“It looks like.” How perceptual hash works
- Transfer
Over the past few months, several people have asked me how TinEye works and how, in principle, the search for similar images works.
In truth, I don't know how the TinEye search engine works. It does not disclose the details of the algorithm (s) used. But looking at the search results, I can conclude that some form of perceptual hash algorithm works.
Perceptual hashes are a different concept compared to cryptographic hash functions like MD5 and SHA1. In cryptography, every hash is random. The data that is used to generate the hash serves as a source of random numbers, so that the same data will give the same result, and different data will give a different result. From comparing the two SHA1 hashes, in fact, only two conclusions can be drawn. If the hashes are different, then the data is different. If the hashes match, then the data is most likely the same (since there is a chance of collisions, the same hashes do not guarantee that the data matches). In contrast, perceptual hashes can be compared with each other and make a conclusion about the degree of difference between the two data sets.
All the algorithms for calculating the perceptual hash that I saw have the same basic properties: pictures can be resized, the aspect ratio can be changed, and even the color characteristics can be slightly changed (brightness, contrast, etc.), but they still have the same hash. TinEye exhibits the same properties (but they do more, I will discuss this below).
In images, high frequencies provide detail and low frequencies show structure. A large, detailed photo contains many high frequencies. There is no detail in a very small picture, so it consists entirely of low frequencies. To demonstrate the average hash function, I'll take a photo of my next wife Alison Hannigan.

1. Reduce the size.The fastest way to get rid of high frequencies is to reduce the image. In this case, we reduce it to 8x8, so that the total number of pixels is 64. You can not worry about the proportions, just drive it into a square eight by eight. Thus, the hash will correspond to all variants of the image, regardless of size and aspect ratio.
 =
= 
2. Remove the color. A small image is translated in grayscale, so the hash is reduced threefold: from 64 pixels (64 values of red, 64 green and 64 blue) to a total of 64 color values.
3. Find the mean. Calculate the average for all 64 colors.
4. The chain of bits.This is the funniest: for each color you get 1 or 0, depending on whether it is more or less than average.
5. Build the hash. Convert 64 individual bits to a single 64-bit value. The order does not matter if it is kept constant (I write bits from left to right, from top to bottom).
 =
= 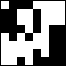 = 8f373714acfcf4d0
= 8f373714acfcf4d0
The resulting hash will not change if the image is scaled, compressed, or stretched. Changing the brightness or contrast, or even manipulating colors, will also not greatly affect the result. And most importantly: such an algorithm is very fast!
If you need to compare two pictures, then just build a hash for each of them and count the number of different bits (this is the Hamming distance) Zero distance means that they are most likely the same pictures (or variations of the same image). Distance 5 means that the pictures are somewhat different, but in general they are still pretty close to each other. If the distance is 10 or more, then these are probably completely different images.
The pHash hash function uses a more robust algorithm (in fact, I use my own version of this algorithm, but the concept is the same). The pHash method is to take the idea of averages to extremes by applying Discrete Cosine Transform (DCT) to eliminate high frequencies.
1. Reduce the size.As with the average hash, pHash works on a small image size. However, here the image is larger than 8x8, here 32x32 is a good size. This is actually done to simplify the DCT, and not to eliminate high frequencies.

2. Remove the color. Likewise, color channels are removed to simplify further calculations.
3. Run the discrete cosine transform. DCT splits a picture into a set of frequencies and vectors. While the JPEG algorithm runs DCT on 8x8 blocks, in this algorithm DCT runs on 32x32.
4. Reduce DCT. This is a magical step. While the original block was 32x32, save only the upper left 8x8 block. It contains the lowest frequencies from the picture.
5. Calculate the average value. As in the average hash, the average DCT value is calculated here, it is calculated on the 8x8 block and the very first coefficient should be excluded from the calculation in order to remove empty information from the hash description, for example, the same colors.
6. Reduce DCT further. Also a magical step. Assign each of the 64 DCT values 0 or 1, depending on whether it is larger or smaller than the average. This option can already withstand gamma correction or a change in the histogram without problems.
7. Build the hash.64 bits turn into a 64-bit value, here, too, the order does not matter. To see what the fingerprint looks like visually, you can assign +255 and -255 values to each pixel, depending on whether it is 1 or 0, and convert the DCT 32x32 (with zeros for high frequencies) back to the 32x32 image.
 = 8a0303769b3ec8cd
= 8a0303769b3ec8cd
At first glance, the picture seems like a meaningless set of spherical outlines, but if you look closely, you can see that the dark areas correspond to the same areas in the photo (hairstyle and strip in the background on the right side of the photo.
As in the average hash, pHash values can be compared with each other using the same Hamming distance algorithm (the value of each bit is compared and the number of differences is calculated).
And again, if you have a service like TinEye, you won’t run pHash every time. I believe that they have a database with pre-calculated hash values. The main function of image comparison is extremely fast (there are some ways to greatly optimize the calculation of the Hamming distance). So computing a hash is a one-time task, and performing millions of comparison operations in a couple of seconds (on one computer) is quite realistic.
Other varieties can analyze the overall color distribution (for example, her hair is more red than blue or green, and the background is more light than dark) or the relative position of the lines.
If you can compare pictures, then completely new perspectives open before you. For example, search engine GazoPaallows you to draw a picture on the screen. As with TinEye, I don’t know all the details of their algorithm, but it looks like some kind of perceptual hash. And since the hash function reduces everything to low frequencies, my crooked pattern of three figures with stick-sticks can be compared with other images, including photos that show three people.
In truth, I don't know how the TinEye search engine works. It does not disclose the details of the algorithm (s) used. But looking at the search results, I can conclude that some form of perceptual hash algorithm works.
This is a perception!
Perceptual hash algorithms describe a class of functions for generating comparable hashes. Image characteristics are used to generate an individual (but not unique) print, and these prints can be compared with each other.Perceptual hashes are a different concept compared to cryptographic hash functions like MD5 and SHA1. In cryptography, every hash is random. The data that is used to generate the hash serves as a source of random numbers, so that the same data will give the same result, and different data will give a different result. From comparing the two SHA1 hashes, in fact, only two conclusions can be drawn. If the hashes are different, then the data is different. If the hashes match, then the data is most likely the same (since there is a chance of collisions, the same hashes do not guarantee that the data matches). In contrast, perceptual hashes can be compared with each other and make a conclusion about the degree of difference between the two data sets.
All the algorithms for calculating the perceptual hash that I saw have the same basic properties: pictures can be resized, the aspect ratio can be changed, and even the color characteristics can be slightly changed (brightness, contrast, etc.), but they still have the same hash. TinEye exhibits the same properties (but they do more, I will discuss this below).
Looks good
How to get perceptual hash? There are several common algorithms for this, and all of them are quite simple (I always wondered how the most famous algorithms give an effect if they are so simple!). One of the simplest hash functions displays the average value of low frequencies.In images, high frequencies provide detail and low frequencies show structure. A large, detailed photo contains many high frequencies. There is no detail in a very small picture, so it consists entirely of low frequencies. To demonstrate the average hash function, I'll take a photo of my next wife Alison Hannigan.
1. Reduce the size.The fastest way to get rid of high frequencies is to reduce the image. In this case, we reduce it to 8x8, so that the total number of pixels is 64. You can not worry about the proportions, just drive it into a square eight by eight. Thus, the hash will correspond to all variants of the image, regardless of size and aspect ratio.
= 2. Remove the color. A small image is translated in grayscale, so the hash is reduced threefold: from 64 pixels (64 values of red, 64 green and 64 blue) to a total of 64 color values.
3. Find the mean. Calculate the average for all 64 colors.
4. The chain of bits.This is the funniest: for each color you get 1 or 0, depending on whether it is more or less than average.
5. Build the hash. Convert 64 individual bits to a single 64-bit value. The order does not matter if it is kept constant (I write bits from left to right, from top to bottom).
= = 8f373714acfcf4d0 The resulting hash will not change if the image is scaled, compressed, or stretched. Changing the brightness or contrast, or even manipulating colors, will also not greatly affect the result. And most importantly: such an algorithm is very fast!
If you need to compare two pictures, then just build a hash for each of them and count the number of different bits (this is the Hamming distance) Zero distance means that they are most likely the same pictures (or variations of the same image). Distance 5 means that the pictures are somewhat different, but in general they are still pretty close to each other. If the distance is 10 or more, then these are probably completely different images.
Trying pHash
The hash is average simple and fast, but it crashes. For example, a duplicate image may not be found after gamma correction or a change in the color histogram. This is due to the fact that the colors change in a non-linear scale, so that the position of the "average" is shifted and many bits change their values.The pHash hash function uses a more robust algorithm (in fact, I use my own version of this algorithm, but the concept is the same). The pHash method is to take the idea of averages to extremes by applying Discrete Cosine Transform (DCT) to eliminate high frequencies.
1. Reduce the size.As with the average hash, pHash works on a small image size. However, here the image is larger than 8x8, here 32x32 is a good size. This is actually done to simplify the DCT, and not to eliminate high frequencies.
2. Remove the color. Likewise, color channels are removed to simplify further calculations.
3. Run the discrete cosine transform. DCT splits a picture into a set of frequencies and vectors. While the JPEG algorithm runs DCT on 8x8 blocks, in this algorithm DCT runs on 32x32.
4. Reduce DCT. This is a magical step. While the original block was 32x32, save only the upper left 8x8 block. It contains the lowest frequencies from the picture.
5. Calculate the average value. As in the average hash, the average DCT value is calculated here, it is calculated on the 8x8 block and the very first coefficient should be excluded from the calculation in order to remove empty information from the hash description, for example, the same colors.
6. Reduce DCT further. Also a magical step. Assign each of the 64 DCT values 0 or 1, depending on whether it is larger or smaller than the average. This option can already withstand gamma correction or a change in the histogram without problems.
7. Build the hash.64 bits turn into a 64-bit value, here, too, the order does not matter. To see what the fingerprint looks like visually, you can assign +255 and -255 values to each pixel, depending on whether it is 1 or 0, and convert the DCT 32x32 (with zeros for high frequencies) back to the 32x32 image.
= 8a0303769b3ec8cd At first glance, the picture seems like a meaningless set of spherical outlines, but if you look closely, you can see that the dark areas correspond to the same areas in the photo (hairstyle and strip in the background on the right side of the photo.
As in the average hash, pHash values can be compared with each other using the same Hamming distance algorithm (the value of each bit is compared and the number of differences is calculated).
Best in class?
Since I am heavily involved in the examination of digital photographs and work with giant image archives, I need a tool to search for identical pictures. So I made a search engine that uses several perceptual hash algorithms. As my rich, albeit unscientific, experience shows, the average hash function is much faster than pHash and it works great if you are looking for something specific. For example, if I have a tiny photo icon and I know for sure that somewhere in the collection a full-size original is stored, then the hash by average quickly finds it. However, if you performed any manipulations with the image, for example, added text or stuck a new face, then it is unlikely to cope with it, while pHash, although slower,And again, if you have a service like TinEye, you won’t run pHash every time. I believe that they have a database with pre-calculated hash values. The main function of image comparison is extremely fast (there are some ways to greatly optimize the calculation of the Hamming distance). So computing a hash is a one-time task, and performing millions of comparison operations in a couple of seconds (on one computer) is quite realistic.
Varieties
There are varieties of perceptual hash algorithm that also improve performance. For example, you can crop the image before reducing the size. In this case, the loss of information around the main part of the image does not play a special role. In addition, the picture can be divided into parts. For example, if you have a face recognition algorithm, you can calculate a hash for each face (I suspect the TinEye algorithm does something similar).Other varieties can analyze the overall color distribution (for example, her hair is more red than blue or green, and the background is more light than dark) or the relative position of the lines.
If you can compare pictures, then completely new perspectives open before you. For example, search engine GazoPaallows you to draw a picture on the screen. As with TinEye, I don’t know all the details of their algorithm, but it looks like some kind of perceptual hash. And since the hash function reduces everything to low frequencies, my crooked pattern of three figures with stick-sticks can be compared with other images, including photos that show three people.