Database scaling in high load systems
At the past internal meeting of Pyrus, we talked about modern distributed repositories, and Maxim Nalsky, the CEO and founder of Pyrus, shared his first impression of FoundationDB. In this article we talk about the technical nuances that you encounter when choosing a technology to scale the storage of structured data.
When the service is unavailable to users for some time, it is wildly unpleasant, but still not fatal. But losing customer data is absolutely unacceptable. Therefore, we scrupulously evaluate any technology for data storage by two or three dozens of parameters.Some of them dictate the current load on the service.
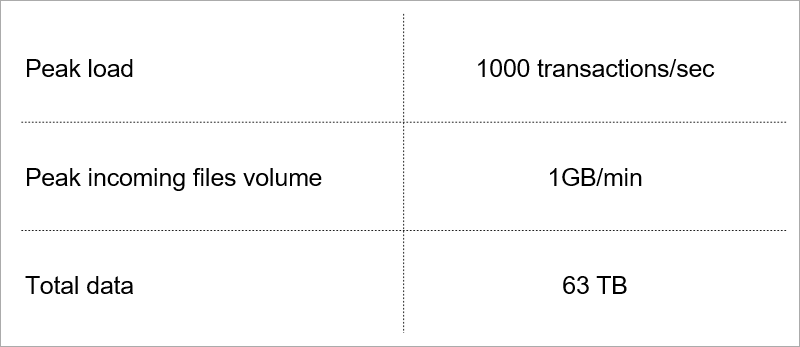 Current load. We select technology taking into account growth of these indicators.
Current load. We select technology taking into account growth of these indicators.
The classic client-server model is the simplest example of a distributed system. The server is a synchronization point, it allows several clients to do something together in a coordinated manner.
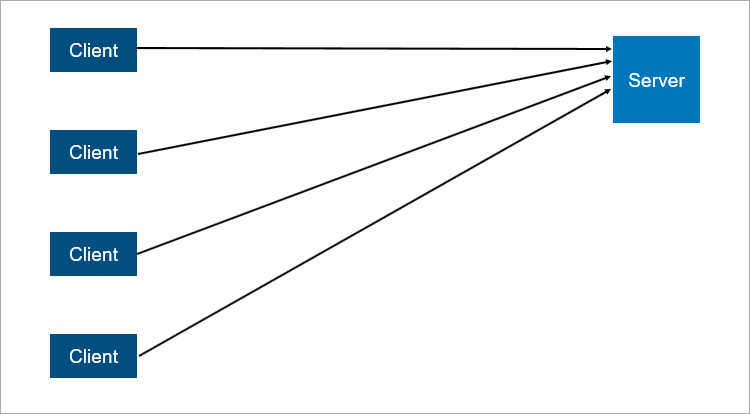 Very simplified client-server interaction scheme.
Very simplified client-server interaction scheme.
What is unreliable in client-server architecture? Obviously, the server may fall. And when the server crashes, all clients cannot work. To avoid this, people came up with a master-slave connection (which is now politically correct called leader-follower ). Essence - there are two servers, all clients communicate with the main server, and the second just replicates all the data.
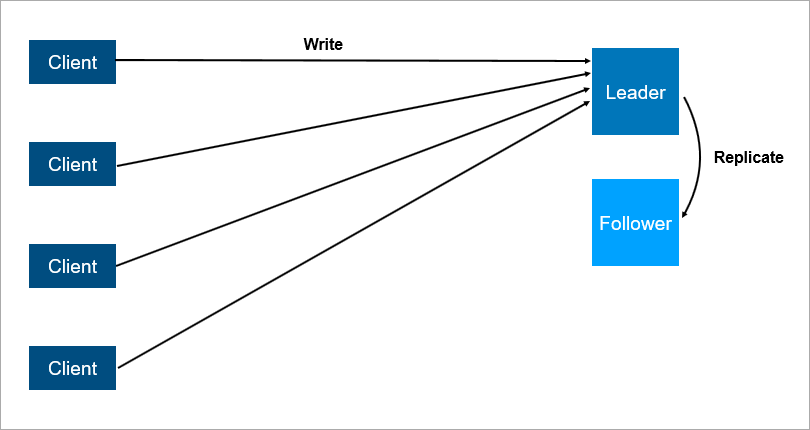 Client-server architecture with data replication on the follower.
Client-server architecture with data replication on the follower.
It is clear that this is a more reliable system: if the main server falls, then a follower has a copy of all the data and it can be quickly picked up.
It is important to understand how replication works. If it is synchronous, then the transaction must be saved simultaneously on both the leader and the follower, and this may be slow. If replication is asynchronous, then some data may be lost after failover.
And what will happen if the leader falls at night when everyone is asleep? There is data on the follower, but no one told him that he is now the leader, and his clients are not connecting to him. OK, let's endow the follower with the logic that he begins to consider himself the main thing when the connection with the leader is lost. Then we can easily get a split brain - a conflict, when the connection between the leader and the follower is broken, and both think that they are the main ones. It really happens in many systems, for example in RabbitMQ - the most popular technology of queues today.
To solve these problems, they organize auto failover - they add a third server (witness, witness). He guarantees that we have only one leader. And if the leader falls off, the follower is automatically turned on with minimal downtime, which can be reduced to a few seconds. Of course, clients in this scheme must know in advance the addresses of the leader and the follower and implement the logic of automatic reconnection between them.
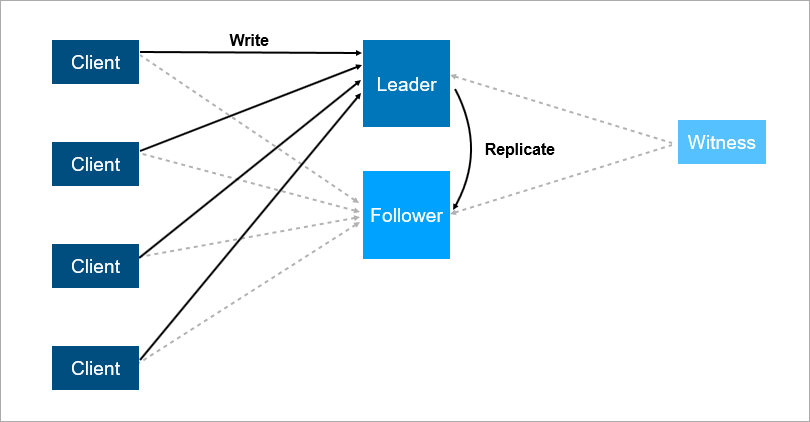 The witness guarantees that there is only one leader. If the leader falls off, the follower is automatically turned on.
The witness guarantees that there is only one leader. If the leader falls off, the follower is automatically turned on.
Such a system now works for us. There is a main database, a backup database, there is a witness and yes - sometimes we come in the morning and see that the switch happened at night.
But this scheme has drawbacks. Imagine that you are installing the service packs or updating the OS on a leading server. Before that, you manually switched the load on the follower and then ... it falls! Catastrophe, your service is unavailable. What to do to protect against this? Add a third backup server - another follower. Three - something like a magic number. If you want the system to work reliably, two servers are not enough, you need three. One is in service, the second falls, the third remains.
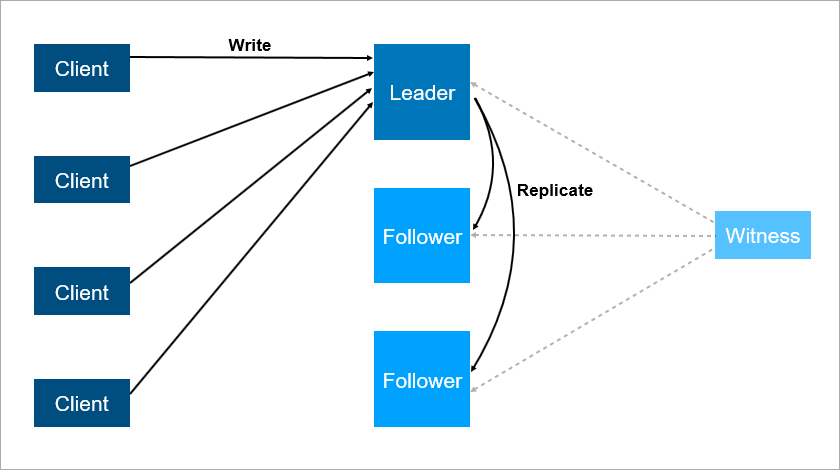 The third server ensures reliable operation if the first two are unavailable.
The third server ensures reliable operation if the first two are unavailable.
To summarize, redundancy should be two. A redundancy of one is not enough. For this reason, in disk arrays, people started using RAID6 instead of RAID5, which is experiencing the fall of two disks at once.
Four basic transaction requirements are well known: atomicity, consistency, isolation, and durability (Atomicity, Consistency, Isolation, Durability - ACID).
When we talk about distributed databases, we mean that the data must be scaled. Reading scales very well - thousands of transactions can read data in parallel without problems. But when, while reading other transactions, writing data, various undesirable effects are possible. It is very easy to get a situation in which one transaction reads different values of the same records. Here are some examples.
Dirty reads.In the first transaction, we send the same request twice: take all users whose ID = 1. If the second transaction changes this line and then rollback, the database will not see any changes on the one hand, and on the other hand The first transaction will read the different age values for Joe.

Non-repeatable reads. Another case is if the write transaction was completed successfully, and the read transaction also received different data when executing the same query.

In the first case, the client read the data that was not in the database at all. In the second case, the client read the data from the database both times, but they are different, although the reading occurs within the same transaction.
Phantom reads -This is when we, within the framework of one transaction, reread any range and get a different set of rows. Somewhere in the middle another transaction got in and inserted or deleted records.

To avoid these undesirable effects, modern DBMS implements locking mechanisms (a transaction restricts other transactions to access data with which it now works) or multi-version control, MVCC (a transaction never changes previously recorded data and always creates a new version).
The ANSI / ISO SQL standard defines 4 transaction isolation levels that affect the degree of interlocking. The higher the isolation level, the fewer unwanted effects. The charge for this is slowing down the application (since transactions are more often in anticipation of unlocking the data they need) and increasing the likelihood of deadlocks.
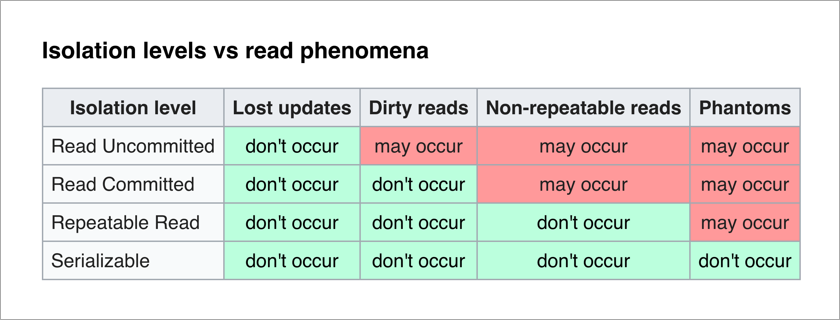
The most pleasant thing for an application programmer is the level of Serializable - there are no undesirable effects and the whole complexity of ensuring the integrity of the data is shifted to the DBMS.
Let's think about the naive implementation of the Serializable level - with each transaction we simply block all others. Each write transaction can theoretically be done in 50µs (the time of a single write operation on modern SSD drives). And we want to save data on three cars, remember? If they are in the same data center, the recording will take 1-3 ms. And if they, for reliability, are located in different cities, the recording can easily take 10-12ms (the travel time of the network package from Moscow to St. Petersburg and back). That is, with a naive implementation of the Serializable level by sequential writing, we can perform no more than 100 transactions per second. With that, a separate SSD drive allows you to perform about 20,000 write operations per second!
Conclusion: write transactions need to be executed in parallel, and for their scaling you need a good conflict resolution mechanism.
What to do when the data no longer fit on one server? There are two standard scaling mechanisms:
The sharding key is a parameter by which data is shared between servers, for example, a customer or organization identifier.
Imagine that you need to write to the cluster data about all the inhabitants of the Earth. As the key of the shard you can take, for example, the year of birth of a person. Then enough 116 servers (and each year will need to add a new server). Or you can take as a key the country where the person lives, then you need about 250 servers. The first option is preferable because the date of birth of a person does not change, and you will never need to transfer data about him between servers.
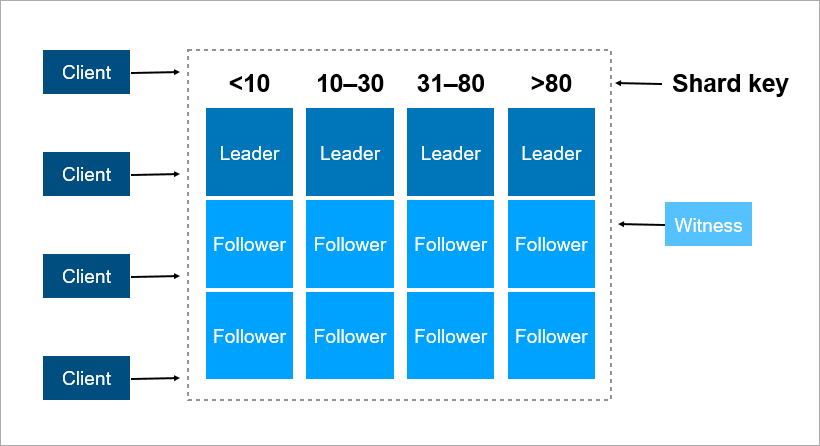
In Pyrus, you can take an organization as a sharding key. But they are very different in size: there is a huge Sovcombank (more than 15 thousand users), and thousands of small companies. When you assign a certain server to an organization, you do not know in advance how it will grow. If the organization is large and uses the service actively, then sooner or later its data will no longer fit on one server, and it will be necessary to do resharing. And this is not easy if these terabytes. Imagine: a loaded system, transactions go every second, and in these conditions you need to move data from one place to another. It is impossible to stop the system, such a volume can be pumped for several hours, and business customers will not survive such a long and simple period.
As a sharding key, it is better to choose data that rarely changes. However, the applied task does not always allow this to be done easily.
When there are a lot of machines in a cluster and some of them lose touch with the others, how to decide who stores the latest version of the data? Simply assigning a witness server is not enough, because it can also lose touch with the entire cluster. In addition, in a split brain situation, several machines can record different versions of the same data — and you need to somehow determine which one is the most relevant. To solve this problem, people came up with consensus algorithms. They allow several identical machines to reach a single result on any issue by voting. In 1989, the first such algorithm, Paxos , was published , and in 2014, the guys from Stanford came up with an easier to implement Raft. Strictly speaking, in order for a cluster of (2N + 1) servers to reach a consensus, it is sufficient that there are no more than N failures at a time. To survive 2 failures, the cluster must have at least 5 servers.
Most databases that developers are used to working with support relational algebra. The data is stored in tables and sometimes you need to join data from different tables using the JOIN operation. Consider an example of a database and a simple query to it.
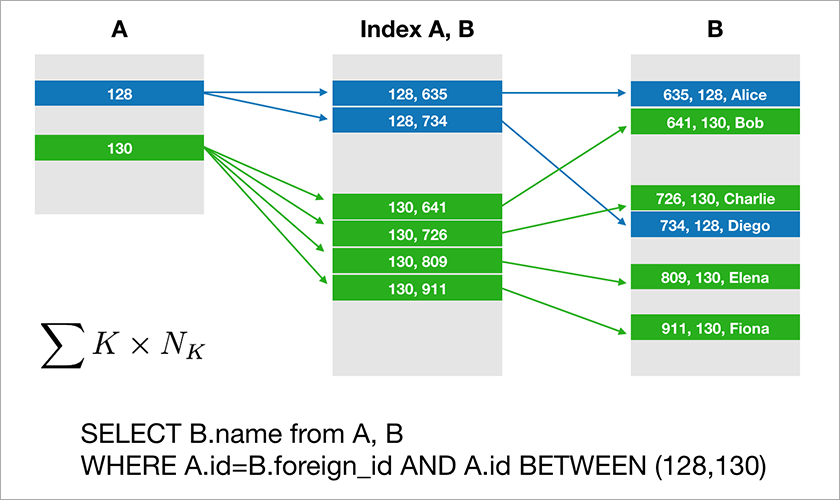
Assume that A.id is a primary key with a clustered index. Then the optimizer will build a plan that will most likely select the desired records from table A first and then take from the appropriate index (A, B) the corresponding links to the records in table B. The execution time of this query grows logarithmically from the number of records in the tables.
Now imagine that the data is distributed across four servers in the cluster and you need to perform the same query:
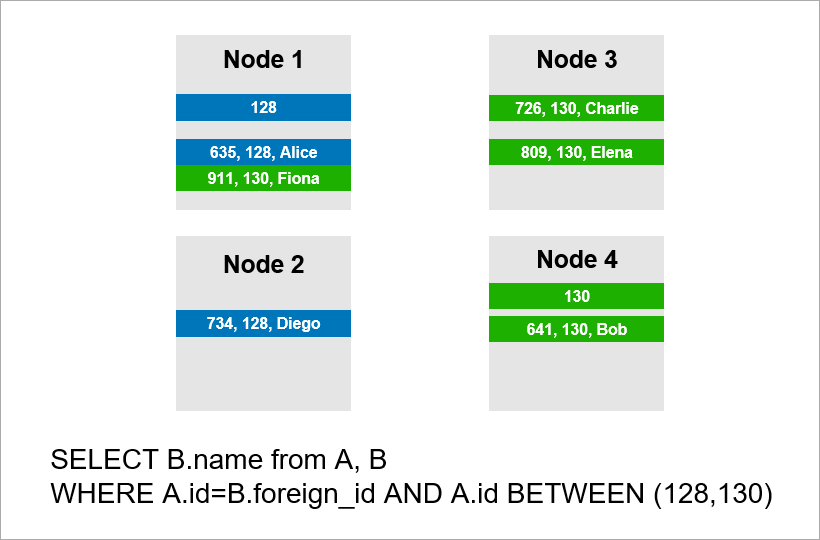
If the DBMS does not want to look through all the records of the entire cluster, then it will probably try to find records with A.id equal to 128, 129, or 130 and find suitable records for them from table B. But if A.id is not the sharding key, then the DBMS is in advance cannot know which server the data of table A. is on. It will be necessary to contact all servers anyway to find out if there are records A.id. that are suitable for our condition. Then each server can make a JOIN inside itself, but this is not enough. See, we need a record at node 2 in the sample, but there is no record with A.id = 128? If nodes 1 and 2 do the JOIN independently, the query result will be incomplete - we will not get some data.
Therefore, to fulfill this request, each server must address all the others. Runtime grows quadratically with the number of servers. (You’re lucky if you can shard all tables with the same key, then you don’t need to bypass all servers. However, in practice this is not realistic - there will always be queries that require non-shard key sampling.)
Thus, the JOIN operations are scaled fundamentally bad and this is the fundamental problem of the relational approach.
Difficulties with scaling classical DBMS led to the fact that people invented NoSQL-databases, in which there is no JOIN operation. No joins - no problem. But there is no ACID-properties, and this was not mentioned in the marketing materials. Craftsmen were quickly found who tested different distributed systems for strength and spread the results publicly . It turned out that there are scenarios when the Redis cluster loses 45% of the saved data, the RabbitMQ cluster - 35% of messages , MongoDB - 9% of records , Cassandra - up to 5% . And we are talking about the loss after the cluster informed the client about the successful preservation. Usually you expect a higher level of reliability from the chosen technology.
Google has developed the Spanner database , which operates globally around the world. Spanner guarantees ACID-properties, Serializability and even more. They have atomic clocks in data centers that provide accurate time, and this allows us to build a global transaction order without having to send network packets between continents. The idea behind Spanner is that it is better to let programmers deal with performance problems that arise when there are a large number of transactions than crutches do around the lack of transactions. However, Spanner is a closed technology, it does not suit you, if you for some reason do not want to depend on one vendor.
Natives from Google developed an open source analog Spanner and called it CockroachDB (“cockroach” in English “cockroach”, which should symbolize the survivability of the database). On Habré already wrote about the unavailability of the product to production, because the cluster was losing data. We decided to check out a newer version 2.0, and came to a similar conclusion. We did not lose the data, but some simple requests were carried out for an unreasonably long time.
As a result, today there are relational databases that scale well only vertically, and this is expensive. And there are NoSQL solutions without transactions and without ACID guarantees (if you want ACID, write crutches).
How to do mission-critical applications, in which data does not fit on one server? New solutions are appearing on the market and one of them, FoundationDB , will be described in more detail in the next article.
When the service is unavailable to users for some time, it is wildly unpleasant, but still not fatal. But losing customer data is absolutely unacceptable. Therefore, we scrupulously evaluate any technology for data storage by two or three dozens of parameters.Some of them dictate the current load on the service.
Current load. We select technology taking into account growth of these indicators.Client-server architecture
The classic client-server model is the simplest example of a distributed system. The server is a synchronization point, it allows several clients to do something together in a coordinated manner.
Very simplified client-server interaction scheme. What is unreliable in client-server architecture? Obviously, the server may fall. And when the server crashes, all clients cannot work. To avoid this, people came up with a master-slave connection (which is now politically correct called leader-follower ). Essence - there are two servers, all clients communicate with the main server, and the second just replicates all the data.
Client-server architecture with data replication on the follower.It is clear that this is a more reliable system: if the main server falls, then a follower has a copy of all the data and it can be quickly picked up.
It is important to understand how replication works. If it is synchronous, then the transaction must be saved simultaneously on both the leader and the follower, and this may be slow. If replication is asynchronous, then some data may be lost after failover.
And what will happen if the leader falls at night when everyone is asleep? There is data on the follower, but no one told him that he is now the leader, and his clients are not connecting to him. OK, let's endow the follower with the logic that he begins to consider himself the main thing when the connection with the leader is lost. Then we can easily get a split brain - a conflict, when the connection between the leader and the follower is broken, and both think that they are the main ones. It really happens in many systems, for example in RabbitMQ - the most popular technology of queues today.
To solve these problems, they organize auto failover - they add a third server (witness, witness). He guarantees that we have only one leader. And if the leader falls off, the follower is automatically turned on with minimal downtime, which can be reduced to a few seconds. Of course, clients in this scheme must know in advance the addresses of the leader and the follower and implement the logic of automatic reconnection between them.
The witness guarantees that there is only one leader. If the leader falls off, the follower is automatically turned on. Such a system now works for us. There is a main database, a backup database, there is a witness and yes - sometimes we come in the morning and see that the switch happened at night.
But this scheme has drawbacks. Imagine that you are installing the service packs or updating the OS on a leading server. Before that, you manually switched the load on the follower and then ... it falls! Catastrophe, your service is unavailable. What to do to protect against this? Add a third backup server - another follower. Three - something like a magic number. If you want the system to work reliably, two servers are not enough, you need three. One is in service, the second falls, the third remains.
The third server ensures reliable operation if the first two are unavailable. To summarize, redundancy should be two. A redundancy of one is not enough. For this reason, in disk arrays, people started using RAID6 instead of RAID5, which is experiencing the fall of two disks at once.
Transactions
Four basic transaction requirements are well known: atomicity, consistency, isolation, and durability (Atomicity, Consistency, Isolation, Durability - ACID).
When we talk about distributed databases, we mean that the data must be scaled. Reading scales very well - thousands of transactions can read data in parallel without problems. But when, while reading other transactions, writing data, various undesirable effects are possible. It is very easy to get a situation in which one transaction reads different values of the same records. Here are some examples.
Dirty reads.In the first transaction, we send the same request twice: take all users whose ID = 1. If the second transaction changes this line and then rollback, the database will not see any changes on the one hand, and on the other hand The first transaction will read the different age values for Joe.
Non-repeatable reads. Another case is if the write transaction was completed successfully, and the read transaction also received different data when executing the same query.
In the first case, the client read the data that was not in the database at all. In the second case, the client read the data from the database both times, but they are different, although the reading occurs within the same transaction.
Phantom reads -This is when we, within the framework of one transaction, reread any range and get a different set of rows. Somewhere in the middle another transaction got in and inserted or deleted records.
To avoid these undesirable effects, modern DBMS implements locking mechanisms (a transaction restricts other transactions to access data with which it now works) or multi-version control, MVCC (a transaction never changes previously recorded data and always creates a new version).
The ANSI / ISO SQL standard defines 4 transaction isolation levels that affect the degree of interlocking. The higher the isolation level, the fewer unwanted effects. The charge for this is slowing down the application (since transactions are more often in anticipation of unlocking the data they need) and increasing the likelihood of deadlocks.
The most pleasant thing for an application programmer is the level of Serializable - there are no undesirable effects and the whole complexity of ensuring the integrity of the data is shifted to the DBMS.
Let's think about the naive implementation of the Serializable level - with each transaction we simply block all others. Each write transaction can theoretically be done in 50µs (the time of a single write operation on modern SSD drives). And we want to save data on three cars, remember? If they are in the same data center, the recording will take 1-3 ms. And if they, for reliability, are located in different cities, the recording can easily take 10-12ms (the travel time of the network package from Moscow to St. Petersburg and back). That is, with a naive implementation of the Serializable level by sequential writing, we can perform no more than 100 transactions per second. With that, a separate SSD drive allows you to perform about 20,000 write operations per second!
Conclusion: write transactions need to be executed in parallel, and for their scaling you need a good conflict resolution mechanism.
Sharding
What to do when the data no longer fit on one server? There are two standard scaling mechanisms:
- Vertical, when we simply add memory and disks to this server. This has its limits - according to the number of cores per processor, the number of processors, the amount of memory.
- Horizontal, when we use a lot of machines and distribute data between them. Sets of such machines are called clusters. To put the data in a cluster, they need to be shuffled - that is, for each record, determine which server it will be located on.
The sharding key is a parameter by which data is shared between servers, for example, a customer or organization identifier.
Imagine that you need to write to the cluster data about all the inhabitants of the Earth. As the key of the shard you can take, for example, the year of birth of a person. Then enough 116 servers (and each year will need to add a new server). Or you can take as a key the country where the person lives, then you need about 250 servers. The first option is preferable because the date of birth of a person does not change, and you will never need to transfer data about him between servers.
In Pyrus, you can take an organization as a sharding key. But they are very different in size: there is a huge Sovcombank (more than 15 thousand users), and thousands of small companies. When you assign a certain server to an organization, you do not know in advance how it will grow. If the organization is large and uses the service actively, then sooner or later its data will no longer fit on one server, and it will be necessary to do resharing. And this is not easy if these terabytes. Imagine: a loaded system, transactions go every second, and in these conditions you need to move data from one place to another. It is impossible to stop the system, such a volume can be pumped for several hours, and business customers will not survive such a long and simple period.
As a sharding key, it is better to choose data that rarely changes. However, the applied task does not always allow this to be done easily.
Cluster Consensus
When there are a lot of machines in a cluster and some of them lose touch with the others, how to decide who stores the latest version of the data? Simply assigning a witness server is not enough, because it can also lose touch with the entire cluster. In addition, in a split brain situation, several machines can record different versions of the same data — and you need to somehow determine which one is the most relevant. To solve this problem, people came up with consensus algorithms. They allow several identical machines to reach a single result on any issue by voting. In 1989, the first such algorithm, Paxos , was published , and in 2014, the guys from Stanford came up with an easier to implement Raft. Strictly speaking, in order for a cluster of (2N + 1) servers to reach a consensus, it is sufficient that there are no more than N failures at a time. To survive 2 failures, the cluster must have at least 5 servers.
Scaling relational DBMS
Most databases that developers are used to working with support relational algebra. The data is stored in tables and sometimes you need to join data from different tables using the JOIN operation. Consider an example of a database and a simple query to it.
Assume that A.id is a primary key with a clustered index. Then the optimizer will build a plan that will most likely select the desired records from table A first and then take from the appropriate index (A, B) the corresponding links to the records in table B. The execution time of this query grows logarithmically from the number of records in the tables.
Now imagine that the data is distributed across four servers in the cluster and you need to perform the same query:
If the DBMS does not want to look through all the records of the entire cluster, then it will probably try to find records with A.id equal to 128, 129, or 130 and find suitable records for them from table B. But if A.id is not the sharding key, then the DBMS is in advance cannot know which server the data of table A. is on. It will be necessary to contact all servers anyway to find out if there are records A.id. that are suitable for our condition. Then each server can make a JOIN inside itself, but this is not enough. See, we need a record at node 2 in the sample, but there is no record with A.id = 128? If nodes 1 and 2 do the JOIN independently, the query result will be incomplete - we will not get some data.
Therefore, to fulfill this request, each server must address all the others. Runtime grows quadratically with the number of servers. (You’re lucky if you can shard all tables with the same key, then you don’t need to bypass all servers. However, in practice this is not realistic - there will always be queries that require non-shard key sampling.)
Thus, the JOIN operations are scaled fundamentally bad and this is the fundamental problem of the relational approach.
NoSQL approach
Difficulties with scaling classical DBMS led to the fact that people invented NoSQL-databases, in which there is no JOIN operation. No joins - no problem. But there is no ACID-properties, and this was not mentioned in the marketing materials. Craftsmen were quickly found who tested different distributed systems for strength and spread the results publicly . It turned out that there are scenarios when the Redis cluster loses 45% of the saved data, the RabbitMQ cluster - 35% of messages , MongoDB - 9% of records , Cassandra - up to 5% . And we are talking about the loss after the cluster informed the client about the successful preservation. Usually you expect a higher level of reliability from the chosen technology.
Google has developed the Spanner database , which operates globally around the world. Spanner guarantees ACID-properties, Serializability and even more. They have atomic clocks in data centers that provide accurate time, and this allows us to build a global transaction order without having to send network packets between continents. The idea behind Spanner is that it is better to let programmers deal with performance problems that arise when there are a large number of transactions than crutches do around the lack of transactions. However, Spanner is a closed technology, it does not suit you, if you for some reason do not want to depend on one vendor.
Natives from Google developed an open source analog Spanner and called it CockroachDB (“cockroach” in English “cockroach”, which should symbolize the survivability of the database). On Habré already wrote about the unavailability of the product to production, because the cluster was losing data. We decided to check out a newer version 2.0, and came to a similar conclusion. We did not lose the data, but some simple requests were carried out for an unreasonably long time.
As a result, today there are relational databases that scale well only vertically, and this is expensive. And there are NoSQL solutions without transactions and without ACID guarantees (if you want ACID, write crutches).
How to do mission-critical applications, in which data does not fit on one server? New solutions are appearing on the market and one of them, FoundationDB , will be described in more detail in the next article.