RAID-4 / RAID-DP - Turning Flaws Into Strengths

When I wrote in a previous post that Snapshots were, at the time of the appearance of NetApp systems, their main “features”, I partly misled (and partly just forgot), because at that moment they had at least one more feature that radically distinguished one of a number of “traditional” storage systems is “RAID type 4”.
This is even more interesting since no one else uses this type of RAID for use in disk storage systems.
Why was this type chosen, what are its advantages, and why no one else uses this type of RAID today?
For those who are far from the theory of readjusting, I recall that of the six standard types of RAID described in the scientific work that laid the foundation for their use, RAID type 2 (with Hamming code protection) was not used in "living nature", remaining a fun theoretical exercise, RAID-1 (and its version of RAID-10, or, sometimes, as RAID-0 + 1) is data protection by automatic synchronous mirroring on a pair (or several pairs) of physical disks, and RAID-3, 4 and 5 (later to them RAID type 6 was added) - these are the so-called "RAID with striping and parity." Between themselves, they differ in the way they organize and store parity data, as well as in the order of data rotation. In RAID-5, which is usually well known to everyone, data is striped across disks along with parity information, that is, parity does not take up a special disk.
In RAID-3 and 4, a separate disk is allocated for parity information (Between 3 and 4, the difference in the size of the striping unit is a sector in type 3 and a group of sectors, a block in type 4).
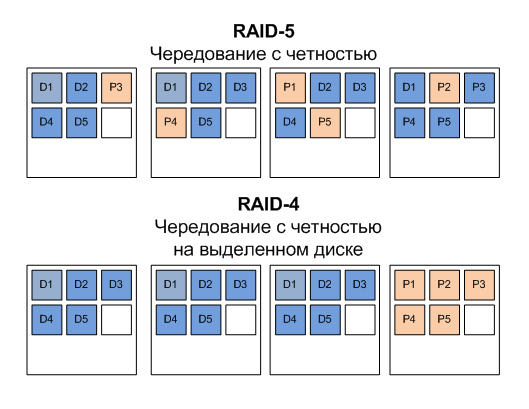
RAID-4, that is, “RAID with block striping and parity on a dedicated drive,” has one important advantage. It can be increased in size by simply adding physical disks to the RAID, and there is no need to completely rebuild the entire RAID, as, for example, is the case with RAID-5. If you use 5 drives for data (and one for parity) in RAID-4, then in order to increase its capacity, you can simply add one, two, and so on to it, and the capacity of the RAID array will immediately increase by volume of added disks. No long process of rebuilding a RAID array unavailable for use, as in the case of RAID-5, is needed. An obvious and very convenient advantage in practice.
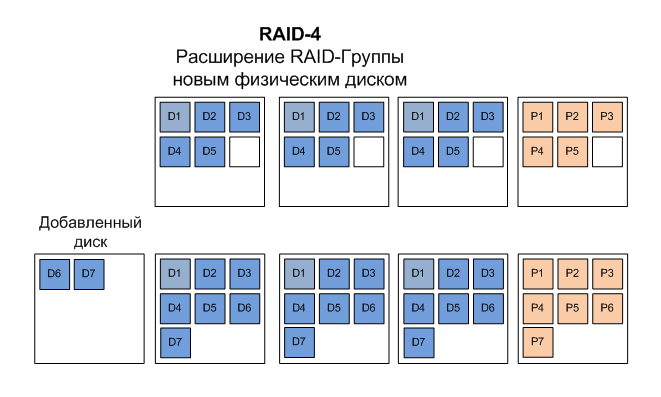
Why then is RAID-4 not universally used instead of RAID-5?
It has one but very serious problem - write performance.
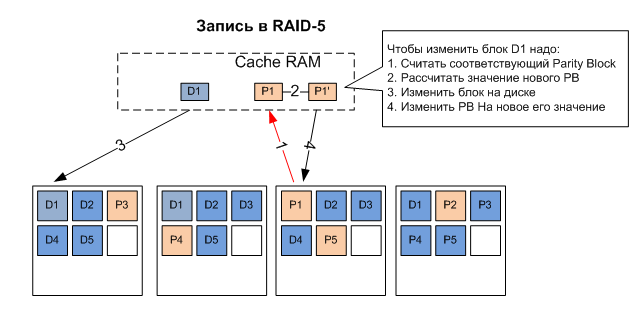
The fact is that each write operation of a block on RAID disks is accompanied by a write to update the parity block on the Parity disk. This means that no matter how much we add to our array of disks, between which I / O will be parallelized, it will still all rest in one single disk - the parity disk. In fact, the performance of RAID-4, in its "classic" application, is limited by the performance of the Parity disk. While this disc has not been updated to record the contents of the parity blocks lying on it, all other disks that store data spin and wait for this operation to complete.
This problem was partially solved in RAID-5, where parity blocks are also parallelized across disks, as well as data blocks, and the bottleneck problem with parity disk was partially solved, which, however, does not mean that RAID-5 is devoid of all the drawbacks, rather the opposite, is, for today, the worst type of RAID of all widely used, suffering from unreliability and low performance, which I wrote in the article "Why RAID-5 - mustdie?" .
Particularly dwelling on performance issues (read the article about reliability), RAID-5 has one, but very serious “birth injury,” which was originally structurally inherent in this type of RAID in general (types 3,4,5 and 6 - “alternating with parity ") - low performance on an arbitrary (random) record. This aspect in real life is very important, since the volumes of arbitrary, random in nature, records in the total storage traffic are quite significant (reaching 30-50%), and a drop in write performance directly affects the performance of the storage in general.
This problem is "sick", I repeat, all the "classic" storage systems that use RAID of this type (3, 4, 5 and 6).
Everyone except NetApp.
How did NetApp solve both the bottleneck problem with the parity disk and the poor performance problem with random write?
Here we again have to recall the structure of WAFL, which I already wrote about earlier.
As NetApp engineer Kostadis Roussos said on this subject: “Almost any file system today is on top of a particular RAID. But only WAFL and RAID on NetApp are aware of each other so much as to use each other’s capabilities and compensate each other’s shortcomings. ” This is true, because for WAFL the RAID level is just another logical level of data layout inside the file system itself. Let me remind you that NetApp does not use hardware RAID controllers, preferring to build RAID using the means of its file system (a similar approach was later chosen by ZFS from its RAID-Z)
What are these “mutual possibilities”?
As you remember from my story about WAFL, it is designed in such a way that the data on it, once recorded, is not overwritten in the future. If it is necessary to make changes to the contents inside the already recorded file, a space is allocated in the space of free blocks, the modified block is written there, and then the pointer to the contents of the old block is moved to the new block, which was empty, and now carries new content.
This recording strategy allows us to turn a random recording into a sequential record. And if so, we can record as efficiently as possible - by “full stripe” having prepared it beforehand, and by collecting all the “dubs” aimed at different parts of the discs into one convenient recording area. That is, instead of overwriting individual blocks, writing in a single step a finished, formed “strip” of data, at once to all RAID disks, including the previously calculated parity of the entire strip to the corresponding disk. Instead of three read-write operations, one.
It's no secret that sequental operations are much faster and more convenient for the system than random operations.
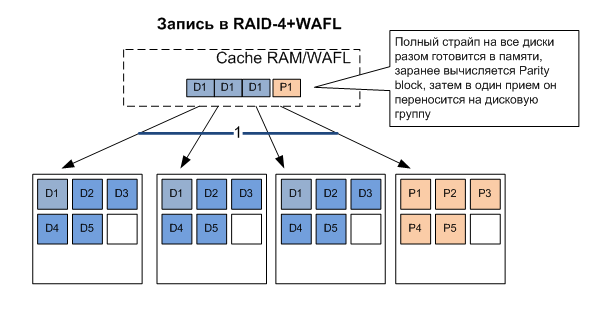
Recording "full strip", that is, on all RAID drives with striping, this is the most desirable recording algorithm for this type of RAID. For this reason, on the RAID-controllers, they increase the cache size, which on high-end systems reaches very impressive sizes (and cost). The larger the write cache in traditional arrays, and the longer the data block that came from the server to write to disk “hangs” in it, the more chances are that in this cache a “full strip” will one day be assembled from such blocks, and it will be possible to merge onto disks as profitably as possible.
That is why the write-back caches of RAID controllers tend to flush data to drives less often, and they need to be powered off-line by battery to save data blocks that are waiting for their turn in the cache.
With the growing volume of disks, NetApp, like all others, was faced with the need to provide increased reliability of RAID data storage. For this reason, since 2005, it is RAID-DP, the NetApp implementation of RAID-6, that is the recommended, preferred, and generally “default configuration”. NetApp also excels in this, since RAID -DP, protecting, like RAID-6, from data loss when losing two disks at once (for example, a failure during rebuild of a previously failed disk), does not degrade performance, unlike RAID- 6 compared to RAID-5 or RAID-10.
The reasons for this are the same. The situation of "other vendors" with RAID-6, compared with RAID-5 is even worse. It is generally accepted that the performance of RAID-6 drops by 10-15% compared to RAID-5, and by 25-35% compared to RAID-10. Now it is necessary to carry out not only read-write of one parity block, but it must be done for two different groups of blocks.
However, RAID-DP still does not need this, the reasons are the same - accidental recording to an arbitrary location in the array is converted into WAFL by a sequential recording into a pre-allocated space, and such recording is much faster and more profitable.
Confirmation that the use of RAID-4 (and its variant - RAID-DP, an analog of RAID-6) on NetApp systems does not objectively lead to performance degradation - authoritative tests of the performance of SAN disk systems (Storage Performance Council, SPC-1 / SPC-1E ) and NAS ( SPECsfs2008 ), which NetApp demonstrates on RAID-4 (and RAID-DP since 2005).
Moreover, NetApp systems with RAID-DP compete there on an equal footing with systems with RAID-10, that is, they show performance much higher than usual for “RAID with striping and parity”, while maintaining high space efficiency, because, as you know, on RAID -10 can be used for data only 50% of the purchased capacity, while on RAID-DP, with higher reliability, but comparable to RAID-10 performance, and for the standard group size, there is an available space for data over 87% .
Thus, the witty use of two “features” together - RAID-4 and the write mode in WAFL, made it possible to get advantages from both of them, at the same time getting rid of their shortcomings. And the further development of RAID-4 in RAID-DP, which provides protection against double disk failure, has increased the reliability of data storage without sacrificing traditionally high performance. And this is not easy. Suffice it to say that the use of RAID-6 (an analogue of RAID-DP, with an equivalently high level of protection), because of low write performance, is not practiced and is not recommended for primary data by any other storage system manufacturer.
How to become rich, strong and healthy at the same time (and so that there is nothing for it)? How to ensure a high degree of data protection from failure, without sacrificing either high performance or disk space?
NetApp knows the answer.
Refer to his partner companies;)
UPD: in the main role in the photo in the splash screen article - NetApp FAS2020A from the farm of the foboss habrayuzer .