Four kinds of NTFS metadata
 In this topic, I will consider four types of metadata that can be attached to a file or directory using the NTFS file system . I will describe the purposes for which this or that type of metadata can be used; I will give an example of its use in any Microsoft technology or third-party software.
In this topic, I will consider four types of metadata that can be attached to a file or directory using the NTFS file system . I will describe the purposes for which this or that type of metadata can be used; I will give an example of its use in any Microsoft technology or third-party software. We will talk about reparse points, object identifiers and other types of data that a file can contain in addition to its main content.
Object id
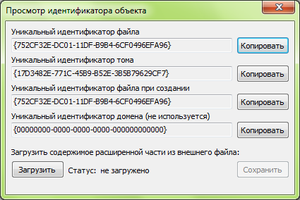
The object identifier is 64 bytes that can be attached to a file or directory. Of these, the first 16 bytes allow you to uniquely identify the file within the volume and access it not by name, but by identifier. The remaining 48 bytes may contain arbitrary data.
Object identifiers have existed in NTFS since Windows 2000. In the system, they are used to track the location of the file referenced by a shortcut (.lnk). Suppose the file referenced by the shortcut has been moved within the volume. When you launch the shortcut, it will still open. A special Windows service, if the file is not found, will try to open the file not by its name, but by a previously created and saved identifier. If the file has not been deleted and has not left the volume, it will open, and the shortcut will again point to the file.
Object IDs were used in iSwift technology of Kaspersky Anti-Virus version 7. Here is how this technology is described:The technology was developed for the NTFS file system. In this system, an NTFS identifier is assigned to each object. This identifier is compared with the values of the special iSwift database. If the database values with the NTFS identifier do not match, then the object is checked or double-checked if it has been modified.
However, an overabundance of created identifiers caused problems with scanning the disk with the standard chkdsk verification utility; it took too long. In the next versions of Kaspersky Anti-Virus, they refused to use NTFS Object Id.
Reparse point
In the NTFS file system, a file or directory may contain a reparse point, which is translated into Russian as a “reprocessing point” . Special data is added to the file or directory, the file ceases to be a regular file and only a special file system filter driver can process it.
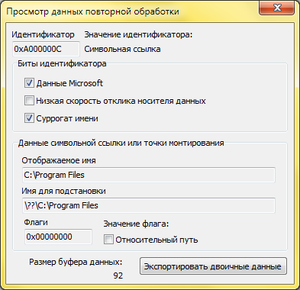
There are reparse point types on Windows that can be processed by the system itself. For example, through the reprocessing points in Windows, symlink and junction points, as well as mount points for volumes are implemented in the directory.
A reparse buffer attached to a file is a buffer with a maximum size of 16 kilobytes. It is characterized by the presence of a tag that tells the system which type the reprocessing point belongs to. When using a reparse buffer of its own type, it is still necessary to specify a GUID in it in a special field, and it may not be present in Microsoft reparse buffers.
What types of reprocessing points exist? I will list the technologies that use reparse points. These are Single Instance Storage (SIS) and Cluster Shared Volumes in Windows Storage Server 2008 R2, Hierarchical Storage Management, Distributed File System (DFS), Windows Home Server Drive Extender. These are Microsoft technologies, third-party technologies that use reprocessing points are not mentioned here, although there are some.
Extended attributes
Extended file attributes . About them was my previous topic . It is worth mentioning only that under Windows this technology is practically not used. Of the software I know, only Cygwin uses extended attributes to store POSIX permissions. A single NTFS file can have either extended attributes or a reprocessing point buffer. Simultaneous installation of both is not possible. The maximum size of all extended attributes for a single file is 64 Kb.
Alternate Data Streams
Additional file streams. Probably everyone already knows about them. I will list the main features of this type of metadata: naming (that is, a file can have several streams, and each has its own name), direct access from the file system (they can be opened using the format "file name, colon, stream name"), unlimited size , the ability to start a process directly from a thread (and the ability to implement a file-free process through it ).
Used in iStream technology of Kaspersky Anti-Virus. They are used in Windows itself, for example, when downloading a file from the Internet, the Zone.Identifier stream is attached to it, containing information about where this file is received from. After running the executable file, the user can see the message“Cannot verify publisher. Are you sure you want to run this program? ” .
So the user is given additional protection against rash running programs received from the Internet. This is just one application of threads, and so you can store a variety of data in them. The aforementioned Kaspersky Anti-Virus stored checksums of each file there, but later this technology was also abandoned for some reason.
Anything else?
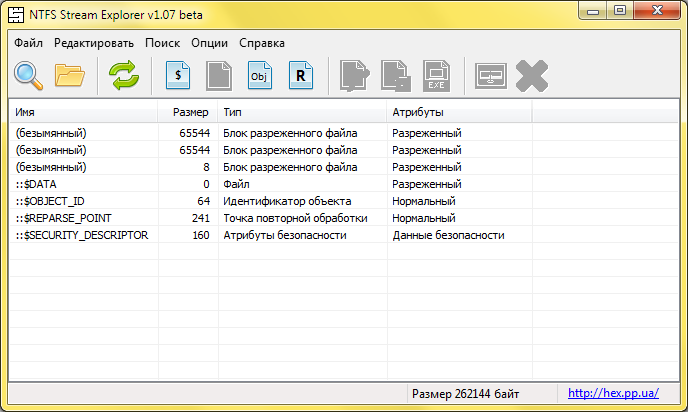
There is also a security identifier , plus standard file attributes that are not directly accessible, even though they are also implemented as file streams. And they, and extended attributes, and reparse and object id - all these are file streams from the point of view of the system. Directly changing the security identifier shown in the following image as :: $ SECURITY_DESCRIPTOR makes no sense, let the system deal with its change. The system itself does not provide direct access to other types of flows. So that’s all.
Viewing the contents of object id, reprocessing points, as well as working with advanced attributes and alternative file streams is possible using the NTFS Stream Explorer program , as well as through the fsutil system console utility .