RMQ Challenge - 1. Static RMQ
Introduction
The RMQ problem is very common in sports and application programming. It is amazing that no one has mentioned this interesting topic on Habré. I'll try to fill the gap.
The acronym RMQ stands for Range Minimum (Maximum) Query - query for the minimum (maximum) on a segment in an array. For definiteness, we will consider the operation of taking a minimum.
Let an array A [1..n] be given. We need to be able to respond to a request of the form “find a minimum in the interval from the ith element to the jth”.
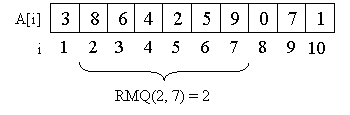
Consider, as an example, an array A = {3, 8, 6, 4, 2, 5, 9, 0, 7, 1}.
For example, the minimum in the segment from the second element through the seventh is two, that is, RMQ (2, 7) = 2.
The obvious decision comes to mind: we will find the answer to each request simply by going over all the elements of the array lying on the segment we need. Such a solution, however, is not the most effective. Indeed, in the worst case, we will have to go over O (n) elements, i.e. the time complexity of this algorithm is O (n) per request. However, the problem can be solved more efficiently.
Formulation of the problem
First, let us clarify the statement of the problem.
What does the word static mean in the title of an article? The task of RMQ is sometimes posed with the ability to change the elements of an array. That is, the ability to change an element, or even change elements in a segment (for example, increase all elements in a sub-segment by 3) is added to the minimum take request. This version of the problem, called dynamic RMQ, I will consider in subsequent articles.
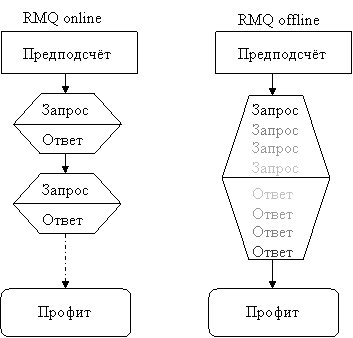
I note here that the RMQ task is divided into offline and online versions. In the offline option, you can first get all the requests, analyze them in some way, and only then give an answer to them. In online-stop requests are given in turn, i.e. The next request comes only after the answer to the previous one. Note that having solved RMQ in an online installation, we immediately get a solution for offline RMQ, however, there may be a more effective solution for offline RMQ that is not applicable for online installation.
In this article we will look at static online RMQ.
Preprocessing time
To evaluate the efficiency of the algorithm, we introduce one more time characteristic - preprocessing time. In it, we will take into account the time for preparation, i.e. pre-calculation of some information necessary to respond to requests.
It would seem, why do we need to separate the preprocessing separately? But why. We give one more solution to the problem.
Before you start responding to queries, take and simply calculate the answer for each segment! Those. we will construct an array P [n] [n] (in the future I will use a C-like syntax, although I will number array A from one for ease of implementation), where P [i] [j] will equal the minimum in the interval from i to j. Moreover, we calculate this array at least for O (n 3) - in the most stupid way, going over all the elements for each segment. Why are we doing this? Suppose the number of queries q is much greater than n 3 . Then the total operating time of our algorithm is O (n 3 ) + q * O (1) = O (q), i.e. time for preprocessing by and large will not affect the overall time of the algorithm. But thanks to the summarized information, we learned to respond to a request in O (1) time instead of O (n). It is clear that O (q) is better than O (qn).
On the other hand, for q <n 3 , the preprocessing time will play a role, and in the above algorithm, it is O (n 3 ), unfortunately, is too long, even though it can be reduced (think how) to O (n 2 ).
Starting from this moment, we denote the temporal characteristics of the algorithm as (P (n), Q (n)), where P (n) is the time for pre-calculation and Q (n) is the time for responding to one request.
So, we have two algorithms. One works for (O (1), O (n)), the second for (O (n 2 ), O (1)). We learn how to solve the problem in (O (nlogn), O (1)), where logn is the binary logarithm of n.
Lyrical digression. Note that you can take any number as the base of the logarithm, because log a n always differs from log b n exactly a constant number of times. The constant, as we recall from the school algebra course, is log a b.
So, we got to the next step:
Sparse Table, or Sparse Table
Sparse Table is a table ST [] [] such that ST [k] [i] is a minimum on the half-interval [A [i], A [i + 2 k ]). In other words, it contains minima on all segments whose length is a power of two.
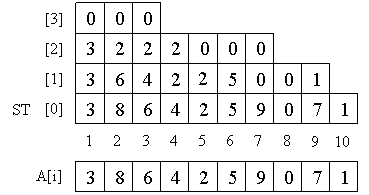
We count the array ST [k] [i] as follows. It is clear that ST [0] is simply our array A. Next, we use the clear property:
ST [k] [i] = min (ST [k-1] [i], ST [k-1] [i + 2 k - 1 ]). Thanks to it, we can first calculate ST [1], then ST [2], etc.
Note that there are O (nlogn) elements in our table, because the level numbers should be no more than logn, because for large values k the length of the half-interval becomes greater than the length of the entire array and it makes no sense to store the corresponding values. And at each level O (n) elements.
Lyrical digression again: It is easy to notice that we still have many unused elements of the array. Is it worth it to store the table differently so as not to waste memory? We estimate the amount of unused memory in our implementation. On the ith row of unused elements - 2 i - 1. Therefore, Σ (2 i - 1) = O (2 logn ) = O (n) remains the total unused , that is, in any case, the order of O (nlogn) - O (n) = O (nlogn) places to store the Sparse Table. So you can not worry about unused items.
And now the main question: why did we consider all this? Note that any segment of the array is divided into two overlapping sub-segments of length two.

We get a simple formula for calculating RMQ (i, j). If k = log (j - i + 1), then RMQ (i, j) = min (ST (i, k), ST (j - 2 k + 1, k)). Thus, we obtain the algorithm in (O (nlogn), O (1)). Hurrah!
... almost get it. How do we take the logarithm of going for O (1)? The easiest way to calculate it is also for all values not exceeding n. It is clear that the asymptotic behavior of preprocessing will not change from this.
What's next?
And in subsequent articles, we will consider many variations of this task and plots associated with them, such as:
- tree of segments
- interval modification
- two-dimensional tree of segments
- adjacent RSQ problem
- Fenwick tree
- LCA task
- persistent statement of the RMQ problem
- ... a lot of interesting things ...
- and the most charming thing: the Farah-Colton and Bender algorithm and the RMQ -> LCA -> RMQ ± 1 transformation, which allows us to solve the RMQ problem in (O (n), O (1))
For details, you can contact, for example, in the clever book of T. Cormen, C. Leiserson, and R. Rivest "Algorithms: construction and analysis."
Other topics will appear in subsequent topics.
Thank you for attention.