, an ordered data block.

By the way, there is a nuance, but it lies in the fact that there is a difference, what conditions should be prescribed in WHERE, and which in HAVING. But this is better to look at the video.
We continue. The path of the request is saved in the form of a query plan in the cache, that is, our butler writes everything down, because he is a good butler - what if you want to repeat your order next year? And such plans, in principle, can be many.
Types of connections in the query plan
There are three connections that you may encounter in the query plan:
Before dwelling on each of them in more detail, let's summarize, why should we even read the request plan. In fact, it is very useful, as you will learn:
Nested Loop
Suppose we need to connect data from different tables. Let's present these tables in the form of ... a small amount of Skittles candy and full M & M's packaging.

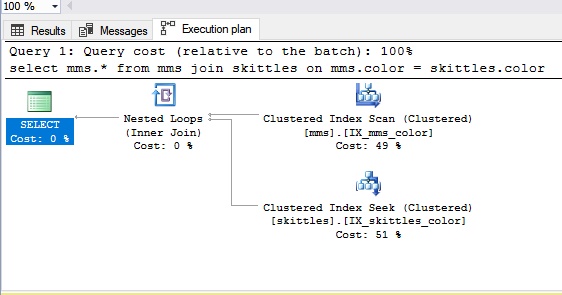
When connecting the type of Nested Loop, we take the candy Skittles, and then we blindly get the candy from the M & M's package. If we don’t come across a candy of the same color (this is our condition), we get the next one, that is, a normal search occurs. As a result, we can say that the Nested Loop connection is more suitable for small amounts of data. Obviously, if there is a lot of data, busting is not the best option.

Let's see how it looks in the SQL panel:
Merge join
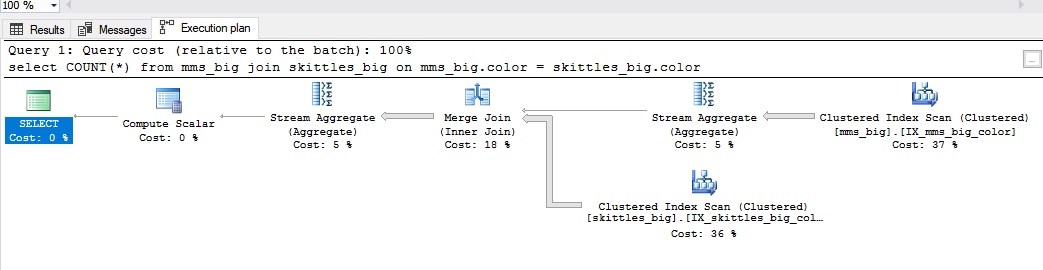
A join is used for large amounts of data. When you have a merge join, both tables have an index by which they can be joined. In the case of candies, it is as if they are arranged in advance in colors.
Everything looks like this:

Merge join is good in the following cases:
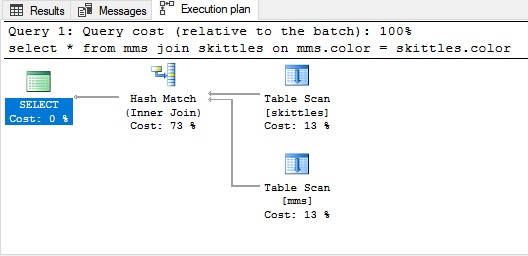
Hash join
Hash join is used for unsorted large amounts of data. To join the tables in this case, you need to build something that imitates an index.
Hash join example:
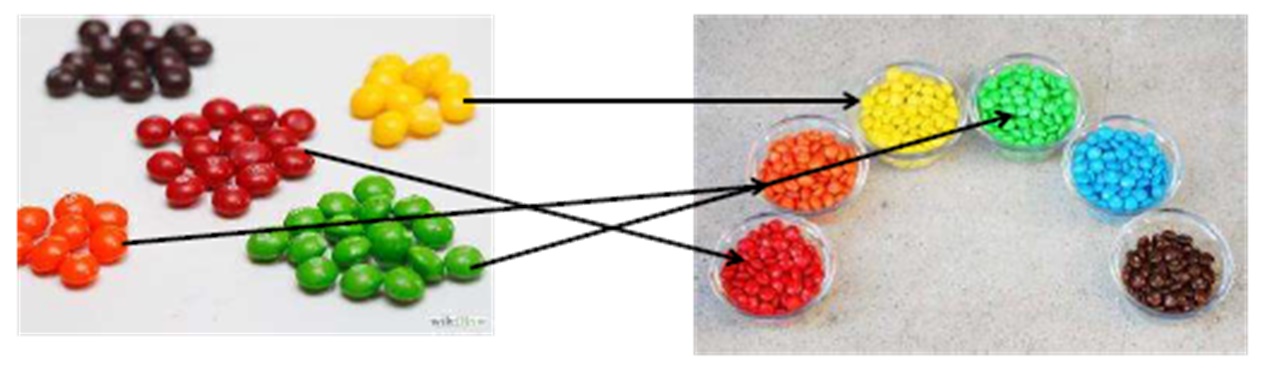
For clarity, let's recall our candies:

Hash join application involves 2 phases of actions:
When Hash join is good:
An important point: if there is not enough memory, the recording will go to tempdb - to disk.
Friends, besides the above, in the open lesson included other interesting points that are best seen, watching the video. We offer to visit the open day of the course “MS SQL Server Developer”, where you can ask the teacher all the questions.
PS Teacher Kristina Kucherova expresses appreciation to Jes Schultz Borland for her presentation with the PASS Summitt Execution Plans, which was used in the preparation of the open lesson.
Colleagues, on the last day of January we launch the course “MS SQL Server Developer” , in connection with which we had a thematic open lesson. On it, we talked about how MS SQL Server performs a SELECT query, discussed the order in which and what is being analyzed, and also slightly dived into reading the query plan.
The instructor is Kristina Kucherova , data model architect at Sberbank of Russia.
Objectives and route of the webinar
At the beginning of the webinar were set the following goals:
- See how the server performs the request, and why it happens that way.
- Learn to read the query plan.
To achieve them, the teacher has prepared a simple but effective route:
Why do we need a query plan?
The query plan is a very useful tool that, unfortunately, many developers do not use. At first glance, it may seem that it is not necessary to know the mechanics of the query. However, if you understand what is happening inside SQL Server, you can write a more efficient query. And it will greatly help, for example, with optimization.
How do we see the SELECT query?
Let's see what a SELECT query looks like:
| SELECT [field1], [field2] ... | Which fields do we choose? |
| FROM [table] | From where |
| WHERE [conditions] | Where are the conditions such and such |
| GROUP BY [field1] | Group by field |
| HAVING [conditions] | Having such and such conditions |
| ORDER BY [field1] | Order (sort) |
How to understand where to go for the data?
The first thing the server tries to understand when a request comes in is where to go for the data. The FROM command answers this question, since it is here that we will have a list of tables (or the name of a single table).
For clarity, let's imagine that our server is a kind of butler, whom we order to collect us on vacation. Accordingly, the butler begins to think, and in what closet are the necessary things (in which table do you need to take data)? And so that our butler can easily complete his task, we use FROM.
How to understand what data to take?
Suppose the butler found the closet he needed and opened it. But what things to take? Maybe we are going to a ski resort? Or maybe on a hot sunny beach? In order for our things to match the weather, we need the WHERE command, which defines the conditions, that is, allows us to filter the data. If it's hot, we take slates, T-shirts and swimsuits, if it's cold - mittens, knitted socks, sweaters)).
The next stage is to put this data into groups, which is done with the help of GROUP BY (shirts separately, socks separately). According to the results of grouping, you can impose one more condition using HAVING (for example, weed out unpaired things). In the end, we add everything with the help of ORDER BY, resulting in a ready-made bag of things, or rather, an ordered data block.
By the way, there is a nuance, but it lies in the fact that there is a difference, what conditions should be prescribed in WHERE, and which in HAVING. But this is better to look at the video.
We continue. The path of the request is saved in the form of a query plan in the cache, that is, our butler writes everything down, because he is a good butler - what if you want to repeat your order next year? And such plans, in principle, can be many.
Types of connections in the query plan
There are three connections that you may encounter in the query plan:
- Nested Loop.
- Merge join.
- Hash join.
Before dwelling on each of them in more detail, let's summarize, why should we even read the request plan. In fact, it is very useful, as you will learn:
- which index is used;
- in what order join is done;
- what is selected from the buffer;
- how much a server spends on a resource;
- what is the difference between a hypothetical and a real plan.
Nested Loop
Suppose we need to connect data from different tables. Let's present these tables in the form of ... a small amount of Skittles candy and full M & M's packaging.
When connecting the type of Nested Loop, we take the candy Skittles, and then we blindly get the candy from the M & M's package. If we don’t come across a candy of the same color (this is our condition), we get the next one, that is, a normal search occurs. As a result, we can say that the Nested Loop connection is more suitable for small amounts of data. Obviously, if there is a lot of data, busting is not the best option.
Let's see how it looks in the SQL panel:
--drop table skittles--drop table mms--запрос для окна слеваcreatetable mms
(idintidentity(1,1),
color varchar(25),
taste varchar(15))
insertinto mms (color, taste)
values ('yellow', 'chocolate')
insertinto mms (color, taste)
values ('red', 'nuts')
create clustered index IX_mms_color ON mms(color);
createtable skittles
(idintidentity(1,1),
color varchar(25),
taste varchar(15))
createindex IX_skittles_id ON skittles(id);
create clustered index IX_skittles_color ON skittles(color);
insertinto skittles (color, taste)
values ('red', 'cherry')
insertinto skittles (color, taste)
values ('blue', 'strange')
insertinto skittles (color, taste)
values ('yellow', 'lemon')
insertinto skittles (color, taste)
values ('green', 'apple')
insertinto skittles (color, taste)
values ('orange', 'orange')
--запрос для правого окнаselect mms.*
from mms join skittles on
mms.color = skittles.color
select *
from mms join skittles on
mms.color = skittles.colorMerge join
A join is used for large amounts of data. When you have a merge join, both tables have an index by which they can be joined. In the case of candies, it is as if they are arranged in advance in colors.
Everything looks like this:
--2 tables 50000 rows, only clustered index by color, color is not uniqueselectCOUNT(*)
from mms_big join skittles_big on
mms_big.color = skittles_big.colorMerge join is good in the following cases:
- large data sets;
- identical fields of connection of the same type;
- there are indexes on the connection fields.
Hash join
Hash join is used for unsorted large amounts of data. To join the tables in this case, you need to build something that imitates an index.
Hash join example:
--drop table skittles--drop table mms--запрос для окна слеваcreatetable mms
(idintidentity(1,1),
color varchar(25),
taste varchar(15))
insertinto mms (color, taste)
values ('yellow', 'chocolate')
insertinto mms (color, taste)
values ('red', 'nuts')
insertinto mms (color, taste)
values ('blue', 'strange')
insertinto mms (color, taste)
values ('green', 'chocolate')
insertinto mms (color, taste)
values ('orange', 'chocolate')
createtable skittles
(idintidentity(1,1),
color varchar(25),
taste varchar(15))
insertinto skittles (color, taste)
values ('red', 'cherry')
insertinto skittles (color, taste)
values ('blue', 'strange')
insertinto skittles (color, taste)
values ('yellow', 'lemon')
insertinto skittles (color, taste)
values ('green', 'apple')
insertinto skittles (color, taste)
values ('orange', 'orange')
--запрос для правого окнаselect *
from mms join skittles on
mms.color = skittles.colorFor clarity, let's recall our candies:
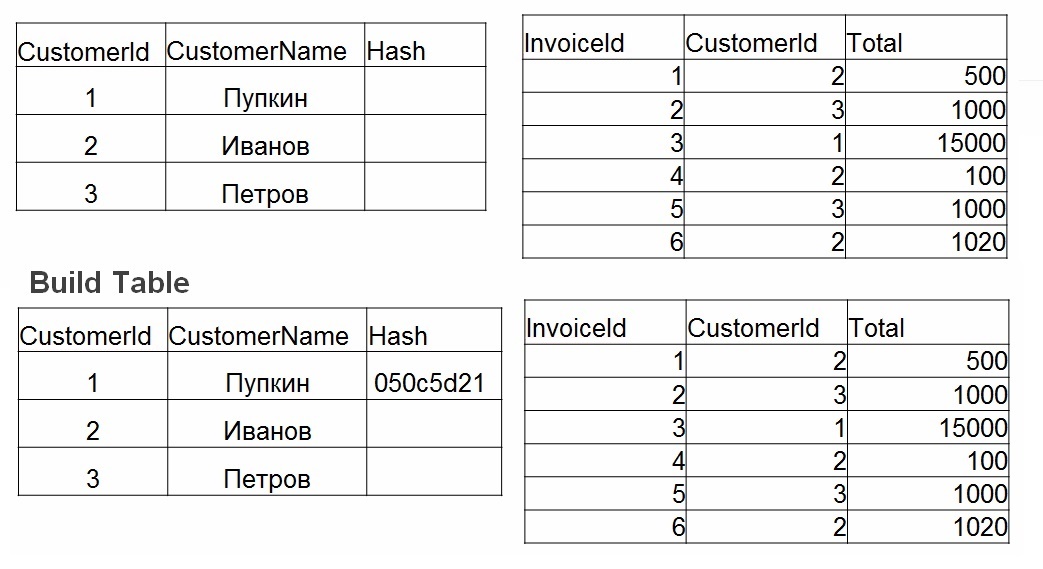
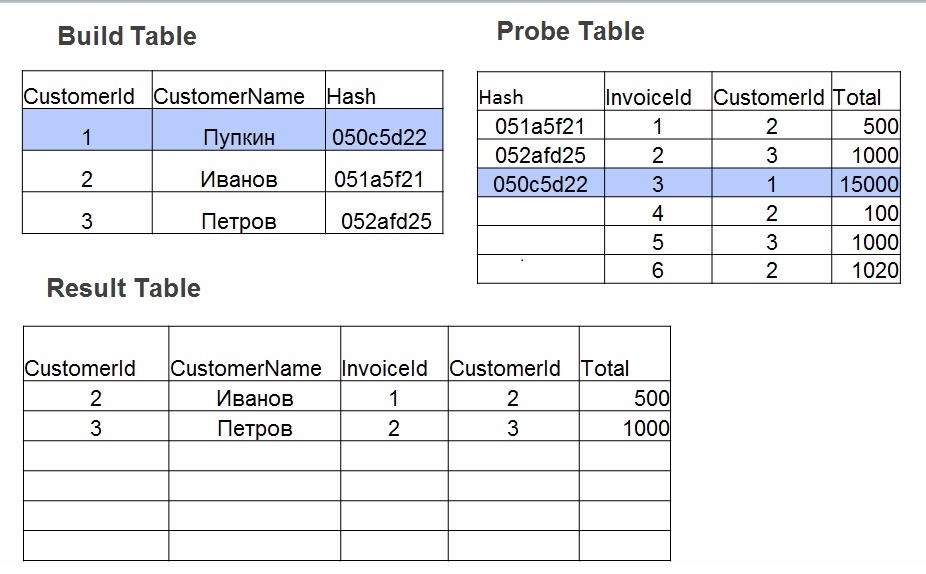
Hash join application involves 2 phases of actions:
- Build - builds a hash table using the smallest table. For each value in the table number 1 is a hash. The value is stored in a hash table, and the calculated hash is used as a key.
- Probe. For each row from table No. 2, the hash value is calculated by the fields that are specified in the join (operator =). Look for a hash in the hash table, check the field values.
When Hash join is good:
- large data set;
- no margin in the margin.
An important point: if there is not enough memory, the recording will go to tempdb - to disk.
Friends, besides the above, in the open lesson included other interesting points that are best seen, watching the video. We offer to visit the open day of the course “MS SQL Server Developer”, where you can ask the teacher all the questions.
PS Teacher Kristina Kucherova expresses appreciation to Jes Schultz Borland for her presentation with the PASS Summitt Execution Plans, which was used in the preparation of the open lesson.