Uber Code Generation
Each of us does the routine work. Everyone writes a boilerplate code. What for? Isn't it better to automate this process and work only on interesting tasks? Read this article if you want a computer to do this work for you. This article is based on the transcript of the report by Zack Sweers, the developer of mobile applications Uber, with whom he spoke at the MBLT DEV conference in 2017.

Uber has about 300 mobile application developers. I work in a team called the “mobile platform”. The work of my team is to simplify and improve the process of developing mobile applications as much as possible. We mainly work on internal frameworks, libraries, architectures, and so on. Because of the large staff we have to do large-scale projects that our engineers will need in the future. This may be tomorrow, and maybe next month or even a year.
I would like to demonstrate the value of the code generation process, and also consider a few practical examples. The process itself looks like this:
This is an example of using Kotlin Poet. Kotlin Poet is a library with a good API that generates Kotlin code. So what do we see here?
After code generation, the following is obtained:
The result of code generation is a file with a name, comment, annotation and the name of the author. The question immediately arises: “Why do I need to generate this code if I can do it in a couple of simple steps?” Yes, you are right, but what if I need a thousand such files with different configuration options? What happens if we start changing the values in this code? What if we have a lot of presentations? What if we have a lot of conferences ahead?
As a result, we will come to the conclusion that it will simply be impossible to maintain such a number of files manually - it is necessary to automate. Therefore, the first advantage of code generation is getting rid of routine work.
The second important advantage of automation is infallibility. All people make mistakes. Especially often this happens when we do the same thing. Computers, on the contrary, do such a great job.
Consider a simple example. There is a Person class:
Suppose we want to add serialization to it in JSON. We will do this with the help of the Moshi library , as it is quite simple and great for demonstration. Create a PersonJsonAdapter and inherit from a JsonAdapter with a parameter of type Person:
Next, we implement the fromJson method. It provides a reader for reading information that will be returned to Person at the end. Then we fill in the fields with the name and surname and get the new value of Person:
Next, we look at the data in JSON format, check it and put it in the required fields:
Will it work? Yes, but there is a nuance: inside JSON there should be objects that we read. In order to filter the extra data that may come from the server, add another line of code:
At this point, we successfully go around the area of routine code. In this example, there are only two value fields. However, in this code there are a lot of different areas where you might suddenly fail. Suddenly we made a mistake in the code?
Consider another example:
If you have at least one problem every 10 models or so, this means that you will definitely have difficulties in this area. And this is the case when code generation can really come to your aid. If there are many classes, it will not work without automation, because all people allow typos. With the help of code generation, all tasks will be executed automatically and without errors.
Code generation has other benefits. For example, it gives out information about the code or tells you if something goes wrong. Code generation will be useful at the testing stage. If you use the generated code, you can see how the working code will look like. You can even run code generation during tests to simplify your work.
Conclusion: it is worth considering code generation as a possible solution to get rid of errors.
Now consider the software tools that help with code generation.
There are two main tools for building code:
Now consider a few examples.
Butter Knife is the library that Jake Wharton developed. He is a fairly well-known figure in the developer community. The library is very popular among Android developers, because it helps to avoid a lot of the chore that almost everyone faces.
Usually we initialize the view like this:
With the help of Butterknife it will look like this:
And we can easily add any number of views, while the onCreate method will not overwrite the boilerplate code:
Instead of manually doing this binding each time, you simply add @BindView annotations to these fields, as well as identifiers (IDs) to which they are assigned.
Butter Knife is cool in that it will analyze the code and generate you all its similar sections. It also has excellent scalability for new data. Therefore, if new data appears, there is no need to re-apply onCreate or track something manually. This library is also great for deleting data.
So, what does this system look like from the inside? The view search is performed by code recognition, and this process is performed at the annotation processing stage.
We have the following field:
Judging by this data, they are used in some FooActivity:
It has its own meaning (R.id.title), which acts as a target object. Note that during data processing, this object becomes a constant value within the system:
This is normal. This is what Butter Knife should have access to anyway. The type is a TextView component. The field itself is called the title. If we, for example, make a container class from this data, we get something like this:
So, all these data can be easily obtained during their processing. This is also very similar to what Butter Knife does inside the system.
As a result, this class is generated here:
Here we see that all these pieces of data are going together. As a result, we have the target class ViewBinding from the Underscore java-library. Inside, this system is designed in such a way that every time you create an instance of a class, it immediately performs all this binding to the information (code) that you generated. And all this is pre-statically generated during the processing of annotations, which means that it is technically correct.
Let's return to our software pipeline:
During annotation processing, the system reads these annotations and a ViewBinding class is generated. And then during the execution of the bind method, we perform an identical search for the same class in a simple way: we take its name and append the ViewBinding at the end. By itself, the section with the ViewBinding during processing is rewritten into the specified area using JavaPoet.
RxBindings itself is not responsible for code generation. It does not handle annotations and is not a Gradle plugin. This is a regular library. It provides static factories based on the principle of reactive programming for the Android API. This means that, for example, if you have setOnClickListener, a method will appear for a click that will return a stream (Observable) of events. It acts as a bridge (design pattern).
But in fact, RxBinding has code generation:
In this directory called buildSrc there is a Gradle task, which is called KotlinGenTask. This means that all this is actually created by code generation. RxBinding has implementations in Java. It also has Kotlin artifacts that contain extension functions for all target types. And all this is very strictly subject to the rules. For example, you can generate all Kotlin extension functions, and you do not have to control them individually.
What does this look like in reality?
Here is a completely classic RxBinding method. Here are returned Observable objects. The method is called clicks. Work with click-events occurs under the hood. Omit the extra code fragments to keep the example readable. In Kotlin it looks like this:
This extension function returns Observable objects. In the internal structure of the program, it directly calls the familiar Java interface. In Kotlin you will have to change this to the type of Unit:
That is, in Java, it looks like this:
And so - Kotlin-code:
We have an RxView class that contains this method. We can substitute the appropriate data fragments in the target attribute, in the name attribute with the name of the method and in the type that we extend, as well as in the type of the return value. All this information will be enough to start writing these methods:
Now we can directly substitute these fragments into the generated Kotlin code inside the program. Here is the result:
Over Service Gen, we are working in Uber. If you work in a company and deal with general characteristics and a common software interface for both the backend and the client side, then it makes no sense to manually create models and services regardless of whether you are developing Android, iOS or web applications. for team work.
We use Google’s AutoValue library for object models. It processes annotations, analyzes data, and generates a two-line hash code, the equals () method, and other implementations. It is also responsible for supporting extensions.
We have an object of type Rider:
We have lines with ID, firstname, lastname and address. We use the Retrofit and OkHttp libraries to work with the network and JSON as the data format. We also use RxJava for reactive programming. This is our generated API service:
We can write all this manually if we want to. And for a long period of time we did. But it takes a lot of time. In the end - it is costly in terms of time and money.
The last task of my team is to create a text editor from scratch. We decided to no longer write manually the code, which later falls into the network, so we use Thrift . It is something like a programming language and protocol at the same time. Uber uses Thrift as a language for technical specifications.
In Thrift, we define API contracts between the backend and the client side, and then simply generate the appropriate code. To parse the data we use the Thrifty library , and for code generation - JavaPoet. At the end, we generate implementations using AutoValue:
We do all the work in JSON. There is an extension called AutoValue Moshi , which can be added to AutoValue classes using the static jsonAdapter method:
Thrift helps in the development of services:
We also have to add some metadata here to let us know what end result we want to achieve:
After code generation, we will get our service:
But this is only one of the possible results. One model. As we know from experience, no one has ever used only one model. We have a lot of models that generate code for our services:
At the moment we have about 5-6 applications. And they have a lot of services. And they all go through the same software pipeline. Writing all this by hand would be insane.
In serialization in JSON, “adapter” does not need to be registered in Moshi, and if you use JSON, then you do not need to register in JSON. It is also doubtful to suggest employees to carry out deserialization through code rewriting via a DI-graph.
But we work with Java, so we can use the Factory pattern, which we generate through the Fractory library . We can generate this because we know about these types before the compilation has occurred. Fractory generates an adapter like this:
The generated code does not look very good. If it cuts the eye, it can be rewritten manually.
Here you can see the previously mentioned types with the names of services. The system will automatically determine which adapters to select, and call them. But here we face another problem. We have 6000 such adapters. Even if you separate them among themselves within the same template, the “Eats” or “Driver” model will fall into the “Rider” model or will be in its application. The code will stretch. After a certain moment, it cannot even fit in the .dex file. Therefore, we need to somehow separate the adapters:

Finally, we will analyze the code in advance and create a working subproject for it, as in Gradle:

In the internal structure, these dependencies become dependencies Gradle. Items using the Rider app are now dependent on it. With it, they will form the models they need. As a result, our task will be solved, and all this will be governed by the system of building code inside the program.
But here we face another problem: now we have n-number of models of factories. All of them are compiled into various objects:
During annotation processing, it will not be possible to read only annotations to external dependencies and do additional code generation only on them.
Solution: we have some support in the Fractory library, which helps us with one tricky trick. It is contained in the data binding process. Enter the metadata using the classpath parameter in the Java archive for further storage:
Now every time you need to use them in the application, go to the classpath directory filter with these files, and then extract them from there in JSON format to find out which dependencies are available.
We have a Thrift . The data from there goes to Thrifty and passes the parsing. Then they go through a code generation program, which we call Jenga . It produces files in Java format. All this happens before the preliminary stage of processing or before compilation. And during the compilation process, annotations are processed. It is the turn of the AutoValue to generate the implementation. He also calls AutoValue Moshi to provide JSON support. Participates in this and Fractory . Everything happens during the compilation process. The process is preceded by a component of the creation of the project itself, which, first of all, generates the sub-projects Gradle .
Now that you see the big picture, you begin to notice the tools that were mentioned earlier. So, for example, there is Gradle, template creation, AutoValue, JavaPoet for code generation. All tools are not only useful in their own right, but also in combination with each other.
Need to tell about the pitfalls. The most obvious minus is bloat of the code and loss of control over it. For example, Dagger takes about 10% of all code in an application. Models occupy a significantly larger share - about 25%.
In Uber, we are trying to solve a problem by discarding unnecessary code. We have to conduct a certain statistical analysis of the code and understand which areas are really involved in the work. When we figure this out, we can make some transformations and see what comes of it.
We expect to reduce the number of generated models by about 40%. This will help speed up the installation and operation of applications, as well as save us money.
Code generation certainly speeds up development, but the timing also depends on the tools that the team uses. For example, if you work in Gradle, most likely you do it at a measured pace. The fact is that Gradle generates models once a day, and not when the developer wants.
September 28, the 5th International Conference of Mobile Developers MBLT DEV . Will start in Moscow . 800 participants, top speakers, quizzes and puzzles for those who are interested in developing for Android and iOS. The conference organizers are e-Legion and RAEC. You can become a member or partner of MBLT DEV 2018 on the conference website .

Uber has about 300 mobile application developers. I work in a team called the “mobile platform”. The work of my team is to simplify and improve the process of developing mobile applications as much as possible. We mainly work on internal frameworks, libraries, architectures, and so on. Because of the large staff we have to do large-scale projects that our engineers will need in the future. This may be tomorrow, and maybe next month or even a year.
Code Generation for Automation
I would like to demonstrate the value of the code generation process, and also consider a few practical examples. The process itself looks like this:
FileSpec.builder("", "Presentation")
.addComment("Codegeneratingyourwaytohappiness.")
.addAnnotation(AnnotationSpec.builder(Author::class).addMember("name", "%S", "ZacSweers")
.useSiteTarget(FILE)
.build())
.build()
This is an example of using Kotlin Poet. Kotlin Poet is a library with a good API that generates Kotlin code. So what do we see here?
- FileSpec.builder creates a file called “ Presentation ”.
- .addComment () - adds a comment to the generated code.
- .addAnnotation () - adds annotation with type Author .
- .addMember () - adds the variable “ name ” with the parameter, in our case it is “ Zac Sweers ”. % S is the parameter type.
- .useSiteTarget () - sets SiteTarget.
- .build () - completes the description of the code that will be generated.
After code generation, the following is obtained:
Presentation.kt
// Code generating your way to happiness.@file:Author(name = "Zac Sweers")The result of code generation is a file with a name, comment, annotation and the name of the author. The question immediately arises: “Why do I need to generate this code if I can do it in a couple of simple steps?” Yes, you are right, but what if I need a thousand such files with different configuration options? What happens if we start changing the values in this code? What if we have a lot of presentations? What if we have a lot of conferences ahead?
conferences
.flatMap { it.presentations }
.onEach { (presentationName, comment, author) ->
FileSpec.builder("", presentationName)
.addComment(comment)
.addAnnotation(AnnotationSpec.builder(Author::class)
.addMember("name", "%S", author)
.useSiteTarget(FILE)
.build())
.build()
}
As a result, we will come to the conclusion that it will simply be impossible to maintain such a number of files manually - it is necessary to automate. Therefore, the first advantage of code generation is getting rid of routine work.
Error-free code generation
The second important advantage of automation is infallibility. All people make mistakes. Especially often this happens when we do the same thing. Computers, on the contrary, do such a great job.
Consider a simple example. There is a Person class:
classPerson(val firstName: String, val lastName: String)
Suppose we want to add serialization to it in JSON. We will do this with the help of the Moshi library , as it is quite simple and great for demonstration. Create a PersonJsonAdapter and inherit from a JsonAdapter with a parameter of type Person:
classPerson(val firstName: String, val lastName: String)
classPersonJsonAdapter : JsonAdapter<Person>() {
}
Next, we implement the fromJson method. It provides a reader for reading information that will be returned to Person at the end. Then we fill in the fields with the name and surname and get the new value of Person:
classPerson(val firstName: String, val lastName: String)
classPersonJsonAdapter : JsonAdapter<Person>() {
overridefunfromJson(reader: JsonReader): Person? {
lateinitvar firstName: String
lateinitvar lastName: String
return Person(firstName, lastName)
}
}
Next, we look at the data in JSON format, check it and put it in the required fields:
classPerson(val firstName: String, val lastName: String)
classPersonJsonAdapter : JsonAdapter<Person>() {
overridefunfromJson(reader: JsonReader): Person? {
lateinitvar firstName: String
lateinitvar lastName: String
while (reader.hasNext()) {
when (reader.nextName()) {
"firstName" -> firstName = reader.nextString()
"lastName" -> lastName = reader.nextString()
}
}
return Person(firstName, lastName)
}
}
Will it work? Yes, but there is a nuance: inside JSON there should be objects that we read. In order to filter the extra data that may come from the server, add another line of code:
classPerson(val firstName: String, val lastName: String)
classPersonJsonAdapter : JsonAdapter<Person>() {
overridefunfromJson(reader: JsonReader): Person? {
lateinitvar firstName: String
lateinitvar lastName: String
while (reader.hasNext()) {
when (reader.nextName()) {
"firstName" -> firstName = reader.nextString()
"lastName" -> lastName = reader.nextString()
else -> reader.skipValue()
}
}
return Person(firstName, lastName)
}
}
At this point, we successfully go around the area of routine code. In this example, there are only two value fields. However, in this code there are a lot of different areas where you might suddenly fail. Suddenly we made a mistake in the code?
Consider another example:
classPerson(val firstName: String, val lastName: String)
classCity(val name: String, val country: String)
classVehicle(val licensePlate: String)
classRestaurant(val type: String, val address: Address)
classPayment(val cardNumber: String, val type: String)
classTipAmount(val value: Double)
classRating(val numStars: Int)
classCorrectness(val confidence: Double)
If you have at least one problem every 10 models or so, this means that you will definitely have difficulties in this area. And this is the case when code generation can really come to your aid. If there are many classes, it will not work without automation, because all people allow typos. With the help of code generation, all tasks will be executed automatically and without errors.
Code generation has other benefits. For example, it gives out information about the code or tells you if something goes wrong. Code generation will be useful at the testing stage. If you use the generated code, you can see how the working code will look like. You can even run code generation during tests to simplify your work.
Conclusion: it is worth considering code generation as a possible solution to get rid of errors.
Now consider the software tools that help with code generation.
Instruments
- Libraries JavaPoet and KotlinPoet for Java and Kotlin, respectively. These are code generation standards.
- Templates A popular example of templating for Java is Apache Velocity , and for iOS, Handlebars .
- SPI - Service Processor Interface. It is built into Java and allows you to create and apply an interface, and then declare it in a JAR. When the program runs, you can get all the ready-made interface implementations.
- Compile Testing is a library from Google that helps to conduct compilation testing. In the framework of code generation, this means: “This is what I expected, but what I eventually received.” The compilation in memory will start, and then the system will tell you whether this process was completed or what errors occurred. If the compilation has been completed, you will be asked to compare the result with your expectations. The comparison is based on the compiled code, so do not worry about things like code formatting or something else.
Code Building Tools
There are two main tools for building code:
- Annotation Processing - you can write annotations in code and ask the program for more information about them. The compiler will display the information before it finishes working with the source code.
- Gradle is a system for building applications with multiple hooks (a hook is intercepting a function call) in its life cycle of building code. It is widely used when developing on Android. It also allows you to apply code generation to source code that does not depend on current source codes.
Now consider a few examples.
Butter knife
Butter Knife is the library that Jake Wharton developed. He is a fairly well-known figure in the developer community. The library is very popular among Android developers, because it helps to avoid a lot of the chore that almost everyone faces.
Usually we initialize the view like this:
TextView title;
ImageView icon;
voidonCreate(Bundle savedInstanceState){
title = findViewById(R.id.title);
icon = findViewById(R.id.icon);
}
With the help of Butterknife it will look like this:
@BindView(R.id.title) TextView title;
@BindView(R.id.icon) ImageView icon;
voidonCreate(Bundle savedInstanceState){
ButterKnife.bind(this);
}
And we can easily add any number of views, while the onCreate method will not overwrite the boilerplate code:
@BindView(R.id.title) TextView title;
@BindView(R.id.text) TextView text;
@BindView(R.id.icon) ImageView icon;
@BindView(R.id.button) Button button;
@BindView(R.id.next) Button next;
@BindView(R.id.back) Button back;
@BindView(R.id.open) Button open;
voidonCreate(Bundle savedInstanceState){
ButterKnife.bind(this);
}
Instead of manually doing this binding each time, you simply add @BindView annotations to these fields, as well as identifiers (IDs) to which they are assigned.
Butter Knife is cool in that it will analyze the code and generate you all its similar sections. It also has excellent scalability for new data. Therefore, if new data appears, there is no need to re-apply onCreate or track something manually. This library is also great for deleting data.
So, what does this system look like from the inside? The view search is performed by code recognition, and this process is performed at the annotation processing stage.
We have the following field:
@BindView(R.id.title) TextView title;
Judging by this data, they are used in some FooActivity:
// FooActivity@BindView(R.id.title) TextView title;
It has its own meaning (R.id.title), which acts as a target object. Note that during data processing, this object becomes a constant value within the system:
// FooActivity@BindView(2131361859) TextView title;
This is normal. This is what Butter Knife should have access to anyway. The type is a TextView component. The field itself is called the title. If we, for example, make a container class from this data, we get something like this:
ViewBinding(
target = "FooActivity",
id = 2131361859,
name = "title",
type = "field",
viewType = TextView.class
)
So, all these data can be easily obtained during their processing. This is also very similar to what Butter Knife does inside the system.
As a result, this class is generated here:
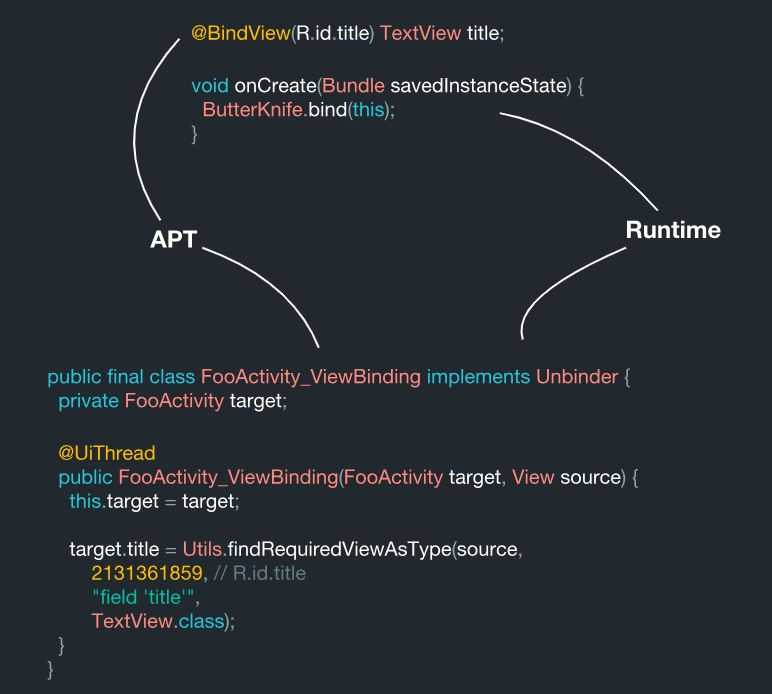
publicfinalclassFooActivity_ViewBindingimplementsUnbinder{
private FooActivity target;
@UiThreadpublicFooActivity_ViewBinding(FooActivity target, View source){
this.target = target;
target.title = Utils.findRequiredViewAsType(source,
2131361859, // R.id.title"field 'title'",
TextView.class);
}
}
Here we see that all these pieces of data are going together. As a result, we have the target class ViewBinding from the Underscore java-library. Inside, this system is designed in such a way that every time you create an instance of a class, it immediately performs all this binding to the information (code) that you generated. And all this is pre-statically generated during the processing of annotations, which means that it is technically correct.
Let's return to our software pipeline:
During annotation processing, the system reads these annotations and a ViewBinding class is generated. And then during the execution of the bind method, we perform an identical search for the same class in a simple way: we take its name and append the ViewBinding at the end. By itself, the section with the ViewBinding during processing is rewritten into the specified area using JavaPoet.
Rxbindings
RxBindings itself is not responsible for code generation. It does not handle annotations and is not a Gradle plugin. This is a regular library. It provides static factories based on the principle of reactive programming for the Android API. This means that, for example, if you have setOnClickListener, a method will appear for a click that will return a stream (Observable) of events. It acts as a bridge (design pattern).
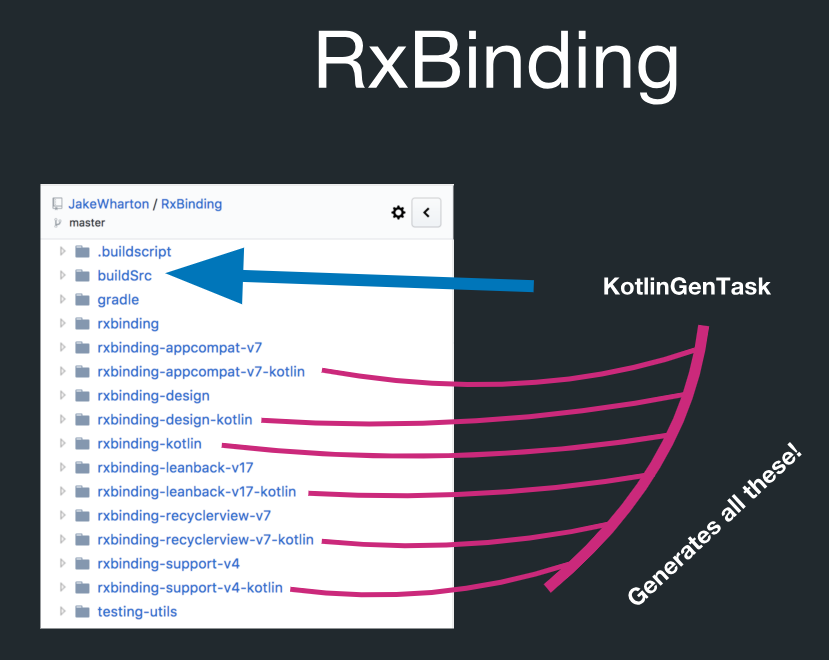
But in fact, RxBinding has code generation:
In this directory called buildSrc there is a Gradle task, which is called KotlinGenTask. This means that all this is actually created by code generation. RxBinding has implementations in Java. It also has Kotlin artifacts that contain extension functions for all target types. And all this is very strictly subject to the rules. For example, you can generate all Kotlin extension functions, and you do not have to control them individually.
What does this look like in reality?
publicstatic Observable<Object> clicks(View view){
returnnew ViewClickObservable(view);
}
Here is a completely classic RxBinding method. Here are returned Observable objects. The method is called clicks. Work with click-events occurs under the hood. Omit the extra code fragments to keep the example readable. In Kotlin it looks like this:
fun View.clicks(): Observable<Object> = RxView.clicks(this)
This extension function returns Observable objects. In the internal structure of the program, it directly calls the familiar Java interface. In Kotlin you will have to change this to the type of Unit:
fun View.clicks(): Observable<Unit> = RxView.clicks(this)
That is, in Java, it looks like this:
publicstatic Observable<Object> clicks(View view){
returnnew ViewClickObservable(view);
}
And so - Kotlin-code:
fun View.clicks(): Observable<Unit> = RxView.clicks(this)
We have an RxView class that contains this method. We can substitute the appropriate data fragments in the target attribute, in the name attribute with the name of the method and in the type that we extend, as well as in the type of the return value. All this information will be enough to start writing these methods:
BindingMethod(
target = "RxView",
name = "clicks",
type = View.class,
returnType = "Observable<Unit>"
)
Now we can directly substitute these fragments into the generated Kotlin code inside the program. Here is the result:
fun View.clicks(): Observable<Unit> = RxView.clicks(this)
Service Gen
Over Service Gen, we are working in Uber. If you work in a company and deal with general characteristics and a common software interface for both the backend and the client side, then it makes no sense to manually create models and services regardless of whether you are developing Android, iOS or web applications. for team work.
We use Google’s AutoValue library for object models. It processes annotations, analyzes data, and generates a two-line hash code, the equals () method, and other implementations. It is also responsible for supporting extensions.
We have an object of type Rider:
@AutoValueabstractclassRider{
abstract String uuid();
abstract String firstName();
abstract String lastName();
abstract Address address();
}
We have lines with ID, firstname, lastname and address. We use the Retrofit and OkHttp libraries to work with the network and JSON as the data format. We also use RxJava for reactive programming. This is our generated API service:
interfaceUberService{
@GET("/rider")
Rider getRider()
}
We can write all this manually if we want to. And for a long period of time we did. But it takes a lot of time. In the end - it is costly in terms of time and money.
What is Uber doing today?
The last task of my team is to create a text editor from scratch. We decided to no longer write manually the code, which later falls into the network, so we use Thrift . It is something like a programming language and protocol at the same time. Uber uses Thrift as a language for technical specifications.
structRider{
1: required string uuid;
2: required string firstName;
3: required string lastName;
4: optionalAddress address;
}
In Thrift, we define API contracts between the backend and the client side, and then simply generate the appropriate code. To parse the data we use the Thrifty library , and for code generation - JavaPoet. At the end, we generate implementations using AutoValue:
@AutoValueabstractclassRider{
abstract String uuid();
abstract String firstName();
abstract String lastName();
abstract Address address();
}
We do all the work in JSON. There is an extension called AutoValue Moshi , which can be added to AutoValue classes using the static jsonAdapter method:
@AutoValueabstractclassRider{
abstract String uuid();
abstract String firstName();
abstract String lastName();
abstract Address address();
static JsonAdapter<Rider> jsonAdapter(Moshi moshi){
returnnew AutoValue_Rider.JsonAdapter(moshi);
}
}Thrift helps in the development of services:
service UberService {
Rider getRider()
}
We also have to add some metadata here to let us know what end result we want to achieve:
service UberService {
Rider getRider() (path="/rider")
}
After code generation, we will get our service:
interfaceUberService{
@GET("/rider")
Single<Rider> getRider();
}
But this is only one of the possible results. One model. As we know from experience, no one has ever used only one model. We have a lot of models that generate code for our services:
structRiderstructCitystructVehiclestructRestaurantstructPaymentstructTipAmountstructRating// And 6000 moreAt the moment we have about 5-6 applications. And they have a lot of services. And they all go through the same software pipeline. Writing all this by hand would be insane.
In serialization in JSON, “adapter” does not need to be registered in Moshi, and if you use JSON, then you do not need to register in JSON. It is also doubtful to suggest employees to carry out deserialization through code rewriting via a DI-graph.
But we work with Java, so we can use the Factory pattern, which we generate through the Fractory library . We can generate this because we know about these types before the compilation has occurred. Fractory generates an adapter like this:
classModelsAdapterFactoryimplementsJsonAdapter.Factory{
@Overridepublic JsonAdapter<?> create(Type type, Set<? extends Annotation> annotations, Moshi moshi) {
Class<?> rawType = Types.getRawType(type);
if (rawType.isAssignableFrom(Rider.class)) {
return Rider.adapter(moshi);
} elseif (rawType.isAssignableFrom(City.class)) {
return City.adapter(moshi);
} elseif (rawType.isAssignableFrom(Vehicle.class)) {
return Vehicle.adapter(moshi);
}
// Etc etcreturnnull;
}
}
The generated code does not look very good. If it cuts the eye, it can be rewritten manually.
Here you can see the previously mentioned types with the names of services. The system will automatically determine which adapters to select, and call them. But here we face another problem. We have 6000 such adapters. Even if you separate them among themselves within the same template, the “Eats” or “Driver” model will fall into the “Rider” model or will be in its application. The code will stretch. After a certain moment, it cannot even fit in the .dex file. Therefore, we need to somehow separate the adapters:
Finally, we will analyze the code in advance and create a working subproject for it, as in Gradle:
In the internal structure, these dependencies become dependencies Gradle. Items using the Rider app are now dependent on it. With it, they will form the models they need. As a result, our task will be solved, and all this will be governed by the system of building code inside the program.
But here we face another problem: now we have n-number of models of factories. All of them are compiled into various objects:
classRiderModelFactoryclassGiftCardModelFactoryclassPricingModelFactoryclassDriverModelFactoryclassEATSModelFactoryclassPaymentsModelFactoryDuring annotation processing, it will not be possible to read only annotations to external dependencies and do additional code generation only on them.
Solution: we have some support in the Fractory library, which helps us with one tricky trick. It is contained in the data binding process. Enter the metadata using the classpath parameter in the Java archive for further storage:
classRiderModelFactory// -> json// -> ridermodelfactory-fractory.binclassMyAppGlobalFactory// Delegates to all discovered fractoriesNow every time you need to use them in the application, go to the classpath directory filter with these files, and then extract them from there in JSON format to find out which dependencies are available.
How it all fits together
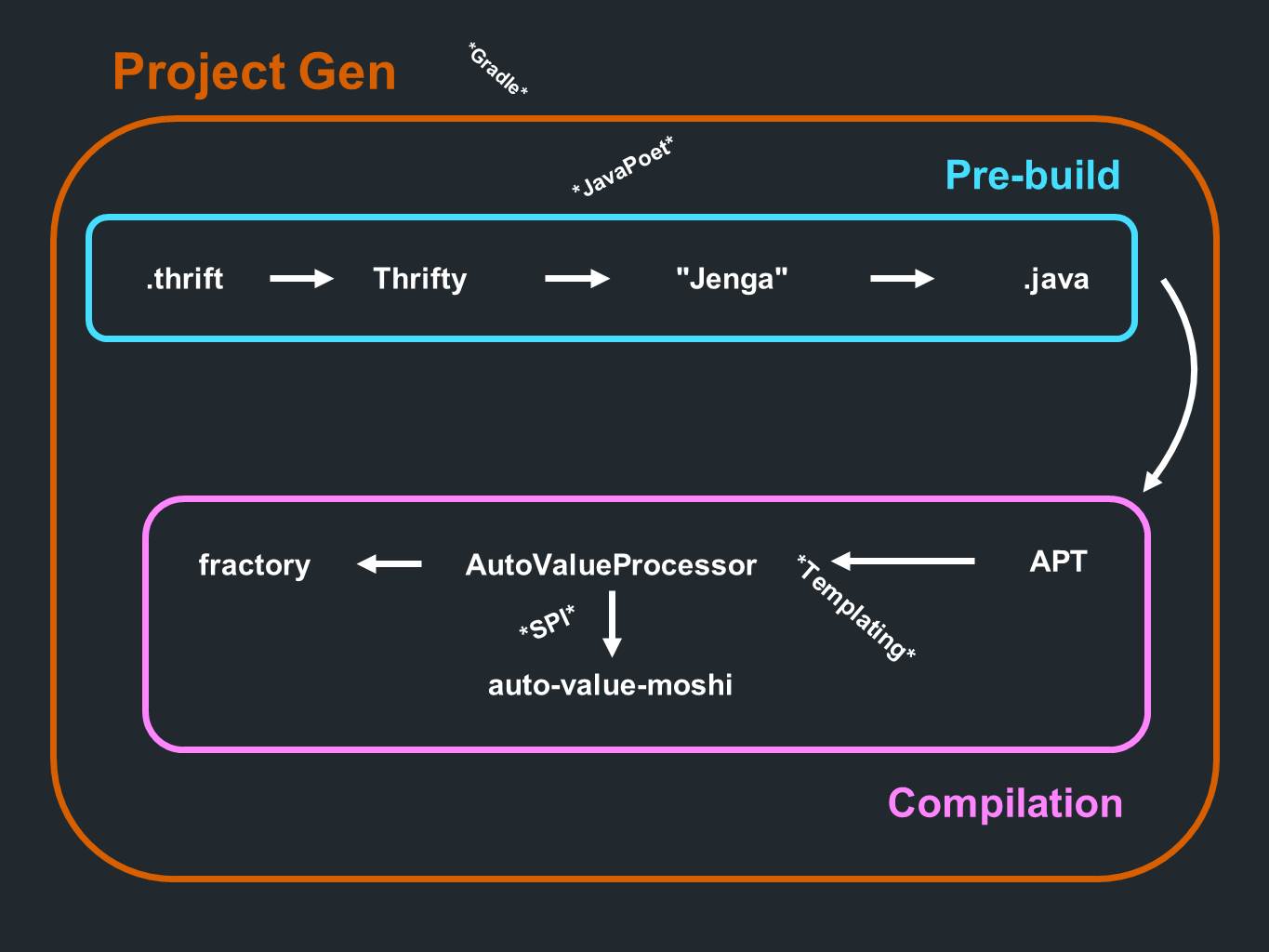
We have a Thrift . The data from there goes to Thrifty and passes the parsing. Then they go through a code generation program, which we call Jenga . It produces files in Java format. All this happens before the preliminary stage of processing or before compilation. And during the compilation process, annotations are processed. It is the turn of the AutoValue to generate the implementation. He also calls AutoValue Moshi to provide JSON support. Participates in this and Fractory . Everything happens during the compilation process. The process is preceded by a component of the creation of the project itself, which, first of all, generates the sub-projects Gradle .
Now that you see the big picture, you begin to notice the tools that were mentioned earlier. So, for example, there is Gradle, template creation, AutoValue, JavaPoet for code generation. All tools are not only useful in their own right, but also in combination with each other.
Cons of code generation
Need to tell about the pitfalls. The most obvious minus is bloat of the code and loss of control over it. For example, Dagger takes about 10% of all code in an application. Models occupy a significantly larger share - about 25%.
In Uber, we are trying to solve a problem by discarding unnecessary code. We have to conduct a certain statistical analysis of the code and understand which areas are really involved in the work. When we figure this out, we can make some transformations and see what comes of it.
We expect to reduce the number of generated models by about 40%. This will help speed up the installation and operation of applications, as well as save us money.
How code generation affects project development timelines
Code generation certainly speeds up development, but the timing also depends on the tools that the team uses. For example, if you work in Gradle, most likely you do it at a measured pace. The fact is that Gradle generates models once a day, and not when the developer wants.
Learn more about development in Uber and other top companies.
September 28, the 5th International Conference of Mobile Developers MBLT DEV . Will start in Moscow . 800 participants, top speakers, quizzes and puzzles for those who are interested in developing for Android and iOS. The conference organizers are e-Legion and RAEC. You can become a member or partner of MBLT DEV 2018 on the conference website .