Clodo Cloud Storage
We are pleased to introduce to the Habrahabra community our new service - Cloud Storage . Like all solutions of this class, it is designed to store and quickly distribute static content - including website content.
Those who attended the excellent Highload ++ conference had the opportunity, among other things, to hear our report on how the storage is arranged. A summary of what we talked about, we offer to the distinguished audience of Habrahabr.
The essence of any cloud is the ability to quickly obtain the required amount of resources of a given type on request. There are familiar ones thanks to desktops - disk space, processor power, RAM. Having taken a little of one, another and third (for example, having acquired a virtual machine with 256 megabytes of memory and a disk for a couple of hundred gigabytes), the user hopes to distribute these gigabytes in the form of thousands of small files - and distribute it quickly to any number of clients: obviously with some a special “cloud magic” about which not far-fetched marketers sang to him. In fact, there are other, not so familiar types of resources that you should keep in mind when designing your service - for example, a content distribution or load balancing resource.
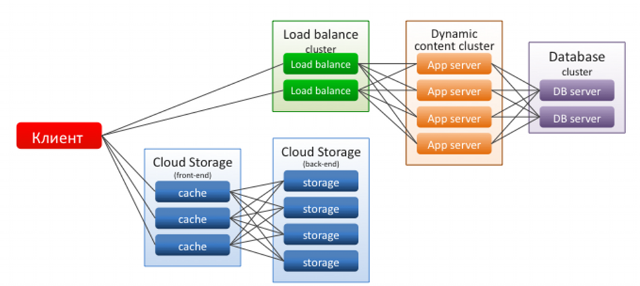
Using the types of entities mentioned above, you can build a solution architecture that, using the traditional LAMP stack, will be designed just to implement the very “cloud magic” and ease of scaling with increasing load. We are systematically implementing what is needed to implement such a scheme.
So, for example, database servers using the usual MySQL, as you know, are difficult to scale horizontally, so it makes sense to scale them vertically - for this we work Scale Server. The application servers accessing them, ideally behind the load balancer, can be scaled horizontally, generating using the APIclone copies. In order to be able to use exact clones, it makes sense to distribute static information through a specially created repository - this allows us not to engage in synchronization, which often does not keep up with content updates.
So, we set ourselves the task of creating a repository:
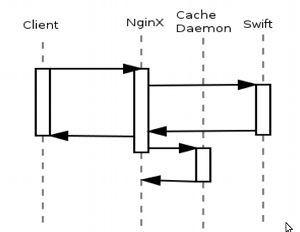
Having decided not to reinvent the wheel, we chose Openstack Swift as the storage, the same storage used by our Western colleagues from Rackspace. The picture explains his device quite well.
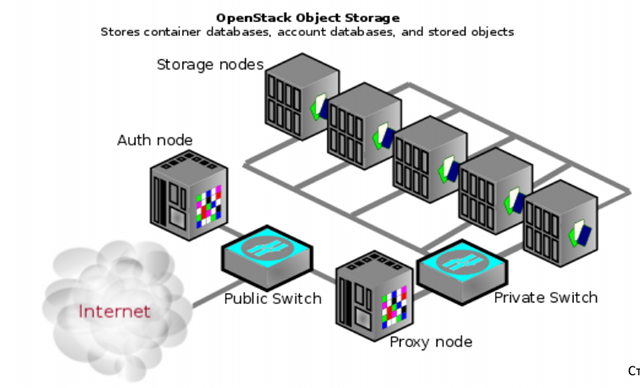
A client from the Internet comes to the authorization node, presents his token there, and depending on the token, he is given access to a particular part of the storage. The storage is flat: the directory structure is set using meta-attributes of files (meta-attributes in Swift provide generally quite rich tools - we can tell more about this if there is such interest).
To get started, we tried a solution entirely based on Swift with Swift Proxy on the front-ends running Pacemaker.
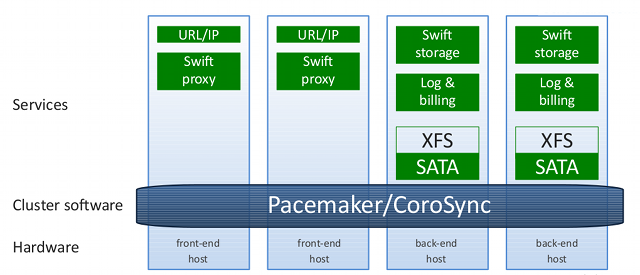
The solution is working, but it began to sink on the processor already at 400 requests per second for the front-end, which in our conditions is absolutely worthless. Therefore, we decided to add NGINX as a caching proxy. We placed cache on SAS disks. Since nginx does not know how to store the cache on several volumes by default, and we did not want to spend expensive SAS disks on overhead RAID 6, we turned to catap and soon we had nginx with a multi-zone cache. This configuration allowed our front-ends to easily withstand 12,000 requests, while resting not on the processor, but on the gigabit channel on the front-end.
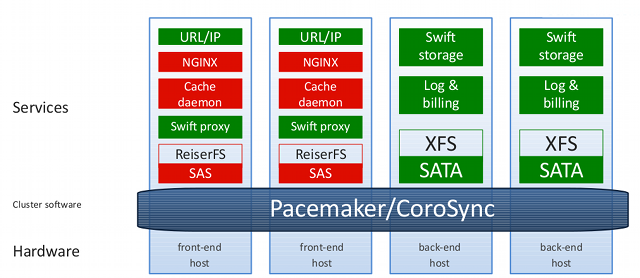
After that, the refinement of the service according to the wishes of customers began. For starters, no one liked public links like
http://cs1.clodo.ru/v1/CLODO_0563290e28e0d6f79a83ab6a84b42b7d/public/logo.gif - everyone wanted something in the spirit of http://st.clodo.ru/logo.gif . In addition to the ability to connect domains, it was necessary to remove the default public container address public from the URL. This was solved by a little "programming on nginx config files".
The next problem is much more thorough. After deleting from the backend, the file remains in the cache and may be available for some time. Our colleagues from Rackspace believe that it is not necessary to solve this problem (and indeed, for all issues of public distribution, they are referred to CDN partners). We decided to try to solve this problem - and the demon Kesha helped us with this.
A charming daemon written in Perl and interacting with nginx via FastCGI, cache cache is invalidated every time data is deleted. At the same time, he tries to show intelligence, and, for example, when deleting a file from a directory, he removes not only the file from the cache, but also the listing of the directory.
We have already outlined several areas of storage development:
Our current solution allows you to have up to 840 TB of disk space, 7 TB of cache and 512 GB of cache in RAM in one storage segment. All this breaks into 30 units in the data center. All this is automatically deployed using Chef on Debian Live, controlled by Pacemaker and the Clodo panel (operations implemented outside of Openstack - for example, linking your domain). In principle, a similar solution can be built for yourself with noticeably less iron and deployed in your own small private cloud.
Cloud storage has been working in production for a month now, and so far, our customers like the fact that it is very simple to use, and its tariffing is the easiest, which can be - 1 kopeck for storing 1 GB for 1 hour and 1 ruble for 1 GB of outgoing traffic. There are no unpredictable loads on processors and RAM and price hikes while increasing the load on the resource: estimating the costs of cloud storage is an order of magnitude easier than using conventional cloud hosting.
PS Pictures in this post are posted on our Cloud Storage.
Those who attended the excellent Highload ++ conference had the opportunity, among other things, to hear our report on how the storage is arranged. A summary of what we talked about, we offer to the distinguished audience of Habrahabr.
The essence of any cloud is the ability to quickly obtain the required amount of resources of a given type on request. There are familiar ones thanks to desktops - disk space, processor power, RAM. Having taken a little of one, another and third (for example, having acquired a virtual machine with 256 megabytes of memory and a disk for a couple of hundred gigabytes), the user hopes to distribute these gigabytes in the form of thousands of small files - and distribute it quickly to any number of clients: obviously with some a special “cloud magic” about which not far-fetched marketers sang to him. In fact, there are other, not so familiar types of resources that you should keep in mind when designing your service - for example, a content distribution or load balancing resource.
Using the types of entities mentioned above, you can build a solution architecture that, using the traditional LAMP stack, will be designed just to implement the very “cloud magic” and ease of scaling with increasing load. We are systematically implementing what is needed to implement such a scheme.
So, for example, database servers using the usual MySQL, as you know, are difficult to scale horizontally, so it makes sense to scale them vertically - for this we work Scale Server. The application servers accessing them, ideally behind the load balancer, can be scaled horizontally, generating using the APIclone copies. In order to be able to use exact clones, it makes sense to distribute static information through a specially created repository - this allows us not to engage in synchronization, which often does not keep up with content updates.
So, we set ourselves the task of creating a repository:
- Reliably storing data;
- With simple data management - including through the API,
since it must be used from program code; - Able to quickly distribute "hot" content via HTTP;
- The interface of interaction familiar to not the most experienced users (FTP, FUSE). Any content manager of the site of the provincial cultural center should be able to upload the file to the repository (yes, we also have such clients);
Having decided not to reinvent the wheel, we chose Openstack Swift as the storage, the same storage used by our Western colleagues from Rackspace. The picture explains his device quite well.
A client from the Internet comes to the authorization node, presents his token there, and depending on the token, he is given access to a particular part of the storage. The storage is flat: the directory structure is set using meta-attributes of files (meta-attributes in Swift provide generally quite rich tools - we can tell more about this if there is such interest).
To get started, we tried a solution entirely based on Swift with Swift Proxy on the front-ends running Pacemaker.
The solution is working, but it began to sink on the processor already at 400 requests per second for the front-end, which in our conditions is absolutely worthless. Therefore, we decided to add NGINX as a caching proxy. We placed cache on SAS disks. Since nginx does not know how to store the cache on several volumes by default, and we did not want to spend expensive SAS disks on overhead RAID 6, we turned to catap and soon we had nginx with a multi-zone cache. This configuration allowed our front-ends to easily withstand 12,000 requests, while resting not on the processor, but on the gigabit channel on the front-end.
After that, the refinement of the service according to the wishes of customers began. For starters, no one liked public links like
http://cs1.clodo.ru/v1/CLODO_0563290e28e0d6f79a83ab6a84b42b7d/public/logo.gif - everyone wanted something in the spirit of http://st.clodo.ru/logo.gif . In addition to the ability to connect domains, it was necessary to remove the default public container address public from the URL. This was solved by a little "programming on nginx config files".
{kind=link}
{kind=link}
The next problem is much more thorough. After deleting from the backend, the file remains in the cache and may be available for some time. Our colleagues from Rackspace believe that it is not necessary to solve this problem (and indeed, for all issues of public distribution, they are referred to CDN partners). We decided to try to solve this problem - and the demon Kesha helped us with this.
A charming daemon written in Perl and interacting with nginx via FastCGI, cache cache is invalidated every time data is deleted. At the same time, he tries to show intelligence, and, for example, when deleting a file from a directory, he removes not only the file from the cache, but also the listing of the directory.
We have already outlined several areas of storage development:
- Possibility for the client to receive the logs of his storage;
- Distribution of media content, streaming;
- Replication between data centers;
- Authorization for pubcookies;
- Enabling all Swift-proxy functionality as a nginx module;
- Full support for HTTP 1.1;
Our current solution allows you to have up to 840 TB of disk space, 7 TB of cache and 512 GB of cache in RAM in one storage segment. All this breaks into 30 units in the data center. All this is automatically deployed using Chef on Debian Live, controlled by Pacemaker and the Clodo panel (operations implemented outside of Openstack - for example, linking your domain). In principle, a similar solution can be built for yourself with noticeably less iron and deployed in your own small private cloud.
Cloud storage has been working in production for a month now, and so far, our customers like the fact that it is very simple to use, and its tariffing is the easiest, which can be - 1 kopeck for storing 1 GB for 1 hour and 1 ruble for 1 GB of outgoing traffic. There are no unpredictable loads on processors and RAM and price hikes while increasing the load on the resource: estimating the costs of cloud storage is an order of magnitude easier than using conventional cloud hosting.
PS Pictures in this post are posted on our Cloud Storage.