Asterisk + UniMRCP + VoiceNavigator. Speech synthesis and recognition in Asterisk. Part 1
Part 2
Part 3
Part 4
Considering the increased interest of the community in Asterisk, I decided to contribute and talk about building voice menus using speech synthesis and recognition.
The article is intended for specialists with experience in building IVR in Asterisk and having an understanding of voice self-service systems.
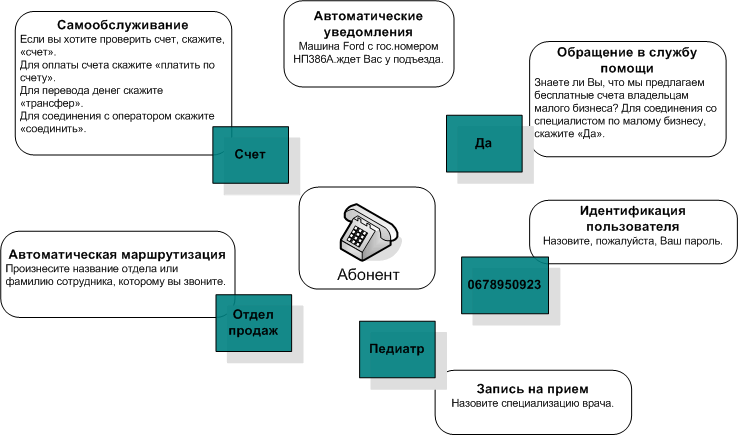
GHS (voice self-service systems) significantly expand the ability to create voice applications and allow the user to receive information and order services independently, without operator intervention. This can be routing calls, requesting and issuing information on a flight schedule, the state of a bank account, ordering a taxi, making an appointment with a doctor, etc.
Recognition eliminates the need for linear menus created with DTMF, speaks human language to the system, and easily creates multiple-choice menus.
The synthesis greatly simplifies the work with dynamically changing information and large amounts of text data.
Below I will describe the integration of Asterisk with VoiceNavigator , as I am an employee of a company that develops it and is engaged in, inter alia, support and integration with small platforms (Asterisk, FreeSWITCH). I must say that the solution is paid. There are no really working OpenSource applications for the synthesis and recognition of Russian speech.
The industry standard for implementing synthesis and recognition functionality is the use of the MRCP protocol .
Asterisk uses the UniMRCP library for this .
UniMRCP is an open source cross-platform software that includes the necessary tools to implement the functions of the MRCP client and MRCP server.
The project is slowly developing and, as far as I know, this is the only OpenSource solution for working with the MRCP protocol for today. Supports Asterisk (all versions starting with 1.4) and FreeSWITCH.
VoiceNavigator is a software package that is installed on a separate Windows machine and provides access to synthesis and recognition engines using the MRCP protocol.
It includes the STC MRCP Server, the STC TTS speech synthesis suite, and the STC ASR speech recognition suite.
The MRCP server controls the interaction between the used voice platform and the ASR and TTS modules. STC MRCP Server supports the following voice platforms: Asterisk, FreeSWITCH, Avaya Voice Portal, Genesys Voice Platform, Cisco Unified CCX, Siemens OpenScape.
MRCP requests are sent by RTSP protocol commands .
To transmit audio data, the RTP protocol is used .
The voice platform through the MRCP server requests access to speech recognition and synthesis modules, depending on this, various interaction schemes are used.
The ASR module deals with speech recognition. A key concept for ASR is the SRGS grammar .
SRGS (speech recognition grammar specification) is a standard that describes the structure of the grammar used in speech recognition. SRGS allows you to specify words or phrases that can be recognized by the speech engine.
The creation of grammars is a separate science and, if there is interest, I am ready to write a separate article.
TTS module uses a markup language SSML is (Speech Synthesis, Markup the Language) based on XML for use in speech synthesis applications.
Synthesis is controlled by tags. With their help, you can determine the pronunciation, control intonation, speed, volume, pause length, reading rules, etc.
An example of the synthesis of speech from the MDGs can be heard here vitalvoice.ru/demo
The call arrives on the voice platform.
The voice platform activates the script of the voice menu, according to which further interaction with the subscriber takes place.
The scenario of the voice menu determines: when the system should read the instructions to the subscriber, ask a question and how to process his answer.
VoiceNavigator receives speech recognition and speech synthesis requests from the voice platform, executes them, and returns the result of execution using the MRCP protocol .
In speech recognition, the voice platform transmits the SRGS grammar and digitized speech and receives a response in the form of NLSML .
In speech synthesis, the voice platform transmits plain text or SSML and receives synthesized speech in response.
Let's move on to the practical part.
The following describes the installation of UniMRCP in the native for Asterisk CentOS. When installing on other OSs, there may be slight differences.
Download the latest version of uni-ast-package-0.3.2 from the official site .
The package contains:
• Asterisk version 1.6.2.9 - work with this version has been tested by the UniMRCP developer;
• Asterisk-UniMRCP-Bridge 0.1.0 - a bridge for pairing Asterisk and UniMRCP module;
• UniMRCP - Module UniMRCP 1.0.0;
• APR - Apache Portable Runtime 1.4.2;
• APR-Util - Apache Portable Runtime Utility Library 1.3.9;
• Sofia-SIP- SIP User-Agent library 12.1.10.
Installation requires autoconf, libtool, gcc, pkg-config.
After unpacking, we see three scripts in the root of the folder:
ast-install.sh - installs the Asterisk that comes with the delivery if it is not installed on the system.
uni-install.sh - installs UniMRCP
connector-install.sh - installs the bridge between Asterisk and UniMRCP.
We launch them in this order (if Asterisk is installed - ast-install.sh is not necessary) and answer all questions in the affirmative.
We see that everything is installed without errors.
In my experience, errors occur only when dependencies are not satisfied. If Asterisk was previously built from source, then all the dependencies should already be satisfied and the installation will be quick and easy.
After installation, Asterisk got 2 new modules res_speech_unimrcp.so and app_unimrcp.so, and the dialplan got the commands MRCPSynth and MRCPRecog. You can verify the installation is correct by entering in the Asterisk console: Before you can work with synthesis and recognition resources, you must connect them. The file /etc/asterisk/mrcp.conf is used to connect to the MRCP server. You can edit its contents or replace it with the following (comments have been added to explain the most important parameters): After restarting Asterisk, the profile will be activated and the system is ready to work and create the first voice application. As described earlier, Asterisk uses the functions MRCPSynth and MRCPRecog of the app_unimrcp.so library to work:

The MRCPSynth function has the following format:
MRCPSynth (text, options), where
text is the text to synthesize (text \ SSML),
options are synthesis parameters.
Synthesis parameters:
p - Connection profile to the synthesis resource, contained in the file mrcp.conf
i - The numbers that are pressed on the phone, the synthesis will be interrupted
f - File name for recording synthesized speech (recording is made in raw, recording is not performed if the parameter or the file name is not specified)
v - Voice that needs to be synthesized, for example, “Maria8000”.
plain-text:
SSML: The advantage of using SSML over plain-text is the ability to use various tags (voice, speed and expressiveness of speech, pauses, interpretation of text, etc.).
The MRCPRecog function has the following format:
MRCPRecog (grammar, options), where
grammar is the grammar (URL \ SRGS), is specified by a link to a file located on the http server or directly in the function body.
options - recognition options.
Recognition parameters:
p - Connection profile to the recognition resource, contained in the file mrcp.conf
i - DTMF code digits, upon receipt of which recognition will be interrupted.
If the value is “any” or other characters, recognition will be interrupted when they are received, and the character will be returned to the dialing plan.
f - The name of the file to play as invitation
b- Ability to interrupt the file being played (barge-in mode) and start recognition (you cannot interrupt = 0, you can interrupt and speech detection is performed by ASR engine = 1, you can interrupt and speech detection is performed by Asterisk = 2)
t - Time, after which the recognition system can interrupt the recognition procedure with the recognition-timeout (003) code, if recognition has begun, and there is not a single recognition option. The value is specified in milliseconds in the range [0..MAXTIMEOUT].
ct - Threshold of confident recognition (0.0 - 1.0).
If the confidence-level returned during recognition is less than confidence-threshold, then the result of recognition is no match.
sl- Sensitivity to non-dictionary commands. (0.0 - 1.0). The higher the value, the higher the sensitivity to noise.
nb - Defines the number of returned recognition results. N recognition results are returned, with a confidence level greater than confidence-threshold. Default value = 1.
nit - The time after which the recognition system can interrupt the recognition procedure, with the code no-input-timeout (002), if recognition starts and speech is not found. The value is specified in milliseconds, in the range [0..MAXTIMEOUT].
Setting the grammar in the body of the function: Specifying the link to the grammar: The parameters f = hello & b = 1 provide the sound of the sound file, for example, "Speak a number from 1 to 100", which can be interrupted using barge-in, i.e. start talking without listening to the message to the end and thereby start the recognition process. The recognition result is returned to Asterisk as NLSML in the variable $ {RECOG_RESULT}. Answer example: The most important parameters in this output are: Recognition Result = “Eight” Confidence Level = 90 Semantic Tag: 8 At the initial stage, the application logic can be built using REGEX, for example, using the NLSML parser is more correct.
The parser that comes with VoiceNavigator is an AGI script in Perl. You can pass it the value of the variable exten => s, n, AGI (NLSML.agi, $ {QUOTE ($ {RECOG_RESULT})}) and as a result get the variables $ {RECOG_UTR0} = eight, $ {RECOG_INT0} = 8, $ { RECOG_CNF0} = 90.
The next series will talk in more detail about the synthesis tags used and the construction of recognition grammars.
Waiting for your questions and comments.
Part 3
Part 4
Considering the increased interest of the community in Asterisk, I decided to contribute and talk about building voice menus using speech synthesis and recognition.
The article is intended for specialists with experience in building IVR in Asterisk and having an understanding of voice self-service systems.
GHS (voice self-service systems) significantly expand the ability to create voice applications and allow the user to receive information and order services independently, without operator intervention. This can be routing calls, requesting and issuing information on a flight schedule, the state of a bank account, ordering a taxi, making an appointment with a doctor, etc.
Recognition eliminates the need for linear menus created with DTMF, speaks human language to the system, and easily creates multiple-choice menus.
The synthesis greatly simplifies the work with dynamically changing information and large amounts of text data.
Below I will describe the integration of Asterisk with VoiceNavigator , as I am an employee of a company that develops it and is engaged in, inter alia, support and integration with small platforms (Asterisk, FreeSWITCH). I must say that the solution is paid. There are no really working OpenSource applications for the synthesis and recognition of Russian speech.
Synthesis and recognition of Russian speech in Asterisk
The industry standard for implementing synthesis and recognition functionality is the use of the MRCP protocol .
Asterisk uses the UniMRCP library for this .
UniMRCP is an open source cross-platform software that includes the necessary tools to implement the functions of the MRCP client and MRCP server.
The project is slowly developing and, as far as I know, this is the only OpenSource solution for working with the MRCP protocol for today. Supports Asterisk (all versions starting with 1.4) and FreeSWITCH.
VoiceNavigator
VoiceNavigator is a software package that is installed on a separate Windows machine and provides access to synthesis and recognition engines using the MRCP protocol.
It includes the STC MRCP Server, the STC TTS speech synthesis suite, and the STC ASR speech recognition suite.
MRCP server
The MRCP server controls the interaction between the used voice platform and the ASR and TTS modules. STC MRCP Server supports the following voice platforms: Asterisk, FreeSWITCH, Avaya Voice Portal, Genesys Voice Platform, Cisco Unified CCX, Siemens OpenScape.
MRCP requests are sent by RTSP protocol commands .
To transmit audio data, the RTP protocol is used .
The voice platform through the MRCP server requests access to speech recognition and synthesis modules, depending on this, various interaction schemes are used.
ASR
The ASR module deals with speech recognition. A key concept for ASR is the SRGS grammar .
SRGS (speech recognition grammar specification) is a standard that describes the structure of the grammar used in speech recognition. SRGS allows you to specify words or phrases that can be recognized by the speech engine.
The creation of grammars is a separate science and, if there is interest, I am ready to write a separate article.
Tts
TTS module uses a markup language SSML is (Speech Synthesis, Markup the Language) based on XML for use in speech synthesis applications.
Synthesis is controlled by tags. With their help, you can determine the pronunciation, control intonation, speed, volume, pause length, reading rules, etc.
An example of the synthesis of speech from the MDGs can be heard here vitalvoice.ru/demo
Scheme of work
The call arrives on the voice platform.
The voice platform activates the script of the voice menu, according to which further interaction with the subscriber takes place.
The scenario of the voice menu determines: when the system should read the instructions to the subscriber, ask a question and how to process his answer.
VoiceNavigator receives speech recognition and speech synthesis requests from the voice platform, executes them, and returns the result of execution using the MRCP protocol .
In speech recognition, the voice platform transmits the SRGS grammar and digitized speech and receives a response in the form of NLSML .
In speech synthesis, the voice platform transmits plain text or SSML and receives synthesized speech in response.
Install and configure UniMRCP
Let's move on to the practical part.
The following describes the installation of UniMRCP in the native for Asterisk CentOS. When installing on other OSs, there may be slight differences.
Download the latest version of uni-ast-package-0.3.2 from the official site .
The package contains:
• Asterisk version 1.6.2.9 - work with this version has been tested by the UniMRCP developer;
• Asterisk-UniMRCP-Bridge 0.1.0 - a bridge for pairing Asterisk and UniMRCP module;
• UniMRCP - Module UniMRCP 1.0.0;
• APR - Apache Portable Runtime 1.4.2;
• APR-Util - Apache Portable Runtime Utility Library 1.3.9;
• Sofia-SIP- SIP User-Agent library 12.1.10.
Installation requires autoconf, libtool, gcc, pkg-config.
After unpacking, we see three scripts in the root of the folder:
ast-install.sh - installs the Asterisk that comes with the delivery if it is not installed on the system.
uni-install.sh - installs UniMRCP
connector-install.sh - installs the bridge between Asterisk and UniMRCP.
We launch them in this order (if Asterisk is installed - ast-install.sh is not necessary) and answer all questions in the affirmative.
We see that everything is installed without errors.
In my experience, errors occur only when dependencies are not satisfied. If Asterisk was previously built from source, then all the dependencies should already be satisfied and the installation will be quick and easy.
After installation, Asterisk got 2 new modules res_speech_unimrcp.so and app_unimrcp.so, and the dialplan got the commands MRCPSynth and MRCPRecog. You can verify the installation is correct by entering in the Asterisk console: Before you can work with synthesis and recognition resources, you must connect them. The file /etc/asterisk/mrcp.conf is used to connect to the MRCP server. You can edit its contents or replace it with the following (comments have been added to explain the most important parameters): After restarting Asterisk, the profile will be activated and the system is ready to work and create the first voice application. As described earlier, Asterisk uses the functions MRCPSynth and MRCPRecog of the app_unimrcp.so library to work:
*CLI> module show like mrcp
Module Description Use Count
res_speech_unimrcp.so UniMRCP Speech Engine 0
app_unimrcp.so MRCP suite of applications 0
2 modules loaded[general]
;Профили для ASR и TTS, используемые по умолчанию.
;Возможна работа одновременно с несколькими MRCP-серверами
default-asr-profile = vn-internal
default-tts-profile = vn-internal
; UniMRCP logging level to appear in Asterisk logs. Options are:
; EMERGENCY|ALERT|CRITICAL|ERROR|WARNING|NOTICE|INFO|DEBUG -->
log-level = DEBUG
max-connection-count = 100
offer-new-connection = 1
; rx-buffer-size = 1024
; tx-buffer-size = 1024
; request-timeout = 60
;Имя профиля
[vn-internal]
; +++ MRCP settings +++
;Версия MRCP-протокола
version = 1
;
; +++ RTSP +++
; === RSTP settings ===
; Адрес MRCP-сервера
server-ip = 192.168.2.106
;Порт, по которому VoiceNavigator принимает запросы на синтез и распознавание
server-port = 8000
; force-destination = 1
;Расположение ресурсов синтеза и распознавания на MRCP-сервере
;(для VoiceNavigator – пустое значение)
resource-location =
;Имена ресурсов синтеза и распознавания в VoiceNavigator
speechsynth = tts
speechrecog = asr
;
; +++ RTP +++
; === RTP factory ===
;IP-адрес компьютера, на котором установлен Asterisk и с которого будет сниматься RTP-трафик.
rtp-ip = 192.168.2.104
; rtp-ext-ip = auto
;Диапазон RTP-портов
rtp-port-min = 32768
rtp-port-max = 32888
; === RTP settings ===
; --- Jitter buffer settings ---
playout-delay = 50
; min-playout-delay = 20
max-playout-delay = 200
; --- RTP settings ---
ptime = 20
codecs = PCMU PCMA L16/96/8000
; --- RTCP settings ---
rtcp = 1
rtcp-bye = 2
rtcp-tx-interval = 5000
rtcp-rx-resolution = 1000MRCPSynth
The MRCPSynth function has the following format:
MRCPSynth (text, options), where
text is the text to synthesize (text \ SSML),
options are synthesis parameters.
Synthesis parameters:
p - Connection profile to the synthesis resource, contained in the file mrcp.conf
i - The numbers that are pressed on the phone, the synthesis will be interrupted
f - File name for recording synthesized speech (recording is made in raw, recording is not performed if the parameter or the file name is not specified)
v - Voice that needs to be synthesized, for example, “Maria8000”.
Dialplan example of using a function
plain-text:
exten => 7577,n,MRCPSynth(Произнесите имя и фамилию сотрудника)
SSML: The advantage of using SSML over plain-text is the ability to use various tags (voice, speed and expressiveness of speech, pauses, interpretation of text, etc.).
exten => 7577,MRCPSynth(Произнесите имя и фамилию сотрудника.
MRCPRecog
The MRCPRecog function has the following format:
MRCPRecog (grammar, options), where
grammar is the grammar (URL \ SRGS), is specified by a link to a file located on the http server or directly in the function body.
options - recognition options.
Recognition parameters:
p - Connection profile to the recognition resource, contained in the file mrcp.conf
i - DTMF code digits, upon receipt of which recognition will be interrupted.
If the value is “any” or other characters, recognition will be interrupted when they are received, and the character will be returned to the dialing plan.
f - The name of the file to play as invitation
b- Ability to interrupt the file being played (barge-in mode) and start recognition (you cannot interrupt = 0, you can interrupt and speech detection is performed by ASR engine = 1, you can interrupt and speech detection is performed by Asterisk = 2)
t - Time, after which the recognition system can interrupt the recognition procedure with the recognition-timeout (003) code, if recognition has begun, and there is not a single recognition option. The value is specified in milliseconds in the range [0..MAXTIMEOUT].
ct - Threshold of confident recognition (0.0 - 1.0).
If the confidence-level returned during recognition is less than confidence-threshold, then the result of recognition is no match.
sl- Sensitivity to non-dictionary commands. (0.0 - 1.0). The higher the value, the higher the sensitivity to noise.
nb - Defines the number of returned recognition results. N recognition results are returned, with a confidence level greater than confidence-threshold. Default value = 1.
nit - The time after which the recognition system can interrupt the recognition procedure, with the code no-input-timeout (002), if recognition starts and speech is not found. The value is specified in milliseconds, in the range [0..MAXTIMEOUT].
Dialplan example of using a function
Setting the grammar in the body of the function: Specifying the link to the grammar: The parameters f = hello & b = 1 provide the sound of the sound file, for example, "Speak a number from 1 to 100", which can be interrupted using barge-in, i.e. start talking without listening to the message to the end and thereby start the recognition process. The recognition result is returned to Asterisk as NLSML in the variable $ {RECOG_RESULT}. Answer example: The most important parameters in this output are: Recognition Result = “Eight” Confidence Level = 90 Semantic Tag: 8 At the initial stage, the application logic can be built using REGEX, for example, using the NLSML parser is more correct.
exten => 7577,n,MRCPRecog(- один
- два
- три
- четыре
- пять
- шесть
- семь
- восемь
- девять
exten => 7577,n,MRCPRecog(http://192.168.1.1/digits.xml,f=hello&b=1)
восемьвосемь C:\Documents and Settings\All Users\Application Data\Speech Technology Center\Voice Digger\temp\e856d208-7794-43b0-bb89-01947e37e655.slf 8
exten => 8800,5,GotoIf(${REGEX("восемь" ${RECOG_RESULT})}?100:10)The parser that comes with VoiceNavigator is an AGI script in Perl. You can pass it the value of the variable exten => s, n, AGI (NLSML.agi, $ {QUOTE ($ {RECOG_RESULT})}) and as a result get the variables $ {RECOG_UTR0} = eight, $ {RECOG_INT0} = 8, $ { RECOG_CNF0} = 90.
Example of a simple voice recognition application for numbers
exten => 7577,1,Answer
exten => 7577,n,MRCPSynth(Назовите число от одного до трех. Говорите после сигнала)
exten => 7577,n,MRCPRecog(- один
- два
- три
The next series will talk in more detail about the synthesis tags used and the construction of recognition grammars.
Waiting for your questions and comments.